






SEED-Story是由腾讯 ARC 实验室推出的一个多模态长篇故事生成项目。它基于大型语言模型(MLLM),能够从用户提供的图像和文本开始,生成包含丰富、连贯的叙事文本以及风格一致的图像的多模态长篇故事。

1️⃣ 开源项目包括啥
多模态故事生成模型:SEED-Story 模型能够生成包含文本和图像的故事,这些故事在角色和风格上保持一致性。
StoryStream 数据集:项目团队还发布了一个专为多模态故事生成训练和基准测试设计的大规模数据集。
技术方法:SEED-Story 采用了三阶段的方法,包括视觉分词、指令调优和去分词器适应。
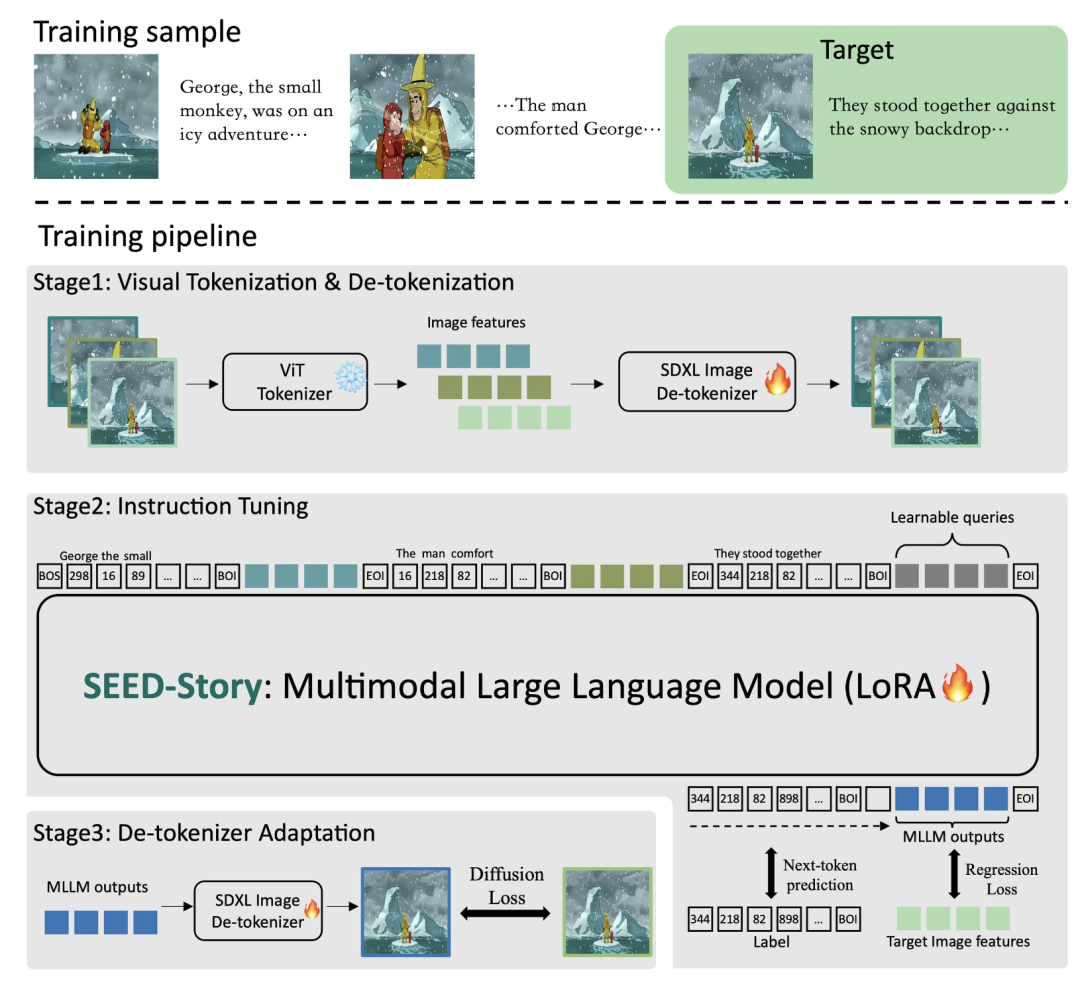
2️⃣ 特色功能
① 用户自定义故事起点:用户可以提供起始图像和文本,SEED-Story 据此生成故事。
② 多模态序列生成:故事可以包含多达 25 个多模态序列,尽管在训练中只使用了最多 10 个序列。

③ 视觉与文本的一致性:生成的图像与叙事文本在风格和角色上保持高度一致。

3️⃣ 如何部署
以下是使用 SEED-Story 生成多模态故事的基本步骤:
① 下载项目,依赖安装:确保 Python 环境(推荐使用Anaconda)和 PyTorch 等依赖项已安装。
git clone https://github.com/TencentARC/SEED-Story.git
cd SEED-Story
pip install -r requirements.txt② 数据准备:下载并准备 StoryStream 数据集,该数据集包含图像和对应的故事文本。
③ 模型权重下载:从 SEED-Story Hugging Face 下载预训练的分词器、去分词器和基础模型。
④ 推理过程:使用提供的脚本进行多模态故事生成和故事可视化。
SEED-Story 展示了大模型在多模态故事生成领域的潜力。无论是研究人员还是开发者,都可以利用这个工具探索和创造引人入胜的故事。
你可以在 GitHub 上搜索 SEED-Story 项目来访问该开源项目的主页。


















 749
749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









