









"与其停留在概念理论层面,不如动手去实现一个简单demo 。" ——鲁迅
前言
目前提供AI开发相关API接口的公司有很多,国外如微软、谷歌,国内的百度、腾讯等都有开放API接口。开发者只需要调用相关接口,几步就能开发出一个“智能APP”。通常情况AI接口有以下几类:
- 计算机视觉
图像分类、图像目标检测以及视频检测跟踪等等。这类API主要用于处理图像和视频,能够给图像打tag,并分析视频图片中的物体及其对应坐标轨迹等。
- 语言
包括自然语言处理,分析自然语言含义,评估情绪等,例如机器翻译等。
- 语音
将语言音频转换为文本,使用声音进行验证,或向应用添加说话人识别。
- 知识
通过映射复杂信息和数据来解决任务,例如智能建议和语义搜索。
基于Web Service的智能API接口让我们不需要了解复杂的机器学习以及数学知识就能轻松开发出智能APP。但是,本文将介绍如何完全自己动手去实现一个智能API接口服务,由于涉及到的东西非常多,本文仅以我比较熟悉的“计算机视觉”为例,包含“图像分类(image classification)”和“目标检测(target detect)”,之后如果有机会,我会介绍“视频轨迹跟踪”相关的东西,大概就是图像处理的升级版。在开始正文之前,先解释几个名词。AI的概念近一两年尤其火热,“机器学习”以及“深度学习”的技术介绍到处都是,这里再简单介绍一下我对它们的理解:
人工智能:
又名AI,概念出现得特别早,上世纪五六十年代就有。人工智能大概可以分为两大类,一类“强人工智能”,你可以理解为完全具备跟人类一样的思维和意识的计算机程序;第二类“弱人工智能”,大概就是指计算机能够完成大部分相对较高级的行为,比如前面提到的理解图片含义,理解语言含义以及理解语音等等。我们日常提到的人工智能通常指第二类,常见的有计算机视觉、语音识别、机器翻译、推荐系统、搜索引擎甚至一些智能美图的APP,这些都可以说使用了人工智能技术,因为它们内部都使用了相关机器学习或者深度学习的算法。
机器学习:
这个概念也出现得很早,大概上世界八九十年代(?)。以前的概念中,计算机必须按照人编写的程序去执行任务,对于程序中没有的逻辑,计算机是不可能去做的。机器学习出现后,计算机具备人类“掌握经验”的能力,在通过大量学习/总结规律之后,计算机能够预测它之前并没有见过的事物。
深度学习:
深度学习的概念近几年才出现,你可以理解为它是机器学习的升级。之所以近几年突然流行,是因为一些传统机器学习算法(比如神经网络)要想取得非常好的性能,神经网络必须足够复杂,同时需要大量的学习数据,这时计算能力遇到了瓶颈。而近几年随着硬件性能普遍提升,再加上互联网时代爆炸式的数据存储,训练出足够复杂的模型已经不再是遥不可及。因此,可以将深度学习理解为更复杂的机器学习方式。
好了,基本概念理清楚之后,开始进入正题了。这次我需要实现计算机视觉中的两大智能API接口:图片分类和目标检测。
技术和开发环境
下面是用到的技术和环境:
1)Python 3.5.2 (PIL、numpy、opencv、matplotlib等一些常见的库)
2)Tensorflow 1.8.0(GPU版本)
3)Keras 2.2.0 (backend是tensorflow)
4)Yolo v3(目标检测算法)
5)Windows 10 + Navida GTX 1080 显卡(需要安装cuda 和 cudnn)
6)VS Code 1.19.3
关于以上技术的介绍以及初次使用时的安装步骤,我这里不再多说了,网上教程很多,提示一下,初次安装环境,会有很多坑。一定要使用gpu版本的tensorflow,如果仅仅是自己搞着练练手,熟悉熟悉流程,安装cpu版本也行。
接口定义
好了,技术环境介绍完了之后,再把接口确定下来:
| 名称 | 接口 | 参数 | 返回 |
| 在线图片检测 | /detect/online | Method=POST online_image_url=url[string] | { “image”:”result_url”, “results”:[ { “box”:[left, top, right, bottom], “score”:score, “class”:class }, { “box”:[left, top, right, bottom], “score”:score, “class”:class } ... ], “time”:create_time, “type”:”online” } |
| 本地图片检测 | /detect/local | Method=POST local_image=file data[byte]
multipart/form-data | { “image”:”result_url”, “results”:[ { “box”:[left, top, right, bottom], “score”:score, “class”:class }, { “box”:[left, top, right, bottom], “score”:score, “class”:class } ... ], “time”:create_time, “type”:”local” } |
| 在线图片分类 | /classification/online | Method=POST online_image_url=url[string] | 还没完成 |
| 本地图片分类 | /classification/local | Method=POST local_image=file_data[byte]
multipart/form_data | 还没完成 |
写这篇博客的时候,图片分类的模型还没有训练好,所以暂时放一下,下次更新。以上四个接口分两类,一类是提交在线图片的url即可,二类是提交本地图片文件(表单上传)。两类都需要POST方式提交,返回结果是json格式,里面包含了处理之后的图片url(所有的结果已经绘制在上面了),还有处理的raw_data,客户端收到这些raw_data后可以自己用作其他地方。
目标检测
目标检测算法使用的是YOLO V3,这里是C语言实现的版本:http://pjreddie.com/darknet/ 。由于我比较熟悉Python,所以我用的是另外一个Python版本的实现(基于Keras),这里是Keras版本的实现:https://github.com/qqwweee/keras-yolo3。 如果想要训练更好的模型,需要自己准备数据集,源码中有一个我写的开源工具,专门用来标记这个框架所用的数据集(这个工具需要.net 4.0+)。

训练数据集使用的是微软的COCO数据集(https://github.com/cocodataset/cocoapi),这个也是C语言版本的默认数据集,你可以直接从官网上下载训练好的模型使用。
图片分类
待更新...
Web服务器
由于是Web API,那么你首先必须得有一个自己的Web Server。因为这是一个demo程序,所以没必要使用类似Django 、Flask这样的框架,于是索性就自己写一个吧。功能很简单,提供静态文件访问、以及可以处理我的API接口就行,写完核心代码大约200行(包含API接口处理的逻辑)。整个Web程序用到的模块大概有:http.server、PIL、urllib、io、uuid、time、json、os以及cgi。可以看到并不复杂。
整个Web Server的代码:
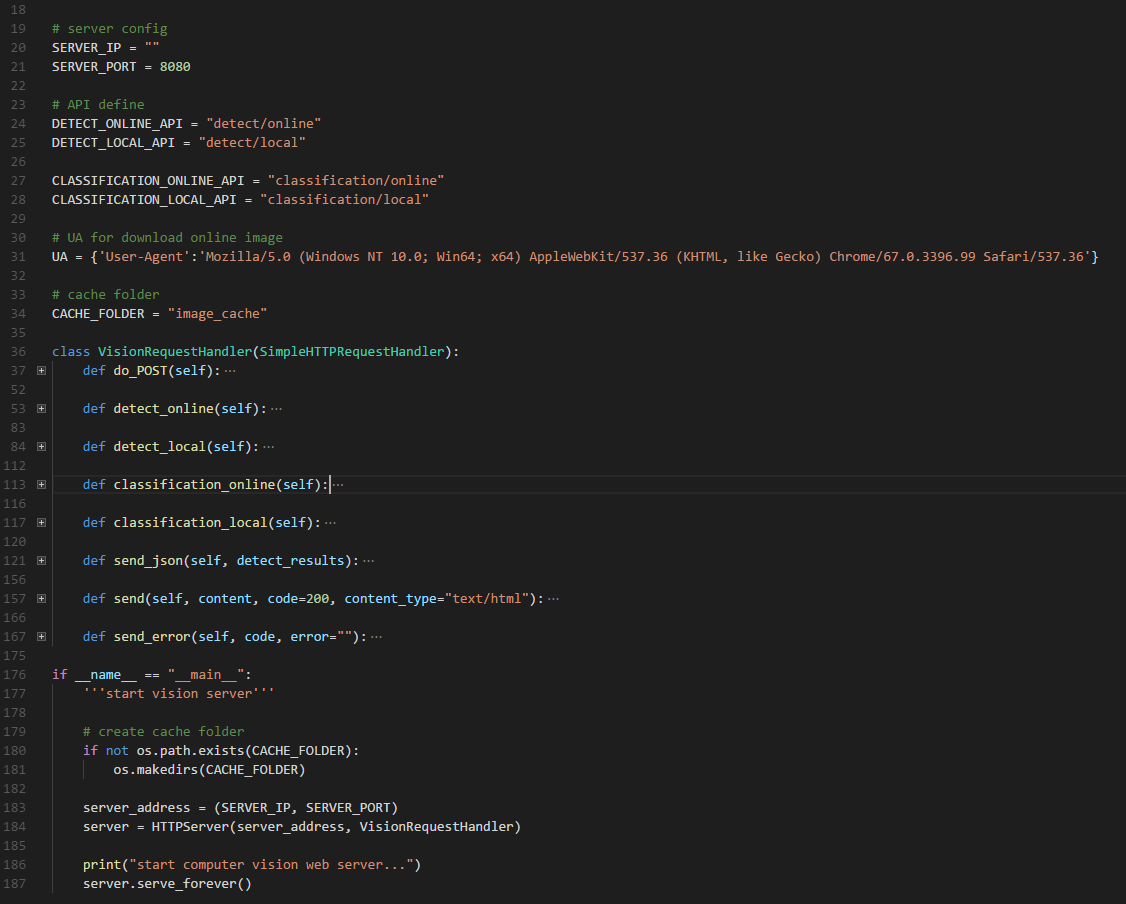
处理逻辑
从调用API接口到返回处理结果的流程相当简单,跟普通的HTTP请求一样,客户端发送HTTP请求,携带对象参数,Web Server在接收到数据后,开始调用计算模块,并将计算结果转换成json格式返回给客户端:
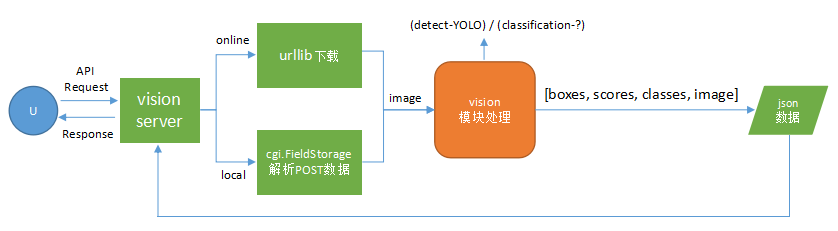
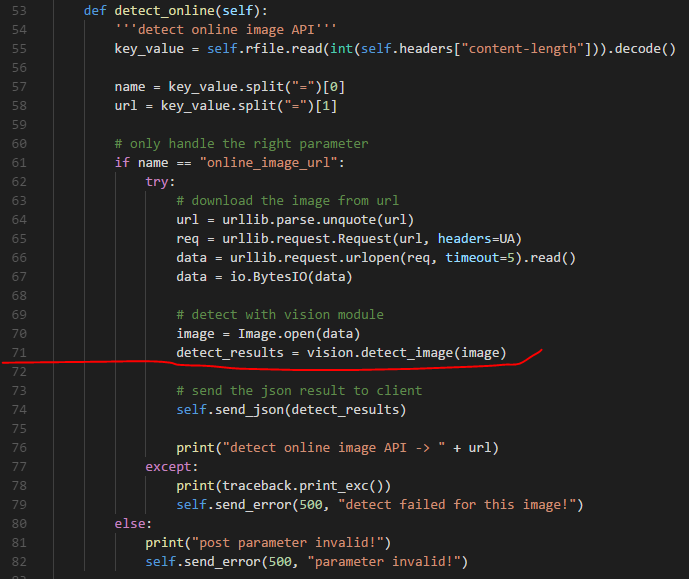
图中橙色部分为关键部分,详细实现请参见源码中的vision模块。
Demo效果
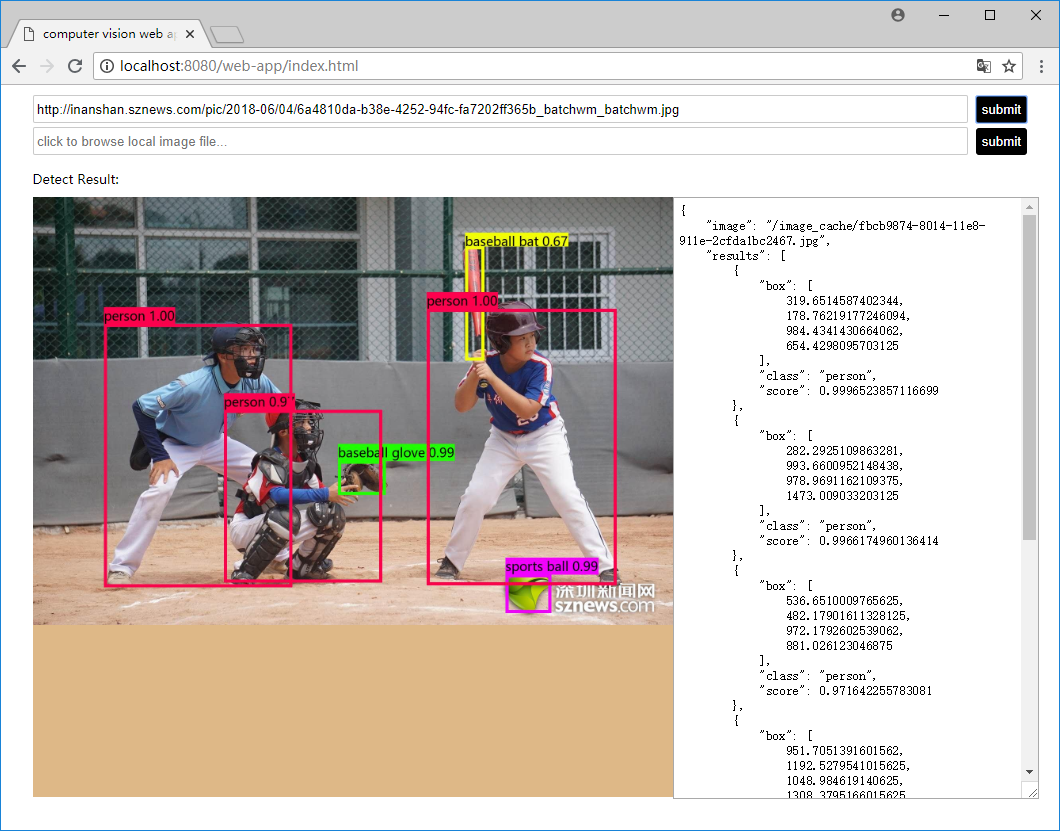
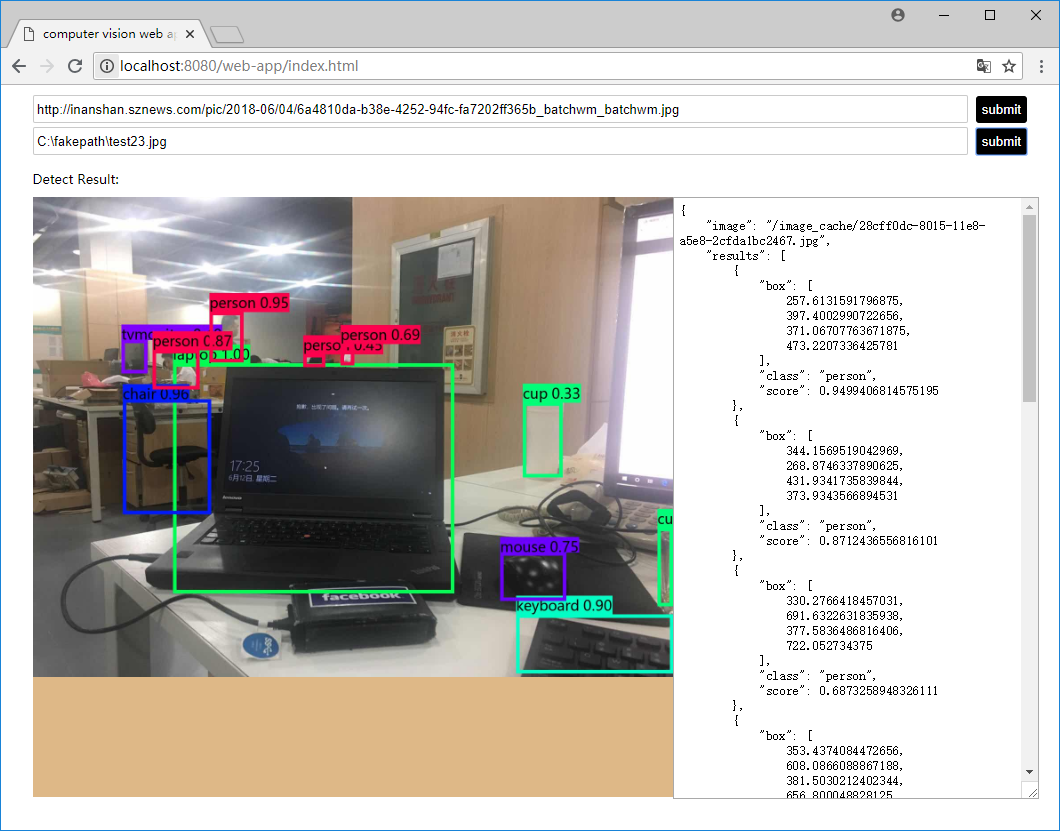
Demo中写好了一个静态html页面,运行python server.py后,在浏览中访问:http://localhost:8080/web-app/index.html即可看见测试页面。左边为处理之后的图片,右边为返回的json结果。

检测在线图片,在文本框中copy图片url,点击提交。
上传本地图片,点击提交。
与此同时,在控制台(或我自己的VS Code集成终端)中可以看到如下输出:

最开始是检测花费的时间,接着就是检测到的目标物体以及对应的坐标、分数等等。后面是转换之后的json字符串,最后客户端根据json中的url加载处理之后的图片。
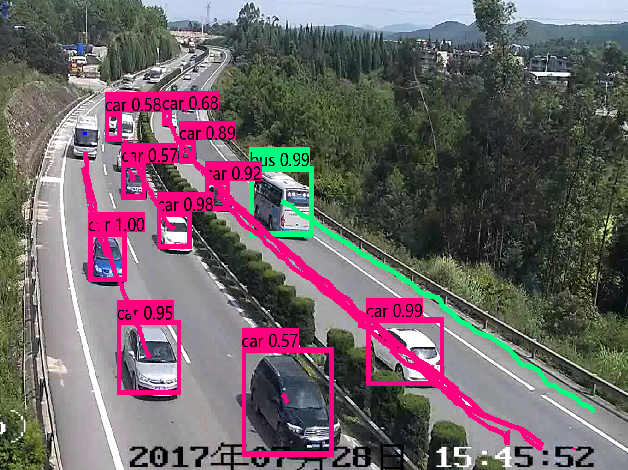
视频目标跟踪
这里稍微说一下跟视频有关的处理。对于视频来讲,它跟图片一样,由一张张图片组成,唯一的区别就是它具备时间的维度。我们不仅要检测每帧中的目标,还要判断前后帧之间各个目标之间的联系。然后利用目标物体的位移差来分析物体行为,对于路上车辆来讲,可以分析“异常停车”、“压线”、“逆行掉头”、“车速”、“流量统计”、“抛洒物”等数据。
关于机器学习
AI开发离不开机器学习(深度学习),而机器学习涉及到的知识相对来讲非常广泛,不仅仅要求开发者掌握好编程技能,还对数学知识有较高的要求。
我认为作为普通程序员,如果要学习AI开发,请用一种Top Down的方式,抛开晦涩难懂的数学理论,先找个适合自己的机器学习框架(比如tensorflow或者基于它的keras),学会如何准备训练数据集(比如本文中如何去标记图片?),如何训练自己的模型,然后用训练得到的模型去解决一些小问题(比如本文中的图像目标检测)。等自己对机器学习有一种具体的认识之后,经过一段时间的摸索,会自然而然地引导我们去了解底层的数学原理,这个时候再去搞清楚这些原理是什么。
个人认为,不要先上来就要搞懂什么是梯度下降优化法、什么是目标函数、什么是激活函数,什么是学习率...,这些概念确实需要掌握,但是不是你学习机器学习最开始的时候。另外学习机器学习,请使用Python。
计划下一篇介绍基于图片识别的视频自动分类,比如自动鉴黄等软件。














 2350
2350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









