










 文章介绍了KVCache在语言模型推理中的应用,通过缓存重复数据加速解码过程,提升了GPT-4等模型的推理速度。同时,分析了KVCache的显存占用,讨论了MultiQueryAttention和GroupedQueryAttention两种优化策略。
文章介绍了KVCache在语言模型推理中的应用,通过缓存重复数据加速解码过程,提升了GPT-4等模型的推理速度。同时,分析了KVCache的显存占用,讨论了MultiQueryAttention和GroupedQueryAttention两种优化策略。
原文:https://zhuanlan.zhihu.com/p/677660376
目录
收起
KV Cache 定义

KV Cache 原理
KV Cache 实现
KV Cache 显存占用分析
KV Cache 优化方法
在语言模型推理的过程中,性能优化一直是一个备受关注的话题。LLM(Large Language Models)的出现使得自然语言处理取得了显著的进展,但随之而来的是庞大的模型和复杂的计算过程,因此推理效率的提升变得至关重要。在这个背景下,KV Cache(键-值缓存)成为了一项被广泛应用的推理优化技术。
KV Cache 定义
KV Cache,即键-值缓存,是一种用于存储键值对数据的缓存机制。在语言模型的推理过程中,经常需要多次访问相同的数据,而KV Cache通过将这些数据缓存到内存中,提供了快速的数据访问速度,从而加速推理过程。该技术仅应用于解码阶段。如 decode only 模型(如 GPT3、Llama 等)、encode-decode 模型(如 T5)的 decode 阶段,像 Bert 等非生成式模型并不适用。
KV Cache 原理
推理过程:给定一个问题,模型会输出一个回答。生成回答的过程每次只生成一个 token,输出的 token会和问题拼接在一起,再次作为输入传给模型,这样不断重复直至生成终止符停止。
GPT-4推理过程图
下图是Scaled dot-product attention 有无 KV Cache 优化计算过程的比较。一般情况下,在每个生成步骤中,都会重新计算之前token的注意力,而实际上我们只想计算新 token 的注意力。而采用 KV Cache 方法后,会把之前 Token的 KV 值存下来,新 token 预测时只需要从缓存中读取结果就可以了。

Scaled dot-product attention 有无 KV Cache 比较,图片来源:https://medium.com/@joaolages/kv-caching-explained-276520203249
KV Cache 实现
huggingface的 transformer库已经实现了 KV cache,在推理时新增了past_key_values,设置 use_cache=True 或 config.use_cache=True 就可以了。
past_key_values(Cacheortuple(tuple(torch.FloatTensor)), optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.
import numpy as np
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "Llama-2-7b-chat-hf"
device = "cuda:7" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map=device)
for use_cache in (True, False):
times = []
for _ in range(10): # measuring 10 generations
start = time.time()
input = tokenizer("What is KV caching?", return_tensors="pt").to(device)
outputs = model.generate(**input, use_cache=use_cache, max_new_tokens=1000, temperature=0.00001)
times.append(time.time() - start)
print(f"{'With' if use_cache else 'Without'} KV caching: {round(np.mean(times), 3)} +- {round(np.std(times), 3)} seconds")执行结果如下所示:
With KV caching: 8.946 +- 0.011 seconds
Without KV caching: 58.68 +- 0.012 seconds从结果可以看出使用 KV Cache 方法进行大模型推理,推理速度增加了6.56倍,差异巨大。
KV Cache 显存占用分析
假设输入的序列长度是 𝑚,输出序列长度是 𝑛 , 𝑏 为数据批次大小, 𝑙 为层数, ℎ 为隐向量维度,以 FP16(2bytes) 来保存,那么 KV Cache的峰值显存占用大小为 𝑏(𝑚+𝑛)ℎ∗𝑙∗2∗2=4𝑏𝑙ℎ(𝑚+𝑛) ,第一个 2 代表 K、V,第二个 2 代表 2bytes。可见随着批次大小和长度的增加,KV Cache 的显存占用也会快速增大。
KV Cache 优化方法
这里主要介绍下 Multi Query Attention 和 Grouped Query Attention。
Multi Query Attention
Multi-query attention is identical except that the different heads share a single set of keys and values.
MQA 和 MHA的区别是:每个头共享相同的 K、V 权重而不共享Q的权重。
Grouped Query Attention
Grouped-query attention divides query heads intoG groups, each of which shares a single key head and value head.
分组注意力将查询头分为 G 组,每组共享一个键头和值头。GQA-G 是指有 G 组的分组查询。GQA-1,有一个组,因此有一个键头和值头,等同于 MQA,而 GQA-H,组数等于头数,等同于 MHA。
MHA、MQA、GQA比较可参考下图。
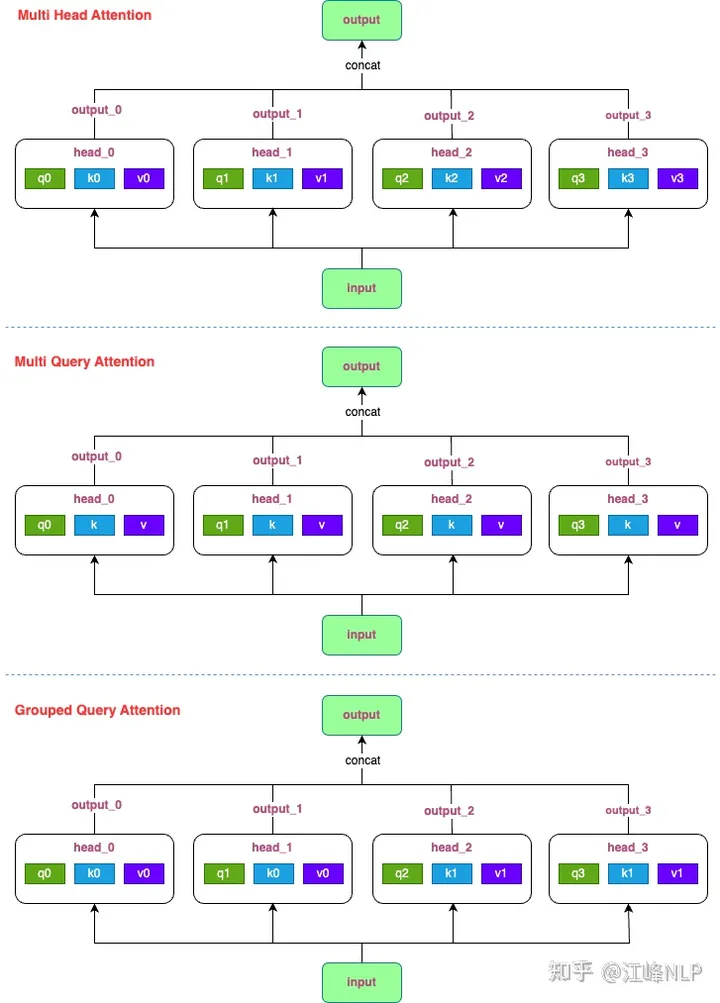
Multi Head Attention、Multi Query Attention、Grouped Query Attention 比较
使用MHA、MQA、GQA进行KV Cache 显存占用情况比较
MHA: 𝑏(𝑚+𝑛)ℎ∗𝑙∗2∗2=4𝑏𝑙ℎ(𝑚+𝑛) ;
MQA: 4𝑏𝑙ℎ(𝑚+𝑛)/𝐻 , 𝐻 代表头数;
GQA: 4𝑏𝑙ℎ(𝑚+𝑛)∗𝐺/𝐻 , 𝐻 代表头数, 𝐺 代表分组数;
MQA、GQA Huggingface 库都有实现,具体见llm_tutorial_optimization。
如果觉得本文对您有帮助,麻烦点个小小的赞,谢谢大家啦~
Transformers KV Caching Explained
Huggingface-llama2
Fast Transformer Decoding: One Write-Head is All You Need
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
编辑于 2024-01-16 21:52・IP 属地江苏

















 1942
1942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









