







网络结构图

YOLOv2采用了一个新的基础模型(特征提取器),称为Darknet-19,包括19个卷积层和5个maxpooling层,如上图所示。
Darknet-19与VGG16模型设计原则是一致的,主要采用 3x3 卷积,采用 3x3 的maxpooling层之后,特征图尺寸降低2倍,而同时将特征图的通道数channles翻倍
与NIN(Network in Network)类似,Darknet-19最终采用global avgpooling做预测,并且在 3x3 卷积之间使用 1x1 卷积来压缩特征图channles以降低模型计算量和参数。
Darknet-19每个卷积层后面同样使用了batch norm层以加快收敛速度,降低模型过拟合。
在ImageNet分类数据集上,Darknet-19的top-1准确度为72.9%,top-5准确度为91.2%,但是模型参数相对小一些。使用Darknet-19之后,YOLOv2的mAP值没有显著提升,但是计算量却可以减少约33%。
yolov2改进策略
Batch Normalization:每个卷积层后面都添加了Batch Normalization层,并且不再使用droput。使用后,YOLOv2的mAP提升了2.4%。
High Resolution Classifier:使用ImageNet(224->448)预训练模型,YOLOv2的mAP提升了约4%
Convolutional With Anchor Boxes;使用先验框,而不是grid cell网格.
在YOLOv1中,输入图片最终被划分为 7x7网格,每个单元格预测2个边界框。YOLOv1最后采用的是全连接层直接对边界框进行预测,其中边界框的宽与高是相对整张图片大小的,而由于各个图片中存在不同尺度和长宽比(scales and ratios)的物体,YOLOv1在训练过程中学习适应不同物体的形状是比较困难的,这也导致YOLOv1在精确定位方面表现较差。
YOLOv2借鉴了Faster R-CNN中RPN网络的先验框(anchor boxes,prior boxes,SSD也采用了先验框)策略。RPN对CNN特征提取器得到的特征图(feature map)进行卷积来预测每个位置的边界框以及置信度(是否含有物体),并且各个位置设置不同尺度和比例的先验框,所以RPN预测的是边界框相对于先验框的offsets值(采用先验框使得模型更容易学习。所以YOLOv2移除了YOLOv1中的全连接层而采用了卷积和anchor boxes来预测边界框。为了使检测所用的特征图分辨率更高,移除其中的一个pool层。
在检测模型中,YOLOv2不是采用 448x448 图片作为输入,而是采用 416x416 大小。因为YOLOv2模型下采样的总步长为2^5 = 32,对于 416 大小的图片,最终得到的特征图大小为 13 ,维度是奇数,这样特征图恰好只有一个中心位置。对于一些大物体,它们中心点往往落入图片中心位置,此时使用特征图的一个中心点去预测这些物体的边界框相对容易些。所以在YOLOv2设计中要保证最终的特征图有奇数个位置。
对于YOLOv1,每个cell都预测2个boxes,每个boxes包含5个值: [x,y,w,h,c] ,前4个值是边界框位置与大小,最后一个值是置信度(confidence scores,包含两部分:含有物体的概率以及预测框与ground truth的IOU)。但是每个cell只预测一套分类概率值(class predictions,其实是置信度下的条件概率值),供2个boxes共享。
YOLOv2使用了anchor boxes之后,每个位置的各个anchor box都单独预测一套分类概率值,这和SSD比较类似(但SSD没有预测置信度,而是把background作为一个类别来处理)。
使用anchor boxes之后,YOLOv2的mAP有稍微下降(这里下降的原因,我猜想是YOLOv2虽然使用了anchor boxes,但是依然采用YOLOv1的训练方法)。YOLOv1只能预测98个边界框( [公式] ),而YOLOv2使用anchor boxes之后可以预测上千个边界框( [公式] )。所以使用anchor boxes之后,YOLOv2的召回率大大提升,由原来的81%升至88%。
Dimension Clusters:使用数据集计算每个数据的集的先验框,使得模型更容易学习,从而做出更好的预测。
New Network: Darknet-19,参考下一个章节的网络结构。在ImageNet分类数据集上,Darknet-19的top-1准确度为72.9%,top-5准确度为91.2%,但是模型参数相对小一些。使用Darknet-19之后,YOLOv2的mAP值没有显著提升,但是计算量却可以减少约33%。
yolov2的网络定义

将darknet-19的网络结构划分4块,其中第3块和第4块分别对应输出为[26x26, 13x13]的输出头
125 = anchors_num*(5+cls_num) = 5x25 = 125,其中5个预测值分别表示[tx,ty,tw,th,score]
tx,ty:就是预测边界框中心点相对于对应cell左上角位置的相对偏移值,为了将边界框中心点约束在当前cell中,使用sigmoid函数处理偏移值,这样预测的偏移值在(0,1)范围内(每个cell的尺度看做1)
tw,th:预测框的大小,是相对于anchor框的大小的
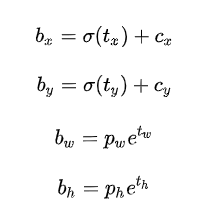
总结来看,根据边界框预测的4个offsets [tx,ty,tw,th] ,可以按如下公式计算出边界框实际位置和大小:
其中 [cx,cy] 为cell的左上角坐标,坐标大小是相对与特侦图(13x13)而言的,宽和高的范围是[0, 12]。如图5所示,在计算时每个cell的尺度为1,所以当前cell的左上角坐标为 [1,1] 。由于sigmoid函数的处理,边界框的中心位置会约束在当前cell内部,防止偏移过多。而 [pw] 和 [ph] 是先验框的宽度与长度,前面说过它们的值也是相对于特征图大小的,在特征图中每个cell的长和宽均为1。这里记特征图的大小为 [1] (在文中是 [W,H] ),这样我们可以将边界框相对于整张图片的位置和大小计算出来(4个值均在0和1之间):
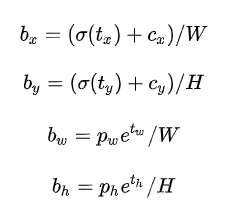
如果再将上面的4个值分别乘以图片的宽度和长度(像素点值)就可以得到边界框的最终位置和大小了。这就是YOLOv2边界框的整个解码过程。约束了边界框的位置预测值使得模型更容易稳定训练,结合聚类分析得到先验框与这种预测方法,YOLOv2的mAP值提升了约5%。
backbone的代码设计如下
#_darknet19.py
# Network
layer_list = [
OrderedDict([
('1_convbatch', vn_layer.Conv2dBatchLeaky(3, 32, 3, 1)),
('2_max', nn.MaxPool2d(2, 2)),
('3_convbatch', vn_layer.Conv2dBatchLeaky(32, 64, 3, 1)),
('4_max', nn.MaxPool2d(2, 2)),
('5_convbatch', vn_layer.Conv2dBatchLeaky(64, 128, 3, 1)),
('6_convbatch', vn_layer.Conv2dBatchLeaky(128, 64, 1, 1)),
('7_convbatch', vn_layer.Conv2dBatchLeaky(64, 128, 3, 1)),
]),
OrderedDict([
('8_max', nn.MaxPool2d(2, 2)),
('9_convbatch', vn_layer.Conv2dBatchLeaky(128, 256, 3, 1)),
('10_convbatch', vn_layer.Conv2dBatchLeaky(256, 128, 1, 1)),
('11_convbatch', vn_layer.Conv2dBatchLeaky(128, 256, 3, 1)),
]),
OrderedDict([
('12_max', nn.MaxPool2d(2, 2)),
('13_convbatch', vn_layer.Conv2dBatchLeaky(256, 512, 3, 1)),
('14_convbatch', vn_layer.Conv2dBatchLeaky(512, 256, 1, 1)),
('15_convbatch', vn_layer.Conv2dBatchLeaky(256, 512, 3, 1)),
('16_convbatch', vn_layer.Conv2dBatchLeaky(512, 256, 1, 1)),
('17_convbatch', vn_layer.Conv2dBatchLeaky(256, 512, 3, 1)),
]),
OrderedDict([
('18_max', nn.MaxPool2d(2, 2)),
('19_convbatch', vn_layer.Conv2dBatchLeaky(512, 1024, 3, 1)),
('20_convbatch', vn_layer.Conv2dBatchLeaky(1024, 512, 1, 1)),
('21_convbatch', vn_layer.Conv2dBatchLeaky(512, 1024, 3, 1)),
('22_convbatch', vn_layer.Conv2dBatchLeaky(1024, 512, 1, 1)),
('23_convbatch', vn_layer.Conv2dBatchLeaky(512, 1024, 3, 1)),
# the following is extra
('24_convbatch', vn_layer.Conv2dBatchLeaky(1024, 1024, 3, 1)),
('25_convbatch', vn_layer.Conv2dBatchLeaky(1024, 1024, 3, 1)),
]),
]
如yolov2的网络定义图所示,backbone的第2,3,4网络结构,分别输出[52x52, 26x26, 13x13]的特征图
layers = net.backbone.layers
forward:
test_images = torch.rand(1,3,416, 416)
stem = layers[0](test_images)
# print("stem:{}".format(stem.shape))
stage4 = layers[1](stem)
stage5 = layers[2](stage4)
stage6 = layers[3](stage5)
middle_feats = [stage6, stage5, stage4]
stage6.shape,stage5.shape,stage4.shape
output:
torch.Size([1, 1024, 13, 13])
torch.Size([1, 512, 26, 26])
torch.Size([1, 256, 52, 52]))
head的设计

layer_list = [
# Sequence 2 : input = sequence0
OrderedDict([
('1_convbatch', vn_layer.Conv2dBatchLeaky(512, 64, 1, 1)),
('2_reorg', vn_layer.Reorg(2)),
]),
# Sequence 3 : input = sequence2 + sequence1
OrderedDict([
('3_convbatch', vn_layer.Conv2dBatchLeaky((4*64)+1024, 1024, 3, 1)),
('4_conv', nn.Conv2d(1024, num_anchors*(5+num_classes), 1, 1, 0)),
]),
]
printinfo:
ModuleList(
(0): Sequential(
(1_convbatch): Conv2dBatchLeaky (512, 64, kernel_size=1, stride=1, padding=0, negative_slope=0.1)
(2_reorg): Reorg (stride=2, darknet_compatible_mode=True)
)
(1): Sequential(
(3_convbatch): Conv2dBatchLeaky (1280, 1024, kernel_size=3, stride=1, padding=1, negative_slope=0.1)
(4_conv): Conv2d(1024, 125, kernel_size=(1, 1), stride=(1, 1))
)
)
head0:将backbone 第13曾卷积程的512个通道的输出,转化程64个通道的输出,然后通过Reorg层转化成[256, 13,13]的输出,以便于与backbone最后13x13的特征图进行合并
head0输出:
torch.Size([1, 1280, 13, 13]))
head1:负责将1280+256个通道降低为1024个通道,然后降低为num_anchors*(5+num_classes)=5*(20+5)=125个通道
head1输出为:
torch.Size([1, 125, 13, 13])
















 4344
4344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









