









这一段要在文件系统中对文件的记录增加索引。实现思路是借鉴了i_zone的三级间接寻址方案。i_zone实际上代表了3层意思,第一层是i_zone这个数组本身,它是放在episode_inode中的,只要拿到了episode_inode的指针或者对象,就可以直接访问;第二层,i_zone[0]--i_zone[9]的内容(就是一个blockid)所代表的那9个block、i_zone[7]-i_zone[9]指向的block里面存储的blocksize/4个blockid所代表的那blocksize/4个block、i_zone[8]-i_zone[9]指向的那个block里面存储的blocksize/4个block里面存储的(blocksize/4)^2个block,以及i_zone[9]指向的那个block里面存储的blocksize/4个block里面存储的(blocksize/4)^2个block里面存储的(blocksize/4)^3个blockid,这一部分内容是由bufferecache进行管理的,在每次进行读写直线,先使用类似的sb_bread(sb,blockid)的方式(放回一个buffere_head的指针)读到内存中,然后通过buffer_head的bdata获得对应的buffer cache地址,然后就可以对buffere cache开始的那段内存区域进行读写等;第三层,i_zone[0]-i_zone[6]指向的blockid所对应的磁盘block中存储的内容、i_zone[7]指向的block里面存储的blocksize/4个blockid所对应的blocksize/4个磁盘block中所存储的内容,i_zone[8]所指向的那个block所存储的blocksize/4个blockid所对应的blocksize/4个block所存储的(blocksize/4)^2个blockid所对应的(blocksize/4)^2个磁盘block所存储的内容,以及i_zone[9]所指向的那个1个block所存储的(blocksize/4)个blockid所对应的blocksize/4个磁盘block所存储的(blocksize/4)^2个blockid所对应的(blocksize/4)^2个磁盘block所存储的(blocksize/4)^3个bockid所对应的(blocksize/4)^3个block所存储的内容,这就是文件的内容,它们是由pagecache进行管理的,在文件读写之前,会先根据要读写的位置,从inode所对应的文件基树中查找对应的page,如果找不到,则读盘并放入page cache,如果找到则返回。
在实现的过程中,由于文件的数据是使用page cache进行读写缓存的,但因为索引数据因为参考了i_zone的设计和实现,而i_zone管理的那些用于存储blockid的那些block本身却没有使用page cache进行管理,而是使用了buffer_head了进行管理。而i_index的第一层是由inode进行直接管理,第二层可以参考i_zone采用buffer cache进行管理,但第三层,如果要参考i_zone的第三层,则需要再在inode中增加一个address_space对象,用于管理index的内容,这个难度有点大。如果我们第三层参考第二层采用buffere_ cache难度会小不少。
另外,如果按照最初的想法,把索引数据作为文件内容的一部分进行管理,如果能成功,则索引可以直接放到pagecache中。首先对于查询的过程,传入的是查询条件,我们可以写一个查询接口,这个接口只对接i_index。如果采用page cache的话,那i_index中应保留对应的块相对于文件开头的偏移量,这样才能调用read接口把对应block存储的索引内容放到page cache中,那么不放偏移量,只放blockid行吗?不行,因为目前文件的内容采用基树进行管理,它是根据偏移量来计算内容属于应该属于哪个page,然后去找这个page是否在page cache中。假如目前索引数据已经读到了page cache,那后面就可以检索得到数据的起始位置和大小了。用户根据起始位置和大小,就可以读数据了。读一般来说比较简单,改吧改吧好实现。
现在说写。第一次写入数据的时候,因为采用page cache,我们要申请2个page,而i_size=0,minix文件系统不支持洞,它判断你查找的位置超过i_size,直接就不干了。当然,你可以改,假如我们申请到了2个page,page p1对应的blockid放到了i_zone[0],page p2对应的blockid放到了i_index[0],这一步能实现。3k的用户数据过来了,根据i_size的位置得到游标,数据写入到了p1,然后更新i_size为3k,现在要写索引了,索引长16字节,写入的位置应该是4k(超过了i_size),目前的机制是不允许洞文件的存在的,假如也改了,支持洞,那就写吧。第一条数据和索引写入成功,p1的内容是数据,p2的数据是占4个字节的表示偏移量的4096和16字节的索引内容。后面继续写,因为很难保证数据和索引同时能填满block。假如后面又来了3k的数据,此时i_size=3k,那么第二条数据的前1k写入到p1,然后落盘,此时i_size=4k,后面2k数据应当从4096字节开始写,经过线性地址解算,发现4096-8191对应的 block已经分配了,只不过用于存储了索引内容,如果直接写,那就把索引数据覆盖掉了。那第二条的数据的后2k就写8k-12k 这个block吧,怎么跳过去呢?也就是要申请一个新的page p3,要写入的位置是8096(这个假如可以通过i_size和i_indexsize来计算出来),然后把它放到page cache中接收2k字节,然后更新i_size为6k还是10k呢?如果是6k,那后面再解算地址的时候,写索引数据就会出错(它会写到第二条数据对应的block p3中),那就为10k吧,可以正常写入数据和索引。后面又写了很多条,假如到了某个时刻,p2终于写满了,这时候i_size假设为25k,对应的page 为p7,这时候又写入2k的数据,i_size变成了27k,写完之后,该写索引了,因为p2终于写满了,我们要申请1个新的page,假如为p8,这时候就需要i_size怎么办?改成28k,就可以正常解算,将索引数据写入到2k开始的位置(此时p8内容为4个字节表示的28k和16个字节的索引),没问题。后面又来了一条数据,500字节,根据i_size计算要写入的位置,此时i_size=32k+20字节,而实际上应当写入到27k这个位置,但是我们回不去了,按照前面的逻辑,只能新申请1个page p9来存储新来的500字节的数据,那这么下去,记录索引数据的page之前的page可能不是满的,这样下去,会不会出问题?我没有进行详细的思考,有索引的存在,可能没有问题。对于顺序读,按照现行的逻辑,会有问题,为啥,因为采用了一个线性地址解析,当你从3k位置开始读取3k字节的时候,它会把p1的1k内容拿出来,并把p2的2k拿出来,而实际上,它应该返回p1的1k和p3的2k,也就是线性地址空间的3k-4k以及8k-10k。这套方案也是可做的,但是难度可能会比第一种大一些。
Page cache和buffer cache一直以来是两个比较容易混淆的概念,在网上也有很多人在争辩和猜想这两个cache到底有什么区别,讨论到最后也一直没有一个统一和正确的结论,在我工作的这一段时间,page cache和buffer cache的概念曾经困扰过我,但是仔细分析一下,这两个概念实际上非常的清晰。如果能够了解到这两个cache的本质,那么我们在分析io问题的时候可能会更加得心应手。
Page cache实际上是针对文件系统的,是文件的缓存,在文件层面上的数据会缓存到page cache。文件的逻辑层需要映射到实际的物理磁盘,这种映射关系由文件系统来完成。当page cache的数据需要刷新时,page cache中的数据交给buffer cache,但是这种处理在2.6版本的内核之后就变的很简单了,没有真正意义上的cache操作。
Buffer cache是针对磁盘块的缓存,也就是在没有文件系统的情况下,直接对磁盘进行操作的数据会缓存到buffer cache中,例如,文件系统的元数据都会缓存到buffer cache中。
简单说来,page cache用来缓存文件数据,buffer cache用来缓存磁盘数据。在有文件系统的情况下,对文件操作,那么数据会缓存到page cache,如果直接采用dd等工具对磁盘进行读写,那么数据会缓存到buffer cache。
Page cache是vfs文件系统层的cache,例如 对于一个ext3文件系统而言,每个文件都会有一棵radix树管理文件的缓存页,这些被管理的缓存页被称之为page cache。所以,page cache是针对文件系统而言的。例如,ext3文件系统的页缓存就是page cache。Buffer cache是针对设备的,每个设备都会有一棵radix树管理数据缓存块,这些缓存块被称之为buffer cache。通常对于ext3文件系统而言,page cache的大小为4KB,所以ext3每次操作的数据块大小都是4KB的整数倍。Buffer cache的缓存块大小通常由块设备的大小来决定,取值范围在512B~4KB之间,取块设备大小的最大公约数。具体关于buffer cache的块大小问题可以参见博文《Linux中Buffer cache性能问题一探究竟》。
这里我们可以通过一个小实验来观察一下buffer cache和page cache的差别。运行top命令,我们可以看到实验机器当前内存使用情况:
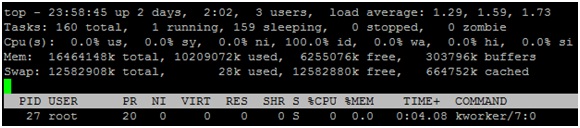
可以看出内存总容量为16GB左右,page cache用了将近10GB(10209072K-303796K),buffer cache用了300MB(303796K),其余6GB(6255076K)空闲剩余。在这种情况下,如果对设备dm0进行裸盘写操作,即运行如下命令:
dd if=/dev/zero of=/dev/dm0 count=4096
那么,我么可以通过top命令发现,buffer cache的容量越来越大,空闲内存越来越少,相当一部分内存被buffer cache占用,并且在IO操作的过程中发现bdi(flush-254:176)线程在繁忙的进行数据回刷操作。
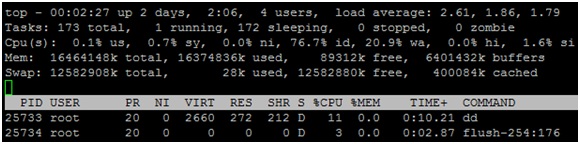
经过一段时间以后,大约6GB(6401432KB)的内存被buffer cache占用,89MB(89312KB)内存空闲,其余大约10GB(16374836KB - 6401432KB)的内存还是被page cache占用。通过这个实验,可以说明对于裸盘的读写操作会占用buffer cache,并且当读写操作完成之后,这些buffer cache会归还给系统。为了验证page cache的占用情况,我做了文件系统级的读写操作,运行如下命令进行文件系统写操作:
cp /dev/zero ./test_file
这是一次文件拷贝操作,因此会采用page cache对文件数据进行缓存。通过top工具我们可以看出在数据拷贝的过程中,page cache的容量越来越大,空闲内存数量急剧下降,而buffer cache保持不变。

拷贝一定时间之后,空闲内存将为1.9GB(1959468KB),文件系统page cache增长为将近14.5GB(14504680KB – 235108KB),buffer cache维持在235MB左右(235108KB)。
由此我们可以得出,page cache和buffer cache最大的差别在于:page cache是对文件数据的缓存;buffer cache是对设备数据的缓存。两者在实现上差别不是很大,都是采用radix树进行管理。
参考文献:
https://blog.51cto.com/alanwu/1122077















 1557
1557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









