






前言
视觉重定位是一个较为独立的研究方向,目前主要的方法分为基于深度学习,基于随机森林的,和基于传统特征点匹配的三种。对于深度学习的方法,越来越重视对位姿的精确回归。
摘要
相机重定位是一个重要但是仍然具有挑战的问题。最近,基于检索的方法被认为是一个具有潜力的方向,因为其能够较为容易地泛化到新的场景中。尽管许多方法被提出,但是这些方法性能瓶颈仍然在于检索模块。这些方法使用相同的特征用于检索和相对位姿回归的任务,然而这两种任务对于特征性能的需求是不一致的。To this end,本文提出了一种coarse-to-fine的基于检索的深度学习框架,包括三个步骤:基于图像的粗检索,基于位姿的精细检索,以及精确的相对位姿回归。
引言
传统的几何方法采用手工图像特征寻找图像之间的特征点对应,然后基于这些对应关系对相机位姿进行恢复。但是,这些方法在弱纹理、光照变化,遮挡,重复结构场景下性能不足。同时,计算代价较高。最近,基于机器学习的算法被用于解决重定位问题。基于随机森林的方法建立2D-3D的对应关系以对相机位姿进行恢复,并通过RANSAC方法进行优化求解。
在基于深度学习的方法中,这些模型利用深度网络的表达能力对场景进行记忆。但是,这意味着他们在新场景下必须被重新训练,限制了他们的泛化能力。其他类型的深度学习方法构建了一个数据库,包括了目标场景的图像特征及其对应的真实世界位姿。对于给定的检索图像,其首先在数据库中检索最相似的图像,然后对相对位姿变换进行预测。但是,之间检索到最优的匹配是困难的,不好的匹配会降低后面的相对位姿回归的性能。本文采用同样的框架,但是使用了一个新的coarse-to-fine策略逐渐靠近最优的检索结果。
在本文中,我们提出了一个coarse-to-fine基于检索框架的图像定位方法。我们的框架具有和基于检索模型相同的泛化能力,能够获得与2d-3d匹配模型一致的精度。之前的检索的方法使用相同的特征在图像检索和位姿回归中。但是,我们认为这是不合理的,因为图像检索模型应该主要学习场景的相似性并且忽略相机之间的轻微角度变化,而位姿回归模型需要对视角变化较为敏感。因此,两个任务使用相同的特征会带来潜在的冲突。为了解决这个问题,我们设计了一个Siamese框架,包括三个分支,基于图像的粗检索,基于位姿的精细检索,和相对位姿回归。只有编码器在三个分支中是共享的。三个任务可以以端到端的方式被共同的学习。
本文的贡献入下:(1)我们提出了一个coarse-to-fine的框架,具有较高的可扩展性和精度。(2) 我们提出了信息检索损失和二阶段检索,提升重定位的精度。(3) 我们证明了所提出方法的可泛化性。
相关工作
相机重定位方法主要分为三种:基于2D-3D匹配的定位,metric localization,基于图像检索的定位。
2.1 2D-3D匹配定位
在每个RANSAC循环中,利用PNP对获得的2D-3D点进行位姿求解。
相比显示的特征匹配,一些方法使用CNN或者随机森林进行隐士的场景表达,然而这些方法在处理大范围场景下可能会失效。
但是,上述的方法基于3D模型,其存储代价和计算代价都较高。
2.2 Metric Localization
该类方法以对相机的位姿和朝向进行回归为目标。比如,PoseNet。
该类方法在特征较少的室内场景较为有效,但是需要在特定的场景下进行学习。而本文的方法具有较高的可扩展性和弹性。
2.3 基于图像检索的定位
本文方法
我们模型的输入是一个成对图像的集合,我们的模型包括三个modules,基于图像的粗检索模块,基于位姿的精细检索模块,精确的位姿回归模块,所有的这些模块共享一个编码网络。
我们设计了一个二阶段的检索框架。给定一个检索图像,我们首先使用ICR模块执行一个最近邻搜索在数据库中找到一个最相似的图像。然后,我们使用PFR模块获得粗糙的相机位姿估计。然后使用PRP模块进行精确的位姿估计。
3.1 基于图像的粗糙检索模块
本文的思想是图像间的重叠区域越大,其对位姿回归的有效性就越高。重叠区域适合用于学习pose-specific特征描述子。本文考虑双向的相机重叠,可以较好的处理大范围的运动。然而,我们发现有些具有较高重叠区域的图像是从相反的方向获取的,具有较大的相对旋转,很难利用深度学习模型进行预测。为了解决这个问题,我们提出了一个batch hard-sample mining strategy by combing a hard triplet loss and an angle-based auxiliary loss.
3.1.1 Bilateral Frustum Loss
基本的思想上,对于一对图像,将其中一个图像观测到的空间点投影到另外一个图像平面,看能够被另外一个图像观测到的空间点所占的比例。基于该比例,构造损失函数,并针对RGBD室内图像和室外RGB图像设计了不同的重叠度计算方法。

3.1.2 基于角度的损失
由于相机视区的重叠对朝向不敏感,我们采用了另外一种角度损失函数,(注意这里的设计,主要就是为了使得输入的图像能够找到位姿相近的图像)

3.1.3 Hard Triplet Loss
通过对朝向角的学习,相机重叠方法的弱点能够被弥补。为了进一步提高相机检索的精度,我们介绍了一种a batch hard sampling with a hard-triplet loss。
具体地,对于训练集中每个anchor图像,我们随机的将其和其他图像组合成图像对。然后,我们根据他们的重叠区域以及相对旋转角和位移将所有的图相对划分为三种类型,容易,中等,以及困难。
我们的目标是实现从容易类别中获取的图像对的距离相较于从中等类别中获取的图相对小,从中等类别中获得的图相对相较于困难图相对的距离小。损失函数如下
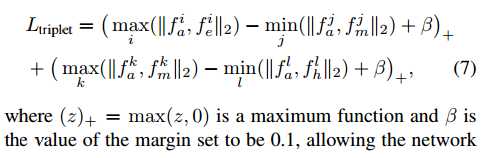
也就是说,在easy中最大的距离也要小于在moderate中国最小的距离。
3.2 Pose-based Fine Retrieval Module
使用RGB图像很难对相机的位移和朝向进行精确地估计,但是本文发现基于一个精确的检索系统,相对位姿的回归任务能够变得简单。

首先基于检索的方法获取图相对,输入到位姿回归模块中。
3.3 Precise Relative Pose Regression Module
通过使用检索模块,降低了相对位姿的回归空间,所以简化了位姿回归的任务。PRP相比于PRP使用了不同的核函数,
3.4 推理阶段
我们首先建立一个数据库,由训练集和的关键帧组成。对于每个真实位姿,我们存储其对应的ICR,PFR,PRP的输出特征。推理过程如下:
(1) 给定一个查询图像,以及ICR输出的其特征表达,在数据库中找到K个最近邻。
(2) 得到PRF模块输出的关于查询帧的特征,找到最近邻的K个特征表达,连接起来输入到PFR中,进行粗糙的位姿估计。
(3) 对于每个估计的位姿,我们检索到最近的位姿作为新的参考位姿。

本文的方法具有一定的泛化性,是因为,在训练过程中没有显示的利用绝对的世界坐标。但是泛化能力仍然是有限的。















 3545
3545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









