







目录
1. 异常: c10::Error,位于内存位置 0x000000B9DA0FF2E0 处
2. CUDA error: invalid device ordinal
3. cu:108: block: [0,0,0], thread: [1,0,0] Assertion `t >= 0 && t < n_classes` failed.
4. 引发了异常: 读取访问权限冲突。this->_Vec._Mypair._Myval2.**_Myfirst** 是 0x111011101110123。
5. 报错位置:return impl_->forward(::std::forward(args)...)
6. 报错位置:// Copy `key` here and move it into the index.
7. E0266 at::Scalar不明确,at::Allocator不明确
10. 重写编译代码成dll后,调试源程序提示当前不会命中断点,追踪不了源程序。
13. 报错位置:{torch::stack(data), torch::stack(targets)}
14. 错误 C2243 “类型强制转换”: 从“const Contained *”到“const torch::nn::Module &”的转换存在
1. 异常: c10::Error,位于内存位置 0x000000B9DA0FF2E0 处
(1)维度不对,操作范围了。卷积操作和全链接操作直接少了一个展平操作,即将特征图(b,c,h,w)展开成(b, c*h*w);
x = torch::flatten(x, 1); // start_dim = 1. (b, c*7*7)(2) 异常: c10::Error,位于内存位置 0x000000CC4BEFDB70 处。错误原因:在gpu上训练后,在cpu上测试,正确操作:
img_tensor = img_tensor.to(torch::kCUDA)2. CUDA error: invalid device ordinal
CUDA error: invalid device ordinal
Exception raised from exchangeDevice at C:\w\b\windows\pytorch\c10/cuda/impl/CUDAGuardImpl.h:31 (most recent call first):
00007FFAAB5CF84A00007FFAAB5CEBE0 c10.dll!c10::detail::LogAPIUsageFakeReturn [<unknown file> @ <unknown line number>]
00007FFAAB5CF4BA00007FFAAB5CEBE0 c10.dll!c10::detail::LogAPIUsageFakeReturn [<unknown file> @ <unknown line number>]
00007FFAAB5D023100007FFAAB5CEBE0 c10.dll!c10::detail::LogAPIUsageFakeReturn [<unknown file> @ <unknown line number>]
00007FFAAB5CFFC500007FFAAB5CEBE0 c10.dll!c10::detail::LogAPIUsageFakeReturn [<unknown file> @ <unknown line number>]原因,使用了错误的显卡序号,1号卡是失效的,改成0号卡即可:
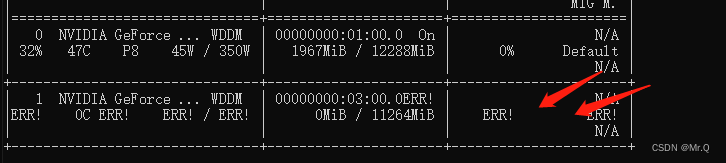
3. cu:108: block: [0,0,0], thread: [1,0,0] Assertion `t >= 0 && t < n_classes` failed.
报错的地方: loss.backward().
报错的原因:目标类别数是2,但是标注的类别是1,2,应该是从0开始,即标注类别是0和1,这样就符合t>= && t<n_classes,其中t是标注类别。
4. 引发了异常: 读取访问权限冲突。
this->_Vec._Mypair._Myval2.**_Myfirst** 是 0x111011101110123。
场景:使用libtorch注册机制,register_module("conv1", conv1)
报错原因:注册机制支持release模型,debug模型会报错
编译时,改成release问题解决
5. 报错位置:return impl_->forward(::std::forward<Args>(args)...)
部分原因:data放到了cuda中,model子模块没有在cuda中。
mainModel.to(torch::kCUDA). 但是因为mainModel的子模块或者子模块的子模块没有使用register_module()函数注册,导致只有主函数会放置到cuda中,其子模块不会放置cuda中,导致莫名奇妙的错误。
其他原因也会导致此处出错。
异常: c10::Error,位于内存位置 0x0000009F715DA580 处。
6. 报错位置:// Copy `key` here and move it into the index.
报错位置:
// Copy `key` here and move it into the index.
items_.emplace_back(key, std::forward<V>(value));
index_.emplace(std::forward<K>(key), size() - 1);原因: register_module注册时使用相同的类别名注册了不同的module。
register_module("model1", conv1);
register_module("model1", conv2);
解决办法:不同的模块也写不同的模块名称。
7. E0266 at::Scalar不明确,at::Allocator不明确
报错位置:using namespace cv;
报错原因:opencv和libtorch命名冲突,libtorch和opencv命名空间下都用Scalar。
解决办法:注释using namespace cv,改用cv::Mat加前缀形式,明确使用哪个库。
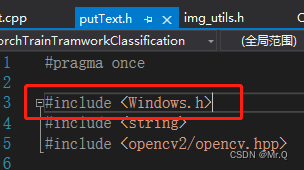
8. 语法错误:意外标记”(",应为ID表达式
错误详情:语法错误:”<parameter-list“ "{"的前面有意外标记;跳过明显的函数体
语法错误:”(“
解决办法:自己写的头文件中包含了#include <Windows.h>系统头文件,引用系统头文件和包含了系统头文件的头文件时都放在第一行位置。
9. Unknown exception
错误详情:resnet->(torch::kCUDA),报错:Unknown exception
解决办法:vs2019 属性->链接器->命令行,输入:
-INCLUDE:?warp_size@cuda@at@@YAHXZ
调试技巧:
auto tmp = resnet->modules();
torch::OrderedDict<std::string, at::Tensor> model_dict = resnet->named_parameters();
for (auto i = 0; i < tmp.size(); i++)
{
std::cout << model_dict[i].key().c_str() << std::endl;
tmp[i]->to(torch::kCUDA); // 查看是那一层出错
}10. 重写编译代码成dll后,调试源程序提示当前不会命中断点,追踪不了源程序。
原因:vs配置问题或者源程序发生改变
解决办法:如果是源程序发生改变,则重新编译即可,如果不是则应该是vs配置问题,修改如下。
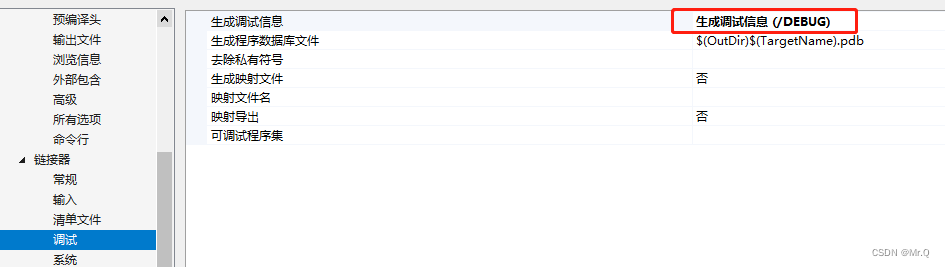
配置->c/c++ -> 常规 -> 调试信息格式:设置成程序设计库zi
配置->链接器->调试->生成调试信息->DEBUG.

11. 推理同一张图片,结果有差异
问题:同一张图片,用相同模型推理,最后的会有差异。
原因:原因会有很多种,我这里的原因是c++编写的模型中,有个dropout层没有使用register_module("dropout", dropout)注册,导致推理是即使使用model.eval(),但dropout层依然处于开启状态。
解决办法:有两个解决办法:1,构造函数中添加register_module("dropout", dropout),然后重新训练模型,再次推理;2,在forward函数中判断是否处于eval模型,从而决定是否开启dropout层。
12. tensor转mat时,图片内容乱序
问题:tensor转成opencv mat时,显示的图片是乱序的,如下所示。


原因:左图是原图,转成tensor后,tensor再转成img时,发生了乱序。原因是读取原图后,经过了一些操作,使得原图在内存中的存储不再是连续的,导致转成tensor时也成为乱序,再转回img就乱序了。
解决办法:opencv mat转成tensor前,先拷贝一下,img = img.clone().
image = image.clone();
auto input_tensor = torch::from_blob(image.data, { image.rows, image.cols, 3 }, torch::kByte).permute({ 2, 0, 1 }).clone(); // (h,w,c)->(c,h,w).
13. 报错位置:{torch::stack(data), torch::stack(targets)}
原因:复写dataset类时,函数get()有个target是解析字符串后的结果,字符串长度不一致,导致返回shape不是一致的,所以stack会报错。
解决办法:解析字符串后,想办法编码成长度一致的序列。
14. 错误 C2243 “类型强制转换”: 从“const Contained *”到“const torch::nn::Module &”的转换存在
原因:class Student: public Person. 继承时少了public,然后
Student d;
Person *p = &d; // C2243
解决办法:加上public继承。
待续。。。



















 3896
3896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











