










原文标题:Molecular Generation Using a Transformer-Decoder Model
地址:https://pubs.acs.org/doi/pdf/10.1021/acs.jcim.1c00600
代码地址:https://github.com/devalab/molgpt
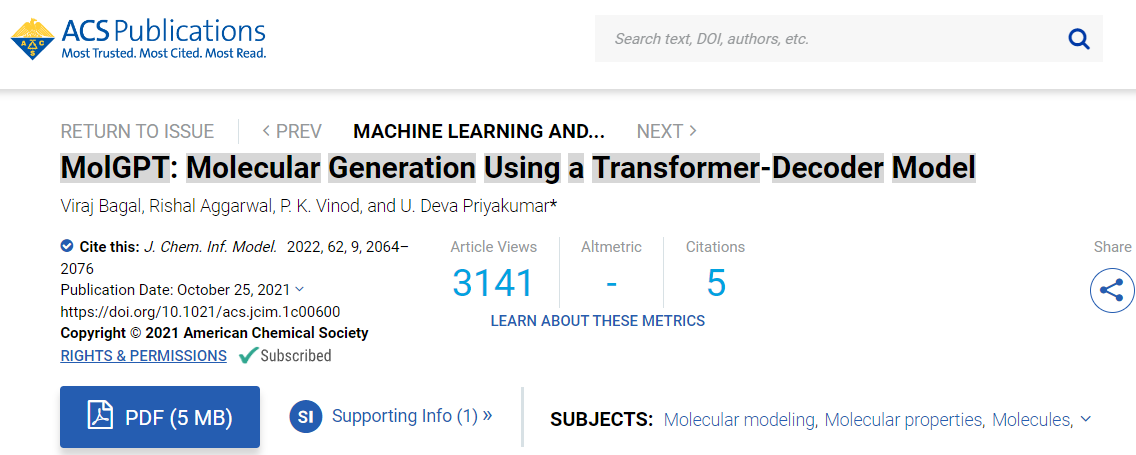
模型大致架构:
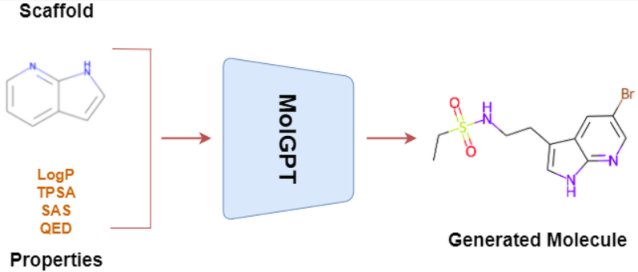
一、问题
潜在的类药物候选分子的总数在1023 ~ 1060个之间,其中1个分子仅合成了108个左右。由于很难筛选实际上无限的化学空间,而且合成分子和潜在分子之间存在巨大的差异,生成模型被用于模拟分子的分布,以采样具有理想性质的分子。
二、模型方法
1、dataset
两个基准数据集,MOSES和GuacaMol,使用RDkit计算分子性质,并提取支架。
优化属性:logP、Synthetic Accessibility score (SAS50)【合成难度,1表示容易、0表示很难】、Topological Polar Surface Area (TPSA)【所有极性原子的表面积之和,测量药物穿透细胞膜的能力】、Quantitative Estimate of Drug-likeness (QED51)【考虑主要的分子特性来量化药物相似度。它的范围从0(所有属性不利)到1(所有属性有利)】
2、模型
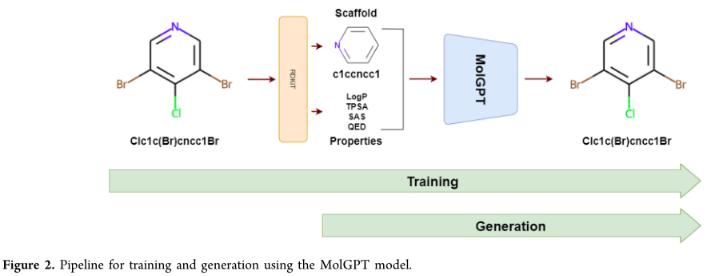
为非条件训练时,分子smile首先被tokenizer使用SMILES tokenizer,然后对模型进行训练下个token预测任务。对于属性条件训练和骨架条件训练,使用RDkit从分子中提取分子属性和支架,并将它们作为条件与分子SMILES一起传递。对于生成,向模型输入一个start token,然后模型按顺序预测下个token,从而生成一个分子。start token是通过加权随机抽样从出现在训练集SMILES字符串中的token列表中获得的。这些token的权重由它们在训练集中SMILES字符串的第一个位置出现的频率决定。然后,为模型提供了一组性质和骨架条件,以及start toekn来采样生成分子。
该模型本质上是GPT迷你版本,GPT1有110 M左右的参数,MolGPT只有6 M左右的参数。
MolGPT由堆叠的encoder block组成,每个block由masked self attention和FFN组成。每个self-attention返回dim = 256的向量,该向量被MLP作为输入。
神经网络的hidden layers输出一个1024大小的向量,并通过GELU激活层。MLP的最后一层返回一个大小为256的向量,然后用作下一个decoder block的输入。
MolGPT由八个decoder block组成。
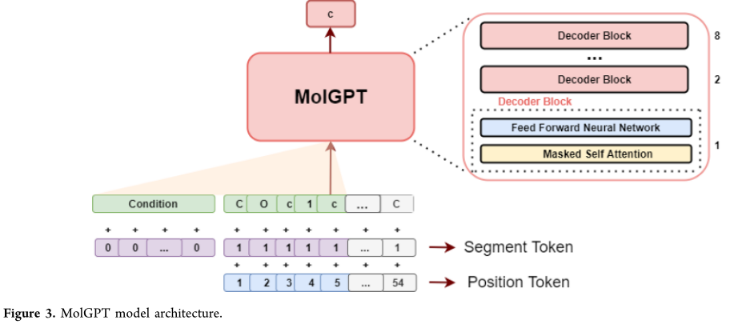
在条件训练期间,提供segment tokens 来区分conditional token和SMILES token。
使用embedding dim为256。使用可训练embedding层将positional token和segment token映射到256维。SMILES token embedding+positional token embedding+ segment token embedding,然后将其作为输入传递给模型。
训练一个模型来预测序列中的下个token时,效果并不理想。因为在生成过程中,与训练过程不同,网络将只能访问在之前的时间步骤中预测的token。
而且,每个块不是执行一个单独的屏蔽自注意操作,而是并行执行多个屏蔽自注意操作(多头注意),并将输出连接起来。通过关注不同位置的不同表示子空间,多头注意提供了更好的表示。因此作者采用了多头注意力(其他都不变)。
3、Training Procedure and Evaluation Metrics
Adam优化器、训练10个epoch,学习率为6e−4。NVIDIA 2080Ti GPU。
衡量标准:
Validity:生成的有效分子占比
Uniqueness:有效生成的分子中唯一分子的占比。较低的唯一性突出了分子生成的重复性和模型对分布的学习水平较低。
Novelty:不属于训练集的有效的唯一生成分子的比例。低新颖性是过度拟合的标志
Internal Diversity (IntDivp):测量生成的分子的多样性,专门设计来检查模式崩溃或模型是否不断生成相似结构的指标。使用生成集(S)中所有分子对(s1, s2)的指纹之间的Tanimoto相似度(T)的幂(p)平均值:

Frechet ChemNet Distance(FCD):利用生成分子的特征和数据集中分子的特征进行计算。这些特征是从ChemNet模型的倒数第二层获得的。低FCD值表示模型已经成功捕获了数据集的统计信息。
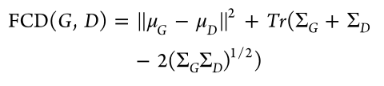
μG是g分布的均值,ΣG是g分布的协方差。对于Guacamol数据集,最终的FCD评分报告为:
![]()
S值越高越好。
KL Divergence:
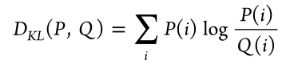
汇总的最终得分S除以所有属性k计算为:
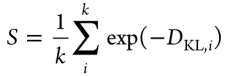
三、实验
1、Nonconditioned Molecular Generation.
好的生成模型应该尝试生成更多新颖有效的分子,以帮助我们探索化学空间,FCD和KL散度分别衡量模型捕获数据集特征的统计和分布的好坏。
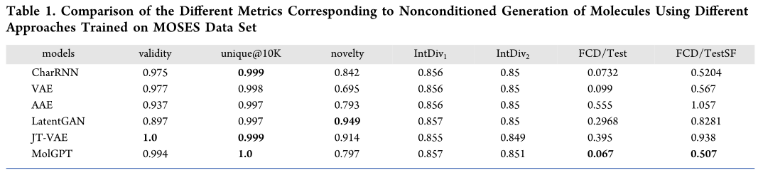
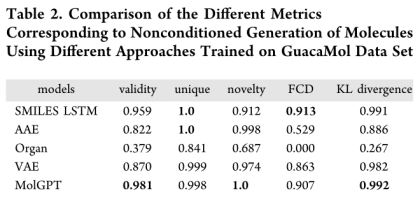
MolGPT在MOSES数据集上具有近乎完美的有效性得分,这表明对SMILES语法的学习能力很强,并对可归因于注意机制的长期依赖性建模。尽管与MOSES数据集相比,GuacaMol数据集的分子更大,但MolGPT生成的分子具有非常高的有效性,这也表明该方法处理远程依赖性非常好。
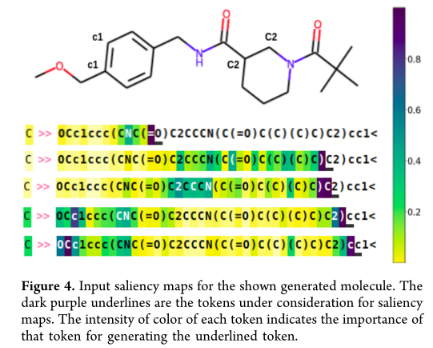
输入显著性方法为每个输入令牌分配一个分数,表示该token在生成下一个token时的重要性。
在生成第一个显著图中的“O”原子时,模型关注的是之前的双键和“N”原子。双键满足了氧原子的价,“N”原子参与了异构体(Lactam和Lactim)的形成,增加了结构的稳定性。在生成第二个显著图中的“C”原子时,模型会注意“(”和“)”以检查它们是否平衡,同时也会注意非芳香族环中的原子。在非芳香环中,它主要与紧邻的“2”和“N”原子有关。当生成“2”令牌时,它关注紧挨着前面的“C”令牌和非芳香环中的令牌。当在显著性映射的最后一行和倒数第二行生成“c”标记时,模型正确地关注芳香环中的原子,因为环仍然是不完整的。因此,这些显著性图为生成过程的化学可解释性提供了一些见解。
2、Generation-based on Single and Multiple Properties.
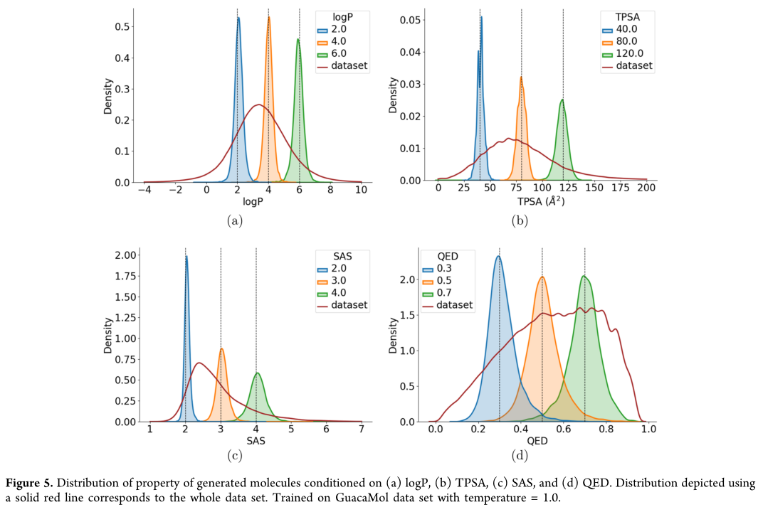
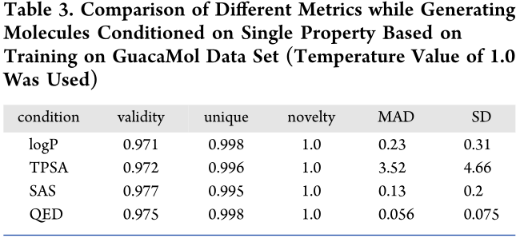
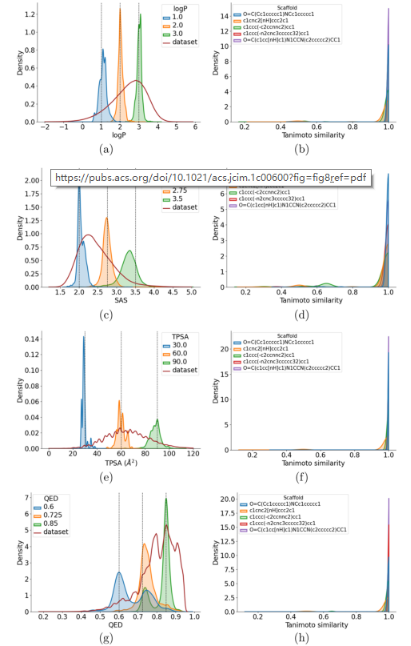
评估MolGPT生成具有特定特性的分子的能力(条件生成),测试模型控制在GuacaMol上训练的分子属性的能力。虽然只有logP、SAS、TPSA和QED用于属性控制,但模型可以通过训练来学习从分子的2D结构推断出的任何属性。对于每个条件,生成10000个分子来评估属性控制。
在控制单一特性时,MolGPT生成的分子的分子特性分布:
每个属性的平均平均偏差(MAD)、标准差(SD)、有效性、唯一性和新颖性值:
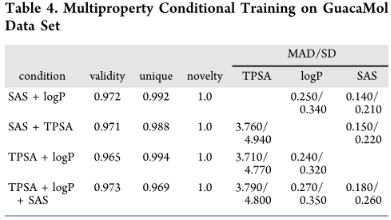
分子的从头设计,有必要优化不止一种性质。例如,人们可能想要有特定logP和TPSA值的分子。因此,我们检查模型同时控制多个属性的能力。为此,使用SAS、logP和TPSA。评估模型一次使用两个和三个属性控件生成所需分布的能力:
每个属性组合的低MAD和SD值(与属性值的范围相比)表明MolGPT对多个属性具有强大的控制,以实现精确生成:
3、Generation Based on Scaffold
评估了MolGPT在保持支架结构的同时生成具有一定属性值的结构的能力。在MOSES基准数据集上进行这些实验,因为它包含一组测试支架,这些测试支架与训练集中的支架不重叠。随机选取100个测试支架,然后为每个支架生成100个分子,然后计算有效性、唯一性、新颖性和“相似比”。“相似比”定义为生成分子的支架与条件支架具有大于0.8的Tanimoto相似性的有效生成分子的比例。
最初,从生成的分子中获得Murcko支架。然后计算生成分子的Murcko支架和条件支架的指纹的Tanimoto相似性。我们使用带有默认设置的RDkit指纹。显示每个指标的箱形图分布情况:
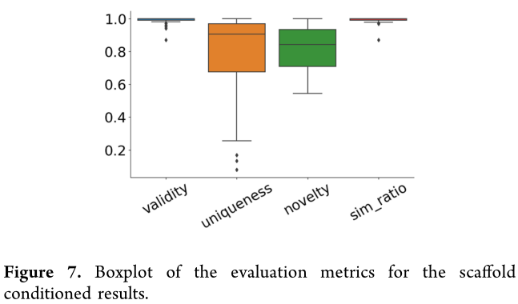
约75%的支架独特性和新颖性大于0.7。所有支架的“相似比”都大于0.8,这表明大多数生成的有效分子与用于条件反射的支架具有非常相似的支架。生成的分子中保持与条件作用完全相同的支架结构的比例被发现为0.9897。
4、Generation Based on Scaffold and Property
评估模型生成包含所需支架的结构的能力,同时也控制了多种分子特性。从MOSES测试集中随机选择5个不同大小的骨架。将有效分子定义为那些满足化学价的分子图,并包含与所需骨架具有至少0.8的谷本相似度的骨架。
定义了一个新的指标,称为相同支架分数(SSF):为生成的分子中含有与条件相同的支架的百分比。较低的MAD和SD评分仍然表明,MolGPT仅轻微偏离预期值。支架结构维持在生成的分子中,其QED值在0.9左右:
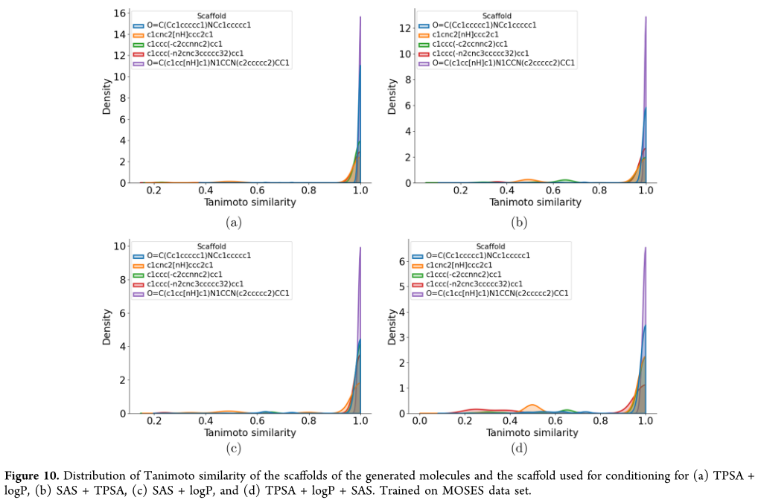
还展示TPSA、LogP和骨架结构得到维护,SAS被改进到更理想的值:
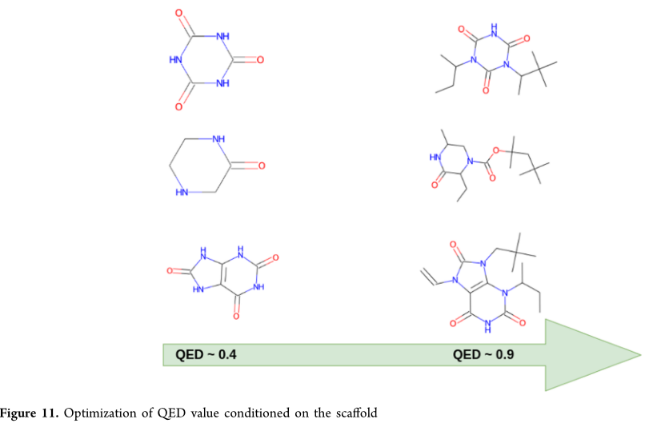
这里的模型仅用于优化简单的分子特性,并不能确保它在诸如先导优化等复杂任务中的可用性。

















 4536
4536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









