








前言
昨天介绍了特征金字塔网络用于目标检测,提升了多尺度目标检测的鲁棒性,今天开始讲讲One-Stage目标检测算法中SSD算法。这个算法是我平时做工程中最常用到的,严格来说平时最常用的Mobilenet做Backbone的SSD算法,因为要考虑到实际部署的时候的速度要求。
摘要
本文提出了仅需要单个卷积神经网络就能完成目标检测的算法,并命名为SSD(Single Shot Detector)。SSD算法将目标框的输出空间离散化为一组在每个特征图位置不同大小和形状的默认框。预测时,网络对位于每个默认框类的物体类别进行打分,并修正默认框位置来更好的匹配物体的位置。此外,SSD网络在不同分辨率的特征图上预测,这样就可以处理大小不同的物体。SSD比那些需要搜索物体候选框的算法简单,因为它完全去除了proposal生成和随后的特征再筛选的过程,把所有的计算封装在一个网络里面。这使得SSD训练起来很容易,可以直接加入到检测系统里面。在PASCAL VOC,COCO,和ILSVRC数据集上的实验也证明,与那些需要object proposal的算法相比,SSD在保证准确性的同时,速度更快。SSD只需一个完整的框架来训练和测试。在NVIDIA Titan X对于一个大小是300 × \times × 300的输入图像,SSD在VOC2007测试上的MAP是74.3%,速度是59FPS。对于512 × \times × 512的输入,SSD的MAP是76.9%,比Faster RCNN更准。和其他单阶段的方法比,即便是输入较小的图像,SSD的准确性也会更高。
介绍
目前,目标检测系统基本采用以下的流程:假设物体边框,对每个边框内进行特征再采样,最后使用分类器进行分类。这个流程比较流行,基于Faster-RCNN的方法通过选择性搜索在PASCAL VOC, COCO和ILSVRC上检测效果都很好。但是这些方法对于嵌入式设备来说计算量过大,甚至需要高端硬件的支持,对于实时系统来说太慢。最快的检测器-Faster RCNN的检测速度也只能到7FPS。人们尝试了很多其他方法来构建更快的检测器,但是增加速度大多以损失检测精度为代价。
本文提出了基于目标检测器的网络(object detector),它不需要为边框进行搜索,但是精度却不降反升。此方法实现了高精度和高速度,在VOC2007 上的测试速度是59FPS,mAP是74.3%;而Faster R-CNN的mAP是73.2%,速度是7FPS;YOLO的mAP是63.4%,速度的是45FPS。速度的提升得益于去除了边框提议(RPN或者Selective Search)和随后的特征再采样。使用了一个小卷积滤波器来预测目标分类和边框位置的偏移,对于不同横纵比检测使用不同的滤波器去处理,然后把这些滤波器应用在后面网络阶段的特征图上,这是为了用检测器检测不同比例的图片,这样我们再相对低分辨率的图像上也能获得高精度的输出,还提升了检测速度。本文的贡献如下:
- 提出了SSD算法—多类别单阶检测器, 要比其它的单阶段检测器(YOLO)快,而且更准确;
- SSD的核心部分是,在特征图上应用小卷积滤波器,预测分类得分和一个固定集合的默认边界框的偏移;
- 为了实现高检测精度,在不同比例的特征图上产生不同的预测,通过纵横比来分开预测;
- 以上的设计可以端到端训练,精度还高,甚至在低分辨率的图像上效果也不错;
- 关于速度和精度的试验,主要在PASCAL VOC, COCO 和 ILSVRC数据集上进行,与其它方法进行比较。
SSD
模型
SSD基于前馈式卷积神经网络,针对那些方框里的目标检测实例,产生一个固定大小边界框集合和分数,紧接着是一个非极大值抑制步骤来产生最后的检测。网络前半部分是个标准结构(用于高质量图片分类),成为基网络。然后对网络增加了辅助结构来实现以下特征:
- 多比例特征图检测:在基网络后增加卷积特征层,这些层按大小减少的次序连接,能够进行多尺度预测。
- 卷积检测预测器:通过一个卷积滤波器集合,每个新增的特征层可以产生一个预测集合。假设特征层大小为
m
×
n
m \times n
m×n,
p
p
p个通道,预测参数的基本单元是一个
3
×
3
×
p
3 \times 3 \times p
3×3×p的小核,它要么产生一个类别的得分,要么产生一个相对于默认方框的位置偏移。核一共要应用在
m
×
n
m \times n
m×n个位置上,在每个位置上它都有一个输出值。边界框的偏移输出值是相对于默认的位置的。

- 默认方框和纵横比:将每个特征图单元(cell) 与默认边界框的集合关联起来,这是对于网络顶层的多特征图来说的。默认方框用卷积的方式覆盖特征图,这样,每个方框对应的单元(cell) 是固定的。在每个特征映射单元上,我们预测相对于默认方框形状的偏移,以及每一类别的分数(表明每一个方框中一个类的出现)。在给定的位置有
k
k
k个框,对于其中的每一个,计算
c
c
c类类别的分数,和相对于原来默认方框形状的
4
4
4个偏移。这就一共有
(
c
+
4
)
×
k
(c+4)\times k
(c+4)×k个滤波器被应用到特征图的每个位置上;对于
m
×
n
m\times n
m×n的特征图,产生
(
c
+
4
)
×
k
×
m
×
n
(c+4)\times k\times m\times n
(c+4)×k×m×n个输出。默认方框跟Faster R-CNN中的Anchor类似,但是作者将它们应用到不同分辨率的特征图上时,由于在一些特征图上有不同的默认框形状,这使得算法对不同尺度的目标有较好的探测作用。
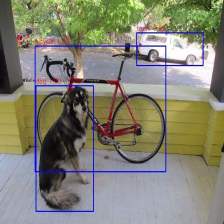
 SSD 在训练中只需一张输入图像和图像中每个目标的ground truth边界框信息。在卷积操作中,我们产生一个默认方框的集合,这些方框在每个位置有不同的纵横比,在一些特征图中有不同的比例,如上图所示。对于每个默认方框,预测它形状的偏移和类别的置信度(
c
1
,
c
2
,
c
3
,
.
.
.
,
c
p
c_1,c_2,c_3,...,c_p
c1,c2,c3,...,cp)。训练时,首先将这些默认方框和 ground truth 边界框对应上。就像图中,作者匹配了2个默认方框,一个是猫,一个是狗,它们被认定为positive, 其余部分被认定为 negative. 模型损失函数是 localization loss(smooth L1) 和 confidence loss(Softmax) 的加权之和。
SSD 在训练中只需一张输入图像和图像中每个目标的ground truth边界框信息。在卷积操作中,我们产生一个默认方框的集合,这些方框在每个位置有不同的纵横比,在一些特征图中有不同的比例,如上图所示。对于每个默认方框,预测它形状的偏移和类别的置信度(
c
1
,
c
2
,
c
3
,
.
.
.
,
c
p
c_1,c_2,c_3,...,c_p
c1,c2,c3,...,cp)。训练时,首先将这些默认方框和 ground truth 边界框对应上。就像图中,作者匹配了2个默认方框,一个是猫,一个是狗,它们被认定为positive, 其余部分被认定为 negative. 模型损失函数是 localization loss(smooth L1) 和 confidence loss(Softmax) 的加权之和。
怎么设置default boxes?
SSD中default box的概念有点类似于Faster R-CNN中的anchor。不同于Faster R-CNN只在最后一个特征层取anchor, SSD在多个特征层上取default box,可以得到不同尺度的default box。在特征图的每个单元上取不同宽高比的default box,一般宽高比在{1,2,3,1/2,1/3}中选取,有时还会额外增加一个宽高比为1但具有特殊尺度的box。上面那张图展示了在8x8的feature map和4x4的feature map上的每个单元取4个不同的default box。原文对于300x300的输入,分别在conv4_3, conv7,conv8_2,conv9_2,conv10_2,conv11_2的特征图上的每个单元取4,6,6,6,4,4个default box. 由于以上特征图的大小分别是38x38,19x19,10x10,5x5,3x3,1x1,所以一共得到38x38x4+19x19x6+10x10x6+5x5x6+
3x3x4+1x1x4=8732个default box.对一张300x300的图片输入网络将会针对这8732个default box预测8732个边界框。
训练
训练SSD和训练其他使用区域提议检测器的主要区别是,ground truth信息在固定检测器输出的情况下需要指定到特定的输出。这样,损失函数和反向传播就可以端到端的应用。训练需要选择默认方框的集合,检测比例,以及hard negative mining(也就是不存在目标的样本集合)和数据增强策略。
- Matching strategy, 在训练中,需要决定哪个默认框匹配一个 ground truth,由此来训练网络。对于每个从默认方框(不同位置,不同纵横比,不同比例上)中选择的 ground truth 边界框,开始时,根据最高的 jaccard overlap 来匹配 ground truth 边界框和默认方框(与MultiBox一样)。实际操作中,与 MultiBox 不同,当它们的 jaccard overlap高于阈值0.5时,作者就将默认方框认为 ground truth。这简化了学习问题,使得网络可以对多个重叠的默认方框预测得到高分,而不是仅挑选一个重合度最高的方框。
- Training objective SSD的训练目标来自于MultiBox,但是作者将之扩展成可处理多目标分类的问题。
x
i
j
p
=
1
,
0
x_{ij}^p={1,0}
xijp=1,0表示匹配第
i
i
i个默认方框和
p
p
p类别第
j
j
j个ground truth边界框。这种匹配策略会出现
∑
i
x
i
,
j
p
>
=
1
\sum_ix_{i,j}^p>=1
∑ixi,jp>=1。整体的目标损失函数是定位损失加分类损失:
L ( x , c , l , g ) = 1 N ( L c o n f ( x , c ) + α L l o c ( x , l , g ) ) L(x,c,l,g)=\frac{1}{N}(L_{conf}(x,c)+\alpha L_{loc}(x,l,g)) L(x,c,l,g)=N1(Lconf(x,c)+αLloc(x,l,g)),其中 N N N是匹配默认框的个数,如果 N = 0 N=0 N=0,loss设为0。
定位损失是预测边界框 l l l和真值边界框 g g g参数的Smooth L1 loss。与Faster R-CNN类似,对默认边界框 d d d中心 ( c x , c y ) (cx,cy) (cx,cy)的偏移量进行回归, w w w是宽, h h h是高。

分类损失是多个类别置信度的 softmax loss:

α \alpha α在交叉验证中设为1。 - Choosing scales and aspect ratio for default boxes 为了处理不同的目标比例,有些方法是把图片处理成不同的大小,然后结合不同大小图片的结果。但是在一个网络中利用多个不同层产生的特征图来预测也能产生类似的结果,所有比例的目标还可以共享参数。前面的研究已经证明使用底层的特征图可以提升语义分割质量,因为底层能捕捉到输入图像中的细节信息。受这些方法启发,本文使用了特征图中的高层和低层特征来进行目标检测。
网络中不同层级的特征图会有不同的感受野,在SSD中,默认框不一定要和每层中的实际感受野对应。假设我们要用 m m m个特征图来预测,每个特征图的默认框尺度计算如下:
s k = s m i n + s m a x − s m i n m − 1 ( k − 1 , k ∈ [ 1 , m ] ) s_k=s_{min}+\frac{s_{max}-s_{min}}{m-1}(k-1,k\in[1,m]) sk=smin+m−1smax−smin(k−1,k∈[1,m]),其中 s m i n s_{min} smin是0.2, s m a x s_{max} smax是0.9,意味着最低的层的尺度是0.2,最高的层的尺度是0.9,有的中间层正常间隔分布。对于默认框,使用不同的高宽比, a r ∈ 1 , 2 , 3 , 1 2 , 1 3 a_r\in{1,2,3,\frac{1}{2},\frac{1}{3}} ar∈1,2,3,21,31。可以计算每个默认框的宽度 w k a = s k a r w_k^a=s_k\sqrt a_r wka=skar和高度 h k a = s j / a r h_k^a=s_j/\sqrt{a_r} hka=sj/ar。对于宽高比是1的情况,增加一个尺度是 s k ′ = s k s k + 1 s_k^{'}=\sqrt {s_ks_{k+1}} sk′=sksk+1的默认框,这样就在每个特征图位置有6个默认框。将框的中心设为 ( i + 0.5 ∣ f k ∣ , j + 0.5 ∣ f k ∣ ) (\frac{i+0.5}{|f_k|},\frac{j+0.5}{|f_k|}) (∣fk∣i+0.5,∣fk∣j+0.5),其中 ∣ f k ∣ |f_k| ∣fk∣是第 k k k个正方形特征图的大小。
结合诸多特征图的不同位置下所有不同尺度和宽高比的默认框,就有了一个预测结果的集合,覆盖不同大小和形状的输入对象。例如图一中,那条狗与 4 × 4 4 \times 4 4×4特征图中的默认框匹配,但是不和任何 8 × 8 8 \times 8 8×8特征图中的默认框匹配,因为这些默认框有着不同的尺度,与狗的默认框不匹配,因此在训练中被认为是negative。 - Hard Negative Mining ,匹配步骤后,默认框中的大多数都是negative, 尤其是候选框个数众多的时候。这就导致positive 和 negative 训练样本不平衡。这些negative 样本不全用,而是对于每一个默认框,通过最高置信度损失来对它们进行排序,选择最高的几个,这样negative 和 positive的比例最多是3:1。这样训练更稳定也更快。
- Data augmentation 为了让模型对不同的输入大小和形状更鲁棒,每张训练图片都通过以下步骤随机选择:(1)使用整张原始图片输入;(2)选择图片中的一块,与物体最低的 jaccard overlap 值为0.1, 0.3, 0.5, 0.7, 0.9;(3)随机采样某一块。采样区块的大小在原图片[0.1,1]之间,高宽比介于0.5和2之间。保留真值边界框中的重叠部分,如果它的中心在采样区块内。在采样步骤后,每个采样区块缩放到固定大小,以0.5的概率来水平翻转。
实验结果
在PSCAL VOC2012上面:

在COCO数据集上面:

速度和精度的整体对比:

结论
SSD优势是速度比较快,整个过程只需要一步,首先在图片不同位置按照不同尺度和宽高比进行密集抽样,然后利用CNN提取特征后直接进行分类与回归,所以速度比较快,但均匀密集采样会造成正负样本不均衡的情况使得训练比较困难,导致模型准确度有所降低。另外,SSD对小目标的检测没有大目标好,因为随着网络的加深,在高层特征图中小目标的信息丢失掉了,适当增大输入图片的尺寸可以提升小目标的检测效果。
代码
https://github.com/weiliu89/caffe/tree/ssd
参考文章
https://blog.csdn.net/calvinpaean/article/details/84301031
https://www.jianshu.com/p/e13792628bac















 684
684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









