







语音识别基础
语音识别全称为“自动语音识别”,Automatic Speech Recognition (ASR),**一般是指将语音序列转换成文本序列。**即给定输入序列O={O1,…,On},寻找最可能的词序列W={W1,…,Wm},即寻找使得概率P(W|O)最大的词序列。贝叶斯公式表示为:
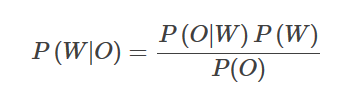 其中P(O|W) 叫做声学模型,描述的是给定词W时声学观察为O的概率;P(W)叫做语言模型,负责计算某个词序列的概率;P(O)是观察序列的概率,是固定的。
其中P(O|W) 叫做声学模型,描述的是给定词W时声学观察为O的概率;P(W)叫做语言模型,负责计算某个词序列的概率;P(O)是观察序列的概率,是固定的。
语音选择的基本单位是帧(Frame),一帧数据是由一小段语音经过ASR前端的声学特征提取模块产生的,整段语音就可以整理为以帧为单位的向量组。每帧的维度固定不变,但跨度可调,以适应不同的文本单位,比如音素、字、词、句子。
之前大多数语音识别的研究都是分别求取声学和语言模型,并把很多精力放在声学模型的改进上(可能是对音质的要求,去噪这些),而基于深度学习和大数据的端到端学习方法直接计算P(W|O)。
现有与深度学习结合的语音识别方法有DNN-RNN、DNN-HMM,可引入LSTM(长短期记忆网络,Long Short-Term Memory),DNN(深度学习网络,Deep Neural Networks),RNN(循环神经网络,Recurrent Neural Network);
也有迁移学习(Transfer learning)算法、以及注意力(Attention)机制的基于语音频谱图的CNN(卷积神经网络,Convolutional Neural Network)模型等。
端到端学习的方法
即规定好了输入和目标输出,中间部分就看模型的了。对于语音,首先考虑输入输出的不定长问题。介绍两种端到端的学习方法。
CTC (连接时序分类,Connectionist temporal classification), CTC 方法早在2006年就已提出并应用于语音识别,但真正大放异彩却是在2012年之后,随之各种CTC研究铺展开来。CTC仅仅只是一种损失函数,简而言之,输入是一个序列,输出也是一个序列,该损失函数欲使得模型输出的序列尽可能拟合目标序列。回忆语音识别系统的基本出发点,即求W∗ = argmaxw P(W|O),其中 O= [O1, O2, O3, …]表示语音序列,W= [w1, w2, w3, …] 表示可能的文本序列,而端对端模型zh本身就是 P(W|O ),则CTC 的目标就是直接优化 P(W|O ),使其尽可能精确。之前需要语音对齐到帧,用这个就可以不需要对齐,它只会关心预测输出的序列是否和真实的序列是否接近(相同)。
Attention Attention模型的基本表述可以这样理解成: 当我们人在看一样东西的时候,我们当前时刻关注的一定是我们当前正在看的这样东西的某一地方,换句话说,当我们目光移到别处时,注意力随着目光的移动也在转移。 Attention机制的实现是通过保留LSTM编码器对输入序列的中间输出结果,然后训练一个模型来对这些输入进行选择性的学习并且在模型输出时将输出序列与之进行关联。















 393
393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









