







一、项目概览
BLIP(Bootstrapping Language-Image Pretraining)是Salesforce Research提出的视觉-语言预训练框架,2022年发表于ICML。该项目通过创新的多模态混合架构,在图像描述生成、视觉问答、跨模态检索等任务上取得突破,其代码库已集成至LAVIS多模态统一框架。
项目亮点:
- 支持ViT-B/Large多尺度视觉编码器
- 提供零样本视频-文本检索能力
- 包含预训练到下游任务全流程实现
- 模型参数规模:Base(223M)到Large(1.2B)
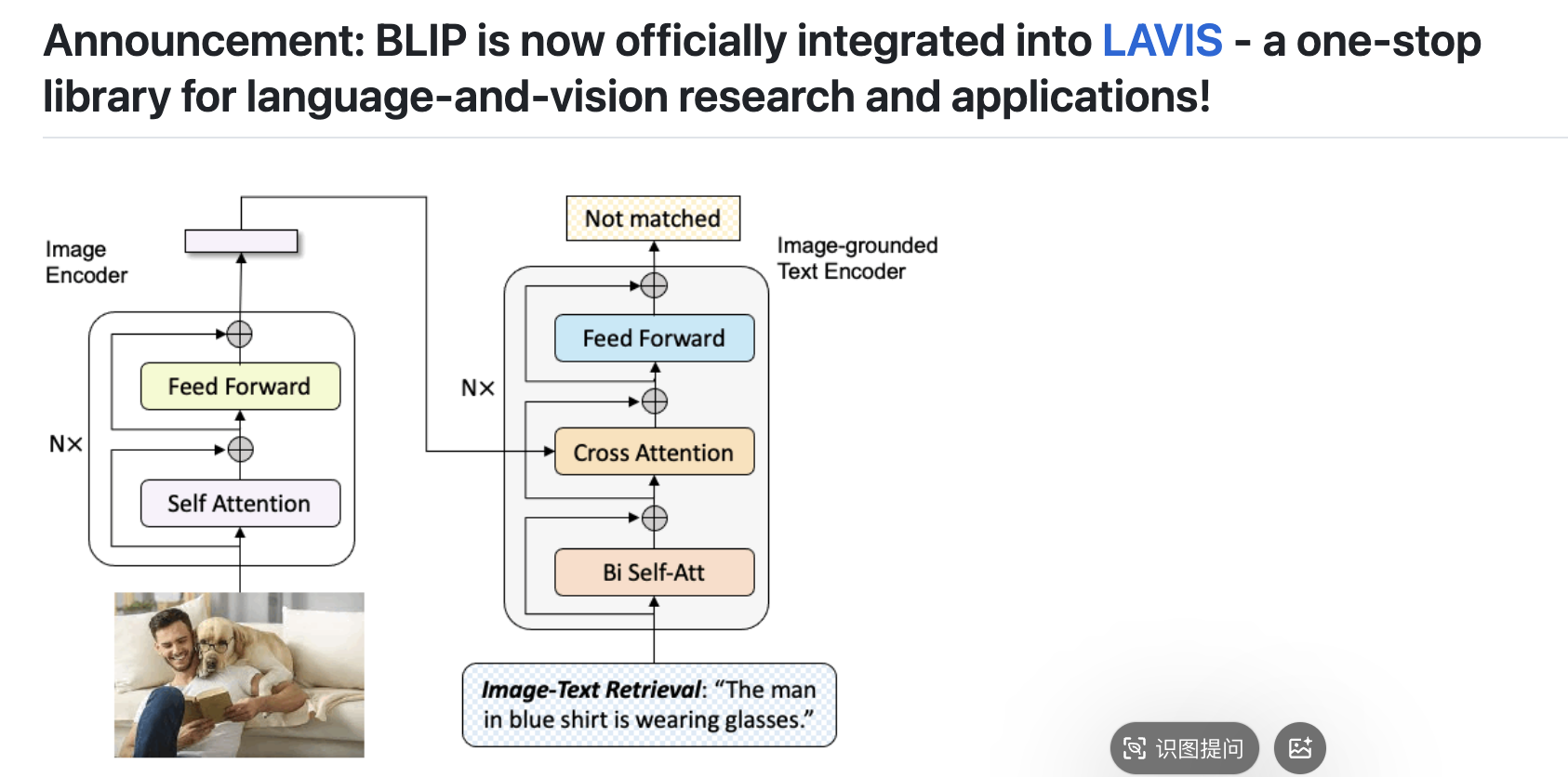
二、快速实践指南
环境部署
git clone https://github.com/salesforce/BLIP
pip install -r requirements.txt # 核心依赖:timm==0.4.12, transformers==4.15.0
示例应用
from models.blip import blip_decoder
model = blip_decoder(pretrained="model_base_capfilt_large.pth")
# 图像描述生成
from PIL import Image
image = Image.open("demo.jpg").convert("RGB")
caption = model.generate(image, sample=True, num_beams=5)
print(f"Generated:  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1115
1115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











