







Paper name
FisheyeDistanceNet: Self-Supervised Scale-Aware Distance Estimation using Monocular Fisheye Camera
Paper Reading Note
URL: https://arxiv.org/pdf/1910.04076.pdf
Demo 视频:https://www.youtube.com/watch?v=Sgq1WzoOmXg
TL;DR
- ICRA 2020 文章,出自于德国 Valeo 自动驾驶公司,在传统的无监督单目深度估计工作中引入鱼眼成像模型从而实现了单目鱼眼的无监督深度估计模型训练,并通过各种 trick 提升模型准确度和预测深度的边缘清晰度
Introduction
- 之前的深度估计方法一般是在基于小孔成像模型的畸变校正厚度图像序列上来做的,广角鱼眼相机相对针孔相机有着更大的视场角,在自动驾驶领域有广泛应用
- 之前的鱼眼相机深度估计主要是基于雷达采集的真实深度作为监督来进行模型训练,本文提出了首个端到端的鱼眼深度估计网络: FisheyeDistanceNet
- 本文贡献有:
- 基于未校正的鱼眼图像序列进行自监督训练得到深度估计模型的方法
- 单目 scale 不确定性问题解决,能直接输出 metric distance map
- 结合超分网络和 deformable 卷积来得到高分辨率的深度图,超分用于取代用于上采样的 nearset/bilinear resize 或反卷积
- 基于反向的视频序列进行训练的 idea
- 一种结合过滤 static pixels 和 ego mask 的方法
- 使用 bundle adjustment 来联合优化深度和相机位姿,通过增加 baseline 和提供额外的一致性约束
Dataset/Algorithm/Model/Experiment Detail
实现方式
- 之前的 SFMLearner 或 monodepth2 方法中的 depthnet 和 posenet 的估计值都存在一个不确定的 scale
- 一种直观的处理方式是基于 piecewise 或 cylindrical 投影后的图片进行无监督训练,这就和 monodepth2 一样了,但是本文提出了一种更简洁直观的方式

鱼眼几何建模
- 投影相机坐标到图像坐标,xc、yc、zc 是相机坐标系的表示,u、v 是图像坐标系下的表示

其中 r c = x c 2 + y c 2 r_{c}=\sqrt{x_{c}^{2}+y_{c}^2} rc=xc2+yc2, θ \theta θ 是入射角,第三个 ρ ( θ ) \rho(\theta) ρ(θ) 是将入射角映射到图像半径上, ( a x , a y ) (a_{x},a_{y}) (ax,ay) 是 aspect ratio, ( c x , c y ) (c_{x}, c_{y} ) (cx,cy) 是光心点坐标 - 图像坐标映射到相机坐标
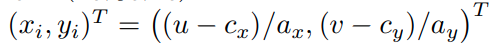
基于 4 阶多项式及畸变参数 k 1 k_{1} k1、 k 2 k_{2} k2、 k 3 k_{3} k3、 k 4 k_{4} k4 计算获取入射角 θ \theta θ
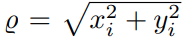
基于获取的 θ \theta θ 得到
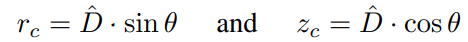
其中 D ^ \hat{D} D^ 是网络估计的 3D 点的欧氏距离
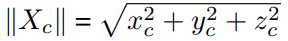
最终计算的结果:
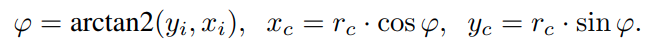
photometric loss
- 基于上述的几何变换可以将相邻帧图像投影到当前帧上,图像重投影的损失定义与 monodepth2 一致,即 L1 加上 SSIM 计算的损失,多帧间在空间维度取最小
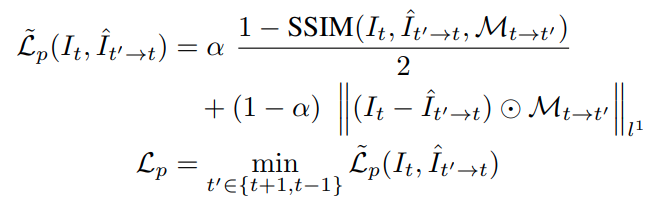
这里不同的地方是考虑到这些重投影过程中肯定还会存在运动物体、物体亮度不一致的问题,所以参考了 论文 中的方式使用了 95 分位数截断
解决训练过程中的 scale factor ambiguity
- 对于针孔成像模型,深度与视差的关系是:
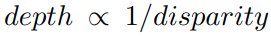
网络经过 sigmoid 后输出的视差可以经过一个 affine 变化后将预测深度控制在 0.1 到 100 units 之间
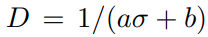
- 在鱼眼图像中,需要 metric 距离才能将相邻帧图像投影到当前帧图像中,所以为了实现 scale-aware 的距离估计值,将 posenet 估计的 T 进行归一化,并且经过
△
x
\triangle{x}
△x 进行 scale 操作。
△
x
\triangle{x}
△x 经过汽车的瞬时速度计算得到(相邻帧的汽车速度均值)
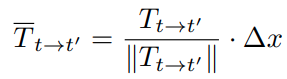
静态像素 mask 和 ego mask
- 类似 monodepth2,rgb 的相邻帧之间变化小的像素会被屏蔽掉,用于过滤与自身相同速度运行的目标,同时过滤自身没有移动时出现的静态图像帧
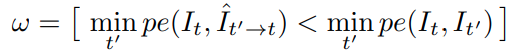
其中 [] 是艾弗森括号,即满足条件时值为1,否者为0 - 另外也参考 文章 提出了一种 ego mask,即排除掉相邻帧间没有合规映射的点,像一些根据相机位姿和深度计算出的target 图像上的区域无法成功重投影到 source 图像中就算做不合规映射区域
反向的训练序列
- 正反向定义
- 正向训练序列: I t I_{t} It 作为 target 帧, I t − 1 I_{t-1} It−1、 I t + 1 I_{t+1} It+1 作为 source 帧
- 反向训练序列: I t I_{t} It 作为 source 帧, I t − 1 I_{t-1} It−1、 I t + 1 I_{t+1} It+1 作为 target 帧
- 一般都只使用正向训练序列,作者参考之前部分工作引入了反向序列,这样更丰富的约束能避免过拟合,并在测试时的解决边界区域的深度未知问题
- 这个方式的劣势是需要增加一次前传和反传,但能涨点
边缘 aware 的平滑性损失
- 和 monodepth 论文提出的损失一致,鼓励非图像边缘区域的深度相对平滑
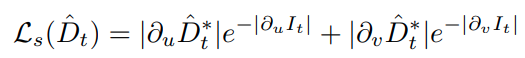
cross-sequence distance consistency loss
- 对于一个训练视频流中的 N 帧图像集合 S:
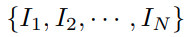
每张图像估计的深度在不同帧上的深度应该是一致的,基于不同帧之间的深度预测差异定义以下损失,用于进一步增加网络预测绝对深度的能力
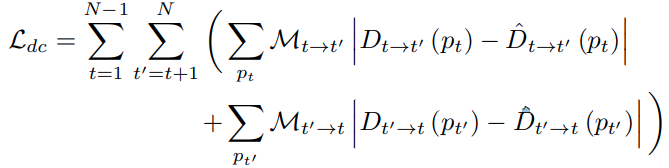
最终训练损失
- 参考 monodepth2,为了防止训练目标由于双线性采样的梯度局部性而陷入局部极小值,也使用了 4 个尺度的特征图进行训练,最终的损失是上述所有损失的加权
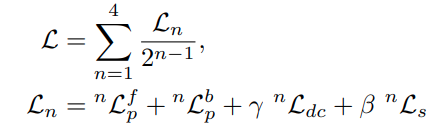
网络结构修改
- deformable super-resolution 网络
- resnet18 作为 encoder,其中卷积算子使用了 deformable conv 替换
- 上采样使用 nearest resize 或反卷积导致物体边缘的误差大,这里使用了超分中常用的 sub-pixel convolution,所以边缘更 sharp
实验结果
-
在 KITTI 和 WoodScape 上的定量评测结果,WoodScape 是作者开源的自动驾驶场景鱼眼图像数据集。这里 KITTI 的评测作者使用的与 monodepth2 对齐的网络输入尺寸(640x192),卷积算子也没有使用 deformable 卷积。可以看出作者提出的各种 trick 能够帮助在 KITTI 上涨点。在鱼眼数据集 Woodscape 上作者将深度截断值控制到 30m 和 40m,用于展示鱼眼在相对近距离上的优势

-
预测结果可视化(1280×800 crop 到 1024×512 用于去除保险杠、阴影等区域,输入网络一般是下采样到 512x256)

-
各种 trick 的消融实验

Thoughts
- 基本工作还是参考 monodepth2,基于鱼眼成像的几何模型适配后实现了无监督鱼眼深度估计方案
- 引入汽车的瞬时速度让单目具备绝对深度感知能力,加上尺度一致性方面的各种约束可能值得参考
- photometric loss 引入的 95 分位数截断值得参考
- subpixel 增加边缘清晰度值得参考
- 本文综合了非常多的 trick,比如反向训练序列、ego mask,虽然很多不是本文首次提出,但是综合起来涨点明显















 1242
1242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









