






本文是对EDA教程《VLSL Physical Design》第二章的理解和笔记,若有谬误欢迎探讨和指出
2.1 介绍
Partitioning,分块
1,为什么要分块?
答:
1)这样能简化设计,让各个模块各自设计。
2)受到芯片大小的限制。比如某个小元件上只能布置8个门电路,那么就要把网络分块成大小不大于8的小块。
2,分块的目标?
答:在块大小,引脚数等限制条件下尽量使块和块之间连接减少。因为太多的连接意味着更长的延时和更高的出错的可能性。
例子:

在这个图中,如果有两块小芯片各自可以刻录4个逻辑门电路,那么第一种设计方案就优于第二种,因为第一种两个模块之间只用连两条线,而第二种需要四条。
2.2 名词约定
1,cell,指一个模块,它可以是一个逻辑门,也可以是一个功能模块。
2,partition,划分。指一个元件集合及其分组情况。
3,k-way-partition,k路划分,一种分了k组的划分
4,对于一个图G(V,E) area(v)指一个点v的权重, W(e)指的是边e的权重
5,disjoint指的是一个图已经应分尽分了,每个点都属于且仅属于一个子集
6,如果一个边e的两端分属于两个子集,则称之为cut。如下图,若B视为是一个模块,则B中四个点的连线就不是cut,但B与a,b,f的连线是cut。称cut的集合,即割线的集合,为。

7,hyper graph,指图中某些线进行了合并,即一个"net"能连接三个以上的点,如下图的c。b,c都是对图a的合理抽象。
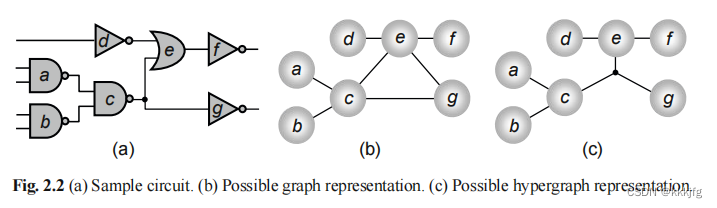
2.3 优化目标
1,使割线的集合尽可能的小
2,满足最大点集大小的限制
注意这里每一个点带了权重。集合大小等于其中每个点的权重加起来。当每个点权重刚好为1时,上式可以写为:
即每个点的点数不超过总点数的1/k。
2.4 分块算法
做了前面一堆的铺垫终于到了这一章的重点分块算法。分块是一个np-hard的问题,没法直接在多项式时间内获得最优解。这一章会介绍两个启发式算法。
2.4.1 KL(Kernighan-Lin)算法
简介
KL算法是一个2-way partition,即把点分成两块的算法。
KL算法的核心思想,就是交换。先随机把点分成两块,再找一左一右各自找一个点,再把这一对点进行交换。
怎么交换呢?就是看一下交换前后是不是能使现状朝着优化目标推进。即是否减少了割线权重和。如果有多对点,我们就选一对能最大程度减小割线权重的点。我们为您反复交换,换到不能换就算是结束了。
术语
1,D(v):
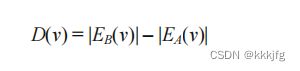
设点v从A集挪到B集。EB指的是点v的割线,EA则指的是其余的线。
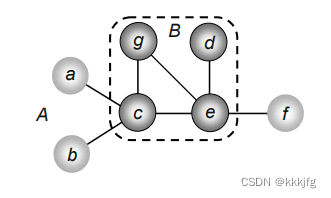
以这个图为例子,若要把e从B集合拿到A集合,(e,f)就是割线,对应上面公式中的EB,(d,e),(g,e)和(c,e)不是割线,即上述式子中的EA。
那么D(v)有什么含义呢?
答:D(v)的意思就是挪动 v所能减少的割线数目。如以上例子,EB-EA=-2,即若挪动e到A 集合,(e,f)不会被割了没错但是(d,e),(g,e)和(c,e)变成了新割线。所以割线数目反而增加了两条。
2,g(a,b):
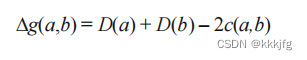
即gain,获得。如果我们要交换分属于两个子集的a,b两点,我们只需要分别算a,b换集的“赚”的程度,加起来就可以了。
忘了点什么?哦对,如果这两个点的换集合的过程不独立的话还能加吗?不能。a,b之间连线的权重显然被多算了两次,要减掉。
交换完的两个点先固定。这样重复多次直到所有点都被固定,这样的过程称为一个pass
前M步把每次交换的gain加起来就是前m步的总获得。
注意这里不是当gi小于0就停止了。因为每次交换的gain可能会出现类似-1,2,-1,2,-2,-2这种,这个例子要交换四次,但如果第一次看到-1就停下来的话可能就会漏掉最佳答案。
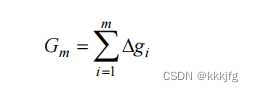
我们这样重复几个pass之后就不再能获得正的G了,这时候算法停止即可。
这是书中的伪码:

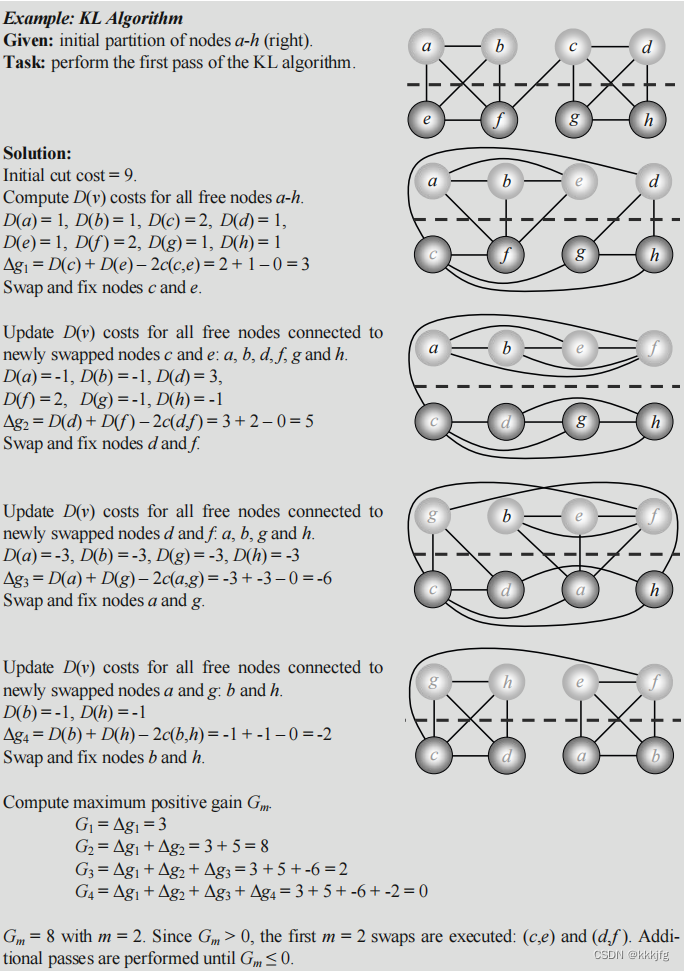
书中的一个例子:
2.4.2 KL算法的扩展
1,若要把一个图划分成两个不是等大小的子集怎么办?
答:不影响,只要限制算法在一个pass里交换min(|A|,|B|)对节点就可以了。
2,若各点之间的权重不相同怎么办?
答:搞成相同的!即拆成各点的最大公约数的权重,各部分之间用无限大的边权进行连接。举个例子,假如有四个点4,4,6,10这些点,我们就全部拆成2这么大,4里面的两个2用无限大的权重连接,6里面的三个2用无限大的权重进行连接,即可转换为正常版。
2.4.3 FM(Fiduccia-Mattheyses)算法
核心思想:
1,解决KL算法中的每次必须找一对点的问题。所以FM是一次只需要挪动一个点。
2,那么问题来了:一次只挪动一个点,挪完子集的大小不就发生变化了吗,怎么保证两个子集之间大小的均衡?FM引入了一个松弛条件,允许两个集合的一些属性在一定程度上波动,这样既可以移动单个的点,又不至于直接给挪到同一边了。
3,FM算法使用hyper-graph
术语
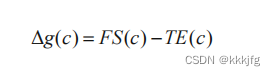
不同于KL算法,FM算法的gain算的是单个点。此处FS指的是“连接到了c但没连接c集合中其他点的边” ,而TE指连到c上的uncut net,即所有点都连着c集合的net,如下面的(c,e,g)
每次挪点之前要计算所有点的gain,取gain最大的点进行挪动,挪到所有点都固定为止。
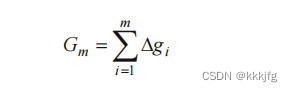
和KL算法一样,FM算法也是计算从1到最后一步每一步的Gm,即gain累加值,取Gm值最大的步数进行交换。
为防止所有点都挪到了同一边,我们要引入一个集合可以到达的范围,若各挪动会超出范围,我们就说它是非法的。
范围限制如下:
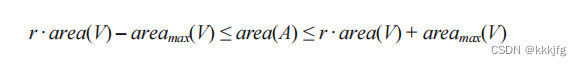


A,B是两个子集合。area_max(V)是V中area最大的点。
不过我有一点不理解为啥r的分子是area(A)不是area(B)。
我尝试这样理解:
把上面的二式代入一式,得
即,A集合权重的上下限是A集合减最大权重节点,到A集合加最大权重节点。
把B换成A同理。
所以我想可能意思就是说,相比于初始状态的A,B,我们不希望太多的权重从A流入到B或者从B流入到A,而我们所能容忍最大限度的权重流动就是area_max(V),若忍耐度低于这个值,可能会造成最大权重节点该挪的时候挪不动,高于这个值可能会造成更严重的往一边跑的现象。我觉得可能忍耐度其实可以略高于area(V),不过这个值已经看上去比较合理了。
算法

书中的例子,即,
1,算gain,取最高,挪动,重复到不能挪了。
2,然后看看这些步数内前多少步的前缀和最大。假设这个数为m,我们把这个挪动序列的前m步进行实现。
3,反复以上的步直到挪动序列的每一步的累加gain都不是正的了,证明已经挪无可挪了,算法停止。
例子
以下是书中的一个例子。



2.5 多级分块。
当一个“net”(即hyper-graph中连了多个点的边)连接了上百个节点时,FM可能会较低效或者解比较差,实际应用过程中为了规避这种情况,可以先聚类以减少点数,应用FM算法,再拆点,再使用FM算法往复循环。
2.5.1 聚类
大致地说就是连接紧密的点聚成一类外部结构不变且内部连接吸收。但不同应用的要求会不一样。大部分应用会对聚类后的点大小做出限制。以下是一个例子:
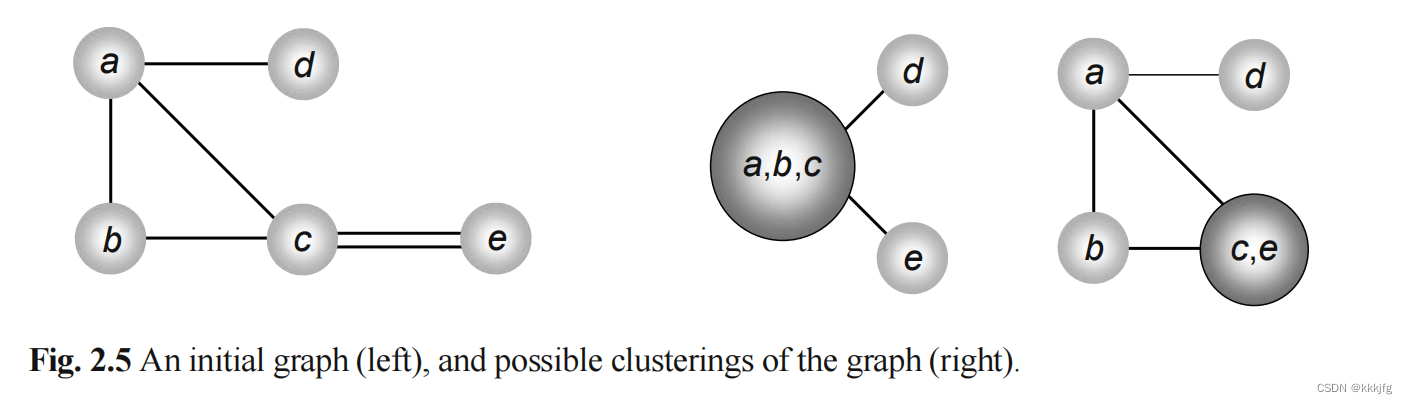
如图是a,b,c,d,e五个点的两种聚类方式。
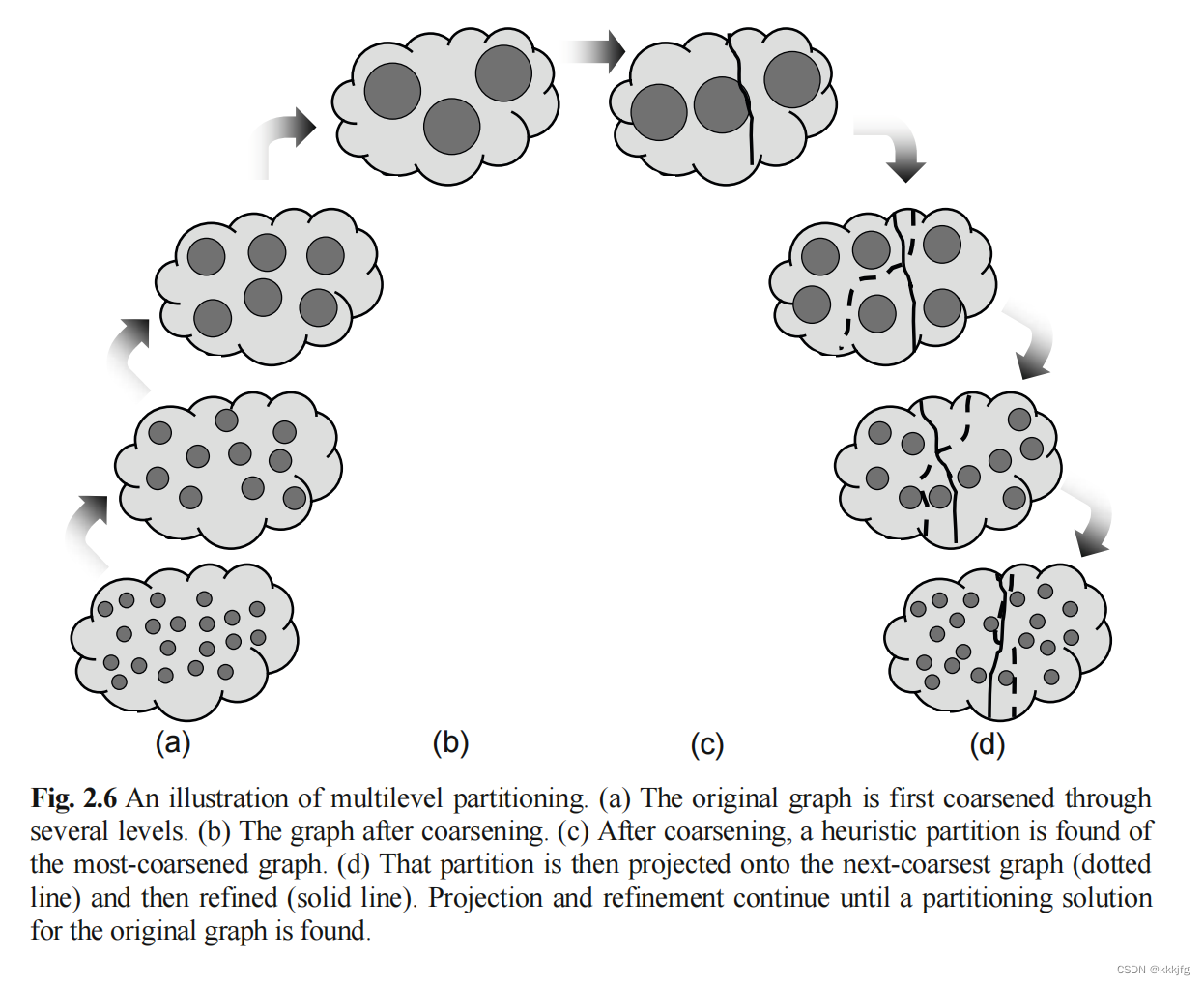
在分级分块的流程中,会先聚类,每次将点数减少固定百分比,这个过程进行log(|V|)次,再交替进行分块、拆点操作,直到变回原图的点数。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









