






 本文详细介绍了VLSI设计中的布局规划,包括布局规划的阶段、目标、术语和各种优化算法,如集群增长、模拟退火等。布局规划的目标是优化边界框面积和布线长度,影响芯片性能和成本。文章还讨论了引脚分配和电源规划策略,强调了这些步骤在整体设计中的重要性。
本文详细介绍了VLSI设计中的布局规划,包括布局规划的阶段、目标、术语和各种优化算法,如集群增长、模拟退火等。布局规划的目标是优化边界框面积和布线长度,影响芯片性能和成本。文章还讨论了引脚分配和电源规划策略,强调了这些步骤在整体设计中的重要性。
本文是EDA教程《VLSL Physical Design》第三章的理解和笔记(有的文字性的非算法的内容片段偏向翻译)。若有谬误欢迎探讨和指出
芯片规划主要包括三个阶段(1)布局规划(2)引脚分配(3)电源规划
其中,第一个阶段的布局规划输入为已经初步确定大小或形状的各个模块,如果不能确定形状,大小,则需要运用第二章分区的知识进行对各门电路等细小部件进行分区。
输入输出位置分配(I/O placement)能布置输入输出块的位置(input and output pads),可以在布局规划之前进行,也可以再布局规划之后再进行调整。
电源规划旨在给每个模块连接到电源网络上,保证电压供应。
第二、三章所涉及的分区、芯片规划的内容会极大地影响后续的设计,非常重要。
3.1 布局规划(floorplanning)简介
1,什么是布局规划?
布局规划是对模块的安排的过程。包括两个方面:
1)决定模块的形状和位置,以方便门规划(gate planning).
2)对于每个有外部连接的引脚,要确定其位置,以便于模块内外的引线排布。
2,布局规划的意义?
布局规划之前,不同模块之间是互相独立的,位置还不固定,形状上还有一些自由度(比如是4cm*3cm大小的块儿,我们可以决定横着放还是竖着放,或者有6:2,4:3,3:4,2:6,1:12一系列候选的大小)。布局规划把它们整合起来,固定各模块的形状和位置,这样就能装在板子上了。无疑,优秀的布局规划可以节省板子的空间,减少需要走线的距离,从而减小电路的延时、提升稳定性。良好的布局能让电路中的最长用时路减短,从而提升时钟频率。
3,布局规划需要考虑的参数?
(1)模块的面积
(2)各模块的可能的长宽比例
(3)与模块连接的外部连线(netlist)。
例子:

如图是一个例子,a的话可以有三种选择,1:4,2:2和4:1,看上去是面积固定了但是可以变比例。b是1:2或者2:1,看上去是形状固定了,但是可以决定横着摆还是竖着摆放。最优答案就是图里这种。这种摆放方式a,b,c中间不会有浪费的面积,能很好的利用这块底板。具体算法原书在这里没给,只是举这个例子说明布局规划在干什么,算法在后面会提及。
3.2布局规划的目标
1,边界框的面积和形状
面积
边界框指包含所有模块的最小的矩形框(不能斜着,可以理解为y坐标从模块的最低点到最高点,x坐标从所有模块的最左到最右这么一段位置的框)。
对于包含同样的内容模块来说,不同的布局导致不同大小的边界框,会影响芯片性能,生产成本。
想要优化这个边界框的面积,需要对内容模块的位置和形状进行优化,以保证他们可以紧密地布置在一块儿。
形状
另外一方面,有时候出于包大小(package size)或者生产方面的考量,长宽比接近1的,即“方”的模块会更受欢迎,所以全局边界框的面积和纵横比是相互关联的,这两个目标通常是一起考虑的。
2,总共的布线长度
过长的布线长度会影响这些方面:
1,信号延时 2,能量损耗
3,制造成本。过长的线除了本身成本高外,可能导致导致可能布线过于拥挤,要扩大模块大小,进一步加大制造成本。
所以布局规划的一大目标就是减小布线的长度。
书上说了一个方法,两个模型来快速评估当前布局可能要用的布线长度。好
1,把所有的模块都连接到整个布局的中心位置,这样的做法虽然不是很精准,但在中、小规模的设计中是比较高效、准确的。
2,两种描述连接性(connectivity)的模型:
(1)使用n*n大小的连接矩阵C,表达各子模块两两之间连接性。最后的优化目标如下。d(i,j)指的是i,j之间的曼哈顿距离。
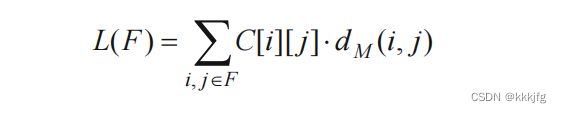
(2)使用一个最小生成树
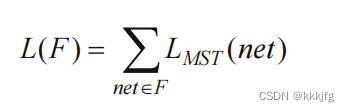
其中指的是布局中的某一个网络的最小生成树的权重和(spanning tree cost)
仔细一看,三条都是估计方法,个人感觉可能意思是前面给的方法是没布线情况下的估计方法,而后两种模型说的是连线已经有了的情况下的评估方法。
3,混合优化
对于面积和线长都要考虑的情况下,我们用加权平均的方式生成优化目标:
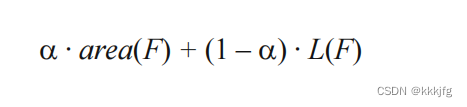
F指的是某一个布局方案。area(F)是该布局下的边界框面积。L(F)是该布局下的线长,我们通过最小化这个式子的值来优化布局方案。
但是,在实际应用中,有时候外围封装尺寸(pakage size)或者空腔尺寸是固定的时候,可能会出现模块的总边界框尺寸固定的情况,那么模块面积就无法放进优化目标函数里了,问题变成了在满足面积限制的的情况下优化布线长度或其他目标。这种时候,面积应视为限制条件而非优化目标。
4,信号延迟
1990年代时,信号延迟主要源于用来做门电路的晶体管,现在,延迟的时间主要花在模块之间的电路上。所以这项延迟的降低是很重要的并会影响芯片可达到的时钟频率。优秀的布局方案应该是不同块之间只使用短线连接以满足所有时间方面的要求。一般来说,关键路径和关键网络会被给予更高的权重,以尽可能地使它们跨越更短的距离。
布局优化已经可以使用静态时序分析的方法识别关键路径。如果时间要求不满足,线路延迟超过了限制,布局优化应该修改,以减短关键路径的延时,以最终满足限制。
3.3术语
1,矩形分割(rectangular dissection)。指的是把芯片区域划分为一组快区或非重叠矩形。
2,切割式平面规划(slicing floorplan)。指的是通过反复切割矩形而得一种矩形分割方案。这样的方式通常从整块芯片出发,使用横切或竖切的方式把芯片分成两半。
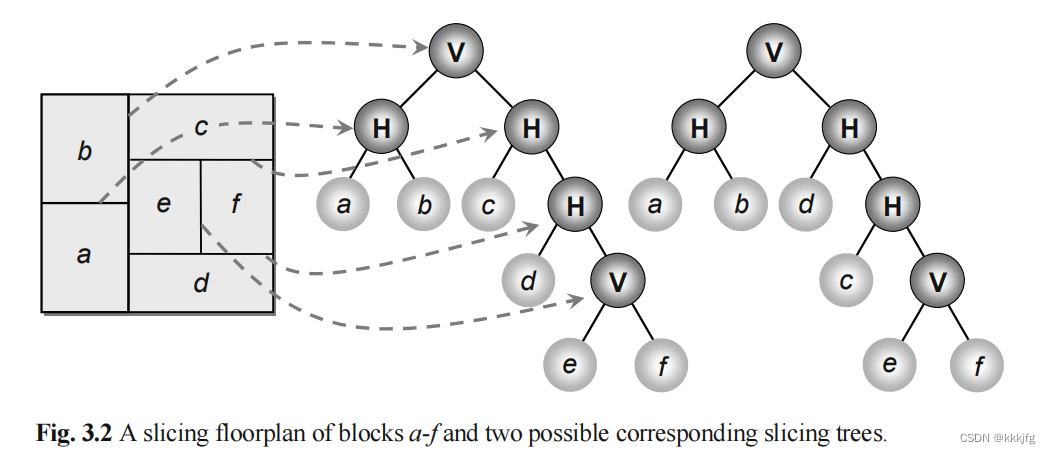
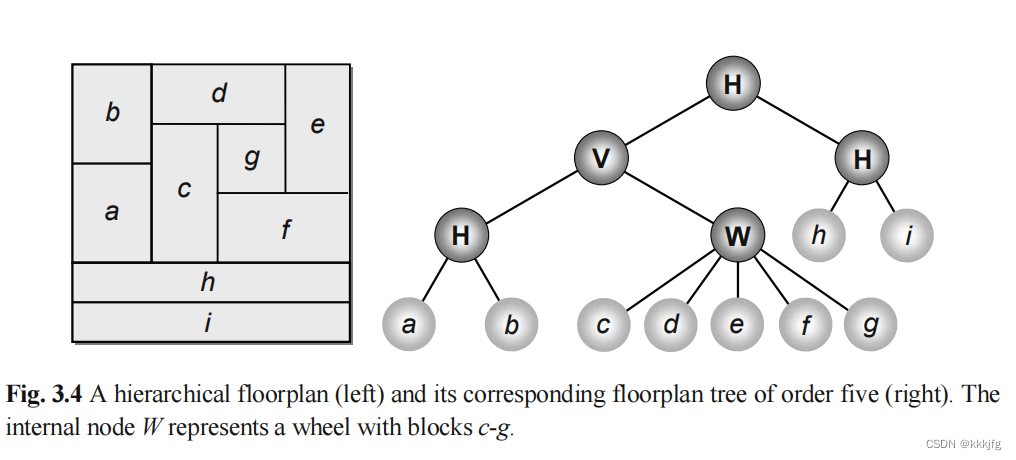
3,切割树/切割式平面规划树(slicing tree or slicing floorplan tree)。均指有着k个叶节点和k-1个非叶节点的树。这个树的每个叶节点代表一个模块。每个非叶节点表示一个横向切割线或者纵向切割线。这本书使用标准表示,即用H和V表示横切和纵切(horizontal and vertical cut)。这种树的特点是每个非叶节点都有两个子节点。
基于这些,我们可以把任何一种切割式平面规划用至少一种切割树表示出来。下图左边是一个切割式平面规划,右侧是两个切割树,两个切割树都可以表示这个规划。
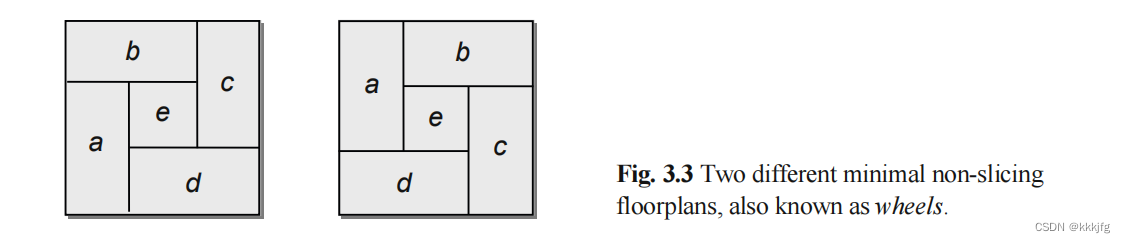
4,非切割式平面规划(non-slicing floorplan)。指不能通过对父模块的横切纵切来形成的平面规划。最小的非切割式平面规划如下,又称作"轮(wheel)":
5,平面规划树(floorplan tree)。指一个用于表达层次式平面规划的树。每个叶节点表示块区,一个非叶节点代表一个横切,纵切或者轮。
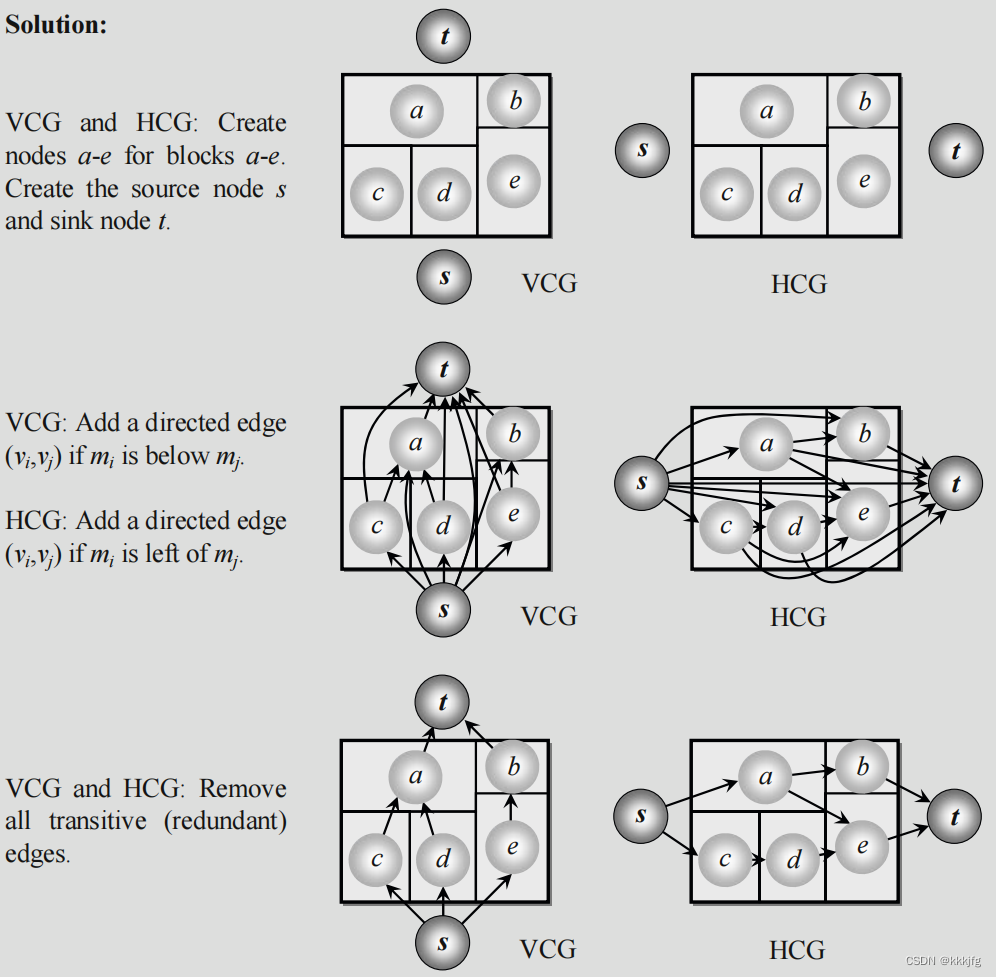
6,约束图对(constraint-graph pair)。指的是一对用于表示一个平面规划的有向图,即纵向约束图和横向约束图,这两个图用于表示块区位置之间的关系。
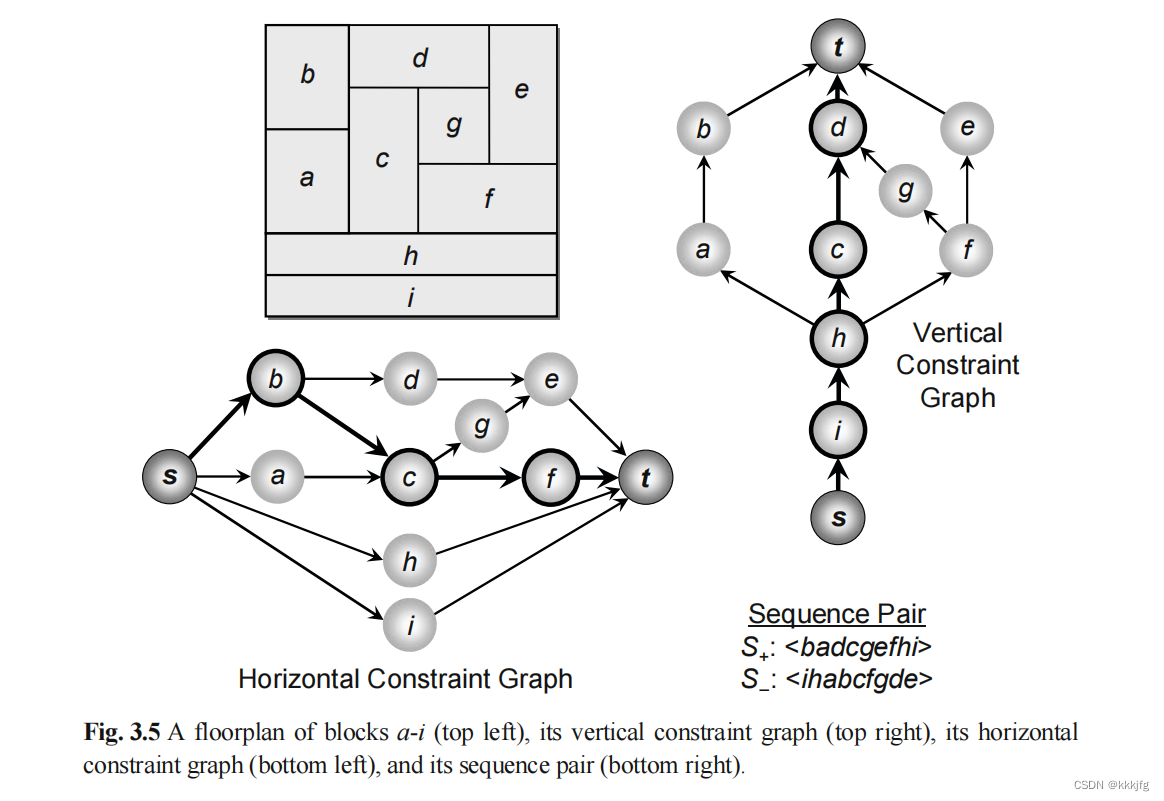
约束图对的含义如下:
在横向约束图(VCG)中,若a,b两点之间有连线,则a,b两点之间挨着,并且连接边是纵向边。被有向边指向侧为右侧,s,t点权值为0,这个0不代表任何含义,其他代表区块的节点的权重为区块的宽度。
在纵向约束图(HCG)中,若a,b两点之间有连线,则a,b两点之间挨着,并且连接边是横向边。被有向边指向侧为上侧,s,t点权值为0,这个0不代表任何含义,其他代表区块的节点的权重为区块的高度。
在VCG中,最长路代表着整个模块的宽度。HCG中最长路代表着整个模块的高度。如图3.5所示,最长路都被标了出来。
图3.5就是一个约束图对的例子。在约束图对中,源节点和汇节点的权重为0,其他节点的权重代表宽度或者高度。比如左侧的横向约束图,点的权重代表点的宽度,右侧的纵向约束图点的权重代表点的高度。有一条箭头从c指向g,代表c,g之间挨着且有一段纵向边相邻。
7,序列对(sequence pair)。指的是一个对有序序列,用于表达模块的序列关系。与约束图相比,序列对同样能表达平面分布的各块区之间的位置关系,但少了权重,不带高度和宽度的信息。
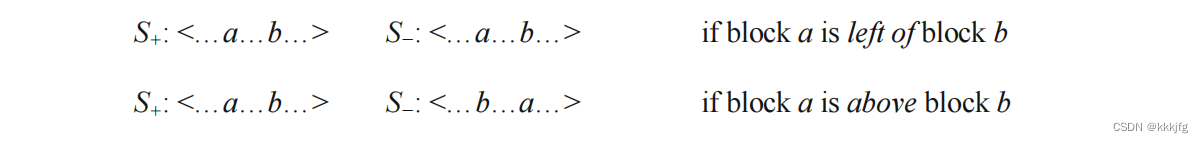
以上是序列对的组成规则,很简单。在序列对的两个序列,
中,假如a在b左,或者a在b上方我们必须保证在
序列中a在b之前出现即可。若a在b左侧或者a在b下方,在
中,我们都应保证a在b之前出现。总结以下就是,
从左到右从上到下排列,
从左到右从下到上排列
拿图3.5来说,中,b肯定是第一个,因为b,a,h,i是最左排,第一个肯定是这四个中的一个,若a,c,d先出现,b在他们后面。都会违反
的生成规则。第二个的话就a,d都可以,都不会违反规则。
差不多。不过是排列规则不同罢了,不过为什么要费事搞两个序列呢?因为在序列对的生成规则中,单一个
或者
序列存在歧义,比如a,b,c,d,e这么一个
序列,可以是a到e从左一直排到右,也可以是从上往下排,但加上
的a,b,c,d,e,我们知道它确实是从左往右,而
如果是e,d,c,b,a就是从下往上了。两个序列能消除一些歧义。
3.4 布局规划的表示方式
这一节的主要内容是讲述各种布局规划表示方式之间的转换,包括(1)把一个布局规划换成约束图对(2)把一个布局规划换成序列对(3)把序列对转换成布局规划。现在的布局规划算法在使用序列对的时候并不需要把它转换成约束图再进行计算,但约束图提供了一种中间表示,有助于理解。
3.4.1把一个布局规划换成约束图对
一共三步:
1,把每个分块转换成一个图里的节点
2,在纵向约束图中,对于所有的块,若在
下方,则添加一条有向边
3,把所有可以通过推断获得的有向边去除,即若有,
,
三条边,则去除
。

以上是书中给的例子,但我感觉比较迷不知道为什么要这样,为什么不在第二步的时候就加一个判定条件,仅当两个节点有边相邻再连线不就行了,何必先加很多线再删线?
3.4.2把一个布局规划换成序列对
序列对中,点的顺序是从上到下,从左到右的,在
中,点的顺序是从下到上,从左到下的,这些关系可以由约束图对转换而来,以下提供一种方法直接判定是否存在两块之间是否存在一个块在另一个块左侧,或者是否一个块在另一个块上侧的关系,也比较好想:
设两个点的位置分别为 ,
宽高分别为
,
,则以下的公式可判断:
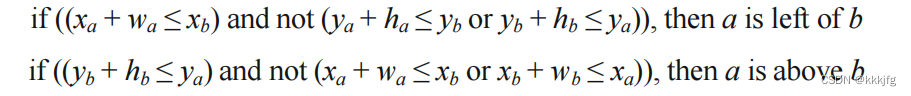
即判定a在b左侧的条件有两条:
1,a最右侧小于等于b最左侧,
2,a,b块的y的范围有所重叠,即不会有a的最高点低于b的最高点,也不存在b的最高点低于a的最低点的情况。

看例子的话意思应该是根据约束图对的各条边,生成各个节点之间的前后关系,逐渐加入S中,然后逐渐调整使每次调整都能满足当前所有需求即可。
3.4.3把序列对转换成布局规划
把序列对转换成布局规划还需要以下三个信息:
1,各块的长宽
2,这个布局规划的位置
3,包的方向
第一条显然,因为序列对没有包含这个信息。二和三是什么意思呢?我的理解是,和
虽说规定了左右,上下关系,但是,怎样算左,怎样算上呢?所以我们需要规定左和上的方向,2,3条合在一起,看起来有点像是把坐标轴画好,定好坐标轴的原点和x,y的指向这个样子。
一个叫“最长相似子序列”(longest common subsequence, LCS)把序列对转换为布局规划。

以上内容展示了这个算法的输入输出是什么。从第三行可知,算法输出整个模块的长度W,各个模块的x坐标,所需的材料是序列对,和每个分块的宽度(第三行的weight来自第二行的width)。
第6行则是把做一个倒序操作,再把weight换成各个模块的高度,即可得到各个模块的y坐标和总的高度。
总结一下,重点就是第3,7行,这两行告诉了我们LCS所需的内容和可以得到的结果。
具体来说,LCS算法如下:

以上LCS算法对应的坐标输出就是position,即第七行,以及总共长度,即第13行。
大致流程是,整个算法在中选模块,每次循环从前往后选中
的一个模块。并在
的序列中找到这个模块,做一些更新操作。举个例子假如
是a,c,d,b,e,
是c,d,a,e,b的话,我们五次循环分别是更新块a,块c,块d,然后是b,e。第一次循环,我们在
中找到a的位置,更新a及其以后的a,e,b的信息。
关键的输出position是通过length决定的。而length代表着从前往后的累计长度。从直觉上理解第七行,为什么position[block]=lengths[index],就是前面已经有了一个假如说长度为7的模块垫着,我们就只能把这个模块放在x=7的位置。
以上两个设定是理解这个算法的关键。一,就是按的顺序取模块,并更新在
上该模块及往后模块的信息。二,位置直接从累计长度中取。
为什么这么做是对的呢?因为是从上到下从左到右,
是从下到上从左到右,所以如果我们想象一个模块有左右两块的话:
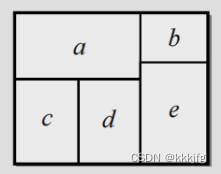
观察左侧(a,c,d)与右侧(b,e)的分界线,如果整条分界线上有东西覆盖的话,或是
中,右侧块区(b,e)肯定是出不来的。具体到这个例子的话,
可以是acdbe或者abcde,
是cdaeb,a得在b,e之前出现,所以b,e的x坐标只需要加上0加伤a的宽度。如果a是c,d那样左右两块呢?根据上面的分析,b,e起码得在分界线暴露之后出现,而分界线暴露了的话,左侧必须有一行清空了,所以前面的宽度全部累加起来即可。
累加是怎么办到的?我们先来更仔细地看一下LCS算法9,10,11行,它每次取中的元素之后,是在
中找到相同元素,并使后面所有元素的length累加都不小于它的右边位置的。的由于
或是
中都是不允许右块先于左块出现,比如本例中有c,d出现,我们看到,
和
中c都在d前,所以取d的时候,c已经更新过了,d会在c的基础上再加d的宽度。而上下关系的块之间,如b,e由于在
和
中分别为b在e前和e在b前,所以更新cdaeb这5个块的时候,b会先更新,不影响e的位置,而后e更新,是在a,c,e的基础上更新的,b不影响它。总结一下,就是由于
和
中,左右关系同序,导致累加,上下关系颠倒,导致不累加。
这样看可能还是很抽象,书上完整的算法例子如下:


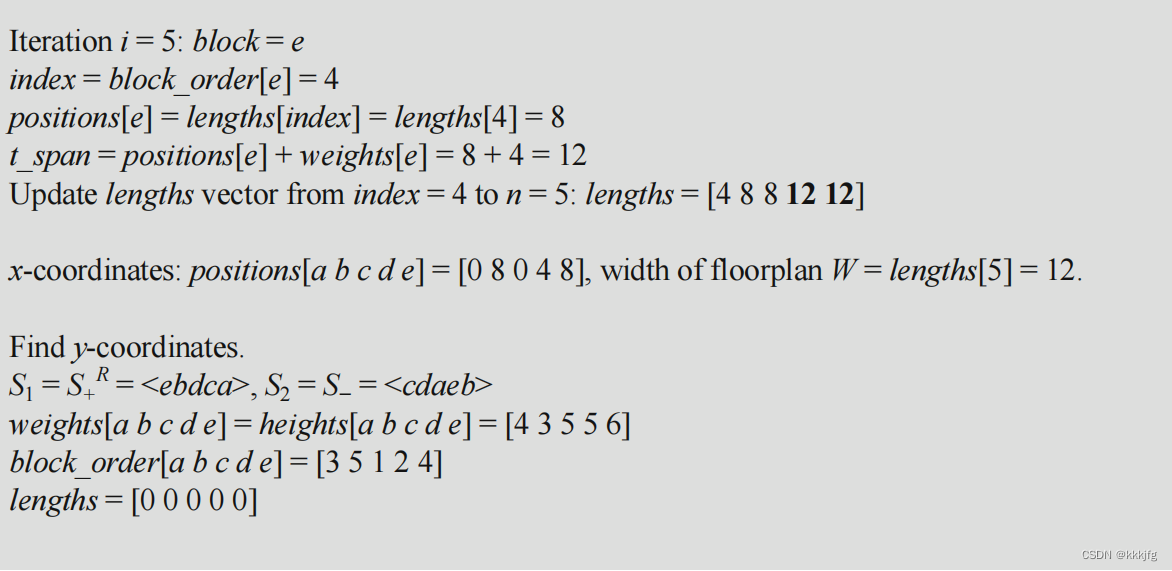

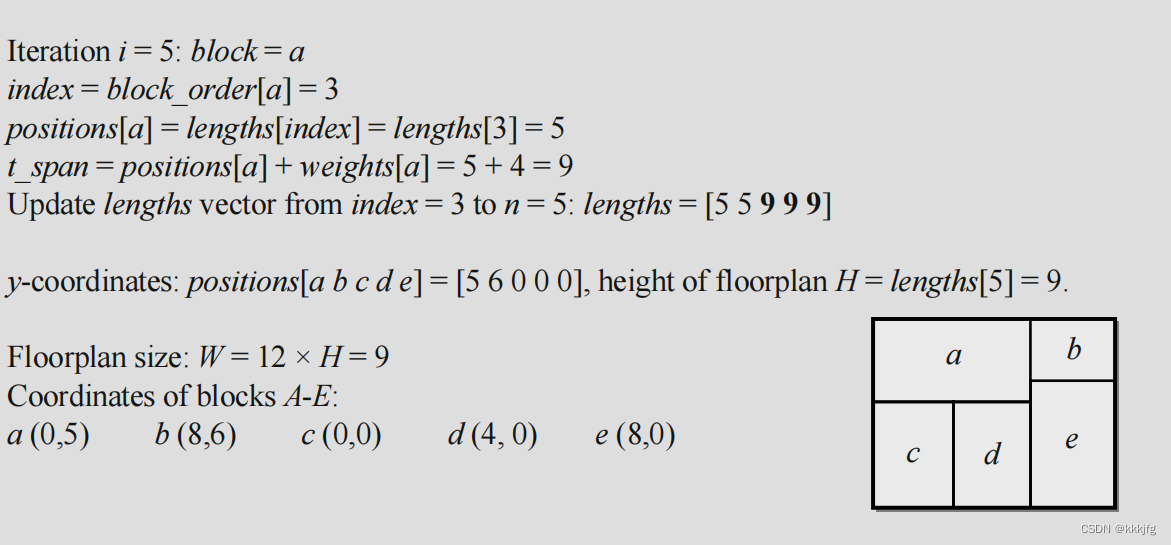
注意算y时反序了,这样就是从下到上,从右往左,和算x时原理一样,y方向与
同序,是累加的,x方向逆序,不累加,这样就算出了各个块的y坐标。这种说明方式不是很严谨,不过可以帮助理解。
3.5 布局规划算法
这一节主要讨论布局的优化算法。将包含布局尺寸优化算法,主要希望得到尽量小的模块尺寸及该方案对应下的子模块的长宽。并会收纳包括集群增长(cluster growth)和模拟退火的算法来优化布线,以尽量减少布线长度,和平衡布线长度与面积。
3.5.1 布局尺寸的优化(Floorplan Sizing)
此节介绍一种较为早期的方法来优化芯片的尺寸。这种方法能充分利用顶层模块和子模块的形状和长宽限制。
以下是这个方法需要用到一些概念比如形状函数(shape functions)和角点(corner points)的概念:
形状函数,或者说形状曲线指的是在面积限制下的描述长宽关系的一个函数。假设一个块区的长宽为h和w,面积为area,那么面积有时候是有最小值的,因为要把所有东西装进一个模块里,大小受到限制,即:
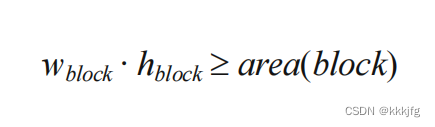
把w看成是一个变量,则上式也可以改写为:
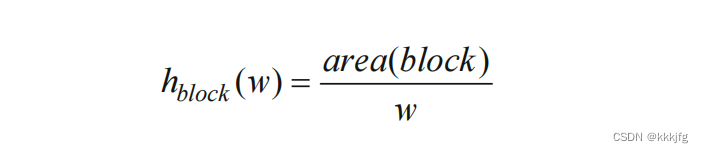
画出来大概长这样:
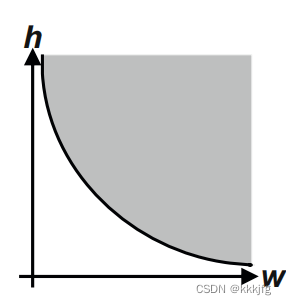
这里h_block表示的是最小h,h≥h_block。
由于h,w过小显然也不合理,比如做一个长长的却只有0.1毫米宽的芯片没意义,因为不好生产也没什么应用面,所以有时长宽会有一个最小值限制。再把长宽整数化处理之后,就会出现一些角点,代表了这个模块的边界情况的长宽的取值。
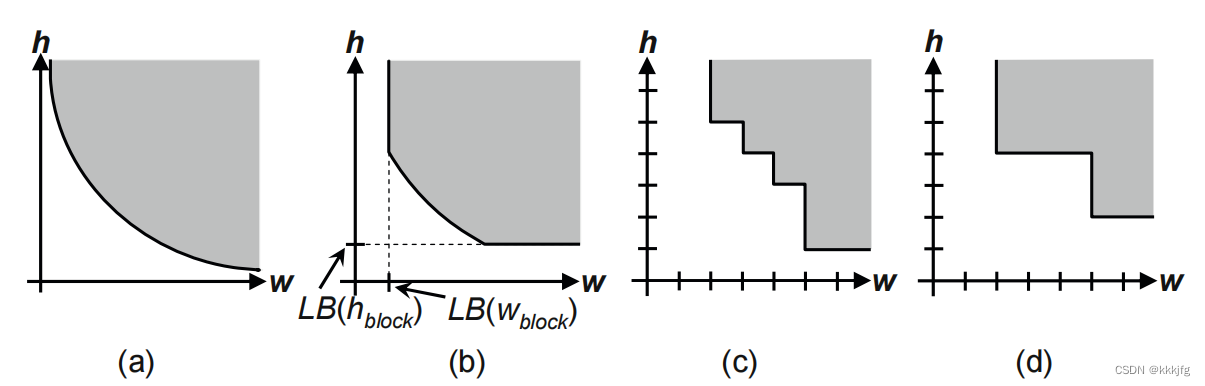
a:形状函数,灰色代表可取。
b:加上最小长宽取值之后的形状函数。
c:将长宽取值离散化,即整数化处理之后的形状函数
d:加入其他的可能的约束(如朝向限制等)之后的形状函数,可选择的边界值进一步减少。
在c,d中每个可选择的边界值(x,y)就是一个角点。
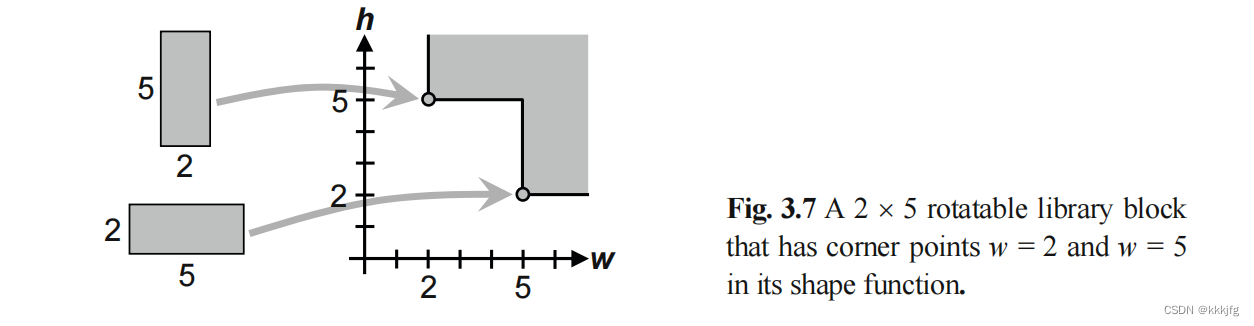
如图,该图绘制了一个确定长宽为5比2,却还没确定方向的模块的形状函数,它有两个角点,分别代表竖着摆和横着摆。
这个算法分两步:
1,构建各分块的形状函数
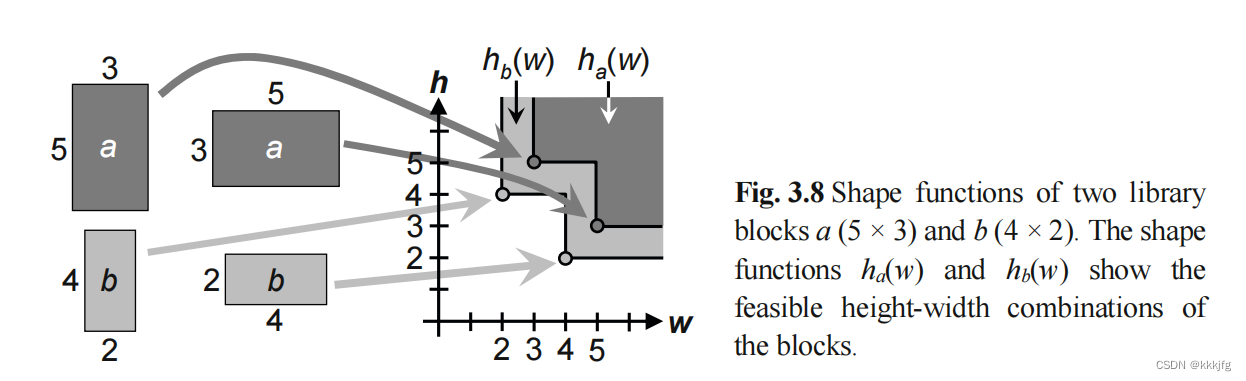
如图,两个分块都有两种形状选择,并把这个选择画在了图上。
2,确定整个模块的形状函数
整个模块的形状函数的构建方式也很简单,就叠加即可。宽度的话取子模块的最大值。
即,
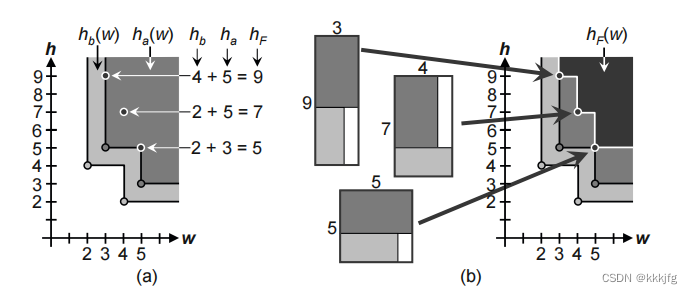
叠加好的顶层模块如上图所示。
说实话顶层宽度取子模块最大值这个操作我是真没看懂,自变量不同步的话应该怎么叠加函数呢?但是如果我们只取这个阶梯函数上的角点看的话,倒是合理,就直接把两个模块叠高高即可,宽度取最大值,这很好理解。这样看的话我们直接把两个子模块的函数相加即可得到图b中的。
不过呢,这里还是有一个小疑问,就是三个或以上的模块就不是简单的叠高高了,这样宽度取最大值真的有效吗,不过我在这本书里还没找到这个算法的三个子块的例子。假如这个算法真的不能适用于多个模块的话,我这俩块直接穷举叠高高方案不就行了吗?犯得着用这个算法吗?
所以我想到这个算法的启示其实是枚举的方式。它其实是枚举了所有可能的总模块宽度,即两模块所有可能的长、短边长度,然后我们一旦选择其中一个值,有一个模块的形状就固定了,我们再找这个宽度限制下另一个模块的最小高度即可,然后叠起来。设形状可能状态为n,则这个算法的复杂度是,直接穷举堆叠方法复杂度是
。
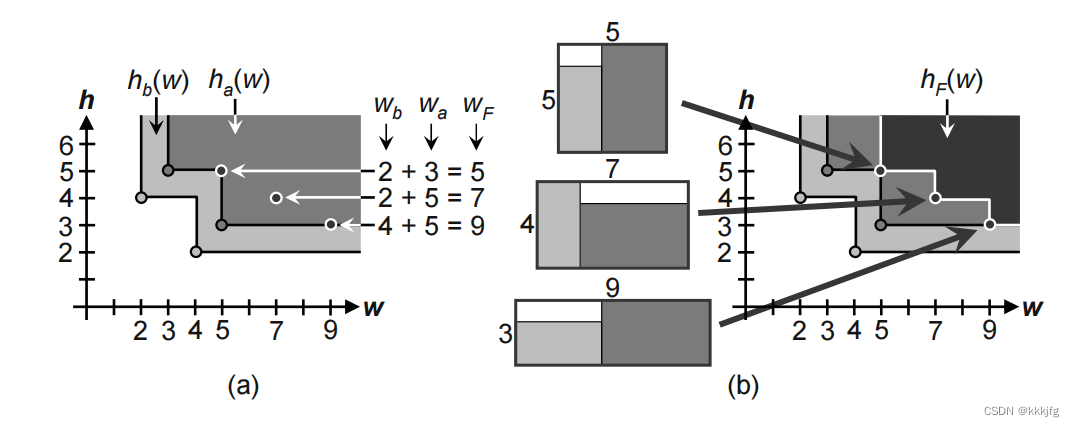
也可以横向叠,高度取最大值。
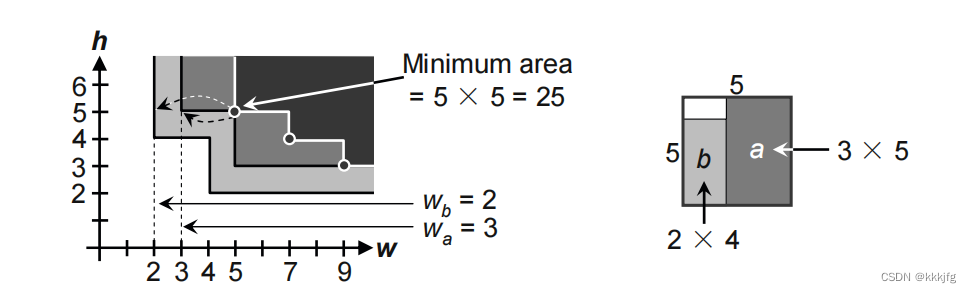
3,确定最小面积。
由上两张图所示,这种算法的顶层模块的角点都能与子模块状态对应,所以直接计算最小面积取方案即可。
以下给了一个这个算法的例子: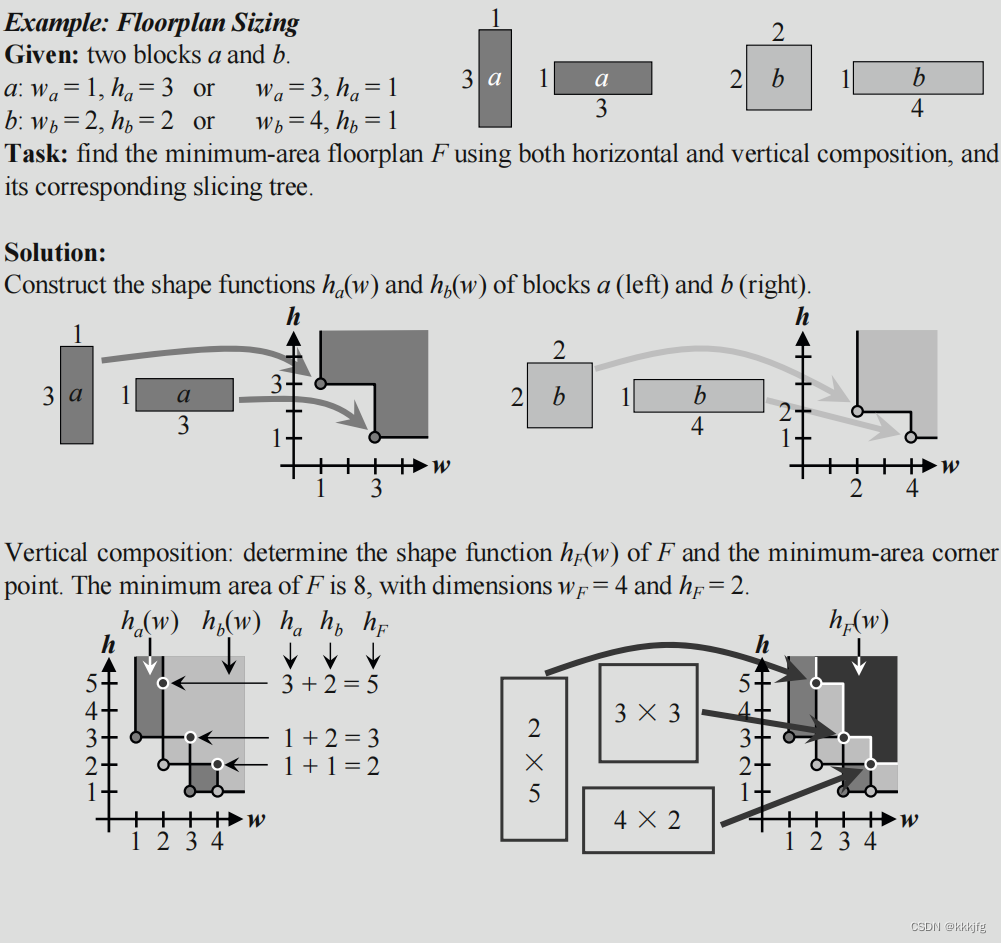
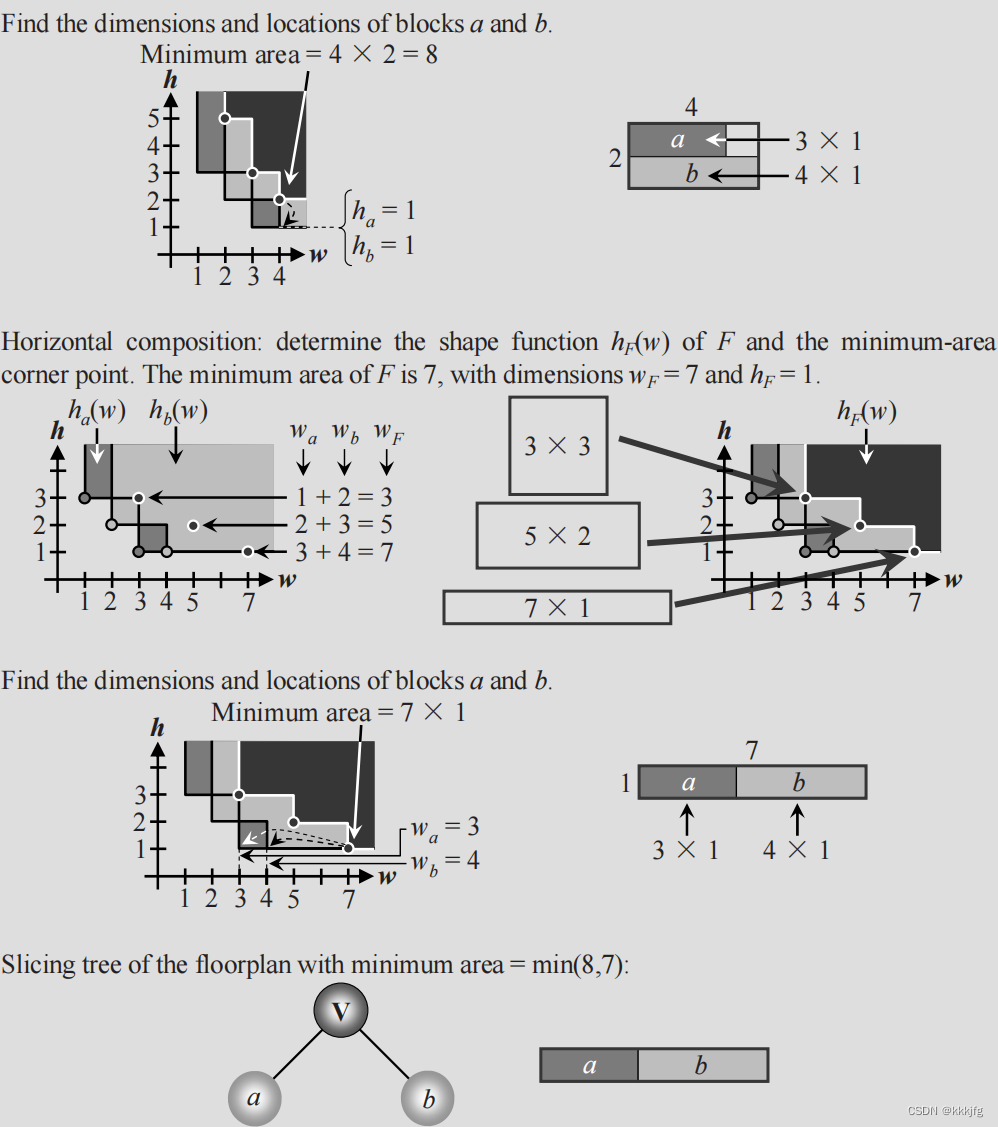
3.5.2 集群增长算法(Cluster Growth)
简介:这是一个通过反复选块、添加到现有模块中的一个算法。每次迭代的时候只选取一个块,横向或者纵向并入整个模块中,并根据现有模块的情况调整方向。这种算法不能像3.5.1那节提到的算法一样能充分考虑子块的形状,但能兼顾总模块和子块的形状的算法还没有出现。
以下是一个这个算法的例子:

如图,我们需要依次加入a,b,c,最终完成整个模块的搭建。
刚刚提到了把a,b,c依次加入,为什么这个顺序是a在前c在后呢?顺序应该怎么定?下面介绍一个叫"线性排序"(Linear ordering)的算法。
线性排序是一个启发式算法,通过模块之间的要连的连线来确定选块和加入布局规划的顺序。
这个排序算法会先选一个初始块(随机或者参考连接性)。
然后给剩余块打分,选一个分数最高的,选完之后再更新其他块分数反复迭代。
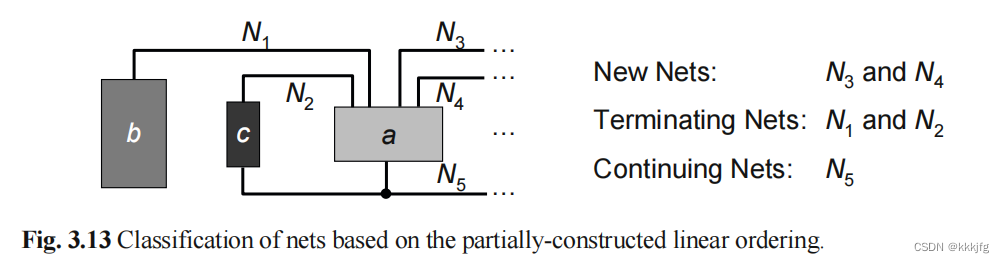
以上是一个连线图,假设a,b,c已经选完了,其余模块的顺序未定(为方便起见我下面称已排序完的块的集合叫旧集,未排的叫新集),那么它会区分三种线:
1,新线,只连新集的线
2,延续线,既连旧集,又连新集的线
3,终止线,只连旧集的线
那么其余模块的打分就会是各模块身上连的终止线数减去新线的差值。分高者为下一个被选中的块。(对应4-9行,选中的集对应为)
若打分相同则选择终止线多的块区。(对应16,17行)
若还是有多个选择选不出来,则选择延续线多的块区。(对应12,13行)
还有多个选项,则选连线最少的。(对应14,15行)
实在没办法就随机选。(对应16,17行)

以下给了一个例子:
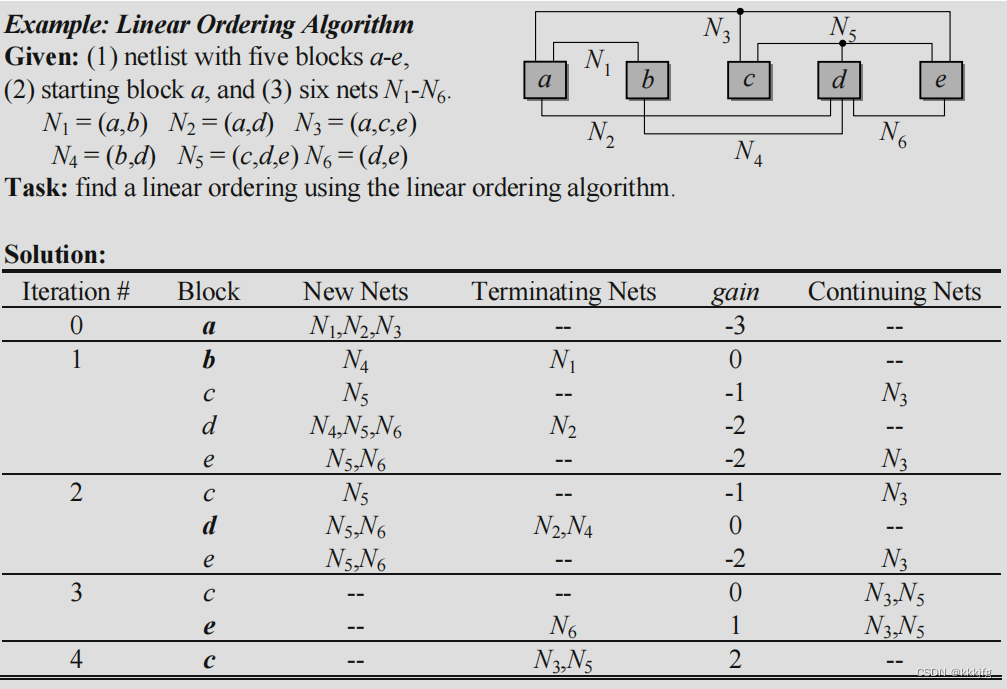
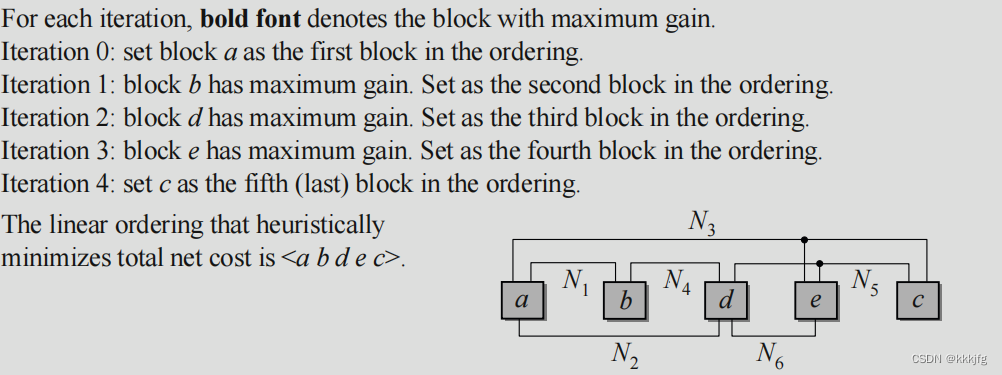
注意这个iteration 0,我想了半天这个a算出来gain有什么用,最后结论是没有用。因为a没放在这里面算,不参与打分排序迭代这一流程,它是随机或者通过连接性,或者什么规则选出来的,评价方法不一定和迭代时一样。当然我觉得这里其实也可以放进去,先把a,b,c,d,e的gain都用终止线减连接线的方式算出来呗,不过呢,一开始并没有终止线算,这样可能也不太科学。毕竟这个算法给人的直观感觉就是,优先选与已选模块连接线多,与新模块连接线少的模块。
由于这个算法大致是从左下角向右上角排列的,所以我大概可以理解为,旧集在左下角,新集在右上角,与旧集连线多的如果越后选,位置就越来越偏右上,导致连线增长,同样的,如果与新集连线多,我们后选,它的位置也会浮动到相对右上的位置上,减少走线长度。
集群增长算法(Cluster-Growth)
在这个算法中,各块区首先是进行排序,然后逐个拿出来加入到布局规划中。对于每一个模块往布局的加入,希望整个模块能在x方向和y方向均匀增长,并尽可能同时满足一些条件,比如总模块的形状约束,走线长度,浪费的空间等等(算法的第五行)。

以下给出了一个例子,这个例子的优化目标是尽量减少布局的面积。
集群增长算法是一种简单、快速、能产生中等质量解的方法,所以常用于生成迭代式方法,如模拟退火算法的初始解。

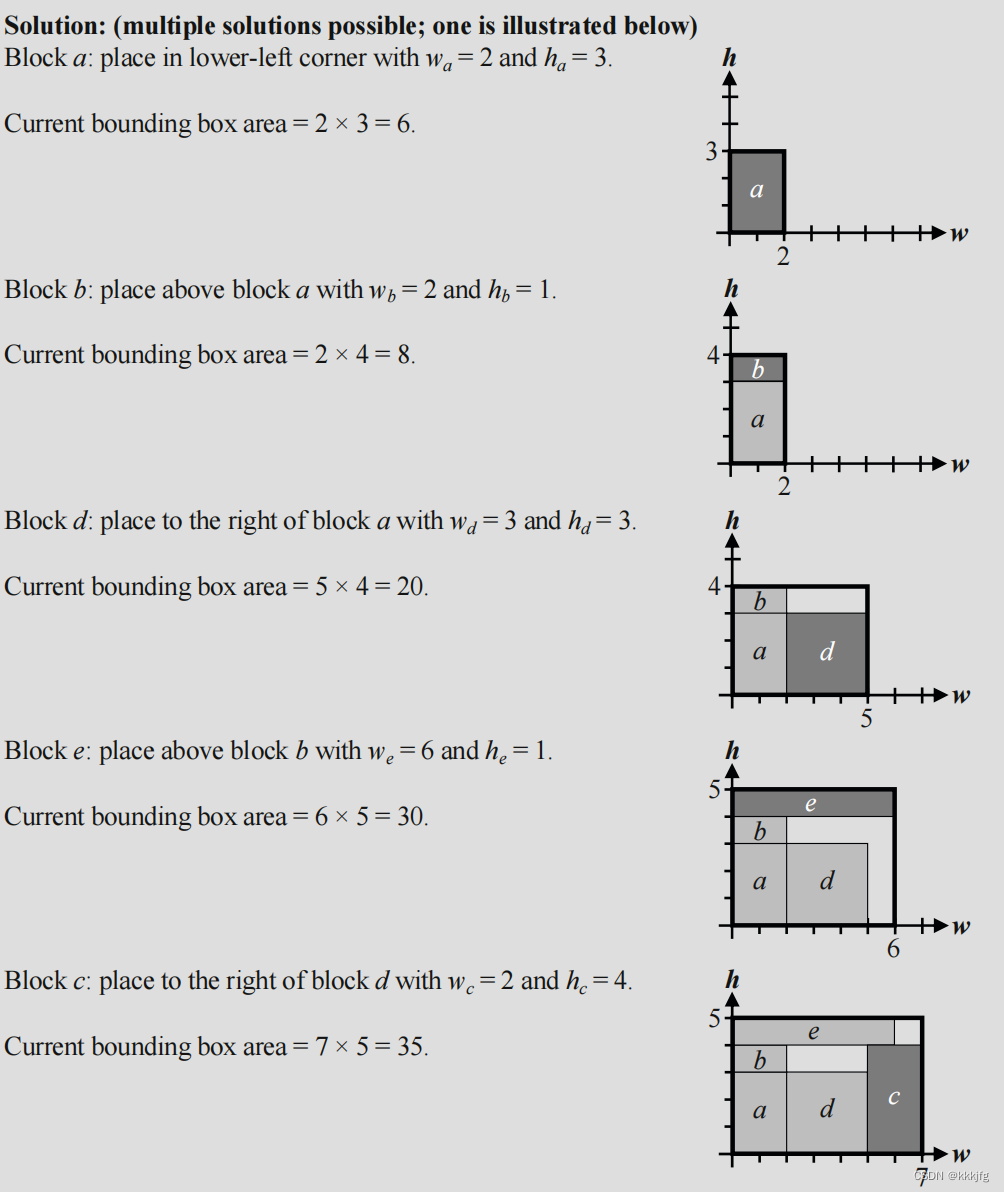 书上这个例子我是看着挺迷的,不知是怎么办到实现达到面积最小的,刚放完a放b的时候为什么放上方?
书上这个例子我是看着挺迷的,不知是怎么办到实现达到面积最小的,刚放完a放b的时候为什么放上方?
我的理解是这个算法是个贪心算法,以上提及的“边界框面积最小”不仅仅是最终的优化目标,也是每一步的摆放目标,只关注本步的边界框使之最小即可。由于b摆在右边是9,摆在上边是8,所以摆上面。
3.5.3模拟退火
这一节书上没有提到具体的模拟退火布局规划算法,但讲了一下模拟退火的基本思想。
模拟退火就是不断做出小调整的算法,区别于贪心算法总是朝着目标损失降低的方向走容易陷入局部最低点,模拟退火对目标损失的升高的一定程度的容忍度使得算法降低了陷入局部最优的风险

如图若I是原点,则贪心算法容易陷入L点,无法去到G点
以下一段是书上描述模拟退火原理的句子,由百度翻译而来:
模拟退火原理。在材料科学中,退火是指高温材料的受控冷却,以改变其性能。退火的目的是改变材料的原子结构并达到最小的能量配置。例如,高温金属的原子处于高能无序状态(混沌),而低温金属的原子则处于低能有序状态(晶体结构)。然而,根据单个晶体的大小,相同的金属可能会经历脆性或机械硬度的原子构型。当高温金属被冷却时,它会从高度随机化的状态变为更结构化的状态。金属冷却的速度将严重影响最终结构。此外,原子沉降的方式本质上是概率性的。实际上,较慢的冷却过程意味着原子有更大的机会以完美的晶格形式沉淀,形成最小的能量配置。冷却过程分步骤进行。在冷却计划的每个步骤中,温度在指定的时间内保持恒定。这允许原子在每个给定温度下逐渐冷却并稳定,即达到热力学平衡。尽管原子有能力跨越大距离移动并产生新的高能态,但这种构型发生剧烈变化的概率随着温度的升高而降低。
随着冷却过程的继续,原子最终将以局部的、可能是全局的最小能量配置。温度下降的速度和步长都会影响原子的沉降方式。如果速率足够慢且增量足够小,原子将很有可能以全局最小值沉降。另一方面,如果冷却速度太快或增量太大,则原子不太可能达到全局最小能量配置,而是将以局部最小能量配置。
模拟退火的优化方式。模拟退火的原理可以应用于组合优化问题,在寻找最小值的问题中,优化问题的过程与找材料的最低能量态相似,所以算法会接受一定程度的"混乱"(高目标损失),并会模拟退火的过程最终形成"有秩序"(低目标损失)的解。
模拟退火的过程是反复进行改变、评估改变和决定是否要接受改变的过程。模拟退火引入了两个变量,T和r来模拟"退火":
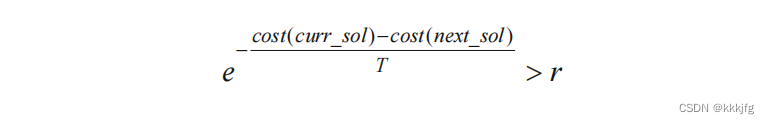
这里r是一个0到1的随机值,T是根据当前评估的损失来决定的一个数,若当前损失还很大,则T较高,损失较小则T较小。cost(cuur_col)是当前损失,cost(next_col)是调整后的损失。
我感觉书上这里cost(cuur_col)和 cost(next_col)顺序写反了(上图为书中截图),但核心思想就是当损失下降的时候,接受改变概率高,损失上升的时候,让接受的概率减小,并且T代表温度,温度越高代表着越混乱,接受改变的概率也越大,随着算法进行,T会随之慢慢变小,接受变化的概率减小,让结果逐渐趋于稳定。
算法
算法首先选择一个初始化的开始局面 init_sol(第3行)
然后分多步迭代,每次选中两个块(第8行),然后尝试做出一些调整(第9行),若这个变化能降低损失,则直接接受这个方案(12,13,14行),若会拉升损失,则根据模拟退火的优化方式进行一个随机并判断是否要接受。

第17行中,当T温度趋于无限大时,趋于0,
趋于1,r取值0到1之间,所以几乎肯定接受变化,当T趋于0,
趋于负无穷,
趋于0,则几乎肯定不接受。
基于模拟退火的布局规划算法
第一个基于模拟退火的布局优化算法由1984年提出后,就成了一种重要的应用在布局规划的算法。
其应用可分为两类。
一类是直接作用在物理布局上的,模拟退火的坐标,大小,形状等参数进行直接的优化。这样做的坏处是不好处理重叠,需要在优化过程中允许中间态有重叠发生,而后再加入惩罚函数进行约束以生成合法解。
另一类是作用在抽象过的布局上,例如树,限制图等,这样做的好处是中间过程不会发生重叠。
3.5.4 集成式的布局规划算法(Integrated Floorplanning Algorithms)
一些分析技术把布局优化问题转换成一系列的等式。这些等式可以描述边界条件和块区之间的关系,使计算结果的块区不相交。目标方程能量化平面规划的一些的重要参数。
混合整数线性规划(mixed integer-linear programming, MILP),是一种位置变量为整数的算法,能求解全局最优解,但复杂度较高只能处理100个块区规模以内的问题。
线性规划(linear programming, LP)速度更快,但不限制位置为整数
3.6 引脚分配(Pin Assignment)
引脚一般布置在模块的边缘,但最佳位置取决于模块之间的位置关系。引脚分配问题指的是把线连到该连的引脚上,并尽量减少寄生回路、增大连通性。

上图是一个引脚分配的例子,分配结束之后,每个引脚将与一个外部设备的引脚相对应,并连接在一起。
如果说,内部引脚与外部引脚确实是一一对应的,那剩下的事情倒比较倾向于路径规划问题了,引脚的分配一个可以优化的点是,我们应该利用一些电路意义上"等价点",即交换连线不改变功能的点对。适当交换它们的连线,以最短化连线,和尽量较少线路交叠。
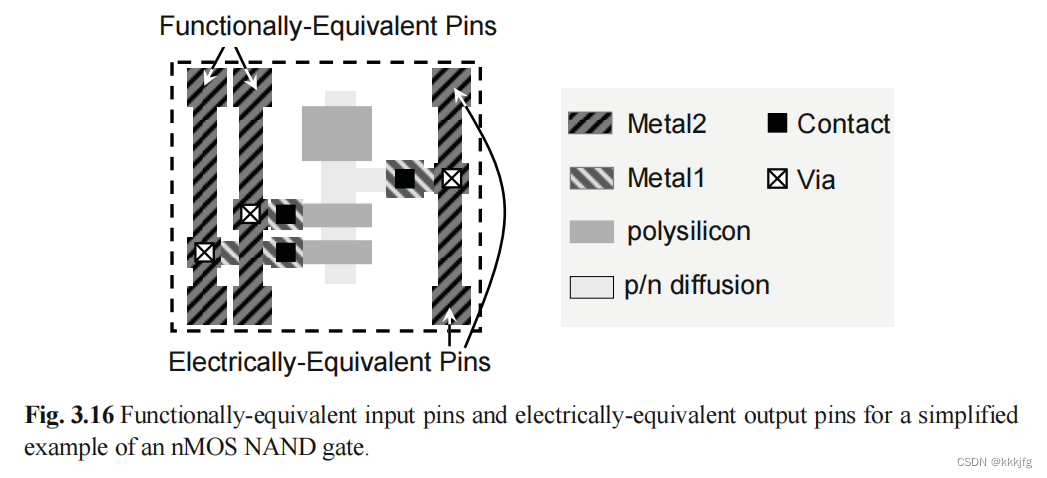
如图与非门的两个输入实际上是等价的,a与或b,b与或a,这两者是等价的,输出引脚的话,从上面引脚输出,从下面引脚输出也是等价的。输入引脚也有上下两端互为等价引脚。
利用这点我们可以做一些优化:
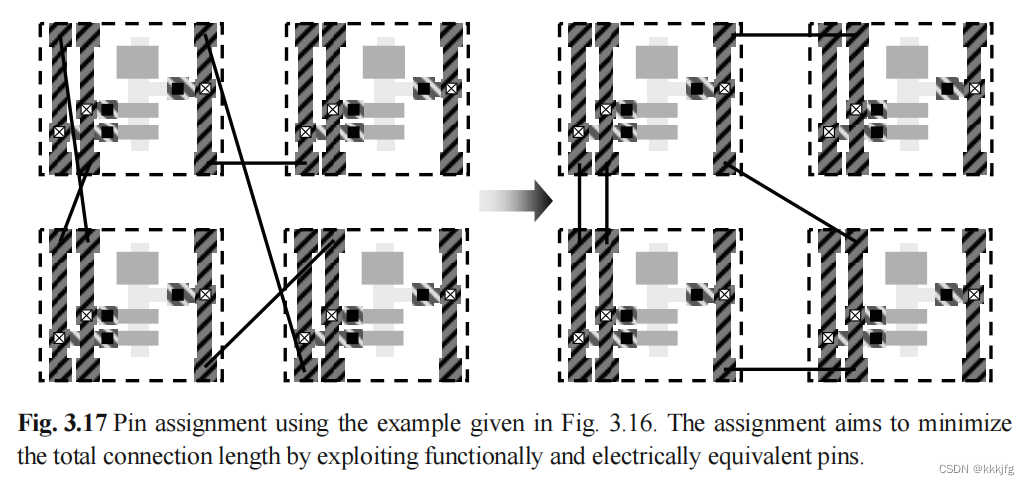
上图左边是一个电路,右边是对它的优化,根据观察发现它们其实是等价的,但右边的交叠更少、布线更短。
使用中心圈算法的引脚分配
这种算法使用场景是,外部有一些等效点待分配,如下所示:
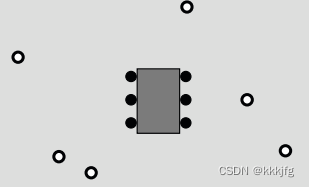
算法旨在找出一个合法的没有重叠的连线方案并减少线的交叠。
这个算法会以主模块为中心,对内点和外点分别画两个以最近点的距离为半径的圈:
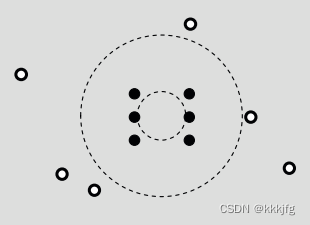
然后把各点投影到这俩圆上:
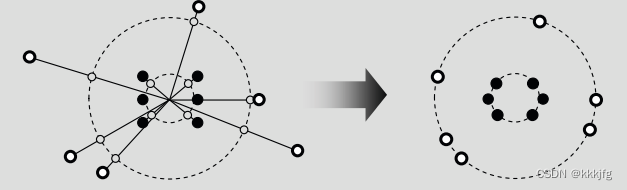
然后随便连一个外点和内点,再顺时针或者逆时针顺序一一连好就行了。这样可以保证不重叠。

把所有可能的方案都试一遍(这图片里的例子显然只有6种),选一个欧几里得距离最短的采纳即可。
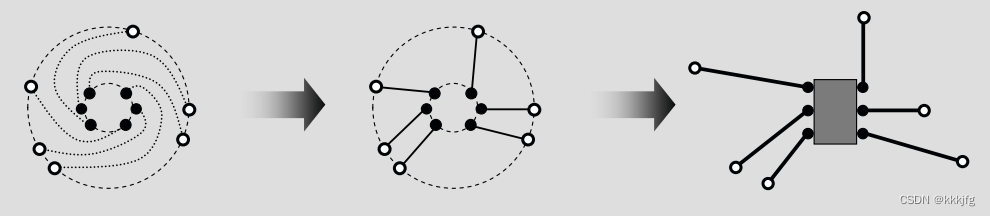
如上图左侧是一个可能的方案,中间是最佳方案,右侧是再换回电路图中的连线图。
拓扑引脚规划(Topological pin assignment)
这个算法提出于1984,改进了中心圈算法,它考虑了外部的块区位置,并能解决有遮挡和障碍的情况。

如图b是外部块区,m是主模块,这样显然无法使用中心圈算法,但是在拓扑引脚规划中,我们可以从m向b连一条射线,与b的远端交于d,我们以这个为分割点展开b的点到一条线上,这时候再把线上点投影到m的一个外圈上,用中心圈算法就可以处理了。
这个算法还可以处理外部模块的互相遮挡的情况。
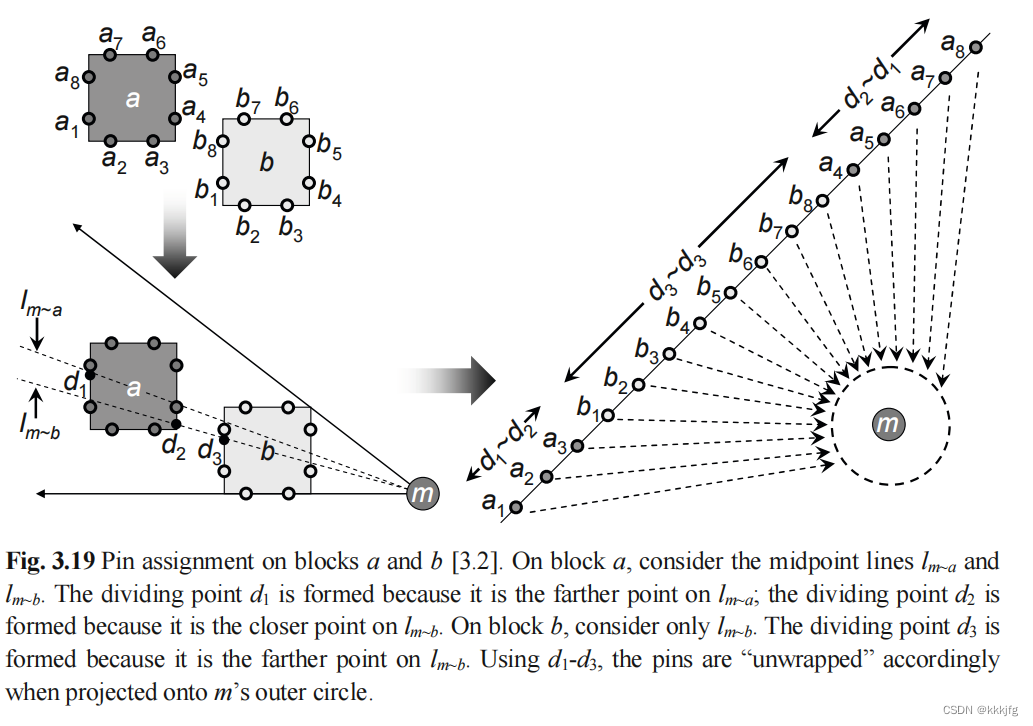
如图,对于m模块来说,b把a挡住了,但也有办法,办法是做两条射线,分别由m到a,和由m到b,对于近的模块b,我们只看与b的远交点d3,对于a,我们看a与
的近角点d2, a与
的近角点d1,b的话按单模块的方式正常展开即可,然后a的话,讲道理是以d1为分割点直接展开即可,但我们在这里把它用d2分成上下两半,下半接在b的展开线下侧,上半则接在b的展开线的上侧。
我在此有一个疑问,就是为什么不直接用a的与的远近交点切成两半不就行了,我想大概是为了平衡上半和下半的点的数目。这个算法可能是以近块b为中心,若a中心线和b中心线偏的比较多的时候,b切割得到的较大一半的点数要略多。如例中d1,d2为切割点就是不平等切割。
3.7电源线和地线的布线(Power and Ground Routing)
随着工艺的改进,电路密度越来越高,芯片耗电也变快,且芯片约20%-40%的金属都用于供应电能,电源线和地线的布线变得尤为重要。
由于经过一段距离的传输,由于电压会下降 V=IR,电源块应该布置在活动较密集的电路附近。
电力的规划布局是迭代的,大致包括以下六部分:
(1)对耗电模块的早期模拟
(2)对芯片功率的早期估计
(3)对芯片用电情况,最大功率密度的总体分析
(4)总芯片功率波动分析
(5)门控时钟(clock gating)导致的固有和附加波动分析
(6)早期功率分布分析:平均、最大和多周期波动
为了构建合适的供应网络,必须考虑设计和工艺技术的多个方面。例如,为了估计芯片功率,设计者必须考虑这些方面:
(1)消耗更多功率的低电压动态电路的使用
(2)低功率的门控时钟的使用
(3)减少开关噪声的添加去耦电容器的数量和位置
3.7.1电源线和地线的布线的设计(Design of a Power-Ground Distribution Network)
由于每个单元必须同时具有电源线和地线连接,供电网络会(1)较大,(2)跨越整个芯片,(3)在任何信号布线之前先进行布线。
核心供电网是I/O供电网,通常电压较高。在许多应用中,一个核心电网和一个核心地网就足够了。一些集成电路,如混合信号或低功率(电源门控或多电压电平)设计,可以具有多个电源和地网。
供应网的布线不同于信号的布线。电源和地网应该有专用的金属层,以避免消耗信号路由资源
为减小电压下降问题,供应网更喜欢厚金属层,也比信号线路宽的多,以达到一些电压标准,比如下降5%以内。且供电网络经常会跨多层布置,为避免电迁移和其他可靠性问题,经常会设置多个跨层电流管道(vias)。
有两种物理设计电源-接地分布的方法-平面方法,主要用于模拟或自定义块,网格方法,主要用于数字集成电路。
3.7.2平面布线(Planar Routing)
3.7.2和3.7.3将介绍两种电源网络布线的方法。本节介绍的布线方法是平面布线,它要求(1)在设计中只有两个供电网,并且(2)一个单元需要连接到两个供电网。
方法大致是找到一个哈密尔顿回路并将布局分成两半,一半只布一种线即可。
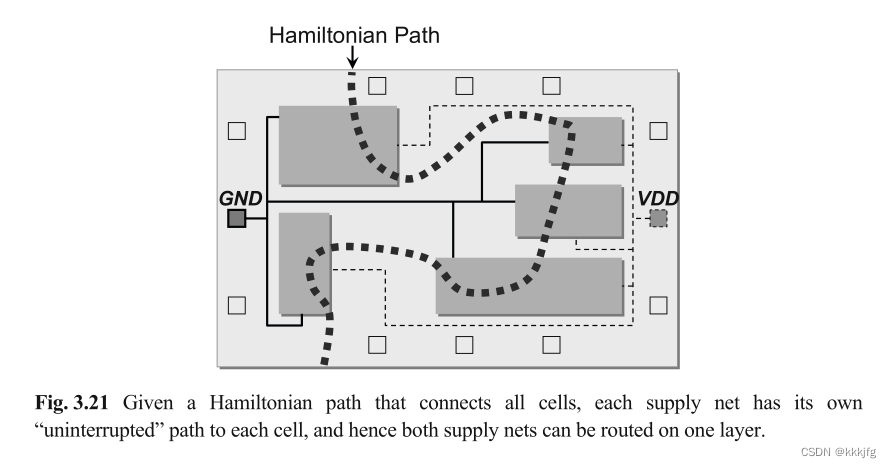
算法分为三步:
第一步:将网的拓扑平面化
由于电源网和接地网都在一层上布线,所以设计时采用哈密顿路径进行分割。在图3.22(a)中,两个网分别从左右两侧开始。这两个网都像树一样生长。由于被哈密顿路径分开,电源网络和地线网络不会有任何重叠。确切的路线将取决于引脚位置。
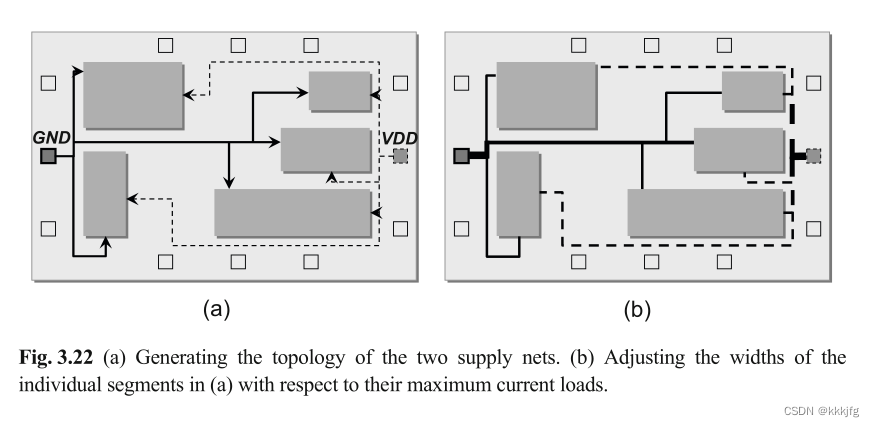
第二步:层分配
根据可布线性、各可用层的电阻和流量等信息,将网段分配给适当的电路层。
第三步:确定网段的宽度
每段的宽度取决于最大电流强度。线段的宽度是根据基尔霍夫电流定律(KCL),由它连接的所有单元的电流之和决定的。当处理大电流时,设计人员经常在垂直维度上扩展“平面”路径的“宽度”,在多层上叠加段,这些段用电流管道(vias)钉在一起。此外,宽度确定通常是一个迭代过程,因为电流取决于时序分析和噪声,电压损耗影响噪声,电流又影响电压损耗。换句话说,在功率、时序和噪声分析中存在循环依赖关系。这个循环通常由经验丰富的设计师通过多次迭代来解决。如3.22(b)
在执行上述三个步骤后,电源线和地线会在后续的信号线布线过程形成障碍。(不确定,原文这里是After executing the above three steps, the segments of the power-ground route form obstacles during general signal routing (Fig. 3.22(b)).)
3.7.3 网格布线(Mesh Routing)
现代芯片设计一般以以下5步设计芯片:
步骤1:构建一个环(creating a ring)
通常,一个环被构造来环绕芯片的整个核心区域,也可能是单个块。该环的目的是连接电源I/O单元,以及可能的静电放电保护结构与芯片或块的全局电源网格。为降低电阻,这些连接和环本身在许多层上。例如,一个环可能使用金属层Metal2- Metal8(除了Metal1之外的每一层)。
步骤2:把输入输出块连到环上(connecting I/O pads to the ring)
图3.23的左上角显示了从输入输出块到环的连接(connecter)。每个输入输出块在每个金属层上都有若干个“手指”。这些应最大限度地连接到电源环,以减少电阻和最大限度地将电流输送到核心的能力。
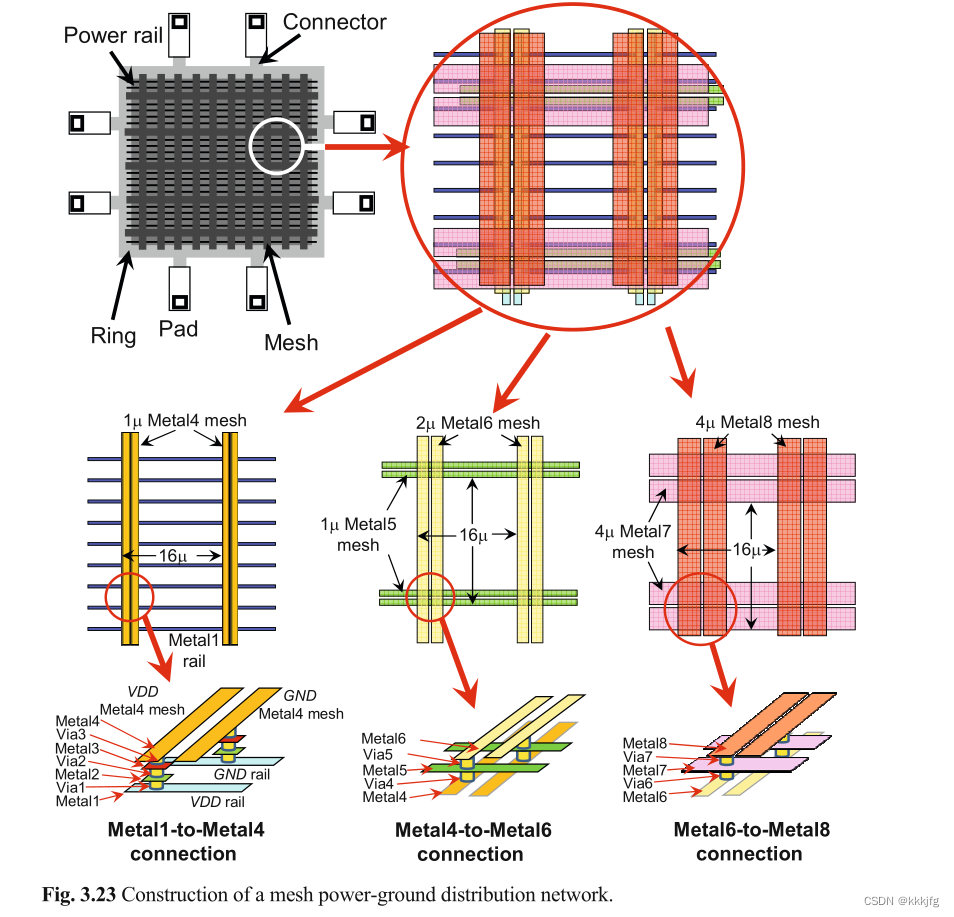
步骤3:构建一个网格(creating a ring)
电源网格由一组在两个或多个层上的确定间距的条状导体组成(图3.23)。条状导体的宽度和间距是根据预估功耗和布局设计原则确定的。条纹成对排列,以VDD-GND、VDD-GND等方式交替排列(如图3.23中间)。电力网格使用最上层和最厚的层,在任何较低的层上都是稀疏的,以避免信号线路拥挤。相邻层上的条状导体通常用尽可能多的电流管道连接,同样是为了最小化阻力。管道连接两层的示意图如3.23下方。
步骤4:Metal1轨道(creating Metal1 rails)
Metal1层是电源网络和地线网络连接逻辑门的地方。Metal1导轨的宽度(电流供应能力)和间距通常由标准单元库决定。标准单元行是“背靠背”布置的,因此每个供电网络由相邻的两个单元行共享。
步骤5:将Metal1导轨连接到网格上(connecting the Metal1 rails to the mesh)
最后,Metal1层通过堆叠的管道(stacked vias)连接到供电网格。一个关键的考虑是适当的大小(通过堆栈中的通过的数量)。例如,功率分布中最有阻性的部分应该是通过堆叠之间的Metal1段,而不是堆叠本身。此外,可以通过优化这些管道的排布,强化设计的可路由性。例如,1 × 4阵列的管道可能比2 × 2阵列更好一些,不过最终取决于路由阻塞的方向。
图3.23给出了电源网络和地线网络的构建方法。在图中,从Metal8到Metal4图层用于网格。实际应用重,由于布线资源的限制,许多芯片使用较少的层(例如,只使用Metal8和Metal7)

















 3305
3305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









