









智能客服业务介绍
介绍智能客服业务是什么样,形态是什么样,业务为什么重要,为什么各家都在投入人力做智能客服,从人工客服到智能客服的变迁过程中,整体趋势是什么样的。
背景
企业为什么需要智能客服?
提高服务效率和客户满意度
节省成本
提高用户粘性,开拓市场
客服的发展历程
2000年之前,电话热线客服
2000-2010,网页或者在线客服
2010年之后,Saas和智能客服
智能客服发展历程(标准化->非标准化)
单一流程定制(订机票):流程简单明了,对话要素清晰
常见问题流程化,基于任务的对话(退换货):出现多个场景,但仍然可以依照标准流程解决问题
多轮对话,基于上下文理解的对话(Long Long Away to go):用户输入更加自由,必须结合上下文才可以理解用户信息,对智能化要求最高
客服中心发展
语音接触,渠道单一,信息量最低
文字接触,开始支持多渠道,信息量丰富不少
机器接触,支持更多自定义个性化服务,信息量骤增
业务预测
基础设施,不断完善
自然交互,广泛应用
底层技术,不断成熟
智能客服介绍
出现背景(传统客服的痛点)
重复问题占用客服重复劳动
人力成本居高不下
无法提供24小时服务
聊天记录闲置(无法创建有效的客服话术、标准问题处理流程知识体系)
不能很好承接动态需求(海量、突发、复杂进线)
服务效率和服务品质有待提高(无法挡住大规模人工进线(无效会话、知识解决))
技术目标
通过回复高频、简单问题,挡住 X%的客户进线,将复杂疑难问题转给人工客服团队
常见的用户问题
售前:目标是促成下单
售中:目标是促成消费
售后:目标是留住客户
闲聊:目标是打发客户时间
技术难点
数据冷启动时:没有足够数据来训练模型,,需要先用通用模型或者先用规则
多轮对话:目前没有攻破多领域多轮对话
人机协作:机器人去辅助客服,机器人去辅助用户,智能客服仍然是辅助
技术应用发展过程
单个关键词匹配
多词匹配+模糊查询
关键词匹配+搜索技术
神经网络
模型训练
用户与客服的沟通是一个巨大的宝藏
第一阶段
语料缺少
重复语料过多
知识库构建困难
模型选型困难
调优困难
第二阶段
数据和模型需快速迭代(大量新增的未知知识)
脏数据过多(影响模型的准确率)
知识库覆盖不全(用户需求增多导致大量未知意图产出)
模型训练流程没有标准化(高度依赖离线训练)
第三阶段
更自动的QA答案挖掘,借助VQA减少运营压力
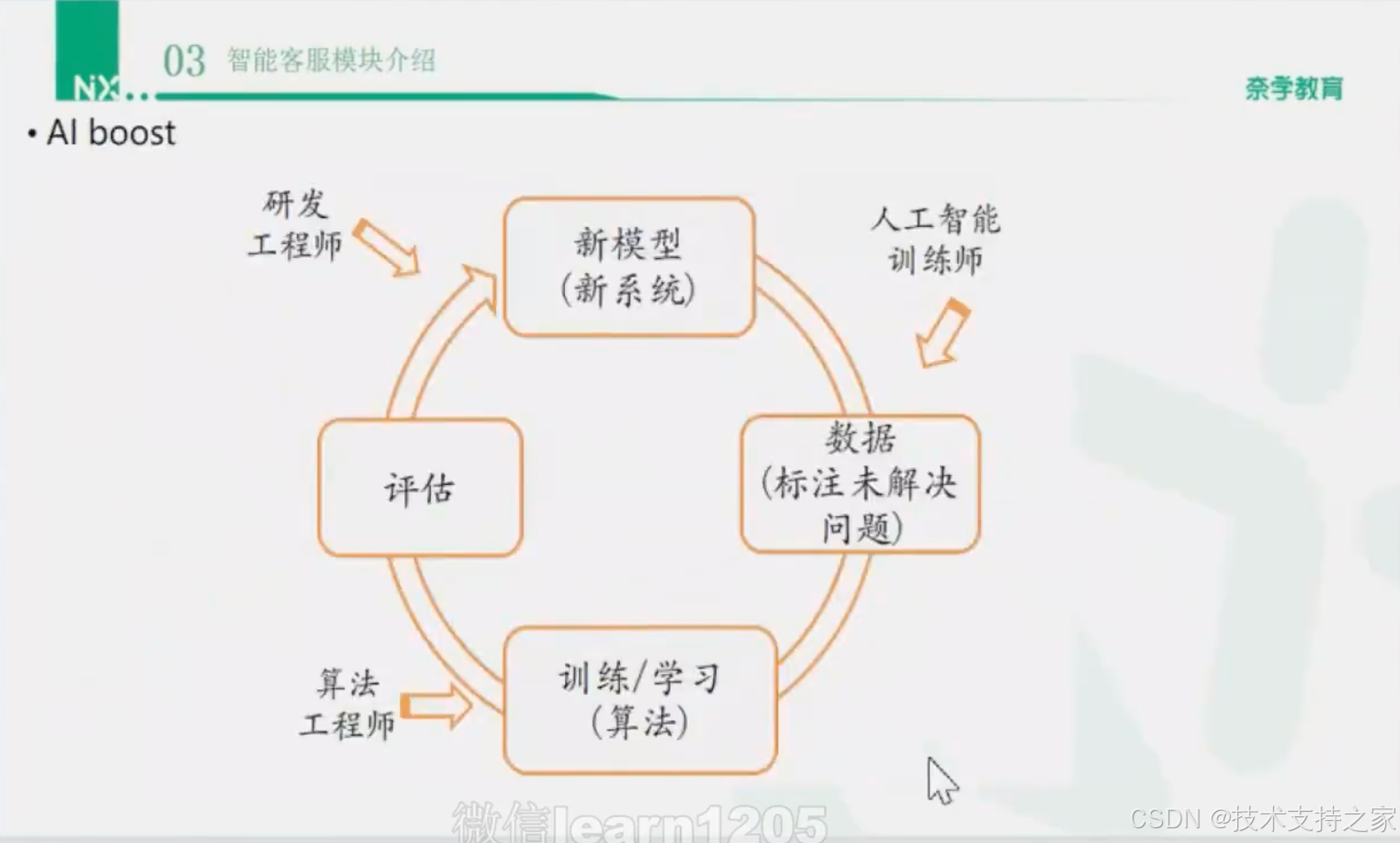
AI boost,指定模型训练闭环流程
智能客服整体架构
介绍算法模块有哪些,工程架构是什么样的。
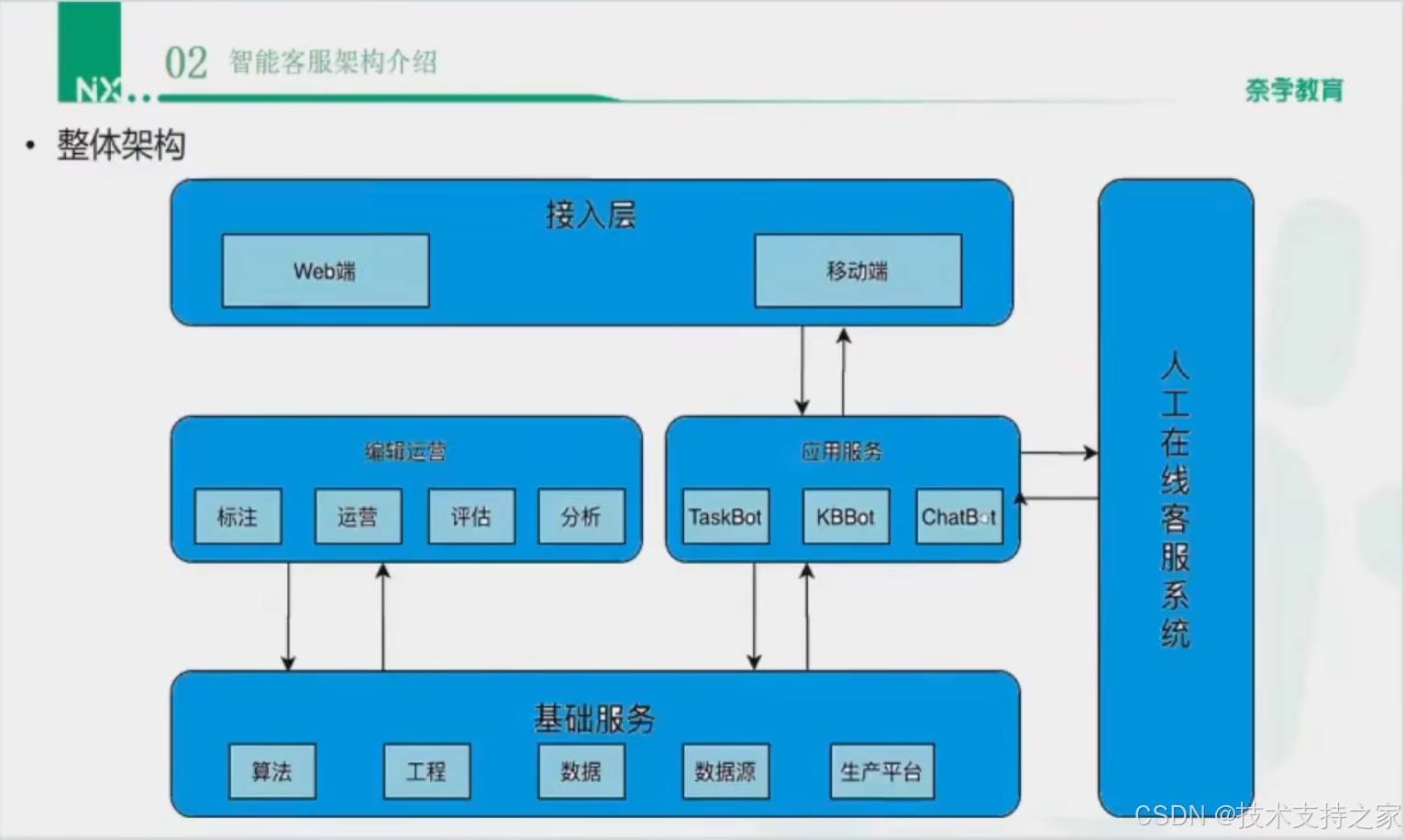
接入层
面向用户,作用是连接用户与智能客服背后的逻辑系统
分为web端和移动端
应用服务
本质就是一个路由
TaskBot:任务型机器人(流程化的Bot)
KBBot:知识库型机器人(KnowledgeBase,依赖于知识库和知识图谱)
ChatBot:闲聊机器人
运营
编辑:根据机器人挖掘的知识,配答案,编辑更好的Answer
标注:根据机器人挖掘的知识,标注是否属于客服数据
评估:评估机器人在处理用户问题时是否存在投诉,机器人的客户服务满意度等
分析:分析机器人挖掘的知识,反馈优化建议
基础服务
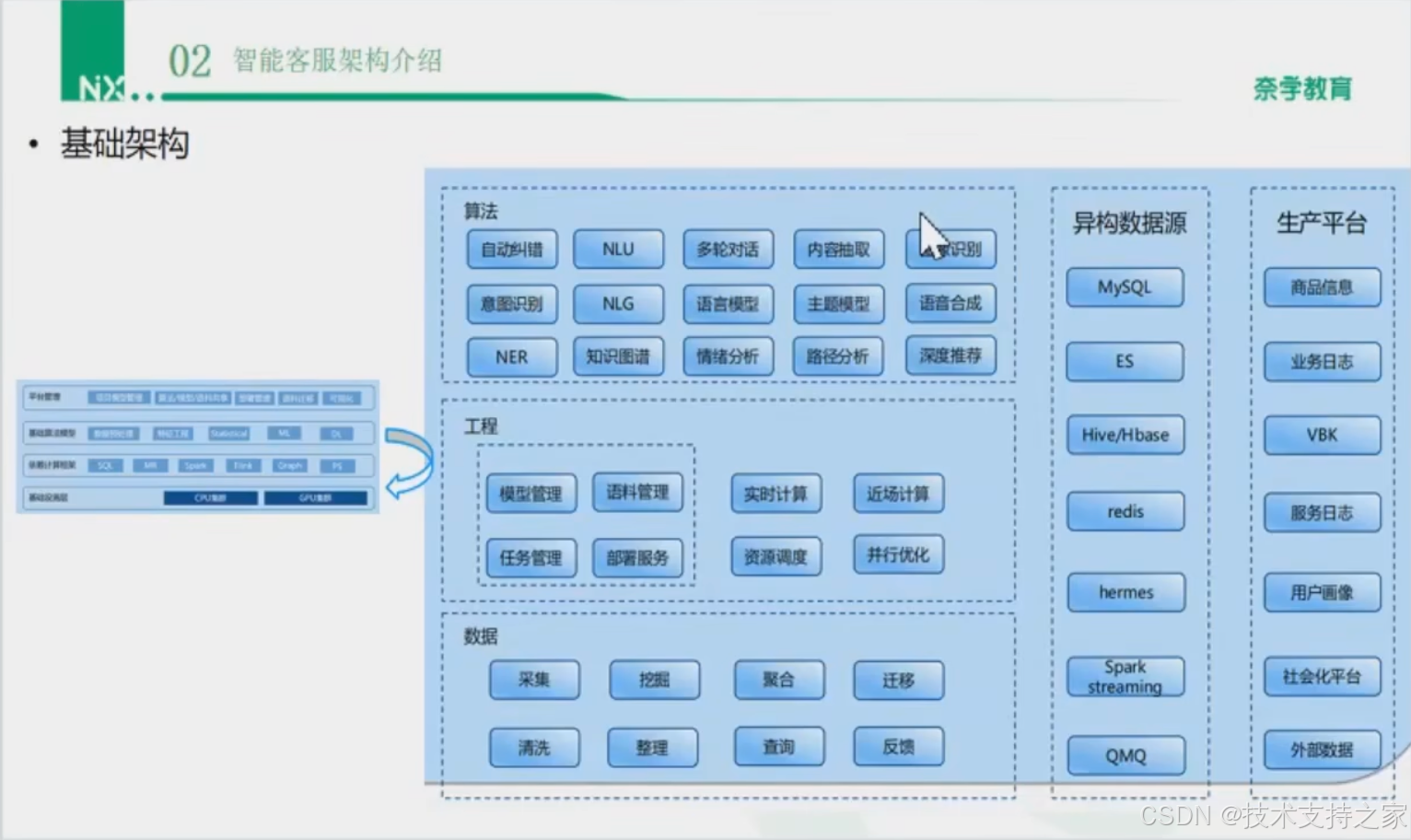
算法模块
自动纠错,NLU,多轮对话,内容抽取,图像识别,意图识别,NLG,语言模型,主题模型,语音合成,NER,知识图谱,情绪分析,路径分析,深度推荐
工程模块
模型管理,语料管理,任务管理,部署服务,实时计算,近场计算,资源调度,并行优化
数据模块
采集,清洗,挖掘,整理,聚合,查询,迁移,反馈
异构数据源模块
MySQL,ES,Hive/Hbase,redis,hermes,Sparkstreaming,QMQ
生产平台模块
商品信息,业务日志,VBK,服务日志,用户画像,社会化平台,外部数据
模型架构
平台管理
项目模型管理,算法、模型、语料共享,部署管理,语料迁移,可视化
基础算法模型
数据预处理,特征工程,Statistical,ML,DL
依赖计算框架
SQL,MR,Spark,Flink,Graph,PS
基础设施层
CPU集群,GPU集群
问答环节
对于智能客服来说,最核心的考察目标是转人工率,客服就是去降低转人工率。
如何生成模版
规则生成
Bootstrap
垂直领域
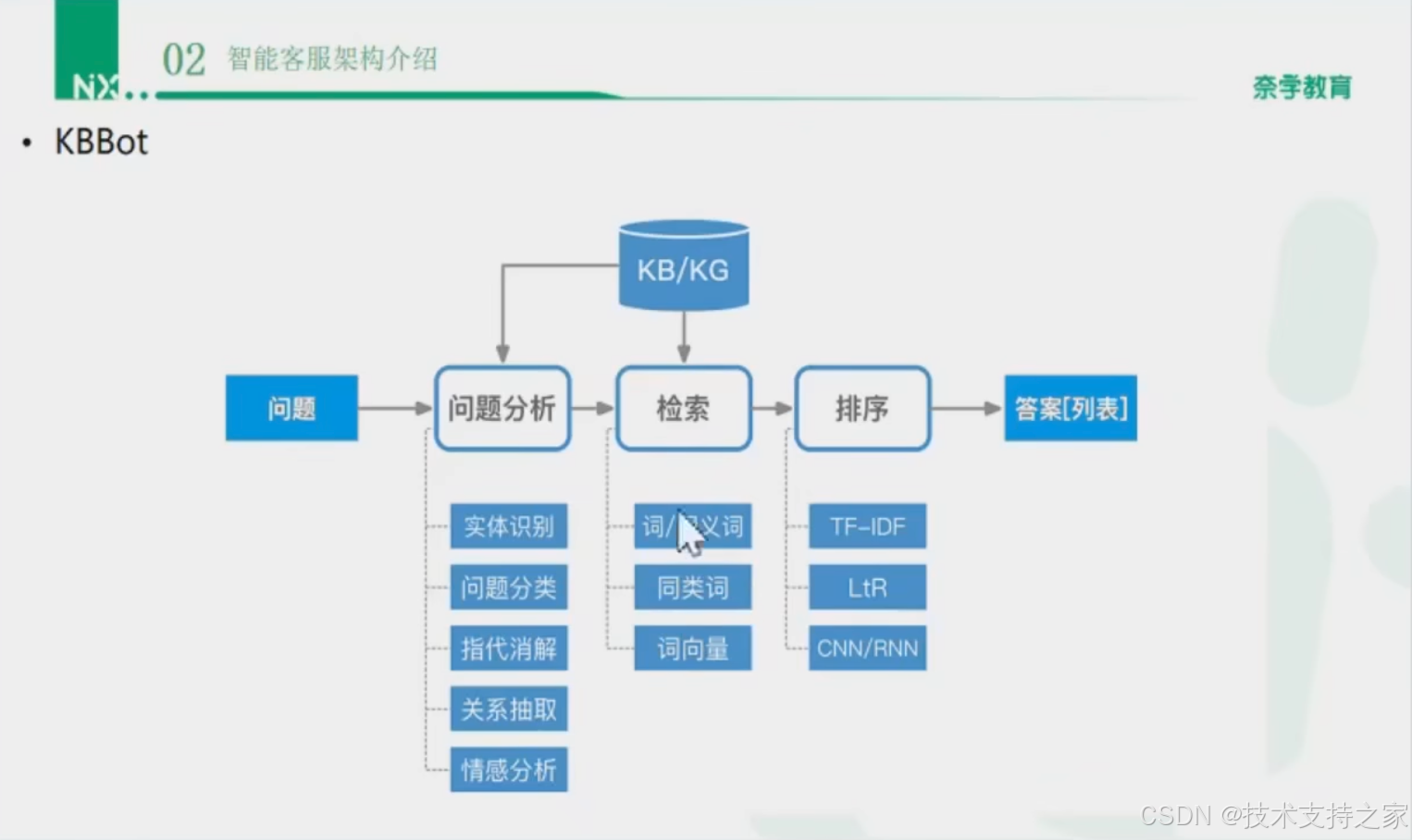
KBBot介绍
知识型机器人基于知识库的问答可以使用检索或者分类模型来实现
知识库是否优秀的评判标准是知识的覆盖面、覆盖率和回答的准确度。
流程
分析---检索---排序---回答
- 首先对用户输入的问题作处理,例如分词、抽取关键词、同义词匹配、计算句子向量等方式。
- 然后基于处理结果在知识库中做检索匹配,例如利用BM-25、TF-IDF或向量相似度匹配出一个问题集合,这类似推荐系统中的召回过程。
- 然后针对问题集合做重排序,依据规则、机器学习或深度学习模型做排序,每个问题打一个分值,挑选出top1,将这个问题的答案返回给用户,这就完成了一个对话流程。
- 在实际应用的过程中,还会设置阈值来保证回答的准确性,如果所有问题集合中的问题打分,都没有达到阈值,会将头部的问题以列表形式返回给用户,让用户选择他想要的问题,从而得到答案。
图示流程
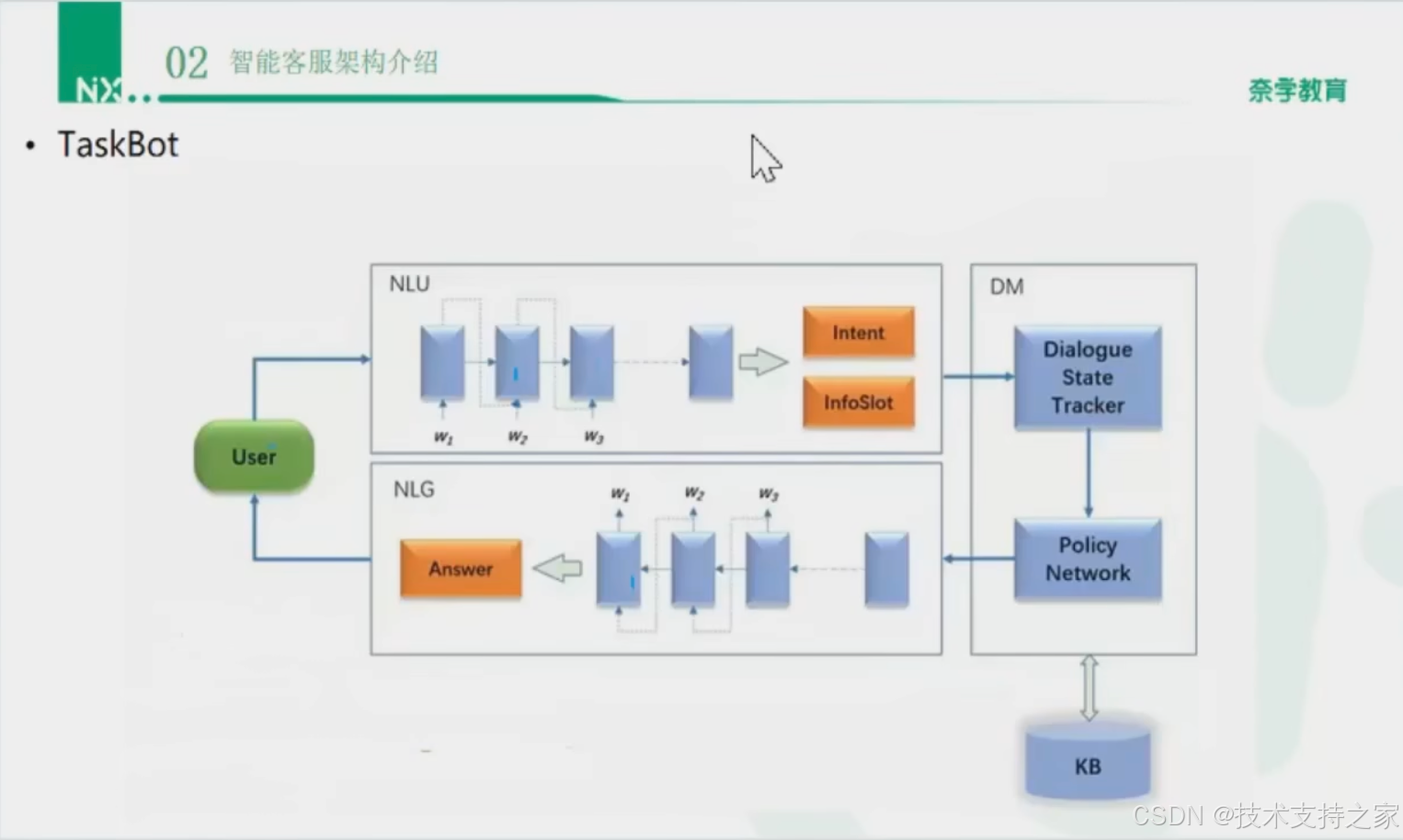
TaskBot介绍
TaskBot就是工作流,可以定义为SOP标准工作流程,可以解决80%用户的问题
不同用户的需求--->通过共性抽象成任务--->TaskBot通过识别领域、意图、槽位完成意图识别
任务型机器人是在特定条件下提供服务,为了满足带有明确目的的用户,例如退换货、查物流等任务型场景。
用户的需求一般较复杂,通常需要机器人和用户多轮互动以帮助用户明确目的
自然语言理解模块(NLU)会识别当前输入问题的意图和槽位,然后输入到对话管理器(DM)中决定下一步的动作,最后在通过自然语言生成模块(NLG)将答案返回给用户。
流程
识别--->输入--->生成--->回答
图示流程
概念理解
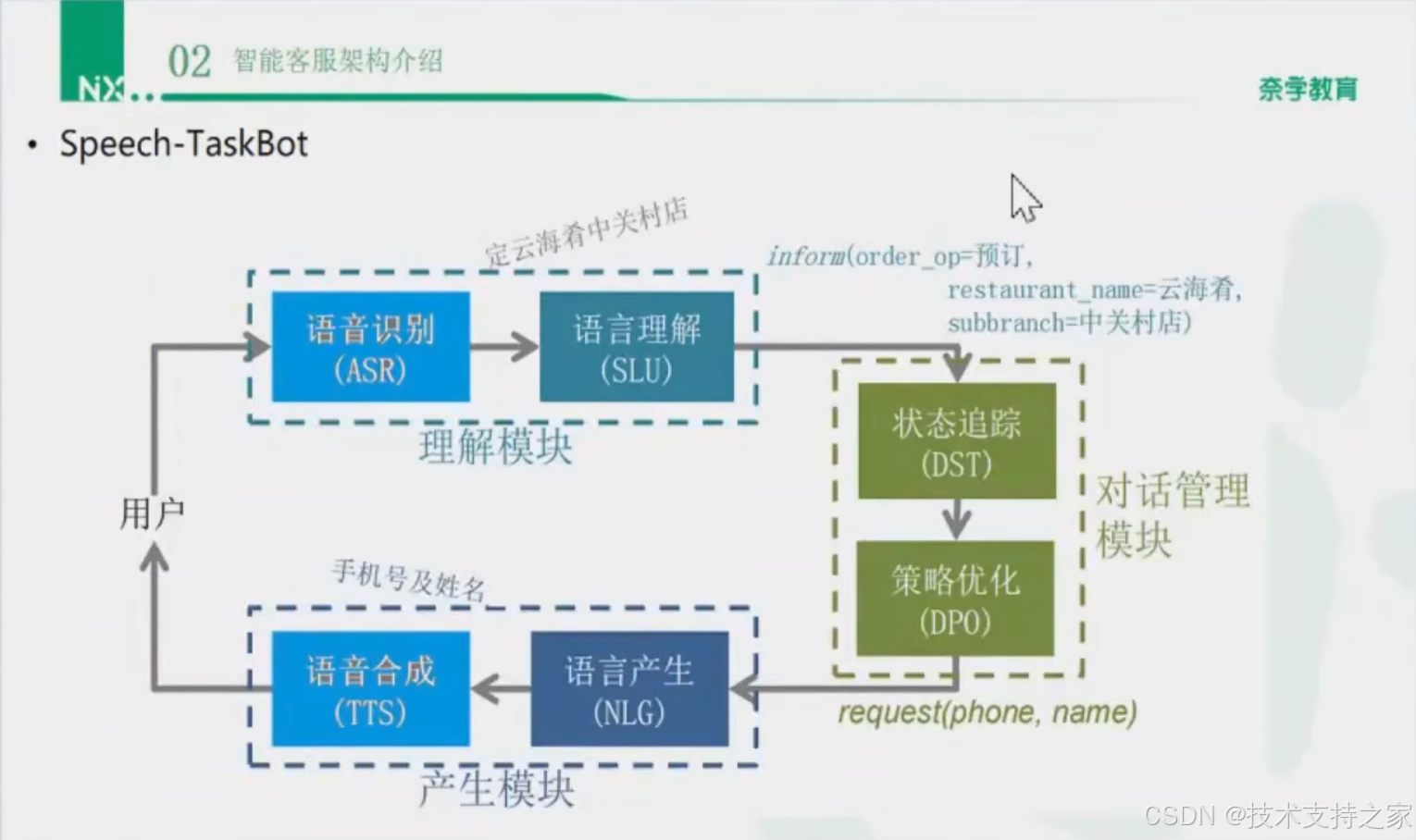
ASR(Automatic Speech Recognition)--->自动语音识别:将用户语音信息转化为文本信息,用于后续的意图识别,对应对话过程的倾听。
NLU(Natural Language Understanding)--->自然语言理解:将ASR生成的文本信息,映射(理解)为用户实际希望完成的意图。(做领域domain识别、意图intent识别、槽位slot识别)
DS(Dialog State)--->对话状态:上下文信息,用于描述当前会话内容信息的状态量,可抽象为多轮会话中的语境
DST(Dialog StateTracking)--->对话状态追踪:在多轮对话中,特别是任务驱动型的多轮对话中,对话往往存在中加状态。同时也可能存在信息缺失,意图不明等情况。因此只理解用户本轮的文本是不够的,还需要结合特定场景内的上下文状态(DS:Dialog State)进行理解。而DST的目标就是结合NLU和DS,去理解用户在多轮对话中的实际意图。DST和NLU共同构成多轮对话中的理解模块。
DP(Dialog Policy)--->对话策略:对话策略是用于控制对话回复的模块。起主要作用是结合对话理解,选决策当前最优一个执行结果。对于不同场景,往往需要决策不同的最终结果。需要根据不同的外部信息来进一步决策最终端到端执行意图,也就是所谓的见人说人话。例如,若意图明确且完整,可以直接执行意图后给予回复;若意图不明确,可以执行追问、澄清等策略话术以明确意图;若连续识别失败,也可以退出当前状态并给予一定指引等。
DM(Dialog Manage)--->对话管理:为了更好的划分模块,往往将DST和DP合称为DM。
NLG(Natural Language Generation)--->自然语言生成:自然语言生成相关回答。
TTS(Text To Speech)--->文本转语音:将对话系统实际生成的文本转换为音频信号。ASR和TTS存在于语音交互为主的系统中,同时也是用户直接感知最强烈的技术之一。
Speech-TaskBot(IVR)流程图示
ChatBot介绍
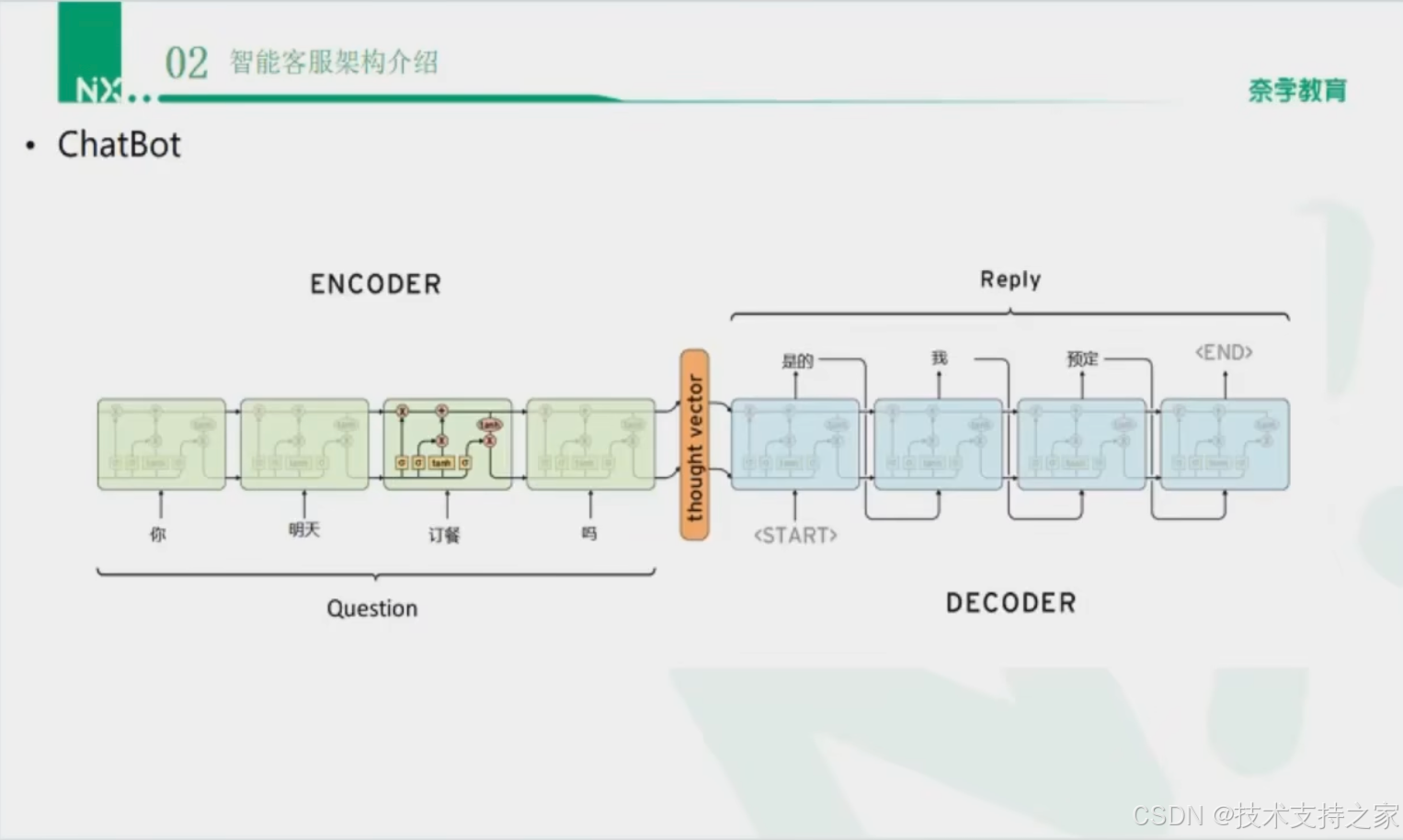
闲聊机器人
闲聊服务是基于一个闲聊语料库,采用模版匹配,检索式回答或者生成式对话等多种方式实现。
模版匹配使用了AIML和正则表达式来匹配。
检索式回答类比KB-Bot中的方式首先检索,然后利用模型排序。
当模版匹配和检索式回答都不能给出闲聊回答时,我们会采用Seq2Seq(VAQ/UniLM)生成式对话,我们使用了一个标准的Seq2Seq模型,问题会首先输入到一个双向LSTM编码器,然后加入Attention机制,最终使用一个单层LSTM做解码,从而得到结果输出。
流程图示
智能客服模块介绍
介绍具体每一个模块的介绍。
概念详解
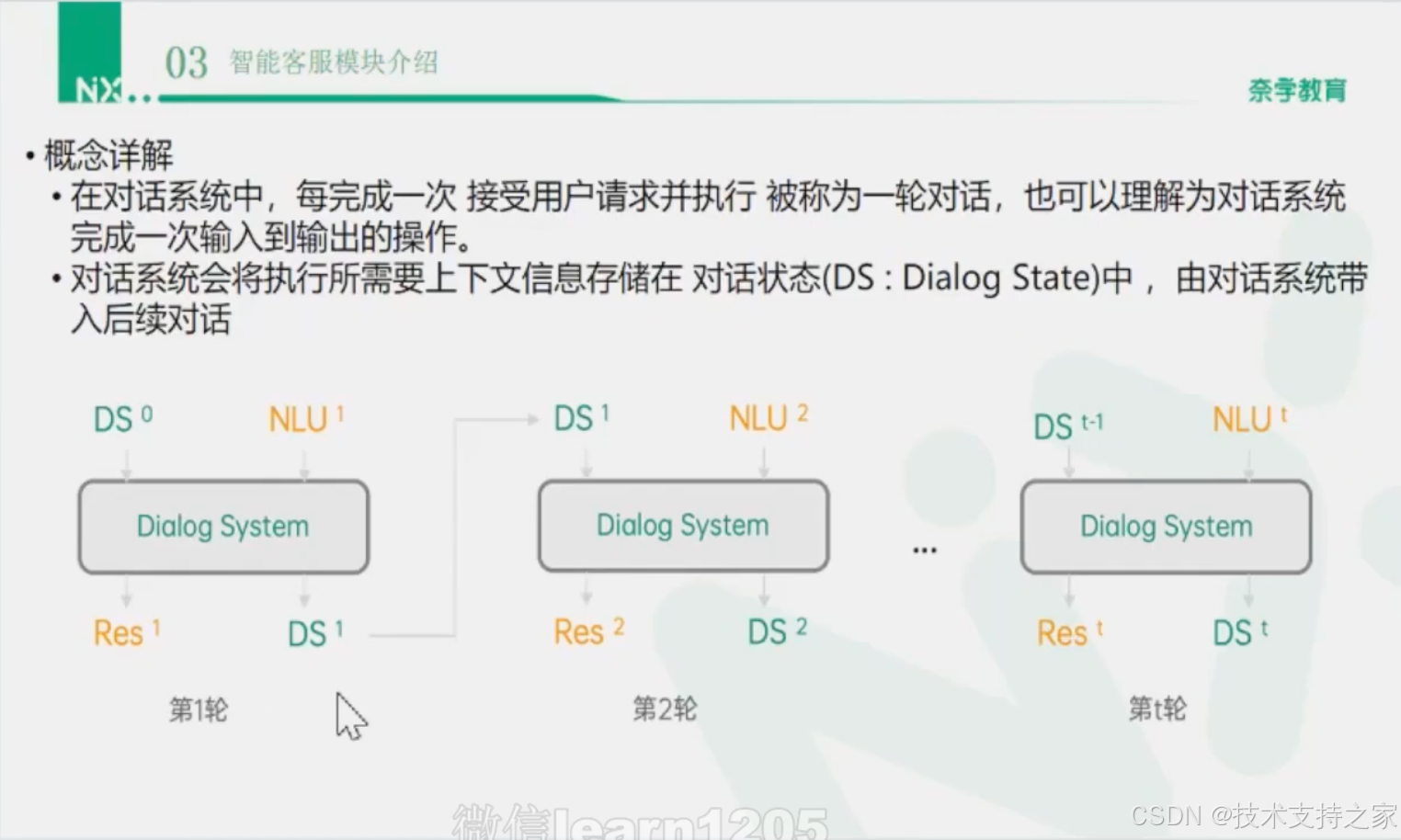
执行用户意图所需的轮次
单轮对话
只需要本轮信息就能够完成用户意图理解和识别的对话场景,应用在意图明确或者不依赖上下文的情况
多轮对话
需要同时考虑多轮上下文以及单轮信息才能够完成用户意图。
- 用户意图明确,但所需要的基础信息较多,用户很难一次性说完。例如订机票
- 用户意图不明确,但是会围绕一个主题展开
总体技术一览
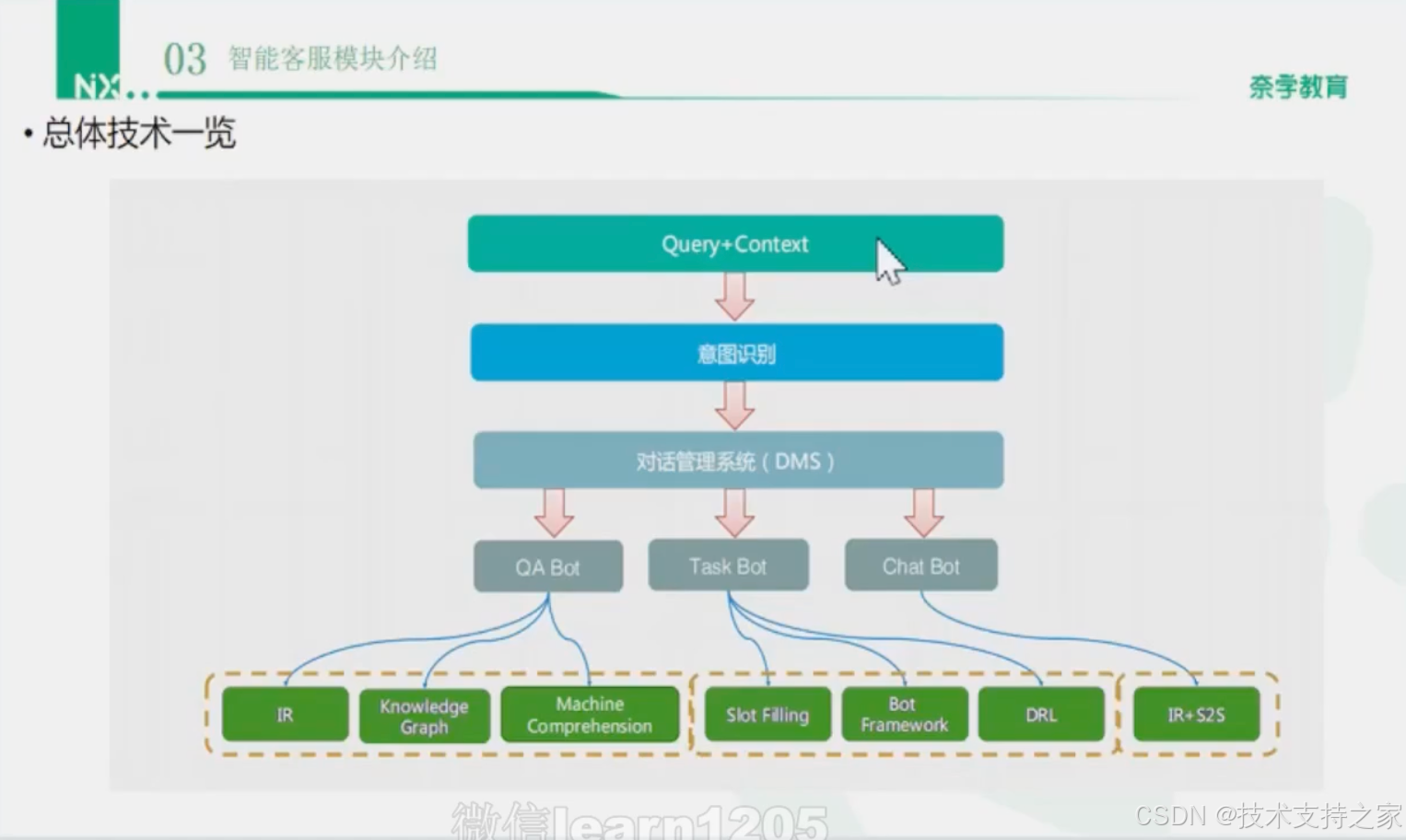
NLU
将ASR生成的文本信息映射为用户实际希望完成的意图,NLU主要在对话系统中起到理解的作用,通过NLU提取用户输入中有用的信息,让对话系统能够理解用户的真实意图并且能够顺利的执行。
NLU输入为用户实际说的话,输出往往为领域、意图、槽位的三元组形式供后续系统使用。
意图识别
意图定义
意图偏向于粗粒度的解决问题,例如传统售后问题可以划分为退换货、查物流、查订单等
完全依赖于运营人员的自定义不太好办,更多的是依赖于技术人员从已有的会话中挖掘出会话簇
同一个会话簇应用优相似的特点
将对应的会话簇交给专业运营人员标注意图名称和答案,通过筛选逻辑,最终将标准QA对入知识库。
意图识别
采用专业的意图识别模型来对用户问题作回答
有时候需要做意图的继承,因为用户有可能在连续问同一个问题(此处需要带上下文来做)
基于模型的分类
特征选择 与 分类算法
传统机器学习 与 深度学习
槽位识别
部分场景下,光有意图识别无法完整的提供执行所需要的基础信息,主要是进行一些固定任务的触发实现。
这些执行意图所需要的基础信息,又被称为槽位,每个意图有哪些槽位,是预先设定好的,只有完整提取到意图执行所必须的槽位,才能正确的执行用户意图。
通过上下文、追问等形式完善意图所需槽位的方式,又被称为添槽式的多轮对话,每个意图所需的槽位类型各式各样,因此槽位解析时所需的技术能力也均不相同。
做法:
词典&模版匹配
命名实体识别
规则解析
领域识别
领域是意图的集合
为了更好的满足用户需求,在实际对话中会将类似功能需求的意图归结到一个领域中统一建设,如售前领域、售后领域、闲聊领域。
由领域、意图、槽位共同决定系统中对用户需求的唯一表达。
QA匹配
QQ匹配
多轮对话

DP:对话策略是用于控制对话回复的模块,起主要作用是结合对话理解,选决策当前最优一个执行结果。
输入:DST输出的会话状态
输出:DP采取的系统操作
在多轮对话场景中,DST将当前轮的会话状态输入DP中,由DP来决定产生什么动作。常见的输入动作有:操作执行,意图澄清,槽位追问,状态跳转等等。DP在整个过程中,不断的根据DST的结果,产生系统,辅助整个系统来逼近最后的结果。
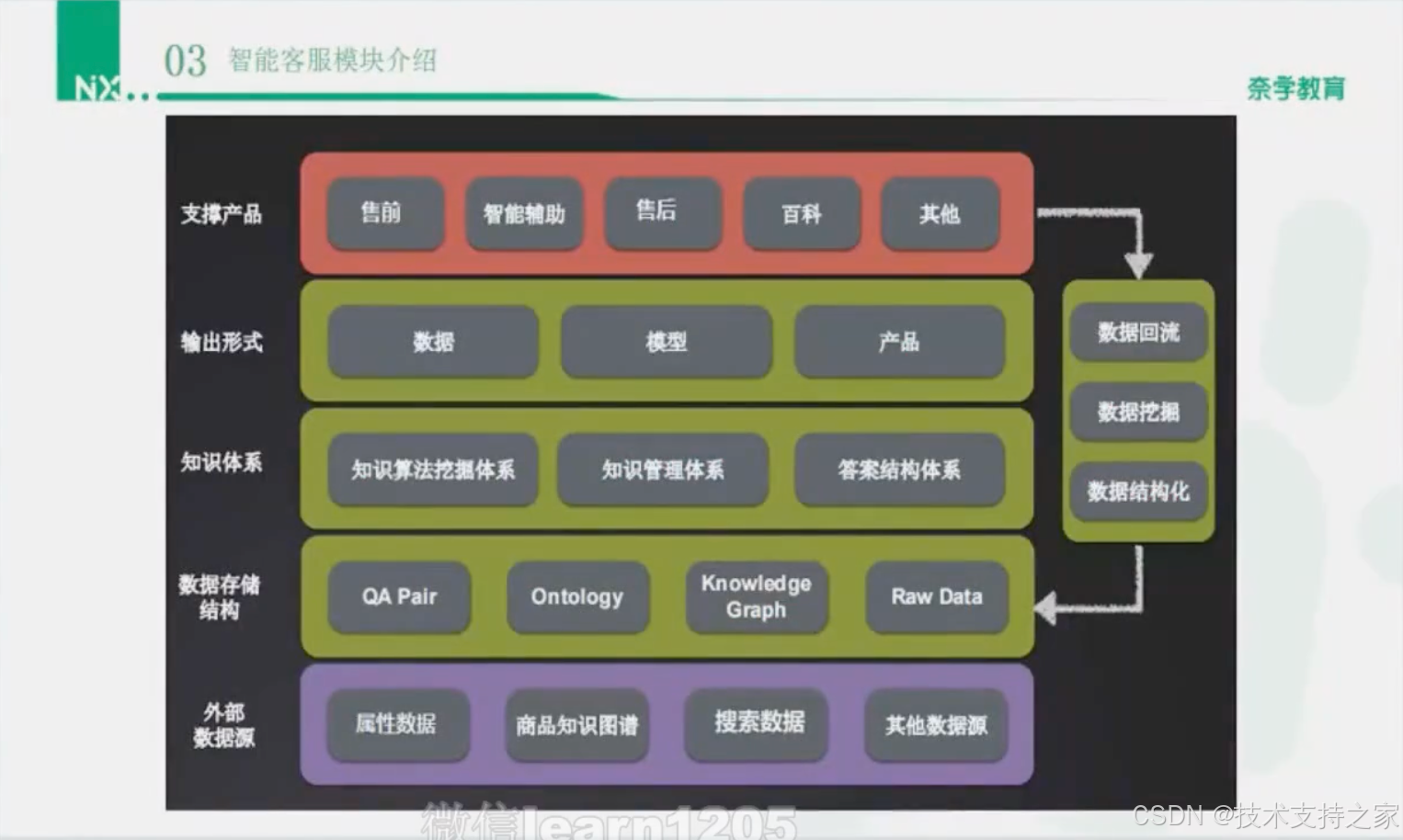
产品技术数据流转的流程图
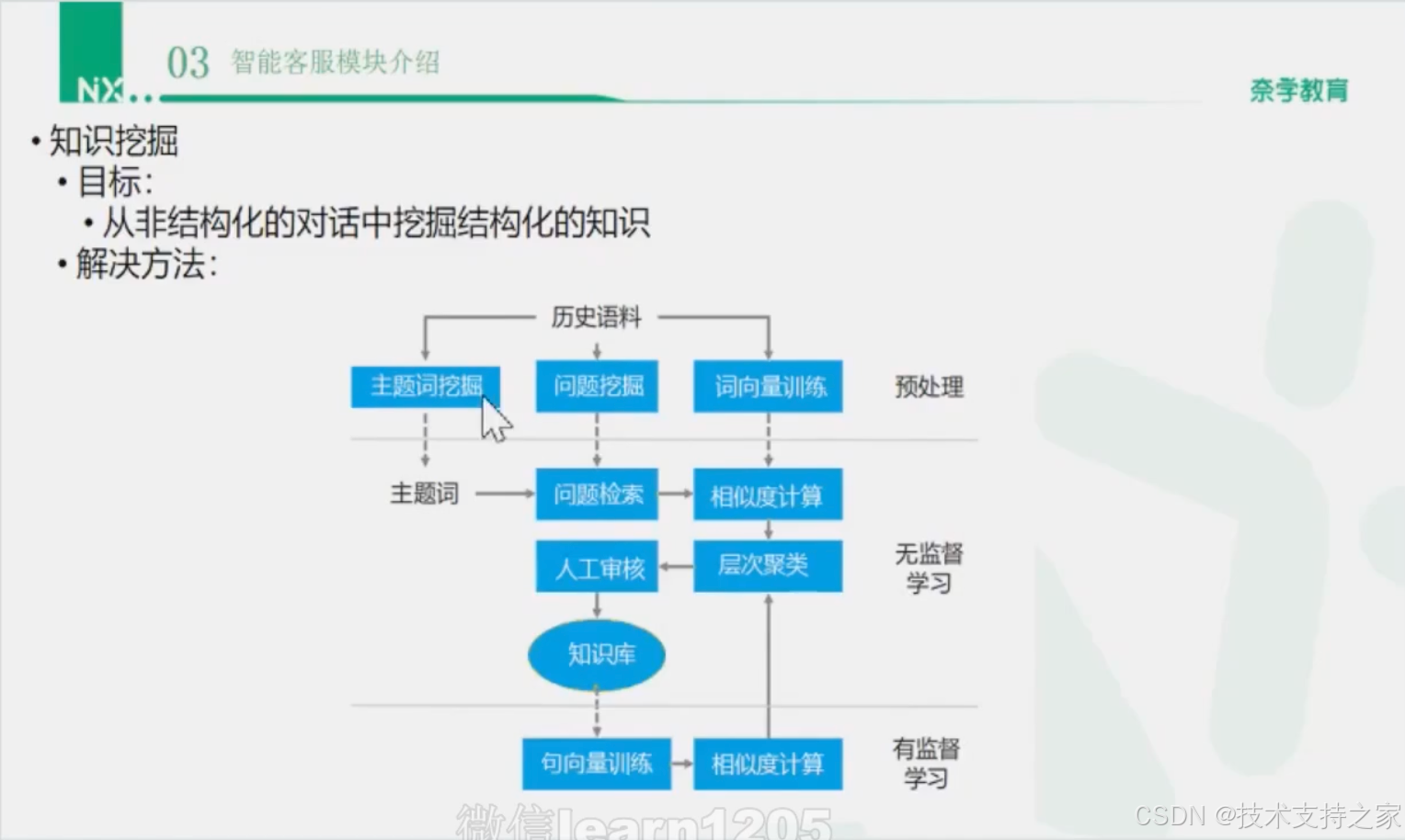
知识挖掘
预处理-->无监督学习--->有监督学习
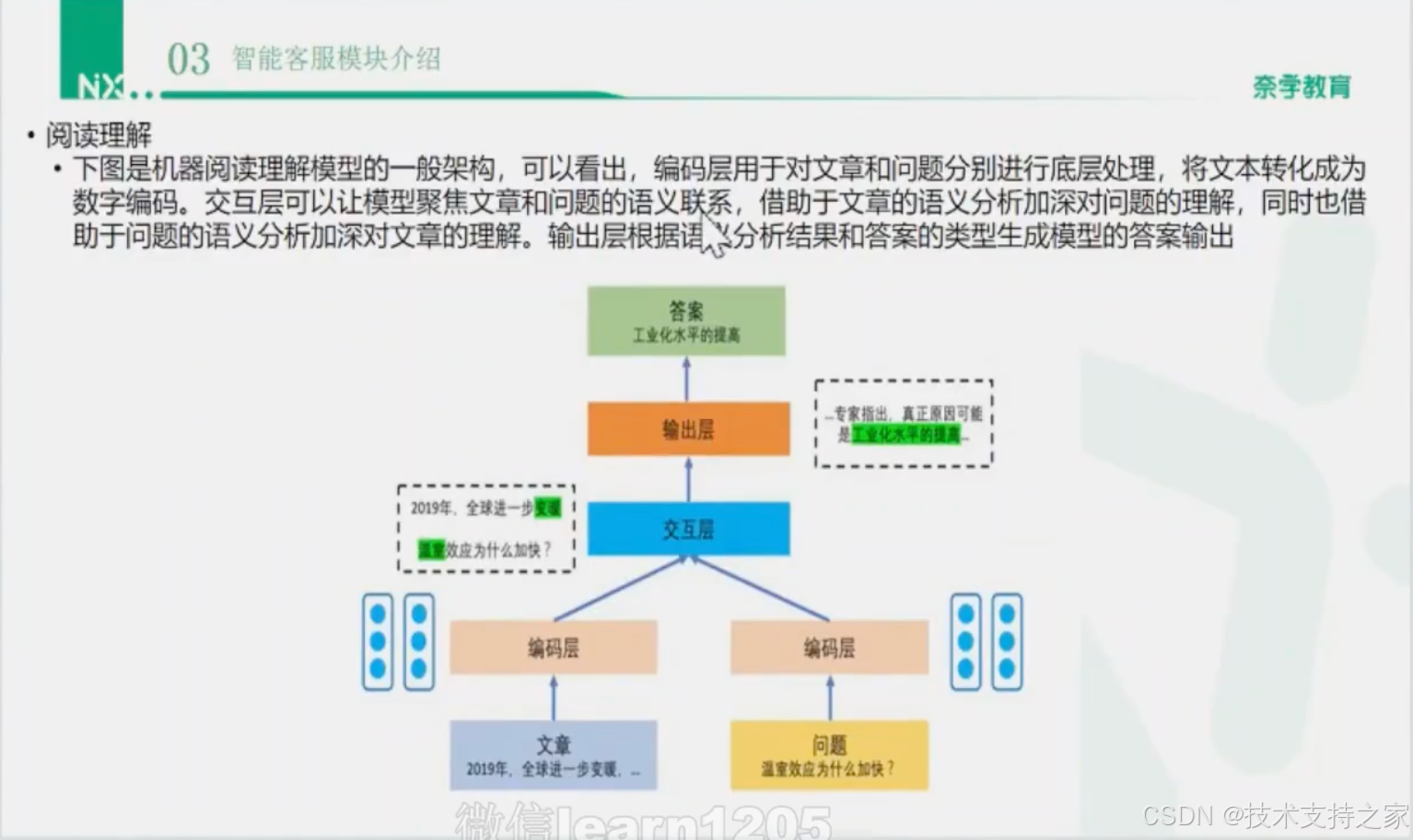
阅读理解
编码层--->交互层--->输出层
阅读理解模型的一般架构
AI boost
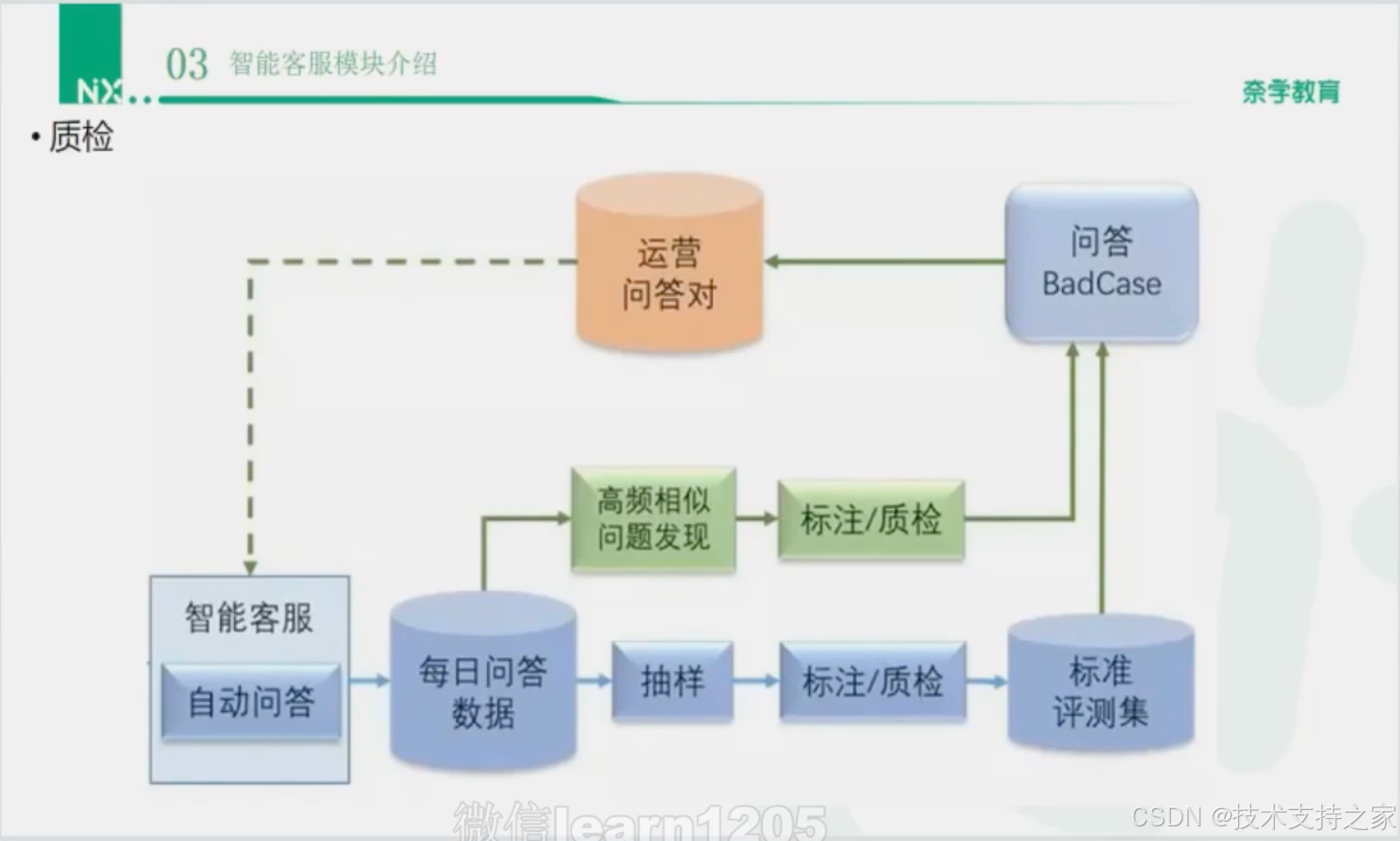
质检
问题推荐

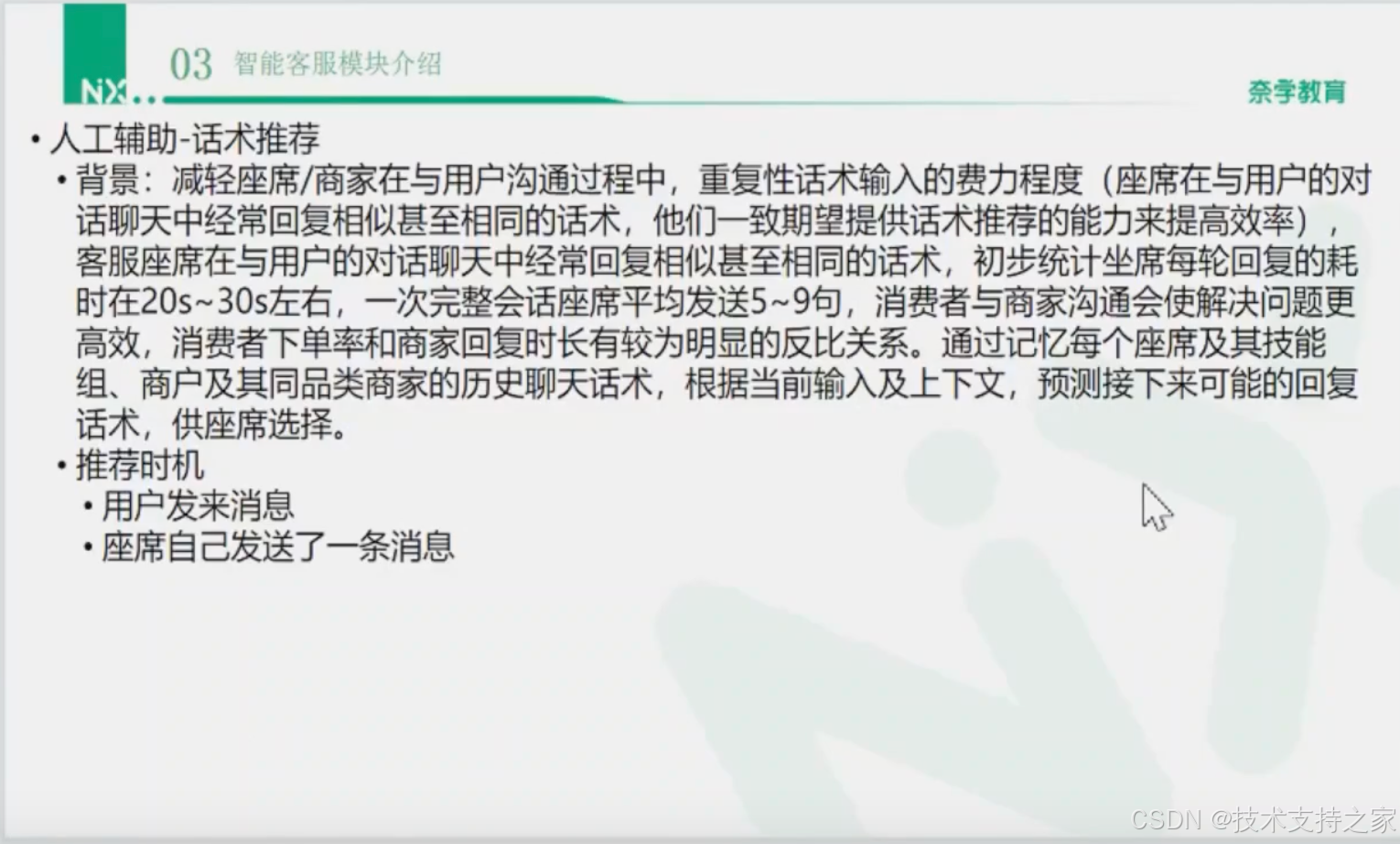
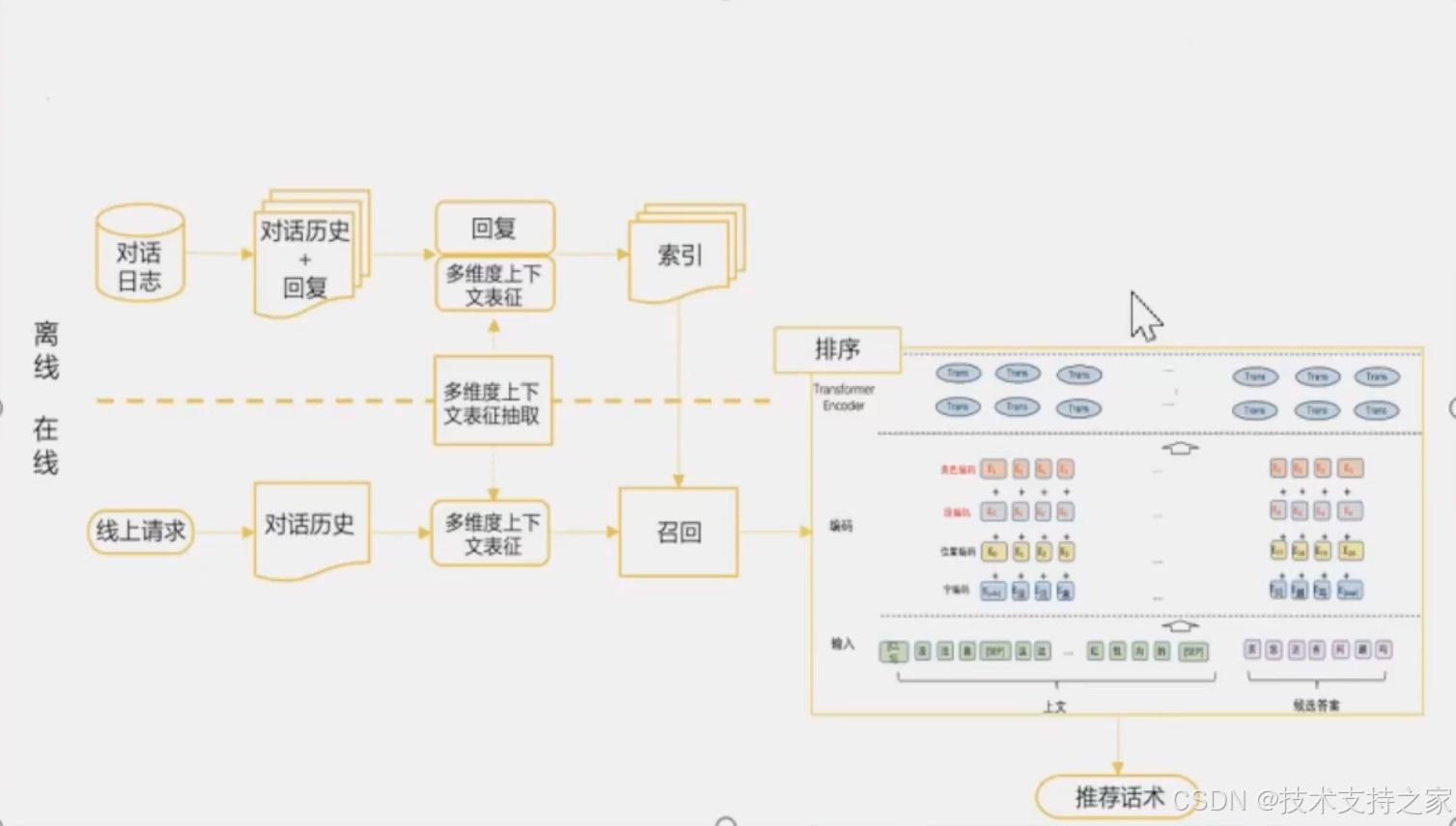
话术推荐

流程图
会话摘要
售前导购
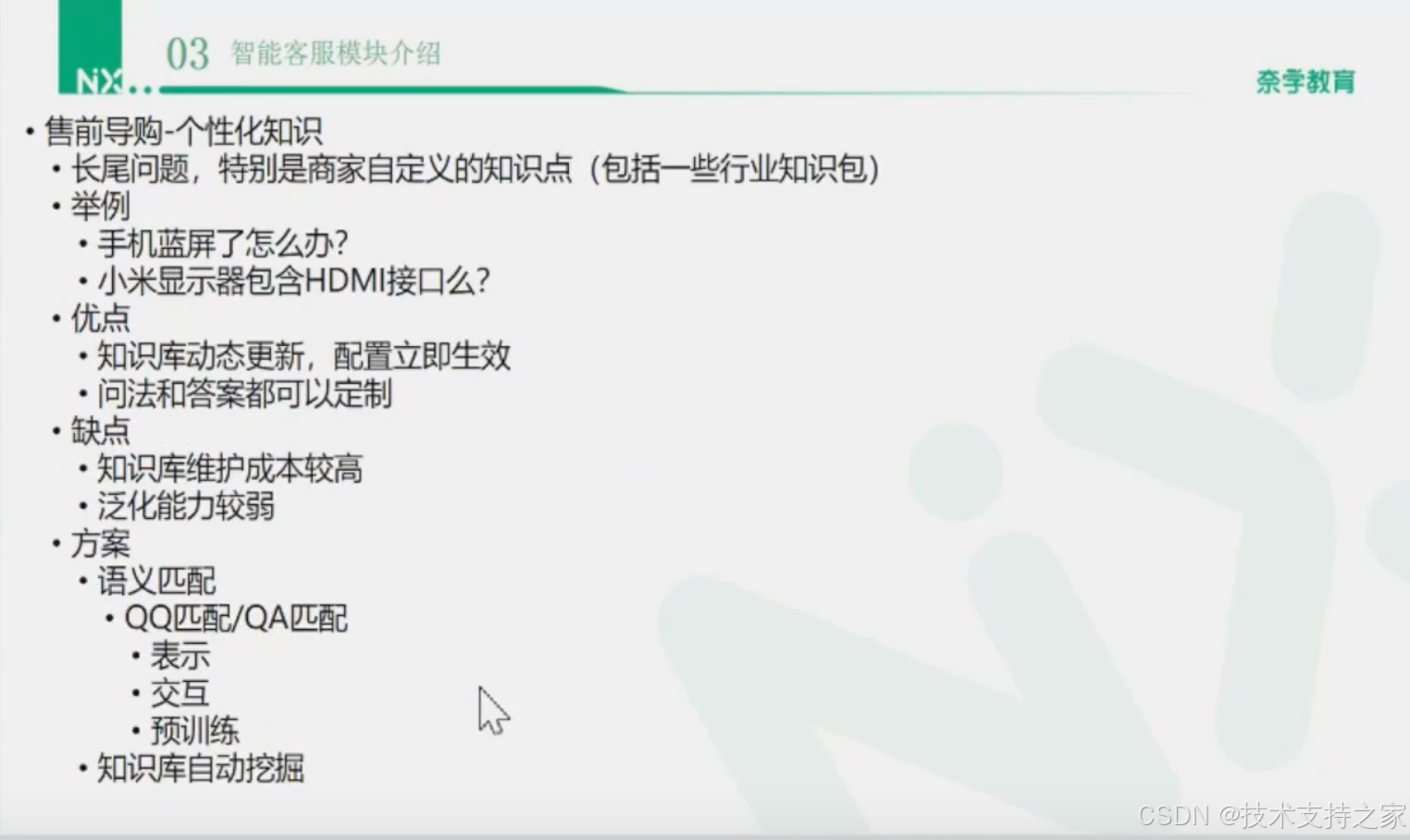
通用知识

个性化知识
专业属性

营销导购
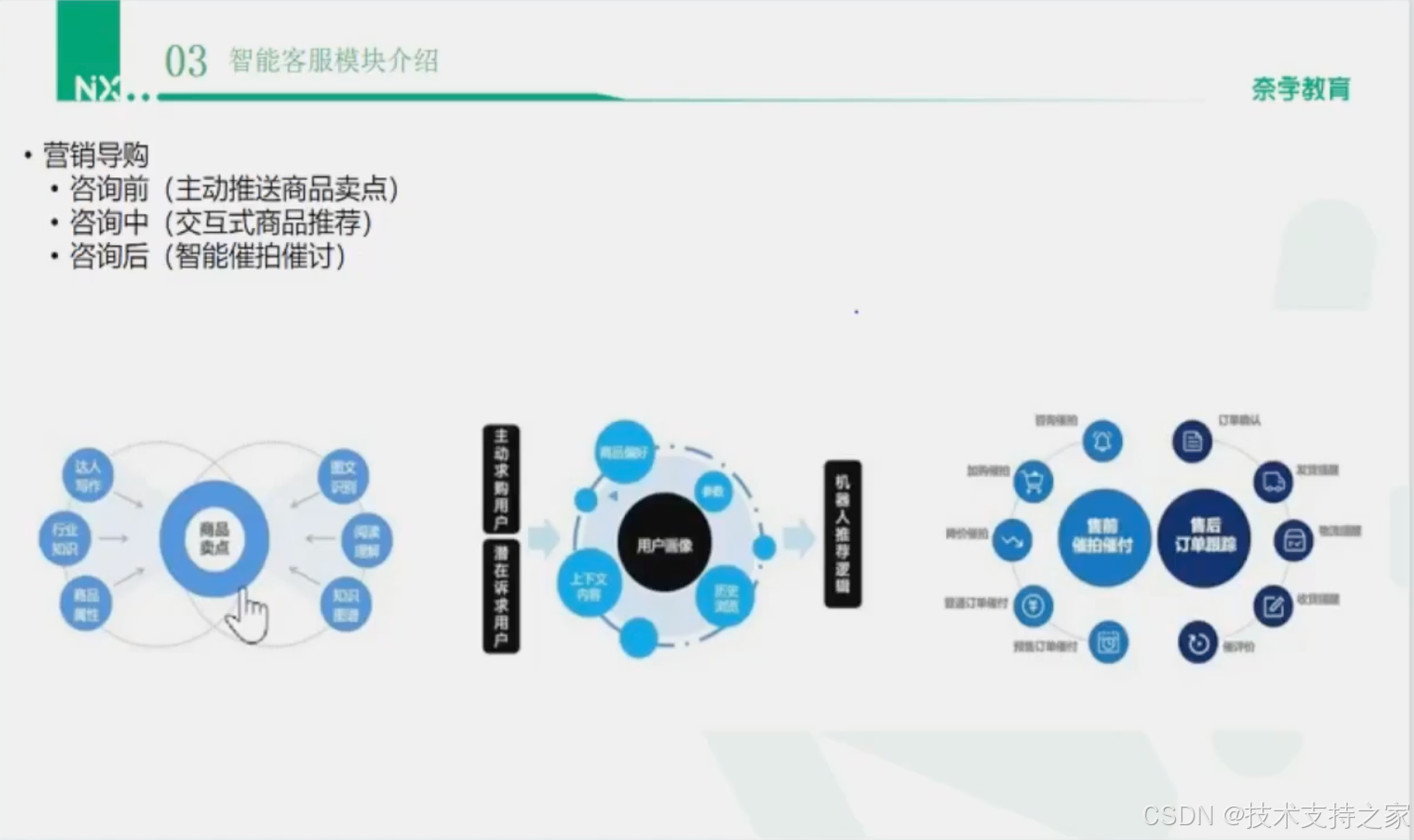
营销导购

交互式商品推荐
智能催拍
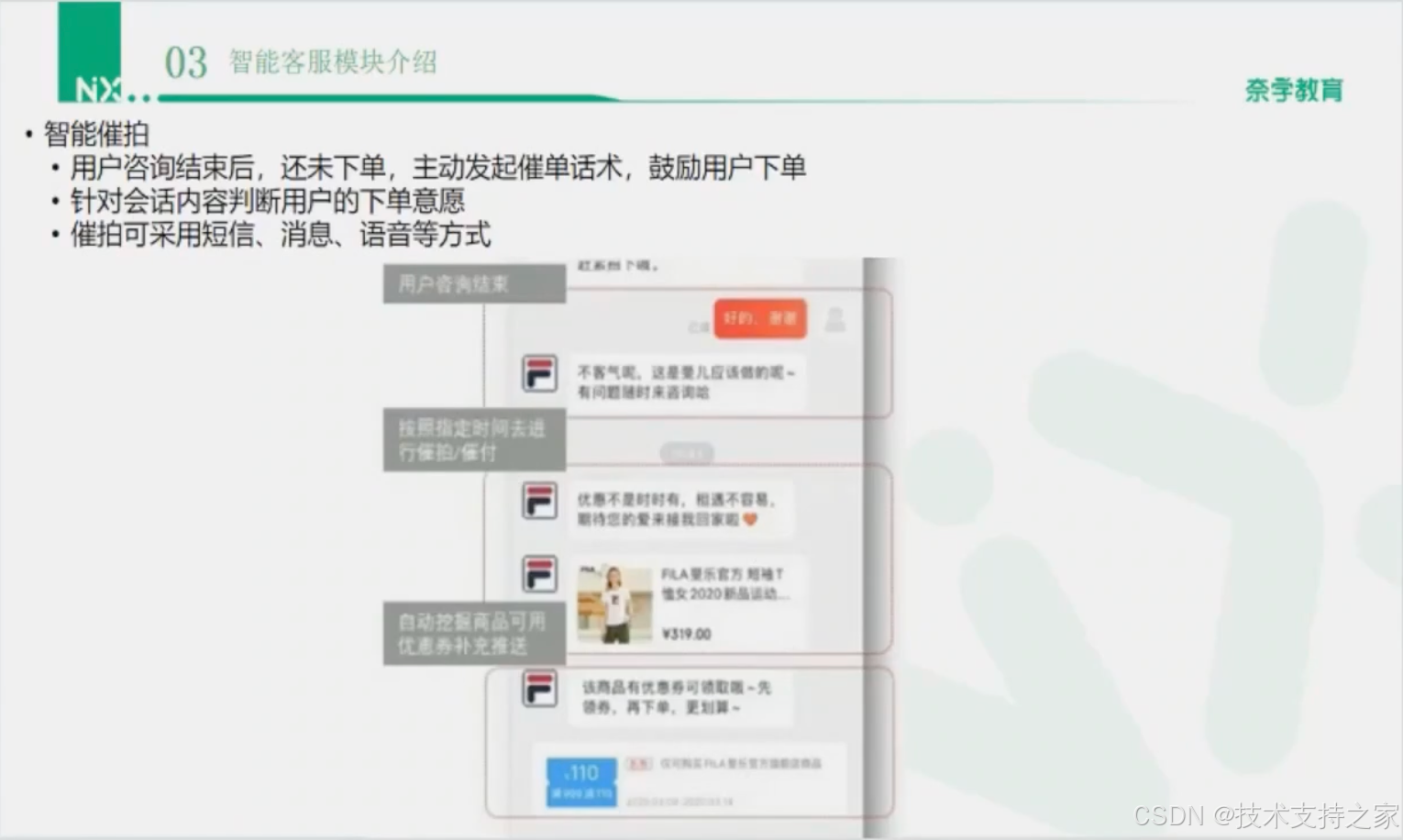
智能客服评价指标
介绍如何评价智能客服做的好与不好,有哪些评价指标。
数据指标

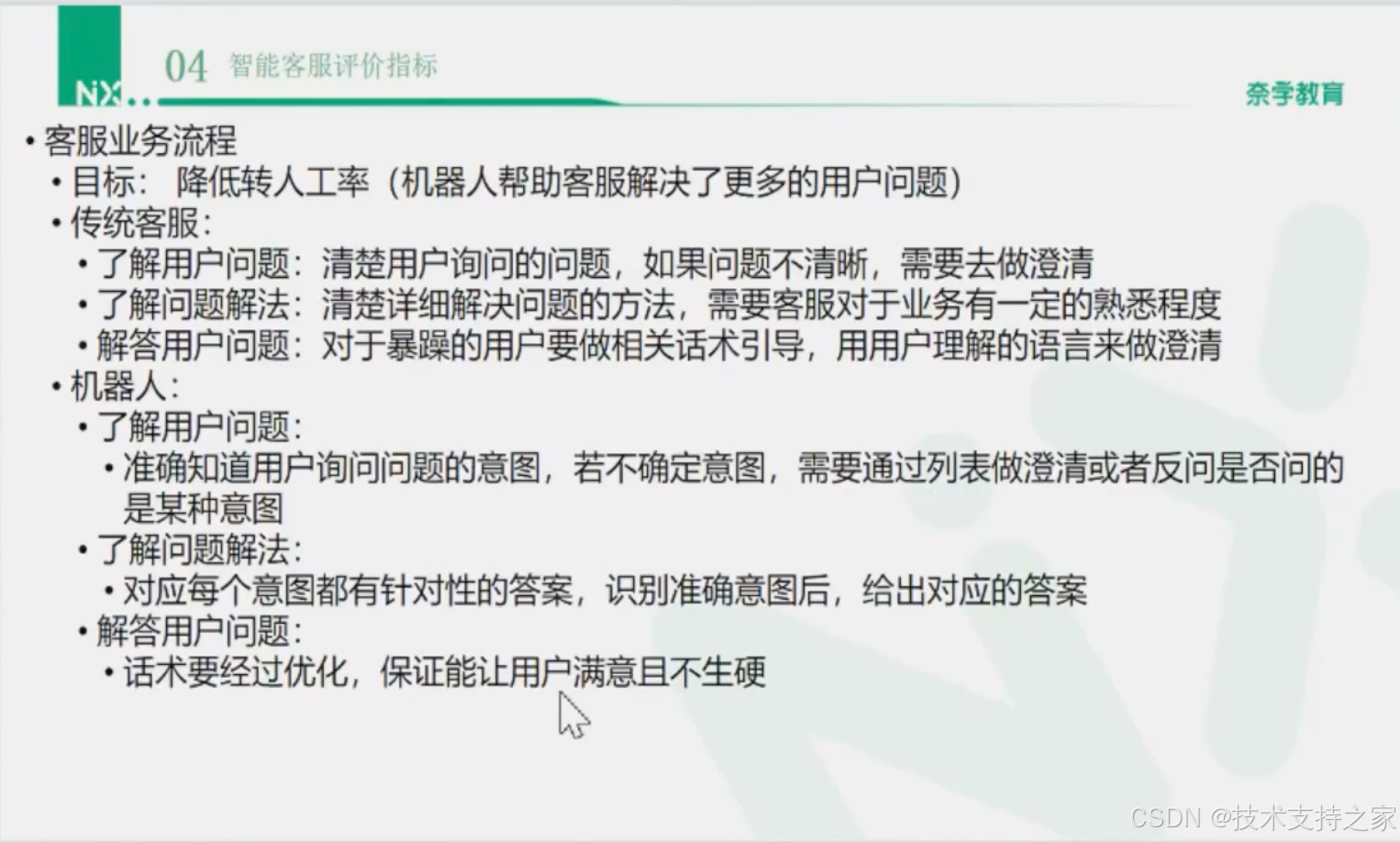
客服业务流程
降低转人工率
识别多不多--识别准不准--回答好不好
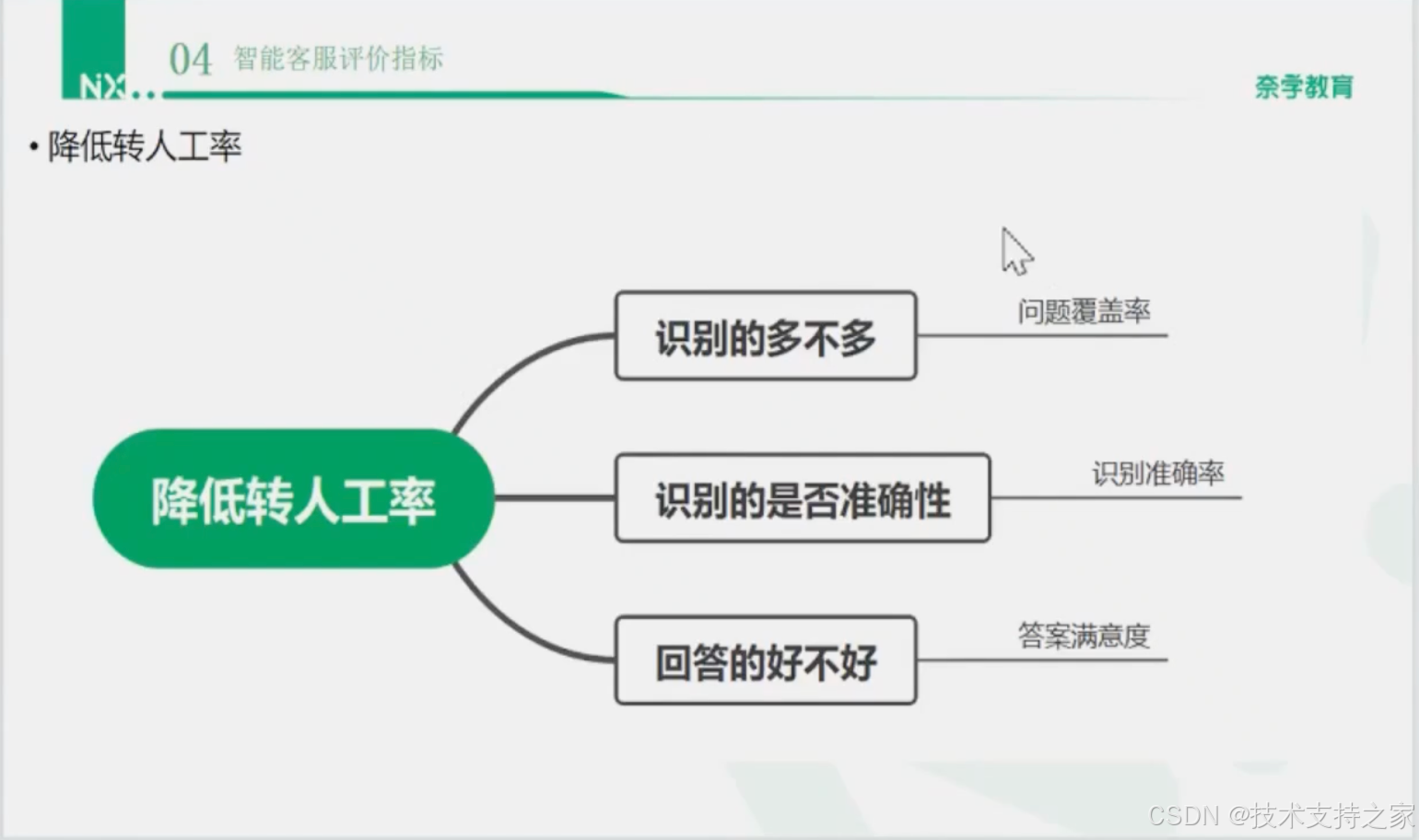
问题覆盖率

问题识别准确率

问题回答满意度

其他指标


















 4357
4357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









