







DataWhale的一篇文章,觉得很好,原文在此。结合自己的经历,梳理如下:
引言
随着人工智能的飞速发展,大模型技术不断突破,我们追求的不再仅限于文字交流,而是期待更加自然、真实的交互方式。OpenAI的GPT-4带来了实时语音对话功能,其低延时和真实声音极大地提升了交流体验。现在,我们能否进一步通过数字人作为媒介,实现面对面的交互呢?这样的交流将结合自然流畅的语音和数字人的形象,仿佛与真人面对面交谈,为交流增添更多真实感。ChatGPT等先进模型的出现,让数字人具备了更强大的智能,使虚拟陪伴、智能助手等功能成为可能,为人们带来了全新的交互体验。
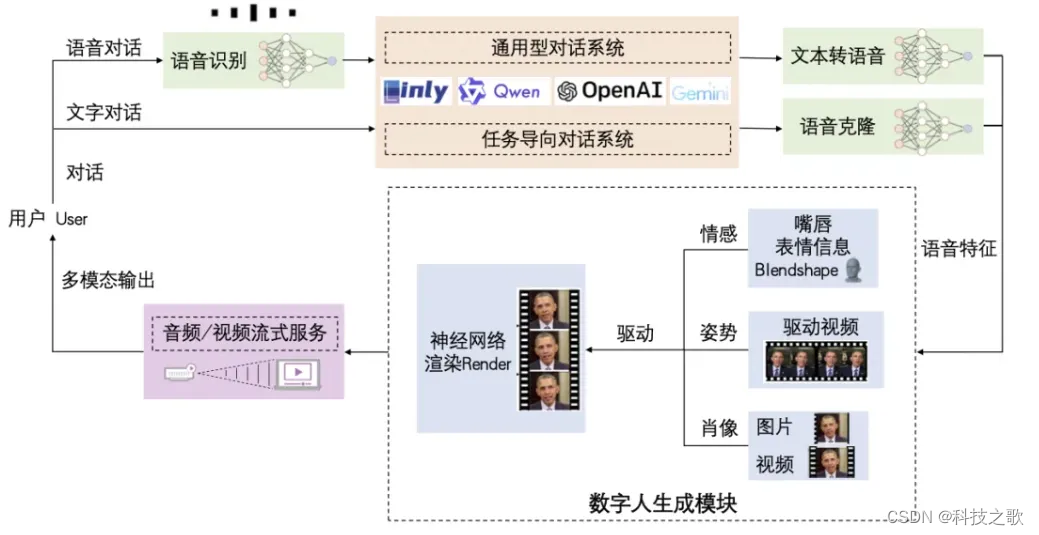 在人工智能时代,带来了一种新的人机交互的范式,可称为“数字人智能对话系统”,根据其功能,整个系统大概需要五大块组成,如上图所示:
在人工智能时代,带来了一种新的人机交互的范式,可称为“数字人智能对话系统”,根据其功能,整个系统大概需要五大块组成,如上图所示:
💡 自动语音识别(ASR):将用户的语音输入转换为文本,能够更流畅的进行语音对话。
💡 大型语言模型(LLM):作为系统的语言处理中枢为数字人赋能,负责理解用户的输入并生成合适的回应。
💡 文本到语音转换(TTS)/ 语音克隆 (Voice Clone):将系统生成的文本回应转换为语音,使用户听到流畅自然的语音输出。
💡 数字人生成(TFG):结合语音特征与数字人技术生成数字人的形象和动作,提升交流的互动性。
💡 音视频流式服务(streaming):利用流式服务提高交互体验,能够达到实时的效果。
🔹 ASR:语音识别技术——同数字人沟通的桥梁
在数字人智能对话系统中,自动语音识别(ASR)是与数字人沟通的重要桥梁。用户通过语音进行对话,我们需要将语音转成文字,以便后续的大语言模型(大脑)能够理解和学习,从而实现更好的沟通和交流。在现有开源 ASR 模型中,比较好的分别是 OpenAI 的 Whisper 模型[1]以及阿里达摩院的 FunASR 模型[2]。

Whisper:https://github.com/openai/whisper
FunASR:https://github.com/alibaba-damo-academy/FunASR
通过这些 ASR 模型,我们能够实时将语音转换为文字。在 GPT4o 的语音对话系统中,可能使用的就是 Whisper 模型。我们也可以使用 Whisper 模型或 FunASR 模型来搭建自己的智能语音助手。
Whisper 和 FunASR 都提供了良好的 API 接口,使我们能够快速搭建系统。以下是关于 Whisper 和 FunASR 的两个演示,只需安装相应的环境,即可快速使用这些强大的开源语音识别模型。
'''
Reference: https://github.com/alibaba-damo-academy/FunASR
pip install funasr
pip install modelscope
pip install -U rotary_embedding_torch
'''
from funasr import AutoModel
class FunASR:
def __init__(self) -> None:
self.model = AutoModel(model="paraformer-zh", model_revision="v2.0.4",
vad_model="fsmn-vad", vad_model_revision="v2.0.4",
punc_model="ct-punc-c", punc_model_revision="v2.0.4",
# spk_model="cam++", spk_model_revision="v2.0.2",
)
def transcribe(self, audio_file):
res = self.model.generate(input=audio_file,
batch_size_s=300)
print(res)
return res[0]['text']
'''
https://github.com/openai/whisper
pip install -U openai-whisper
'''
import whisper
class WhisperASR:
def __init__(self, model_path):
self.LANGUAGES = {
"en": "english",
"zh": "chinese",
}
self.model = whisper.load_model(model_path)
def transcribe(self, audio_file):
result = self.model.transcribe(audio_file)
return result["text"]
🔹 LLM:大语言模型——大语言模型为数字人赋能
通过语音识别(ASR)将语音转化为文本后,智能数字人对话系统会将文本输入到大语言模型中。大语言模型可以视为数字人的大脑,利用大语言模型为数字人赋能。随着人工智能的发展,大语言模型的发展的速度也是越来越快,因此在 LLM(大语言模型)部分有很多选择。
可以利用 OpenAI 和 Google 的 API 直接调用 LLM,也可以使用诸如百度和 kimi 等开放平台提供的接口。在资源允许的情况下,还可以在本地部署开源大语言模型,如 Llama、Qwen、Linly、ChatGLM 等,以确保对话过程中个人信息的安全。此外,还可以采用 langchain 等方法来扩充知识库,甚至定制适用于自身需求的大语言模型。在 Linly-Talker 项目中,已经集成了多个大语言模型,用户可以选择使用适合自己需求的大语言模型来与数字人进行对话,从而充分利用大语言模型为数字人赋能,实现更加优质的对话体验。
🔹 TTS:语音合成技术——赋予数字人真实的语音交互能力
在大语言模型生成文本结果后,需要通过 TTS(文本转语音)技术将文字转化为语音,从而赋予数字人真实的语音交互能力。这正是 GPT-4o 所在进行的工作。通过整合文本生成、语音合成和数字人驱动技术,GPT-4o 能够将大语言模型的反馈转化为语音,并使用先进的语音生成模型提高交互的真实性。
在现有的 TTS 技术中,有几个值得关注的模型和平台。开源领域中,微软的 TTS 是一个优秀的选择。在 https://github.com/rany2/edge-tts 项目中,作者利用 Edge 浏览器接口实现了微软 TTS 的语音生成。该项目支持多种声音,并允许调节语速和音调,不仅免费且速度快。此外,OpenAI 也开放了语音合成接口(https://platform.openai.com/docs/guides/text-to-speech),可以通过 API 方式接入 OpenAI 的语音合成,生成更具质感和情感的声音。
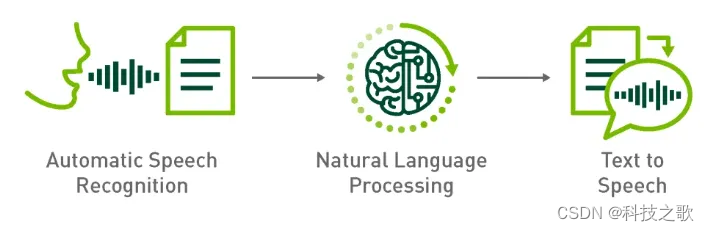 除此之外,在huggingface上有一个开源TTS的排行榜(https://huggingface.co/spaces/TTS-AGI/TTS-Arena),可以关注优秀的语音合成模型来赋予数字人更加真实的语音交互能力。
除此之外,在huggingface上有一个开源TTS的排行榜(https://huggingface.co/spaces/TTS-AGI/TTS-Arena),可以关注优秀的语音合成模型来赋予数字人更加真实的语音交互能力。
🔹 Voice Clone:声音克隆技术——在对话中模仿用户的声音
除语音合成之外,声音克隆技术是一个很好的研究方向,不过这块充满风险(与声纹识别技术一体两面)。在现有的开源方法中能够通过 10 s中的少样本语音来克隆声音,在未来会衍生出定制数字人的方案。通过克隆语音加上克隆数字人形象来定制一个完整的数字人,这个数字人不仅仅带有真实的面孔还有真实的声音。
这块应用有用AI“复活”已故亲人,做情感陪伴。

参考地址:
XTTS:https://huggingface.co/spaces/coqui/xtts
GPT-GoVITS:https://github.com/RVC-Boss/GPT-SoVITS
OpenVoice2:https://github.com/myshell-ai/OpenVoice
接下来介绍一下现有语言克隆模型中比较好的一部分,实际上还有火山克隆等 API 的方式,效果也是比较不错的。
这些技术的应用不仅能够在对话中提供更加个性化和真实的语音体验,还为未来的数字人定制方案提供了强有力的技术支持。
🔹 THG:智能数字人构建——打造智能数字人
在数字人智能对话系统中,最为重要的一环是构建智能数字人。Talking Head Generation(语音驱动人脸生成)一直是人工智能领域的热门研究方向,并且在近期取得了显著进展。简而言之,这项技术通过输入语音和图片/视频,让静态图像或视频中的人物“动起来”,使得数字人能够进行真实的表达。这一步骤的关键在于数字人能否精准对口型,并且达到高质量的生成效果。实际上,数字人的概念非常广泛,凡是通过数字技术创造出的人类形象接近的虚拟人物都可以称为数字人,而 TFG(Talking Head Generation)则是其中一种基于语音驱动的人脸技术。
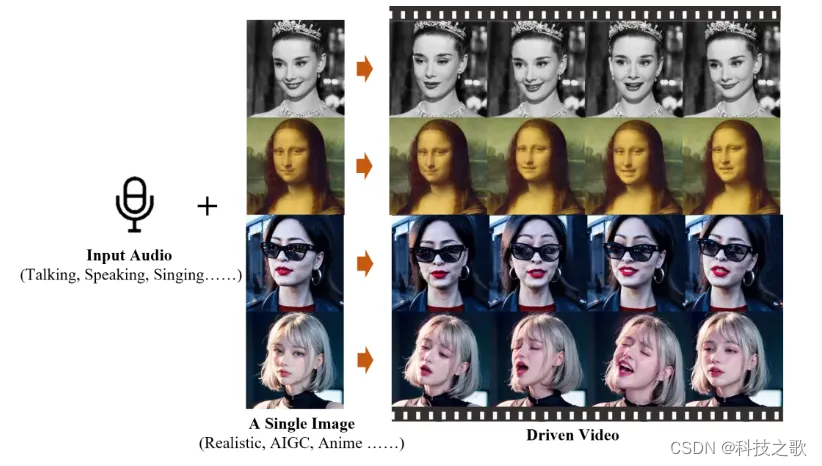 现有的语音驱动人脸技术已有较多的方法和方案,整体来说分为三种:
现有的语音驱动人脸技术已有较多的方法和方案,整体来说分为三种:
▪️ 单图输入驱动数字人
▪️ 视频输入驱动数字人
▪️ 定制数字人进行驱动
前两种方法一般采用基于卷积神经网络(CNN)和生成对抗网络(GAN)的方法,最火的是就是 2020 的 Wav2Lip,它能够将语音与静态图像或视频结合,生成逼真的数字人视频,同样有趣的还有 CVPR2023 的 SadTalker,可以通过单图生成数字人。

第三种方法在 NeRF(神经辐射场)技术出现后取得了突破,以 AD-NeRF[9] 为范式,通过五分钟的视频训练即可重建一个高度逼真的数字人。最新的 CVPR2024 的 SyncTalk[10] 技术更是能达到每秒 40 帧的生成速度,几乎实现了实时效果。
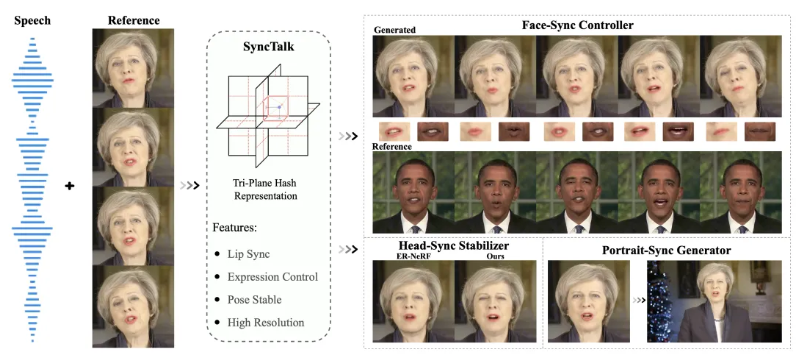
此外,近期广受关注的还有阿里的 EMO和微软 VASA-1,不仅生成效果逼真,而且在多个方面表现优异。这些方法基于强大的扩散模型的能力(diffusion-based),进一步提升了数字人生成的质量和速度。此外,腾讯也开源了 MuseV 和 MuseTalk 的数字人生成技术解决方案,能够在实时条件下生成高质量的数字人视频。
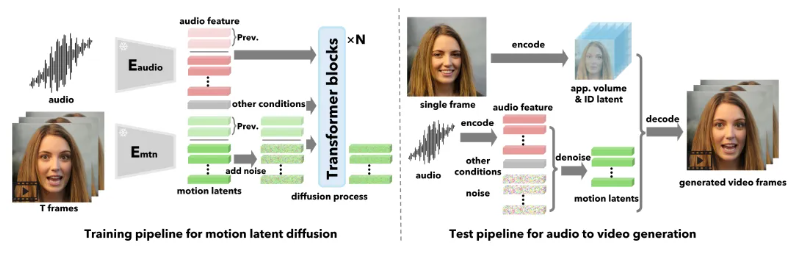
通过这些先进的技术,数字人智能对话系统可以提供更加沉浸式和自然的人机交互体验,使得数字人不仅能“听”懂和“理解”用户,还能以逼真的语音和形象进行互动。
🔹 Streaming:音视频流服务——提供流式音视频服务
在数字人智能对话系统中,音视频流式服务是确保实现实时交互的关键技术之一。通过这项技术,用户的语音和图像数据可以实时传输到系统,同时系统生成的音视频内容也能即时反馈给用户,从而保证了对话的连贯性和互动的自然性。
这一技术模块的主要目标是实现对话的即时性,使得用户能够与数字人进行流畅的交流。通过音视频流式服务,用户可以享受到更加沉浸式和真实的人机交互体验,从而提升了整体对话系统的用户体验。
音视频流式服务需要依赖高效的实时传输技术,如 WebRTC 和 RTMP。这些技术能够确保在低延迟、高带宽环境下传输音视频数据,从而实现实时的交互体验。
以下是一个来源于 VASA-1 的一个 demo 演示,能够低延时利用数字人反馈,完成了音视频流式服务:
🔹 总结展望——探讨未来的发展方向
本文介绍了一种在人工智能时代带来的新型人机交互范式——数字人智能对话系统。通过整合自动语音识别(ASR)、大型语言模型(LLM)、文本到语音转换(TTS)、语音克隆(Voice Clone)以及数字人生成(TFG)等多项技术。我们探讨了各个技术模块的功能和实现方式,展示了如何通过高效的音视频流式服务来实现实时、自然的人机对话。随着人工智能技术的不断发展,数字人智能对话系统将迎来更加广阔的发展前景,如以下几个方面:
🔸 更加智能的对话体验:随着大型语言模型的不断进步和优化,数字人智能对话系统将能够实现更加智能、自然的对话体验。系统将能够更好地理解用户的意图和情感,从而提供更加个性化、贴近用户需求的回应。
🔸 更加沉浸式的交互方式:随着语音克隆技术和数字人生成技术的不断发展,以及类似于VR、MR等技术的沉淀,数字人将能够以更加逼真的语音和形象与用户进行交互,从而提供更加沉浸式、真实感的交互体验。
🔸 多模态交互的普及:未来的数字人智能对话系统将更加注重多模态交互,不仅支持语音和文字输入,还将结合图像、视频等多种输入方式,为用户提供更加丰富多样的交互体验。
🔸 个性化定制服务:数字人智能对话系统将根据用户的偏好和习惯,提供个性化专属服务。系统将能够学习用户的喜好和行为模式,利用用户数据驱动业务策略,从而为用户提供更加个性化、贴心的服务和建议。
🔸 社交互动与情感陪伴:数字人智能对话系统将不仅仅是简单的工具,还将成为用户的情感伙伴和社交伙伴。系统将能够理解用户的情感和情绪,与用户进行情感交流和互动,为用户提供情感上的支持和陪伴。
数字人智能对话系统将在未来成为人们生活中不可或缺的一部分,推动人机交互进入一个新的时代,为用户提供更加智能、个性化、沉浸式的交互体验,成为人们生活和工作中的重要助手和伙伴。


















 866
866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











