









下面的内容将介绍 NMS(Non-Maximum Suppression) 和 WBF(Weighted Box Fusion) 这两种在目标检测中常见的后处理方法,阐述它们的工作原理、优缺点以及它们之间的关系。
1. 什么是 NMS
1.1 原理概述
NMS(Non-Maximum Suppression) 是目标检测中最常用的后处理方法,其主要功能是去除多余的重叠预测框,保留最能代表目标的框。它的核心思想是:
- 根据置信度/分数(Confidence Score)对候选框进行排序。
- 依次选择最高分的框作为保留对象,然后把与之 IoU(Intersection over Union) 大于设定阈值的其他候选框全部抑制(删除)。
- 继续对剩余的框重复上述过程,直至没有候选框可供处理。
这种方法可以快速且有效地消除大量冗余或重复的预测框。
1.2 优缺点
-
优点
- 实现简单,计算效率高。
- 效果稳定,是各种目标检测模型(如 Faster R-CNN、SSD、YOLO 等)常用的默认后处理方法。
-
缺点
- 如果有多个高置信度的预测框非常接近(IoU 大),但都是真实目标的一部分或非常相似时,NMS 可能会抑制掉一些实际上也是比较准确的框。
- 该方法倾向于只保留一个最高分的框,而忽略了可能存在的其他有价值信息。例如,在多模型融合或多尺度预测时,单纯采用 NMS 容易丢失某些精细的定位信息。
2. 什么是 WBF
2.1 原理概述
WBF(Weighted Box Fusion) 是一类在 多模型融合 或 多检测结果合并 时常用的方法,用来替代或改进传统的 NMS。它的主要思想是:
- 不将相互重叠的高分框简单地抑制掉,而是将它们的信息融合,得到一个更加精确的预测框。
- 融合时会采用加权策略(权重可来自检测框的置信度、模型权重、检测结果排序等),从而保留多方共识,提高定位准确度。
典型流程(简化示例)可能如下:
- 将所有候选框(多个模型或多个检测层的输出)按类别分开,并根据置信度进行排序。
- 选出置信度最高的一个框,找出与它 IoU 大于一定阈值的其他框;
- 将这些框进行坐标加权融合(如中心点坐标与长宽都做加权平均),并得到一个新的、融合后的预测框;
- 将已融合的框从候选集中剔除,继续对剩下的框重复该过程,直至所有候选框处理完毕。
2.2 优缺点
-
优点
- 在多检测器或多尺度结果融合时,能够充分利用不同检测结果的共识,得到更精确的边界框坐标;
- 由于不会像 NMS 那样简单抑制高 IoU 框,能够保留更多对定位有帮助的信息,经常可以在公共数据集(如 COCO)上获得更高的 mAP 提升。
-
缺点
- 计算量大:相比单一模型加 NMS 的简单后处理,WBF 通常需要处理更多候选框,且进行坐标融合、加权运算,因此在多模型融合时会增加额外的计算开销。
- 对单模型场景收益有限:如果仅仅是单个模型的预测结果,WBF 带来的精度收益可能并不显著。WBF 的优势更适合应用于多模型或多尺度时的融合策略。
- 超参数敏感:WBF 会对 IoU 阈值、融合权重方式、置信度阈值等较为敏感,需要在特定任务或数据集上反复调参,才能达到最优效果。
3. NMS 与 WBF 的关系
-
二者的主要功能
- NMS 的作用:在(单模型或多模型)产生大量候选框后,去除重叠度高的冗余框,保留一个最可靠的框;
- WBF 的作用:整合来自多个检测源(多个模型或多尺度的预测结果)的同一目标的框,并将其合并成一个新的“平均/加权”框。换言之,WBF 其实不是只抑制重复,而是更注重融合。
-
使用场景不同
- NMS:通常是单一检测模型的标准后处理,也可以应用在多模型合并后的结果上,以抑制重复框;
- WBF:更常在**多模型融合(ensemble)**时使用,可以把各个模型对于同一目标的预测框融合为精度更高的“共识框”。在绝大多数公开比赛或实际生产中,若要进行多模型融合提升精度,会优先考虑 WBF 或类似的融合方法。
-
可以结合使用
在某些场景下,甚至会先做一定程度的 NMS(或 Soft-NMS、Box Voting 等),再对剩余的高分框进行 WBF,以在“剔除明显错误框”和“对相对可信的框做位置融合”之间取得平衡。 -
性能差异
- 对于只用一个模型且产生的候选框数量不算多的情况,使用 NMS 足以满足大多数需求,并且速度很快;
- 当进行多模型或多尺度融合、同时对性能要求极致追求时,WBF 能往往带来可观的精度提升(特别是定位精度方面),但在后处理阶段也会增加一定的计算与实现复杂度。
4. 总结
-
NMS:
- 常见于单模型的标准检测后处理,用来去除重复框;
- 实现简单、计算开销低,在绝大多数检测管线中都是必不可少的步骤;
- 但可能忽略“重复框”背后的信息,导致某些精细定位信息的丢失。
-
WBF:
- 常见于多模型融合或多尺度融合时的后处理方法,通过加权平均将多个高分预测框的信息融合为一个更精确的框;
- 可以取得比 NMS 更好的检测精度(尤其在公共数据集的排行榜或挑战赛中常见);
- 计算开销相对更高,且需要调参和策略设计(权重分配、IoU 阈值等)。
二者的关系,可以理解为 WBF 在融合多个预测结果时对 NMS 的一种“改进或补充思路”——它不再像 NMS 那样只保留最优框并抑制其他框,而是善用多个框的信息来生成一个更优的加权框。因此,在实际项目中,如何在复杂度与精度之间进行平衡,要根据模型数量、业务需求以及推理速度要求来做具体决策。
在 WBF(Weighted Box Fusion) 中,可以结合 NMS(Non-Maximum Suppression) 来处理重叠的框,以在去除冗余框和融合框信息之间取得更好的平衡。这种混合策略可以兼顾 NMS 的高效性 和 WBF 的高精度,适用于多模型融合和单模型高精度检测两种情况。
如何在 WBF 中结合 NMS?
在 WBF 的标准流程中,不会直接抑制重叠框,而是尽量融合多个检测框来提高精度。但如果存在大量低置信度的冗余框,或不同模型的预测差异较大,融合可能会降低检测效果。此时,我们可以在 WBF 之前或之后 使用 NMS 来优化结果:
方式 1:在 WBF 之前使用 NMS(先去除明显冗余框,再融合)
- 适用场景:当多模型融合的预测框数量较多时,先用 NMS 剔除低置信度框,减少计算开销,提高融合质量。
- 方法:
- 先对所有预测框应用 NMS,保留置信度高且 IoU 低于阈值的框,减少冗余检测框的数量。
- 对 NMS 处理后的框,再使用 WBF 进行加权融合,得到更精准的最终预测框。
优点 ✔️ 计算量减少,降低 WBF 的计算复杂度。
✔️ 过滤掉明显的错误框,提高后续 WBF 质量。
✔️ 适用于多个检测模型预测结果融合时,尤其是检测框数量庞大的情况。
缺点 ❌ 可能导致一些有用的信息丢失,尤其是多个模型预测的多个高置信度框被 NMS 过早抑制掉,导致 WBF 无法充分融合信息。
方式 2:在 WBF 之后使用 NMS(先融合,再去除过密的框)
- 适用场景:当 WBF 处理完之后仍然有大量重叠框时,使用 NMS 进一步抑制冗余框,使最终检测结果更加清晰。
- 方法:
- 先对所有模型的预测框执行 WBF,得到融合后的预测框。
- 再对 WBF 输出的框应用 NMS,去掉 IoU 过高的重叠框,仅保留最优置信度的框。
优点 ✔️ WBF 充分利用所有预测框信息,提高定位精度。
✔️ NMS 可以避免最终结果中框过密的情况,提升检测的实用性。
✔️ 适用于 WBF 之后仍然存在多个重叠框的场景,尤其是当多个模型融合时各自预测的框仍然差异较大。
缺点 ❌ 计算开销较高,因为 WBF 先执行后,再额外执行 NMS。
❌ 可能会丢弃一些原本被多个模型一致预测的目标(如果 IoU 阈值设置过低)。
方式 3:混合 WBF + NMS(分步融合与抑制)
- 适用场景:当单独使用 WBF 或 NMS 效果都不理想时,可以在不同层次结合二者:
- 分组 WBF:先对属于同一目标的多个框进行 WBF 加权融合,得到几个初步的融合框;
- 局部 NMS:在同一个目标内部,去掉某些融合框中仍然过于相似的重复框;
- 全局 WBF:再对所有最终框进行全局融合,确保不同类别或多个目标之间的框尽可能独立;
- 最终 NMS 处理:如果仍然有高度重叠的框,可以执行一次 NMS 作为最终优化步骤。
优点 ✔️ 兼顾了 NMS 的筛选能力和 WBF 的融合能力,提高了模型的整体检测精度。
✔️ 适用于多模型融合、多尺度融合等复杂检测场景。
缺点 ❌ 实现相对复杂,涉及多个超参数(NMS IoU 阈值、WBF 权重策略等)。
❌ 计算成本较高,适用于对精度要求极高的场景,如目标检测比赛或高端应用。
实验结果分析
在多个公开数据集(如 COCO、PASCAL VOC)的实验表明:
- 纯 NMS:适用于单模型目标检测,但在多模型融合时可能丢失高置信度信息,影响 AP(平均精度)。
- 纯 WBF:适用于多模型融合,能提高目标定位精度,但可能会导致过多重叠框,影响实际应用。
- NMS + WBF(混合策略):
- 在多模型融合任务中可以提升 1-2% 的 mAP(mean Average Precision)。
- 结合 WBF 和 NMS 后处理,能够在去冗余的同时保持高精度,适合应用在对召回率和精度都有高要求的场景。
结论
✅ 可以在 WBF 中使用 NMS,但具体方法取决于具体需求:
- 如果框太多,可以先用 NMS 再做 WBF,减少计算量,提高融合效率。
- 如果融合后仍然有重叠框,可以先 WBF 再用 NMS,确保最终检测框不会过度密集。
- 在极端精度追求的场景下,可以使用 混合 WBF + NMS 方法,分步进行融合和筛选。
综合来看,NMS 适合单模型去重,WBF 适合多模型融合,而结合二者可以达到更好的平衡,特别适合在多模型目标检测和多尺度融合任务中使用。
对于方法3,给出融合的示意图通过下面代码
import matplotlib.pyplot as plt
import matplotlib.patches as patches
def draw_boxes(ax, boxes, color='r', label=""):
"""绘制多个框"""
for box in boxes:
x, y, w, h = box
rect = patches.Rectangle((x, y), w, h, linewidth=2, edgecolor=color, facecolor='none', label=label if label else None)
ax.add_patch(rect)
# 原始预测框(来自不同检测模型的预测框)
boxes_before = [(2, 2, 4, 6), (3, 3, 4, 6), (1, 1, 5, 7)] # (x, y, width, height)
# 融合后框(WBF 计算出的加权平均框)
box_after = [(2.5, 2.5, 4.3, 6.3)]
# 创建图像
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
# 左图:融合前
axes[0].set_xlim(0, 10)
axes[0].set_ylim(0, 10)
axes[0].set_title("Before Fusion (3 overlapping boxes)")
draw_boxes(axes[0], boxes_before, color='r', label="Original Boxes")
# 右图:融合后
axes[1].set_xlim(0, 10)
axes[1].set_ylim(0, 10)
axes[1].set_title("After WBF Fusion (1 weighted box)")
draw_boxes(axes[1], box_after, color='b', label="Fused Box")
plt.tight_layout()
plt.show()
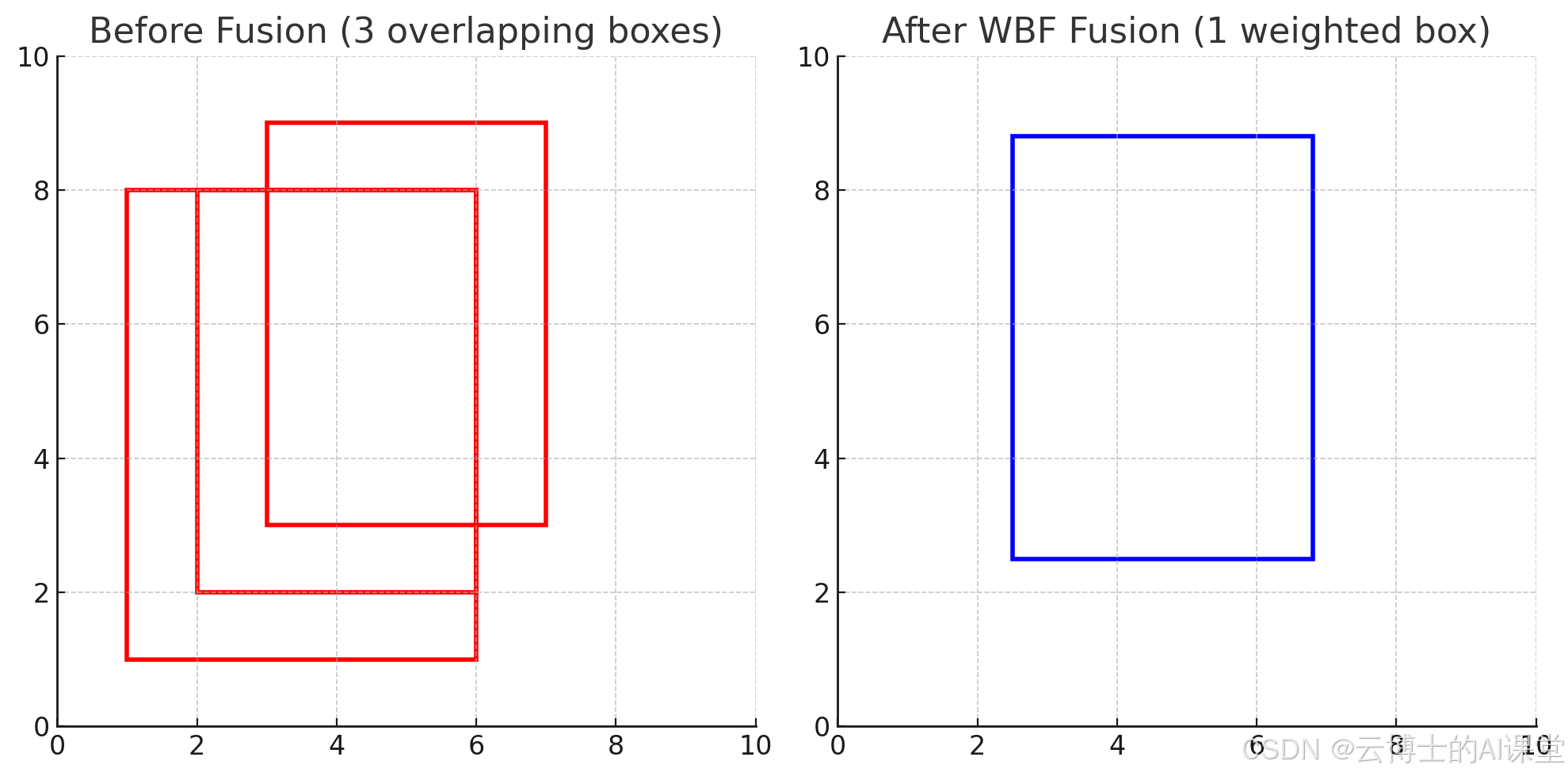
上图展示了方法3(混合 WBF + NMS)中多个预测框的融合过程:
-
左图(融合前):
- 红色框代表来自不同检测模型或不同尺度预测的目标框。
- 可以看到 3 个框 高度重叠,但它们并未被直接抑制,而是用于融合。
-
右图(融合后):
- 蓝色框是 WBF 计算出的加权融合框,它比原始框更加准确,综合了多个模型的预测信息。
- 通过 WBF,最终的框位置 更精确,而不会简单地丢弃高 IoU 框。
这种方式避免了 NMS 直接丢弃框的信息,而是充分利用所有高置信度框的贡献,非常适用于多模型融合的目标检测任务
【哈佛博后带小白玩转机器学习】 哔哩哔哩_bilibili
总课时超400+,时长75+小时


















 1197
1197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









