







转自:http://blog.csdn.net/liyaohhh/article/details/52115638
caffe源码学习:softmaxWithLoss
在caffe中softmaxwithLoss是由两部分组成,softmax+Loss组成,其实主要就是为了caffe框架的可扩展性。

表达式(1)是softmax计算表达式,(2)是sfotmaxLoss的计算损失表达。在caffe中是单独的计算每层的输入和输出,然后再进行向后传递data结果和向前传递diff的结果。
caffe中softmax的计算:
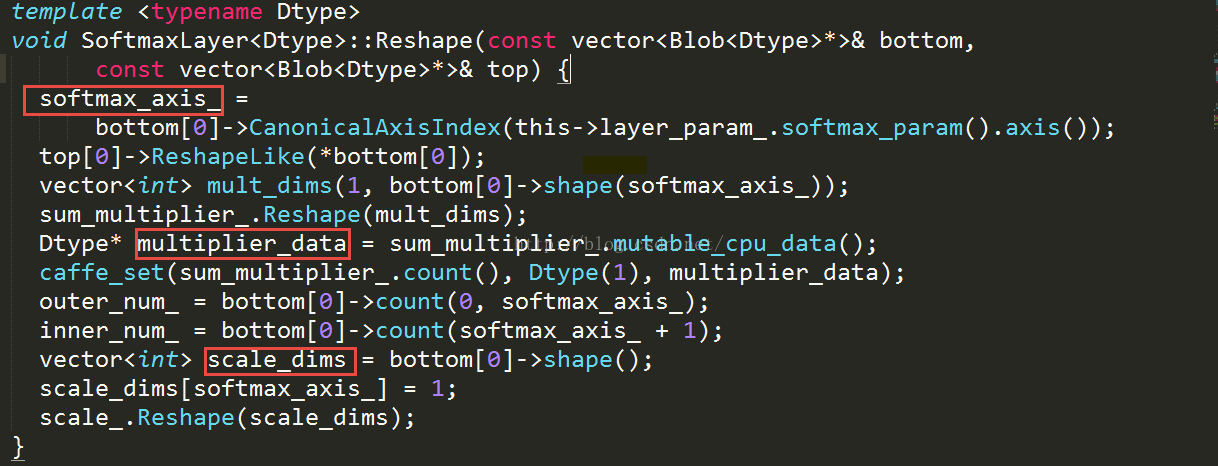
如上所示;在reshape阶段主要是进行相关参数维度的设定。softmax_axis主要是制定从哪个维度开始切,默认是1.后面主要是初始化了两个变量,sum_multiplier_和scale_局部变量的初始化。sum_multiplier_的形状是channel的大小,一般主要是通过矩阵乘法来实现每个feature map相对应的坐标数据进行相加或者相减或者其他的操作。scale通常情况下被用来当作临时的缓冲变量。这两个变量的使用在caffe中到处可见。接下来就是forward_cpu部分的代码。

首先还是获取top和bottom的data,把bottom的data中的数据拷贝给top,以后就直接在top中进行计算。另外在caffe中,dim变量表示的C*W*H,spatial_dim 标识的是W*H。
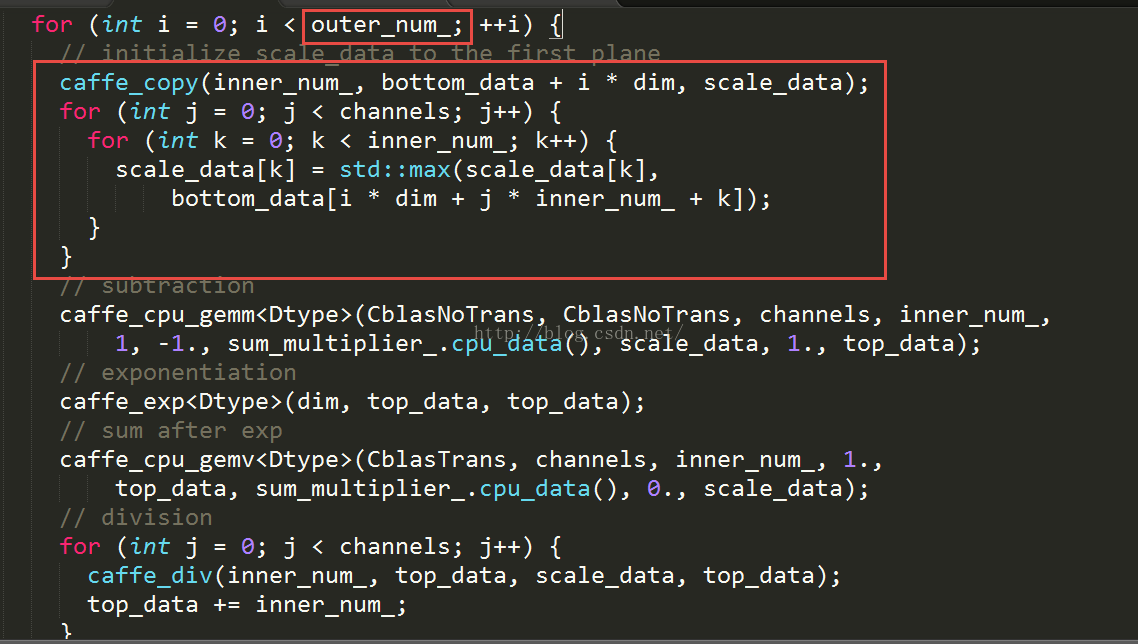
在上面首先是outer_num_样本数据中输入softmax的数据进行一个‘归一化’操作,大红色方框是为了找出当前instance中输入softmax的特征中的那个最大的数值,然后再减去那个最大数值防止产生数值计算方面的问题(例如在mnist数据集中,outer_num_是128代表的是batch的大小,inner_num_是1,这里的softmax前面链接的是inner product层,所以spatial_dim和inner_num的大小均为1,dim的大小是10,scale_data中其实也只有一个数,虽然caffe_copy之后有两行循环,其实由于inner_num是1,也就一行循环). 计算出最大的数值,然后把那个最大是数值乘以sum_multiplier_,就从1个数变成了C个数。继而做exp,把结果存放到topdata,然后把全部channel的数据求和(求和caffe使用矩阵和向量的乘法进行计算)存放到scale_data,形状是inner_num_,也就是W*H(其实就是1*1),最后就是除以求和结果啦。这么多的语句也就描述了表达式(1). 最主要的是考虑到了数值计算中存在的问题。
下面就应该是softmaxWithLoss计算损失;
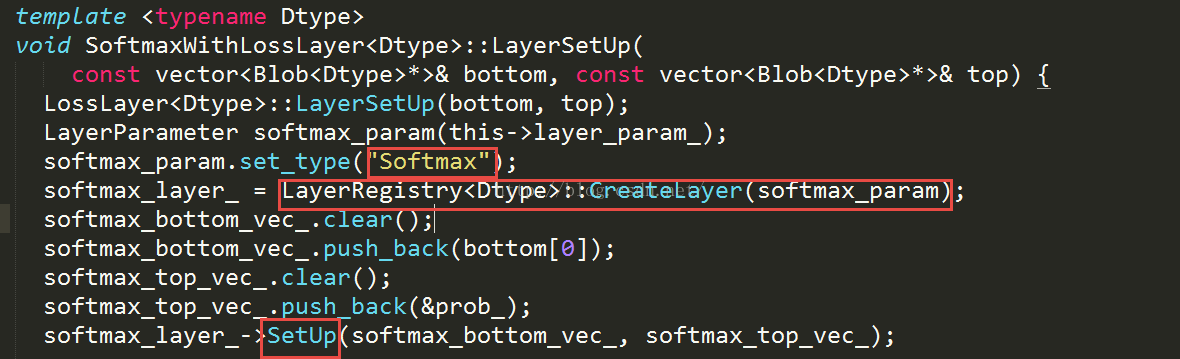
上面是softmaxWithLoss的set函数,可以和很清楚地看到在初始化完成softmax_param这个参数之后,直接把type设置成了softmax,然后又通过工厂函数创建softmaxlayer,继而进行Set_up函数。可以看出softmaxWithLoss是内部创建了一个softmaxlayer。

继续后面主要就是检查当前layer是否设定不对某个label进行计算Loss,也就是说,在mnist中有10个class,但是我只想对12345678进行分类,那就设定ignore_label为9.这个时候遇到标签是9的就不计算Loss。注意protobuf中没有设定默认的数值,has_xxx就返回false,只有设定了数值,才会true。后面的norm是为ignore服务的。

接下来的reshape函数也没啥用处,就是设定了三个变量。softmax_axis_=1,outer_num_=128,inner_num_=1.需要注意的是outer_num_ * inner_num_必须和bottom[1]->count()给定的lable数相同。也就是说当softmax前面接inner product的时候,每个lable对应的是instance对应的类别(一个数),但是当softmax前面是卷积层的时候,每个label就不是一个数,而是一个矩阵,对应着每个 feature map中每个像素值的分类。下面就是计算Loss:

这里寿面是计算softmax_layer_的forward函数,softmax_top_vec_其实是prob_的一个引用。prob_data的大小是N*C*1*1.static_cast<int>(label[i * inner_num_ + j])是从对应的instance中取出相对应的标签。如果当前的label和ignore label相同,那么就不计算Loss损失,这样就存在问题,假如128个instance中有10个不计算Loss,那么最终在计算Loss的平均的时候,是除以多少呢?这就用到了norm。count在这里统计我们计算了多少个instance的Loss数值。prob_data[i * dim + label_value * inner_num_ + j] dim是10,label_value是instance的标签来当作index来从prob中取数据(该instance的分类结果),j是0,因为W=H=1。

get_normalizer在VAILD模式下会返回我们计算了多少个Loss的个数,也就是count。这个时候当前batch的Loss就已经放回到top[0]中去了。下一步要计算的就是Loss的反向传播。















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









