






写在前面
大家好,我是刘聪NLP。
前几天在做生成任务的时候,在Github里搜索「中文BRAT模型」,一下搜到了复旦大学邱锡鹏老师组的「CPT」(Chinese Pre-trained Unbalanced Transformer)论文,并且在该论文中开源了中文的BART模型(感恩)。
个人在自己的对话生成任务上进行了简单的实验,发现CPT模型在某些任务上,不仅效果好,生成推理速度也很快,所以在此分享给大家。
paper:https://arxiv.org/pdf/2109.05729.pdf
github:https://github.com/fastnlp/CPT
介绍
自2018年BERT模型横空出世,预训练语言模型基本上已经成为了自然语言处理领域的标配,而目前的很多预训练语言模型不能很好地兼顾在NLU任务和NLG任务。如下表所示,以Transformer-Encoder结构为主的预训练语言模型,BERT、RoBERTa、ZEN、NEZHA、ERNIE-1.0/2.0等模型在NLU任务上表现更突出;以Transformer-Decoder结构为主的预训练语言模型GPT、CPM等模型在无条件NLG任务上表现更突出;以Transformer-Encoder-Decoder结构为主的预训练语言模型CPM-2、BART、T5等模型在有条件NLG任务上表现更突出。
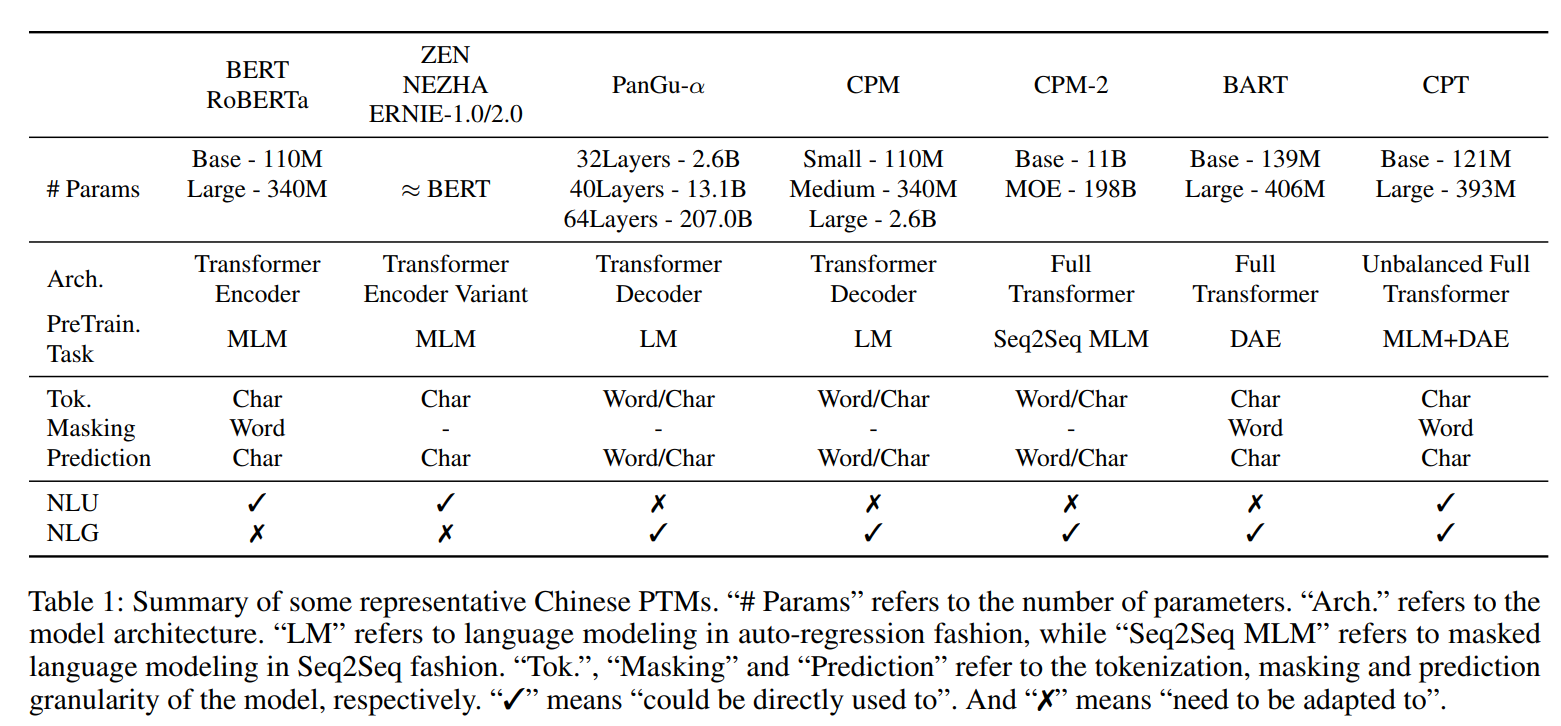
有人会说:有一些其他的统一模型可以兼顾NLU任务和NLG任务。不要急,后面会进行对比介绍。
而在该篇论文中,提出了一种新的中文预训练非平衡变压器CPT,它同时适用于NLU和NLG任务。
模型结构
CPT的架构非常简单,它将完整Transformer的Encoder-Decoder结构进行改变,如下图所示,
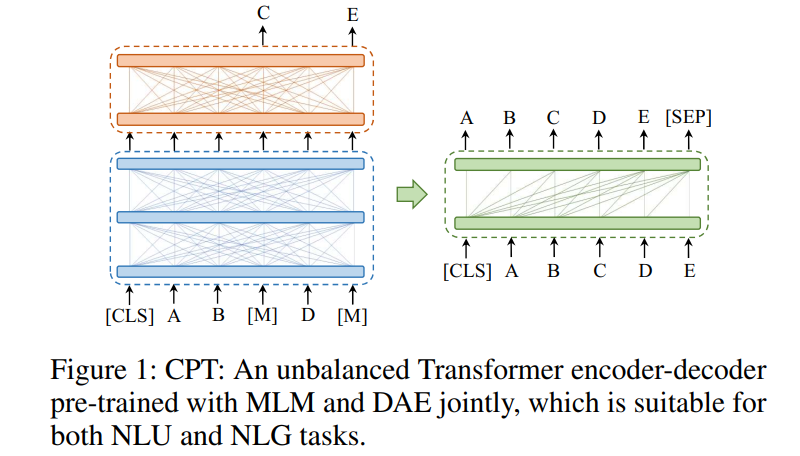
主要由三个部分组成:
-
共享编码器(S-Enc):其结构为深层Transformer-Encoder,目的是获取用于语言理解和生成的通用语义表示。
-
理解解码器(U-Dec):其结构为浅层Transformer-Encoder,专为NLU任务设计,U-Dec的输入是S-Enc的输出,并通过MLM(masked language modeling)任务进行预训练。
-
生成解码器(G-Dec):其结构为浅层Transformer-Decoder,为NLG任务设计,适合处理条件生成任务,并通过DAE(denoising auto-encoding)任务进行预训练。
通过多任务的联合预训练,CPT模型能够分别提高语言理解能力和生成能力。由于采用较深的共享编码器(S-Enc)和两个较浅的解码器(U-Dec、G-Dec),在ULN任务上计算成本不变,但在生成任务上,「浅层解码器可以更快地推理生成」。
简单地,可以理解为,将BERT模型和BART模型放到了一起,共有前六层参数,后六层参数,分别用各自模型的。当然CPT模型编码器和解码器层数不平衡,并且这种不平衡操作已经在机器翻译和纠错任务上得到验证(可见原文参考文献)。
与其他统一模型的区别
-
「与Unilm模型的区别」 UniLM模型使用一组不同的attention mask机制进行预训练,这使得该模型可用于生成和分类任务。不同之处在于,UniLM模型的所有参数都在生成和判别任务上是共享的,而CPT使用两个独立的解码器,CPT可以利用很好地利用DAE预训练任务,训练更好地解码器,用于生成任务。
-
「与GLM模型的区别」 GLM模型与UniLM模型相似,使用了不同的attention mask机制和修改掩码内容的位置信息进行预训练。
-
「与PALM模型的区别」 PALM是一个专注于条件生成的预训练模型。为了迫使编码器理解给定上下文的含义,MLM被添加到预训练的编码器中。相比之下,CPT有一个单独的解码器可以避免DAE带来的负面影响。可以在NLU任务上也具有良好的性能。
-
「与ERNIE3.0模型的区别」 ERNIE3.0模型虽然使用了通用编码器和几种针对特定任务的解码器,但采用了Transformer-XL结构为骨干,并生成部分的预训练任务为左至右单向语言模型任务,而CPT采用编码器-解码器架构,更适合Seq2Seq任务。
预训练
共使用MLM和DAE两种任务进行模型预训练,如下:
-
MLM任务:采用MLM任务预训练S-Enc和U-Dec的参数。给定一个句子,采用全词掩码的技术,用[MASK]标记掩盖掉句子中原有15%的词语,并按照原始BERT的设置,仅有80%用特殊的[MASK]标记替换,有10%用字典中随机标记替换,有10%保持不变。
-
DAE任务:采用破坏原始文本再重构原始文本的方式,预训练S-Enc和U-Dec的参数。通过两种方法来破坏原始文本,如下:(1)Token Infilling:将选定的全词使用一个[Mask]标记替换;(2)Sentence Permutation:按标点切分文本后,将句子顺序随机打乱。
微调
由于CPT模型有两个解码器,因此在不同任务上,存在多种微调的形式,详细如下。
文本分类任务
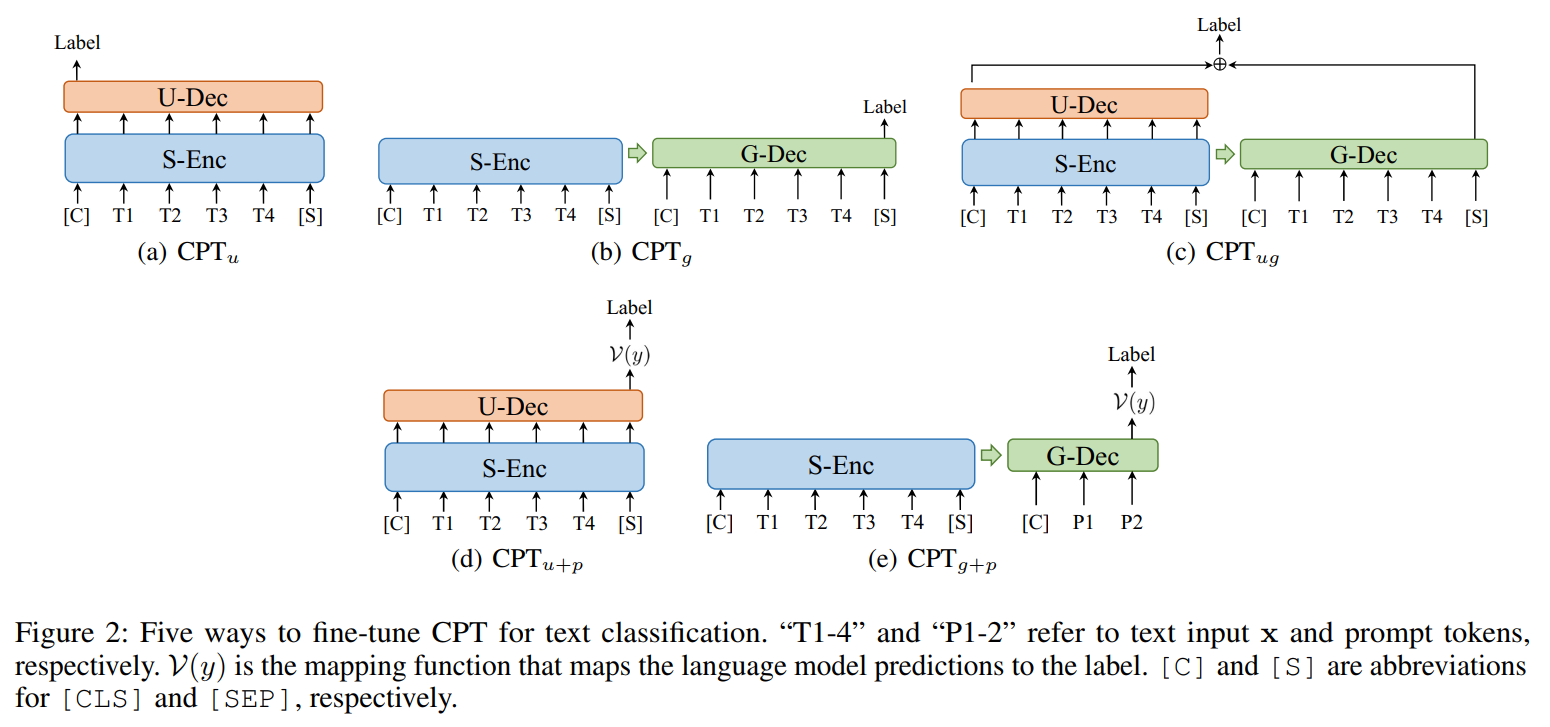
在文本分类任务上,共有5种微调方式,如下图所示,
-
:与BERT模型模式一致。将U-Dec模块的[CLS]向量接入全连接层,进行分类。
-
:与BART模型模式一致。将相同的文本输入S-Enc和G-Dec模块中,将G-Dec模块的最终输出[SEP]向量接入全连接层,进行分类。
-
:将相同的文本输入S-Enc和G-Dec模块中,将U-Dec模块的[CLS]向量与G-Dec模块的最终输出[SEP]向量进行拼接,再接入全连接层,进行分类。
-
:与BERT-Prompt方式一致,构造手工输入模板,将[Mask]标签预测到分类标签字符上,最终获取分类类别。
-
:将文本输入到S-Enc块中,用G-Dec模块进行分类标签字符预测,最终获取分类类别。
下表为五种方法,在CLUE不同数据集上的结果,可以发现,不同数据集上,微调方式的效果,略有不同,但是整体上,针对于base模型,方式更好;针对于large模型,方式更好。(下面在测试集上,均取上述策略作为微调策略)
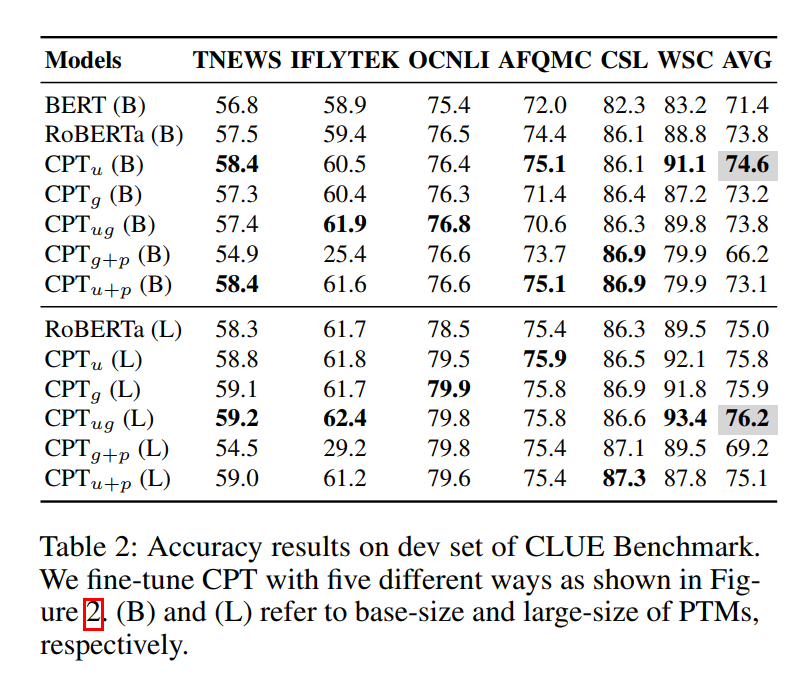
在CLUE上5种分类数据集上测试集结果,如下表所示,可以看出,大部分好于BERT以及RoBERT模型。
序列标注任务
与文本分类任务相似,包含三种微调策略,、和,下图仅展示了和
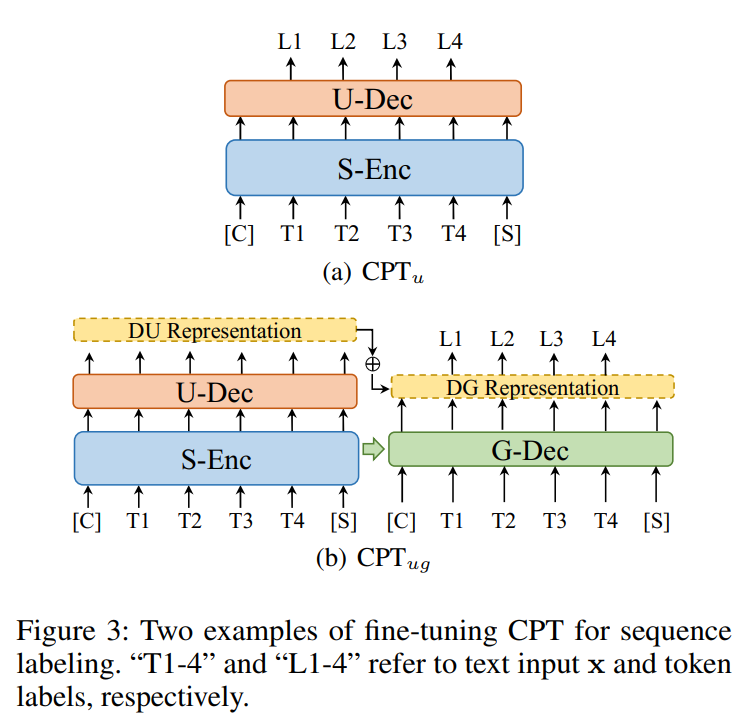
-
:与BERT模型模式一致。将U-Dec模块的每个字符向量进行分类,得到序列标签。
-
:与BART模型模式一致。将相同的文本输入S-Enc和G-Dec模块中,将G-Dec模块的每个字符向量进行分类,得到序列标签。
-
:将相同的文本输入S-Enc和G-Dec模块中,将U-Dec模块的每个字符向量与G-Dec模块的每个字符向量进行拼接,再进行分类,得到序列标签。 从下表中可以看出,在中文分词和命名实体识别任务上,CPT模型均取得了较好的效果。
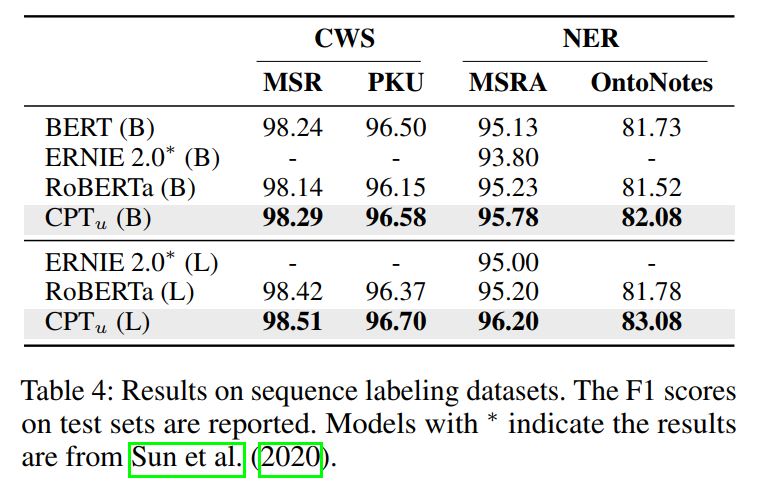
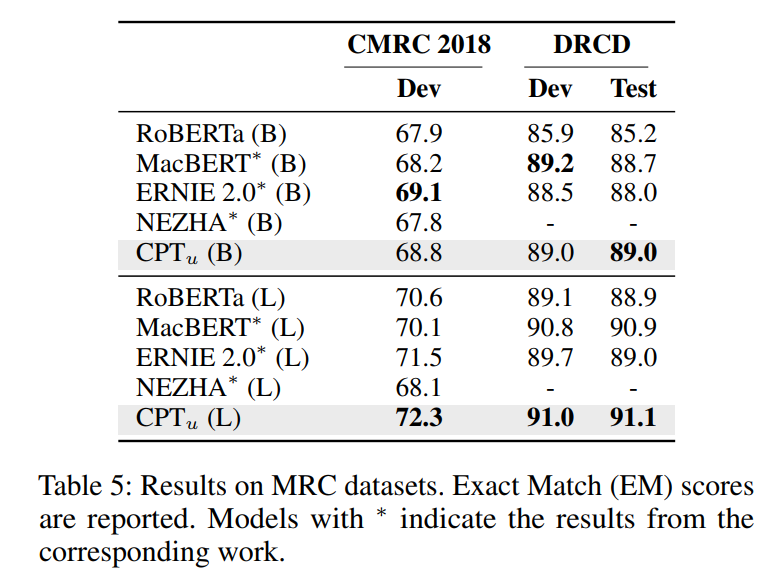
阅读理解任务
与序列标注任务相似,包含三种微调策略,从下表中可以看出,在CMRC2018数据集和DRCS数据集上,CPT-large模型均取得了较好的效果。
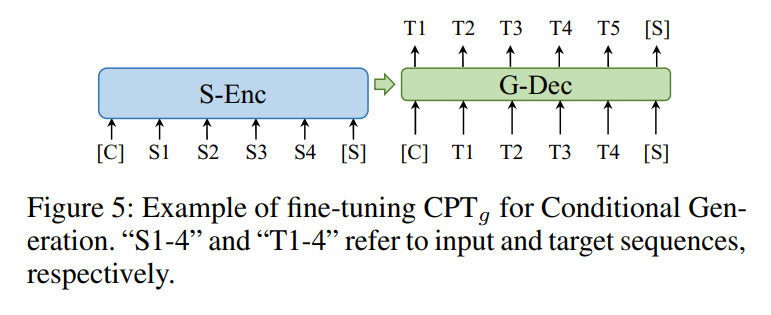
条件生成任务
与其他生成模型一致,如下图所示,将条件文本输入到S-Enc编码器中,然后通过起始字符通过G-Dec解码器进行逐字生成。
从下表中可以看出,CPT模型在条件生成任务上,也取得了不错的效果。 并且由于CPT模型仅采用了浅层解码器,因此推理生成速度较同量级的BART模型,快很多;base模型可以到达1.4-1.5倍速度,large模型可以达到1.7倍速度。
总结
首先CPT模型作为论文副产物,开源了一个质量较高的中文BART模型(感恩);其次CPT模型使用简单地方式,结合两个不同的解码器,将预训练语言模型有机的结合在了一起;最后采用非平衡的编码、解码层数,加快了生成模型的推理速度。
喜欢的的同学们,记得点赞,关注,转载请说明出处哟!!!
整理不易,请多多点赞,关注,有问题的朋友也欢迎加我微信「logCong」、公众号「NLP工作站」、知乎「刘聪NLP」私聊,交个朋友吧,一起学习,一起进步。
我们的口号是“生命不止,学习不停”。

















 1660
1660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









