







论文地址: https://arxiv.org/abs/2108.05542
1 导言
- 预训练的来源
- 最开始是基于规则的学习,后来被机器学习取代
- 早期机器学习需要特征工程,需要专业领域的知识,耗时
- 由于硬件和词嵌入的发展,类似于CNN、RNN的深度学习模型出现
- 问题:除词嵌入外需要从头开始训练模型、需要标记大量实例、成本很高
- 进而我们期望少量标记实例,尽可能少的训练步数
- 基于迁移学习(允许重用在源任务中学到的知识,以便在目标任务中很好地执行)的启发:
- 使用大规模标记数据集(如ImageNet[20],[21])训练大型CNN模型。这些模型学习在所有任务中通用的图像表示法。大型的预先训练的CNN模型通过包括几个特定于任务的层来适应下游任务,然后在目标数据集上进行微调。由于预先训练的CNN模型为下游模型提供了良好的背景知识,他们在许多CV任务中都获得了巨大的成功。
- CNN和RNN长程依赖问题---->Transformer:更好的并行化和长程建模
- T-PTLM(Transformer-based Pretrain Training Language Model)还支持迁移学习,因为这些模型可以通过对目标数据集进行微调或即时调优来适应下游任务
2 自监督学习 SELF-SUPERVISED LEARNING (SSL)
- 自我监督学习是一种相对较新的学习范式,由于它能够利用未标记的数据将关于语言、图像或语音的universal knowledge注入到预训练的模型中,因此在人工智能(AI)研究界得到了广泛的关注
2.1 为什么SSL
- 监督学习的问题使其陷入瓶颈(bottleneck)
- 严重依赖人工标注的实例,生成成本高、耗时长
- 缺乏泛化能力,存在虚假相关性(spurious correlations)
- 许多领域,如医疗和法律,缺乏数据,这限制了人工智能模型在这些领域的应用
- 无法从大量可免费获得的未标记数据中学习
2.2 什么是SSL
- 定义
- 自监督学习(Self-Supervised Learning,SSL)是一种新的学习范式,它基于训练前任务提供的伪监督,帮助模型学习普遍知识
- 𝑋=𝑥1,𝑝1,…,𝑥𝑛,𝑝𝑛为伪标记实例,训练损失为:

- LSSL=λ1LPT−1+…+λmLPT−m, 其中λ, LPT−i分别为权值和损失函数
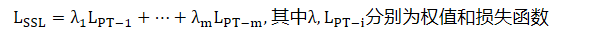
- LSSL=λ1LPT−1+…+λmLPT−m, 其中λ, LPT−i分别为权值和损失函数
- 使用SSL对大量未标记数据进行预训练有助于模型获得基本的常识或背景知识,而没有这些常识或背景知识,模型需要更多的标记实例才能获得良好的性能
- 与无监督学习的对比
- 需要监督
- 目的:无监督是识别隐藏模式,而SSL是学习有意义的表示
- 与监督学习的对比
- 标签是自动生成的
- 目的:监督学习是提供特定领域的知识,SSL是提供通用知识
- SSL的目的:
- 学习语言的通用表示,为下游任务提供背景知识
- 学习大量的免费提供的未标记文本数据,提高泛化能力
2.3 SSL的类型
- Generative SSL 生成式
- 通过解码编码的输入来学习
- 使用自回归(autogressive)、自编码(autoencoder)或混合(hybrid)语言模型
- 自回归语言模型根据前一个token预测下一个token
- GPT-1[1]是第一个基于自回归语言模型的PTLM。自动编码语言模型基于未屏蔽的token(双向上下文)预测被屏蔽的token。例如,MLM包括两个步骤。第一步是使用双向上下文对掩码token进行编码,第二步是基于编码的掩码token表示对原始token进行解码(预测)。像Bert[2]、Roberta[4]和Albert[7]这样的模型都是使用MLM进行预先训练的。
- 混合语言模型结合了自回归语言模型和自动编码语言模型的优点。例如,XLNet[3]中的置换语言建模(permutation language modelling,PLM)就是混合语言模型的一个例子。
- Contrastive SSL 对比式
- 模型在比较中学习。BERT中的NSP和Albert中的语序预测就是对比句法预测的两个例子。NSP涉及识别给定的句子对是否是连续句子,而SOP(sentence order prediction)涉及识别给定的句子对是否是互换的句子。
- Adversarial SSL 对抗式
- 模型通过识别输入句子中的标记是否被替换、打乱或随机替换来学习。ELECTRA[5]中的替换令牌检测(Replaced token detection,RTD)、混洗令牌检测(shuffled token detection,STD)[55]和随机令牌替换(random token substitution,RTS)[56]是对抗性SSL的示例。有关SSL和类型的详细信息,请参阅关于SSL的综述[49]。
3 T-TPLM核心概念
3.1 预训练
- 在大量未标记文本上进行预训练,然后在小的特定于任务的数据集上进行微调,已经成为现代自然语言处理中的一种标准方法。
- 优势:
- 利用大量未标记的文本学习通用语言表示
- 提供良好的初始化,避免了从头开始训练下游模型(特定于任务的层除外):只需添加一到两个特定的层,就可以使预先训练的模型适应下游任务。
- 在小数据集的情况下也可以帮助模型更好地执行,从而减少了对大量已标记实例的需求。
- 由于预训练提供了良好的初始化,它避免了对小数据集的过拟合,因此预训练可以被视为正则化的一种形式
3.1.1 预训练步骤(5个)
- 准备语料库
- 从一个或多个未标记文本源获得的,然后进行清理。
- BERT[2]模型在英文维基百科和图书语料库上进行了预训练。
- 进一步的研究[3],[4],[6]表明,在从多个来源获得的更大的文本语料库上对模型进行预训练进一步提高了模型的性能。
- 此外,Lee et al。[58]结果表明,训练前语料库中存在大量的冗余性,主要表现为 句子近似重复 和 长子串重复,该模型在去重语料库上进行预训练只需要较少的训练步骤就可以达到相似的性能。
- 生成词表
- 大多数基于转换器的预训练语言模型使用诸如WordPiess[59]、Byte Pair Encoding(BPE)[60]、Byte Level BPE(BBPE)[61]和SentencePiess[62]这样的标记器来生成词汇表。
- 通常,词汇由所有独特的字符和常用的子词和单词组成。通过在预训练语料库上应用任一标记器来生成词汇表。不同的T-PTLM使用不同的标记器,并生成不同大小的词汇表。
- 例如,Bert使用大小约为30K的WordPiess词汇表,Roberta使用大小约为50K的BBPE词汇表,XLM[63]使用大小为95K的BPE词汇表,mBERT[2]大小为110K的WordPiess词汇表,XLM-R[64],以及mBART[65]使用大小为250K的SentencePiess词汇表。
- XLM、XLM-R、mBERT和mBART等多语言模型中的大词汇量是有意义的,因为它们必须表示多语言。然而,预训练模型的大小随着词汇大小的增加而增加。
- 在基于字符的T-PTLM(如CharacterBERT[66])和无标记化的T-PTLM(如Canine[67]、ByT5[68]和Charformer[69])的情况下,该步骤是可选的。
- 设计预训练任务
- 在预训练过程中,模型基于一个或多个预训练任务,通过最小化损失来学习语言表示
- 预训练任务的要求
- 要具有足够的挑战性,使模型能够学习单词、短语、句子或文档级别的语义。例如,最近的研究工作[4]、[7]对NSP任务的效率提出了质疑,并导致了新的预训练任务来学习句子层面的语义,如句子顺序预测[7]和句子结构预测[70]
- 提供更多的训练信号,使模型在较少的预训练语料库的情况下学习更多的语言信息。例如,与MLM相比,RTD提供了更多的训练信号,因为RTD是在所有输入token上定义的,而MLM只在token的子集上定义[5]。
- 接近下游任务。例如,spanBERT[71]中的跨度边界预训练任务接近于跨度提取任务,PEGAUSUS[9]中的空位语句生成接近于摘要任务。最近的研究工作产生了更好的MLM版本,如交换语言建模[56],它避免了使用特殊的掩码标记,从而减少了预训练和微调之间的差异
- 选择预训练方法
- 仅使用SSL从头开始培训新模型的成本非常高,并且会消耗大量的预培训时间。
- 可以使用KIPT[72]、[73]等预训练方法,它们同时使用SSL和KD来预先训练模型,而不是仅使用SSL从零开始训练。
- 在将一般模型调整到特定领域的情况下,可以使用预训练方法,如使用新词汇的连续预训练[74]-[77]或适应和提取[78]。为了用有限的领域特定语料库预先训练特定领域的模型,可以使用同时利用通用语料库和领域内语料库的预训练[79]。
- 选择预训练动态(pretraining dynamics)
- BERT模型是在小批量静态masking的句子对上进行预训练的。[4]结果表明,精心设计的预训练选项,如动态掩蔽、大批量、更多的预训练步骤和长输入序列,进一步提高了模型的性能。此外,当使用可能导致优化困难的大批量时,建议a)在早期的预训练步骤中线性提高学习率(类似warm up策略),b)在不同的层使用不同的学习率,这也有助于加快收敛
3.1.2 预训练语料库
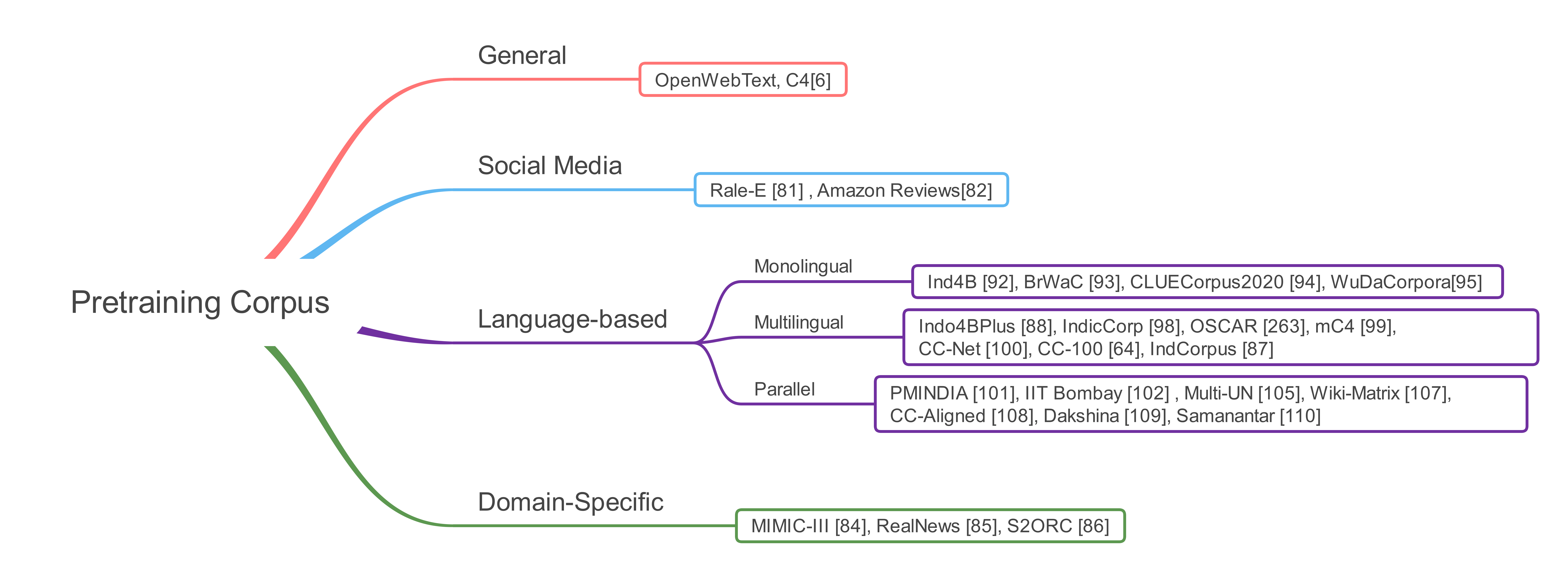
- 分为四类,不同类别有不同的特征
- general: 噪音更少,有专业人士撰写
- social media:噪音最多,一般公众口语化的文字
- domain special:许多特定的领域,如生物医学和金融,包含了许多在一般领域中没有使用的特定领域的词。一般说来,一般领域模型在领域特定任务中的性能是有限的[45]。因此,我们必须根据目标领域来选择预训练语料库,才能达到较好的效果。
- language based:单语、多语、平行
- BERT模型是使用维基百科和图书语料库中的文本进行预训练的,总容量为16 GB[2]。进一步的研究工作表明,使用较大的预训练数据集可以提高模型的性能[3]、[4]。这引发了更大数据集的开发,特别是从常见的爬虫。例如,C4数据包含大约750 GB的文本数据[6],而CC-100语料库包含大约2.5TB的文本数据[64]。多语言T-PTLM(如mBERT[2]、IndT5[87]、IndoBART[88]和XLMR[64])仅使用多语言数据集进行预训练。一些模型,如XLM[63]、XLM-E[89]、infoXLM[90]和MT6[91]都使用多语言和并行数据集进行了预先训练。表1和表2给出了各种预训练语料库的摘要。
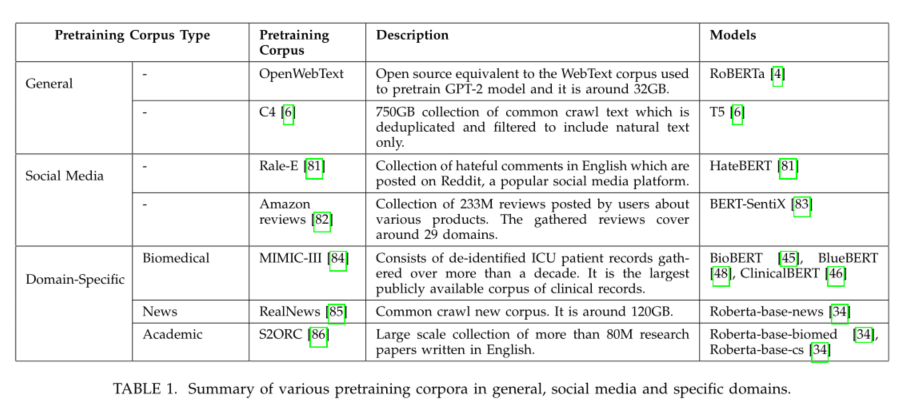
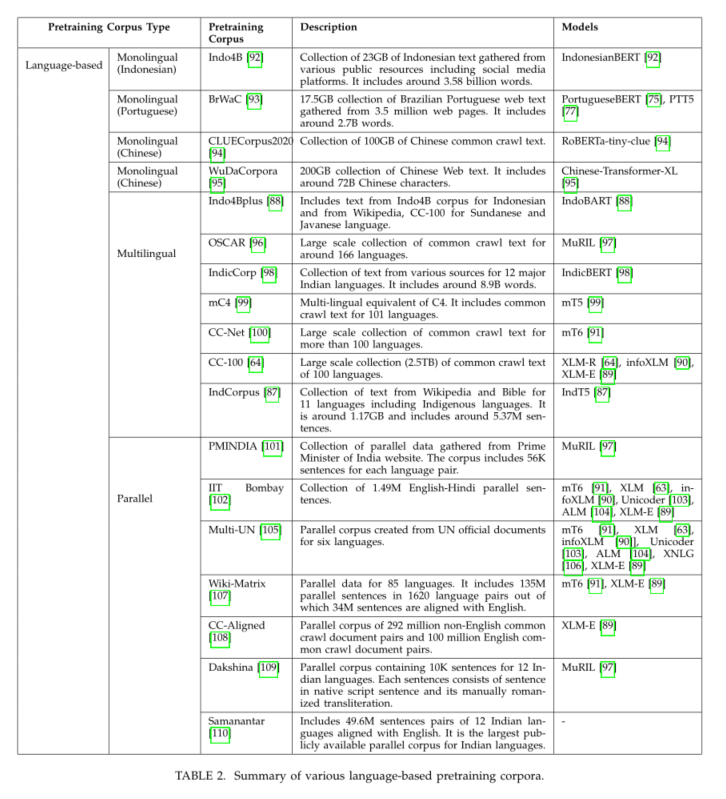
3.2 预训练方法的类型
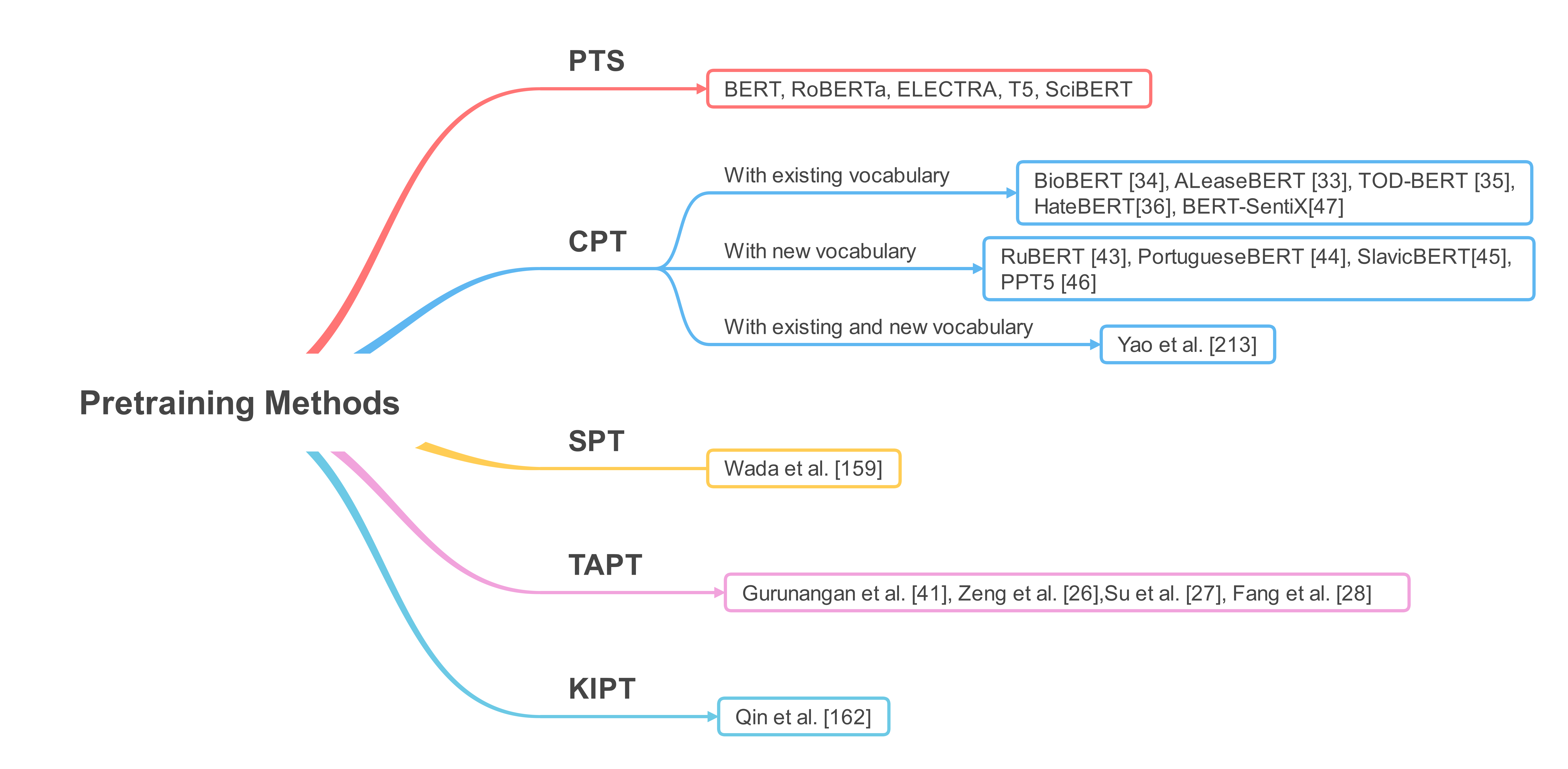
3.2.1 Pretraining from Scratch (PTS) 从头开始预训练
- Bert、Roberta、Electra和T5对大量未标记文本进行了从头开始的预训练
- 通常,任何基于Transformer的预训练语言模型都由嵌入层、转换器编码器或(与)转换器解码器层组成。所有这些层参数都是随机初始化的,然后在预训练期间通过最小化一个或多个预训练任务的损失来学习。例如,使用MLM和NSP从头开始训练BERT模型。从头开始的预训练计算成本很高,并且需要大量的GPU或TPU。
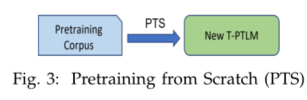
3.2.2 Continual Pretraining (CPT) 持续预训练
- 使用现有的语言模型参数来初始化参数,然后通过进一步的预训练使其适应目标领域(参见图4)。
- 举例:BioBERT[45]、AleaseBERT[32]、Tod-Bert[40]、HateBERT[81]、infoXLM[90]和XNLG[106]。例如,infoXLM是从XLM-R[64]中初始化的,并且在单语和并行数据上进行进一步的预训练;ALeaseBERT是从一般的Albert中初始化的,并且进一步在lease agreements上进行预训练;XLM[63]参数被用于在XNLG中对编码层和解码层进行初始化。
- CPT通常用于开发特定领域的T-PTLM,如社交媒体[81]、[111]、[112]、生物医学[45]、法律[32]、新闻[34]、计算机网络[41]等。
- CPT的主要优点是避免从头开始训练模型,并利用现有的语言模型参数。由于CPT从现有的模型参数出发,与PFS相比,它的代价更低,需要的训练时间和计算资源更少。
- 然而,当目标领域由许多领域特定的单词组成时,缺乏目标领域特定的词汇是CPT的一个缺点。
- 例如,BioBERT[45]是从一般的BERT初始化的,并且进一步在生物医学文本上进行预训练。虽然语言模型适用于生物医学领域,但在一般领域文本中学习的词汇并不包括许多特定于领域的单词。结果,特定领域的单词被分成多个子词,这阻碍了模型学习,并降低了其在下游任务中的性能。同样,mBERT支持100多种语言,其词汇表(110K)中特定于一种语言的标记数量较少。
- 一种可能的解决方案是使用目标领域或特定语言的词汇进行CPT[75]-[77]。在目标域或语言文本上生成新的词汇表。在连续的预训练过程中,嵌入层被随机初始化,所有其他层参数被现有的语言模型参数初始化。
- 例如,Rubert[74]、PortueseBERT[75]、SlavicBERT[76]等模型是从mBERT初始化的,但进一步使用特定于语言的词汇进行预训练。同样,PPT5[77]是从T5模型初始化的,但进一步用语言特定的词汇进行预训练。然而,通过不断地对新词汇进行预训练得到的模型的性能略逊于从零开始训练的模型的性能,但与PTS模型的性能相当。由于CPT的计算成本较低,在资源受限的情况下,使用新词汇的CPT可能比PTS更可取。
- 最近,[78]提出了一种通过词汇量扩展和知识提炼使通用模型适应特定领域的改编和抽取方法。与现有的自适应方法不同的是,自适应和抽取方法不仅使一般模型适应特定领域,而且减小了模型的规模。
- 对于CPT,不需要使用现有模型所使用的同一组预训练任务。例如,Bert-Sentix[83]模型是从Bert初始化的,并使用四个情感感知预训练任务进一步预训练产品评论。类似地,TOD-BERT[40]是从BERT初始化的,并使用MLM和反应对比损失(response contrastive loss, RCL)进一步在对话语料库文本上进行预训练。
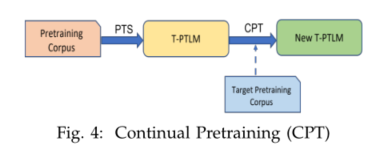
3.2.3 Simultaneous Pretraining (SPT) 同步预训练
- 领域特定的T-PTLM可以通过PTS从头开始训练或通过CPT持续的预训练来开发。这两种预训练方法都需要大量领域特定的未标记文本来预训练模型。然而,特定于领域的文本在许多领域中的可用性是有限的。此外,除英语以外的其他语言的特定领域文本仅有少量可用。例如,在生物医学领域,MIMIC-III[84]是最大的公开可用的(英文)医疗记录集。然而,很难获得如此大量的日语病历[79]。使用少量领域特定文本的PTS或CPT不适合该模型。同步预训练(SPT)允许模型使用同时具有一般文本和领域特定文本的语料库从头开始进行预训练[79](参见图5)。在这里,对特定于领域的文本进行上采样,以确保模型词汇中有大量的特定于领域的术语,并进行均衡的预训练。[79]结果表明,使用SPT进行预训练的日语临床BERT优于从头开始训练的日语临床BERT。
3.2.4 Task Adaptive Pretraining (TAPT) 任务自适应预训练
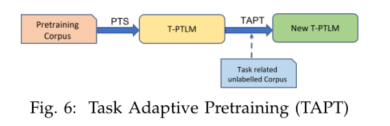
- PTS、CPT和SPT等预训练方法允许模型通过对大量一般或领域特定或组合文本的训练来学习通用或领域特定的语言表示。由于所有这些方法都需要对大量文本进行训练,因此这些方法代价高昂。
- 任务自适应预训练(TAPT)允许模型通过对少量任务特定的无标签文本[34]进行预训练,学习细粒度的任务特定知识以及领域特定知识[34](参见图6)。由于TAPT只需要少量的文本,与其他预培训方法相比,它的成本较低。其他与任务相关的句子可以使用轻量级方法从大型领域语料库中获得,比如 VAMPIR
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1260
1260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









