









一、极大似然估计
1、明确极大似然函数的目的
- 随机变量的概率分布往往由少量的参数定义(也叫做有效统计量)
- 只要计算出这些参数我们就确定了这个分布的情况
- 极大似然估计就是用来估计这个参数的
例如:
二项分布:
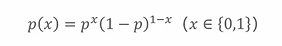
P(x)仅由由一个参数p决定,极大似然估计就要估计p
正态分布:
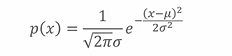
正态分布由均值μ和方差
σ
2
σ^2
σ2决定,极大似然估计就要估计μ和
σ
2
σ^2
σ2
2、通俗体现极大似然估计思想的例子
案例一:
一位同学和一位猎人一起外出打猎,一只野兔从前方窜过。 只听一声枪响,野兔应声到下,如果要你推测,这一发命中的子弹是谁打的?
你就会想,只发一枪便打中,由于猎人命中的概率一般大于你那位同学命中的概率,从而推断出这一枪应该是猎人射中的。这个例子所作的推断就体现了最大似然法的基本思想。
即我们认为:
- 概率大的事件发生的可能性就更大
- 希望找出一个参数θ使得 x x x最像是从这样的数据分布 p ( x ∣ θ ) p(x|θ) p(x∣θ)抽取的
案例二:
比如掷硬币的例子:
一般的,常说的概率是指给定参数后,预测即将发生的事件的可能性。
问题一:
我们已知一枚均匀硬币的正反面概率分别是0.5(正反概率为0.5即我们所说的给定的参数),要求预测抛两次硬币,两次硬币都朝上的概率:
解:
H代表Head,表示头朝上
则两次都朝上的概率: p(HH | pH = 0.5) = 0.5*0.5 = 0.25.
Notice:
p(HH | pH = 0.5)这种写法其实有点小误导,后面的这个pH其实是作为参数存在的,而不是一个随机变量,因此不能算作是条件概率,更靠谱的写法应该是 p(HH;pH=0.5)。个人觉得这应该是频率主义学派和贝叶斯学派两者争议的点吧,两种写法都可以
而似然概率正好与这个过程相反,我们关注的量不再是事件的发生概率,而是已知发生了某些事件,我们希望知道参数应该是多少。
问题二:
现在我们已经抛了两次硬币,并且知道了结果是两次头朝上,这时候,我希望知道这枚硬币抛出去正面朝上的概率为0.5的概率(似然)是多少?正面朝上的概率为0.8的概率(似然)是多少?
如果我们希望知道正面朝上概率为某某的概率,这个东西就叫做似然函数,硬币抛出去正面朝上的概率为0.5的概率(似然) 可以说成是对参数(pH=0.5)的似然概率,这样表示成(条件)概率就是
L ( p H = 0.5 ∣ H H ) = P ( H H ∣ p H = 0.5 ) = ( 另 一 种 写 法 ) P ( H H ; p H = 0.5 ) L(pH=0.5|HH) = P(HH|pH=0.5) =(另一种写法)P(HH;pH=0.5) L(pH=0.5∣HH)=P(HH∣pH=0.5)=(另一种写法)P(HH;pH=0.5).
为什么可以写成这样?
我觉得可以这样来想:
似然函数本身也是一种概率,我们可以把
L
(
p
H
=
0.5
∣
H
H
)
L(pH=0.5|HH)
L(pH=0.5∣HH)写成P(pH=0.5|HH);
而根据贝叶斯公式,
P
(
p
H
=
0.5
∣
H
H
)
=
P
(
p
H
=
0.5
,
H
H
)
/
P
(
H
H
)
P(pH=0.5|HH) =P(pH=0.5,HH)/P(HH)
P(pH=0.5∣HH)=P(pH=0.5,HH)/P(HH);
既然HH是已经发生的事件,理所当然P(HH) = 1,
所以:
P
(
p
H
=
0.5
∣
H
H
)
=
P
(
p
H
=
0.5
,
H
H
)
=
P
(
H
H
;
p
H
=
0.5
)
P(pH=0.5|HH) =P(pH=0.5,HH) = P(HH;pH=0.5)
P(pH=0.5∣HH)=P(pH=0.5,HH)=P(HH;pH=0.5).
右边的这个计算我们很熟悉了,就是已知头朝上概率为0.5,
求抛两次都是H的概率,即0.5*0.5=0.25。
所以,我们可以safely得到:
L
(
p
H
=
0.5
∣
H
H
)
=
P
(
H
H
∣
p
H
=
0.5
)
=
0.25
L(pH=0.5|HH) = P(HH|pH=0.5) = 0.25
L(pH=0.5∣HH)=P(HH∣pH=0.5)=0.25.
这个0.25的意思是,在已知抛出两个正面的情况下,pH = 0.5的概率(似然)等于0.25。
再算一下
L
(
p
H
=
0.6
∣
H
H
)
=
P
(
H
H
∣
p
H
=
0.6
)
=
0.36
L(pH=0.6|HH) = P(HH|pH=0.6) = 0.36
L(pH=0.6∣HH)=P(HH∣pH=0.6)=0.36.
把pH从0~1的取值所得到的似然函数的曲线画出来得到这样一张图:

可以发现, p H = 1 pH = 1 pH=1的概率是最大的(最大似然)。
即在参数pH等于1时达到最大似然: L ( p H = 1 ∣ H H ) = 1 L(pH = 1|HH) = 1 L(pH=1∣HH)=1。
也就是在观测到HH的情况下, p H = 1 pH = 1 pH=1是最合理的
(虽未必符合真实情况,这是因为数据量太少的缘故,随着数据量的增加会越来越接近真实值pH=0.5)。
小结:
- 最大似然概率,就是在已知观测的数据的前提下,找到使得似然概率最大的参数值。
- 在data mining领域,许多求参数的方法最终都归结为最大化似然概率的问题。
二、由问题引入EM算法
1、掷硬币问题:
假设现在有两枚硬币A和B,随机抛掷后正面朝上的概率分别为p1,p2。为了估计这两个概率,做实验,每次取一枚硬币,连掷5下,记录下结果,如下:
| 硬币编号 | 结果 | 统计 |
|---|---|---|
| 1 | 正正反正反 | 3正-2反 |
| 2 | 反反正正反 | 2正-3反 |
| 1 | 正反反反反 | 1正-4反 |
| 2 | 正反反正正 | 3正-2反 |
| 1 | 反正正反反 | 2正-3反 |
在上述情况下,p1,p2的计算非常简单
- p1 = (3+1+2) /15 = 0.4
- p2 = (2+3)/10 = 0.5
2、掷硬币问题-升级版:
假设现在不知道每次实验的硬币编号怎么办?如何求解P1和P2?
| 硬币编号 | 结果 | 统计 |
|---|---|---|
| Unknown | 正正反正反 | 3正-2反 |
| Unknown | 反反正正反 | 2正-3反 |
| Unknown | 正反反反反 | 1正-4反 |
| Unknown | 正反反正正 | 3正-2反 |
| Unknown | 反正正反反 | 2正-3反 |
- 由于硬币编号未知,其本身也成为了一个随机变量,成为隐变量(即无法观测到的随机变量),通常在EM算法中记作Z
- 那么在这里Z也有了5个样本z1,z2, z3, z4, z5,其中 z i z_i zi∈{硬币1,硬币2}
- 如果Z未知,那么P1和P2就无法估计,因此得先估计出Z
- 但是要想估计出Z,我们得先知道P1和P2,然后才能使用极大似然估计去计
算Z - 鸡生蛋,蛋生鸡?怎么破?
解决思路:
1、一不做二不休,先对P1和P2随机赋值,用来估计一个Z值
2、然后再用估计出来的值去估计新的P1和P2
3、如果新的P1和P2和旧的P1、P2差距不大,那么说明旧的P1和P2是相对靠谱的
4、如果差距较大,那么进行新一轮的估计,直到收敛
按照上述思路进行求解:
- 假设P1=0.2, P2=0.7
- 现在计算一- 下第- -轮的掷硬币(3正2反)最有可能是哪个硬币的结果
- 硬币1出现3正2反的概率: 0.2 * 0.2 * 0.2 * 0.8 * 0.8 = 0.005
- 硬币2出现3正2反的概率: 0.7 * 0.7 * 0.7 * 0.3 * 0.3 = 0.031
- 那么我们就说第一-轮掷硬币最有 可能的是硬币2的结果
- 以此计算出剩余4轮
- 硬币1,硬币1,硬币2,硬币1
得到下表:
| 硬币编号(估计值) | 结果 | 统计 |
|---|---|---|
| 2 | 正正反正反 | 3正-2反 |
| 1 | 反反正正反 | 2正-3反 |
| 1 | 正反反反反 | 1正-4反 |
| 2 | 正反反正正 | 3正-2反 |
| 1 | 反正正反反 | 2正-3反 |
根据Z的估计,我们计算出了新的P1和P2
- P1=(2+1+2) /15 = 0.33
- P2= (3+3) / 10= 0.6
| 初始化的p1 | 估计出的p1 | 真实的p1 | 初始化的p2 | 估计出的p2 | 真实的p2 |
|---|---|---|---|---|---|
| 0.2 | 0.33 | 0.4 | 0.7 | 0.6 | 0.5 |
随着迭代次数的增加,估计值会越来越接近真实值
细心的同学可能会有一些疑问:
- (1)上述做法只使用了一个最可能的z值,而不是所有可能的z值
- (2)新估计出的P1和P2-定会接近真实值吗?
- (3) 一定会收敛到真实的P1和P2吗? (不一定,收敛的结果依赖于初始估计值)
3、掷硬币问题-升级版2:
- 考虑所有可能的z值,对每一个z值都估计出一 个新的P1和P2,将每一个z值概率大小作为权重,将所有新的P1和P2分别加权相加
绘制如下表格:
| 轮数 | 硬币1出现统计结果的概率 | 硬币2出现统计结果的概率 |
|---|---|---|
| 1 | 0.005 | 0.031 |
| 2 | 0.02 | 0.013 |
| 3 | 0.082 | 0.006 |
| 4 | 0.005 | 0.031 |
| 5 | 0.02 | 0.013 |
- 在第一轮中,使用硬币1的概率为: 0.005/(0.005+0.031)=0.14,硬币2的概率为0.86
根据上述思路我们把所有的5轮实验进行汇总的到如下表格:
| 轮数 | z i z_i zi=硬币1 | z i z_i zi=硬币2 |
|---|---|---|
| 1 | 0.14 | 0.86 |
| 2 | 0.61 | 0.39 |
| 3 | 0.94 | 0.06 |
| 4 | 0.14 | 0.86 |
| 5 | 0.61 | 0.39 |
在上一张表中,我们估计出了Z的概率分(EM算法中称之为E步)
我们根据Z的概率分布来估计新的P1和P2 (使用分布的好处就是能够顾及到所有值,而不是依靠单点值,从而可以更快的收敛)
- 以第一轮为例,第一轮(3正2反)是硬币1的概率为0.14,那么可以认为第一轮用硬币1投出了0.143=0.42个正面和0.142个反面,同理得到5轮的结果如下:
| 轮数 | 硬币1投出的正面数量 | 硬币2投出的正面数量 |
|---|---|---|
| 1 | 0.42 | 0.28 |
| 2 | 1.22 | 1.83 |
| 3 | 0.94 | 3.76 |
| 4 | 0.42 | 0.28 |
| 5 | 1.22 | 1.83 |
- 根据上表,硬币1投出的正面的总数为: 0.42+ 1.22+0.94+0.42+ 1.22=4.22
- 硬币1投出的反面的总数为7.98
那么硬币1正面朝_上的概率P1=4.22/ (4.22+7.98) =0.35
| 初始值p1 | 单点估计值 | 概率分布估计值p1 | 真实p1 |
|---|---|---|---|
| 0.2 | 0.33 | 0.35 | 0.4 |
可以看到通概率分布估计值更加接近真实值,也起到了加速迭代的过程
小结:
EM算法的前提条件:
- P1和P2对应着我们所遇到的问题中需要求解的值
- Z对应着数据中未知的量(隐变量)
- 需要求解的值和未知量存在着依赖关系
解决思路:
- 假定目标初始值
- 用初始值求解隐变量的概率分布,
- 根据隐变量的概率分布,进一步调整目标值
- 重复上述过程进行循环迭代,最终逼近真实值
三、EM算法的数学化定义
基本流程:
- X表示已经观测到的集合,Z表示隐变量, θ \theta θ表示需要求解的参数
- 使用极大似然估计,得到对数似然函数 L ( θ ∣ X , Z ) L(θ|X, Z) L(θ∣X,Z)
- 发现上式存在隐变量Z,无法直接求解
于是:
- 使用迭代式的方法
- 基本思想:若参数θ已知,则可以推断出最优的z;
而z已知,则可以使用极大似然方法估计θ值 - 记 θ 0 θ^0 θ0为初始值,第t次迭代的参数记为 θ t θ^t θt
- E步:根据初始化θ或者中间迭代的θ值来推测z
- M步:根据E步得到的Z值反过来估计θ的值
- 不断重复EM步,直到参数收敛
两种EM算法
1、通过计算z的期望值
- 基于 θ t θ^t θt推断隐变量Z的期望(单点值),记为 z t z^t zt
- 基于已观测变量x和 z t z^t zt对 θ \theta θ作极大似然估计,记为 θ t + 1 θ^{t+1} θt+1
- 直到
2、通过计算z的分布
- 基于
θ
t
θ^t
θt推断隐变量Z的分布,记为
P
(
Z
∣
X
,
θ
t
)
P(Z|X, θ^t)
P(Z∣X,θt),并计算对数似然函数
L
(
θ
∣
X
,
Z
)
L(θ|X, Z)
L(θ∣X,Z)
关于z的期望,记为 Q ( θ ∣ θ t ) Q(θ|θ^{t}) Q(θ∣θt) - 计算使得 Q ( θ ∣ θ t ) Q(θ|θ^t) Q(θ∣θt)达到最大的θ,记为 θ t + 1 θ^{t+1} θt+1
三、EM与K-Means的关系
1、高斯混合聚类(Gaussian Mixed Cluster)-多元高斯分布
n维空间的中的随机向量x服从多元高斯分布,那么概率密度函数为:
p
(
x
∣
μ
,
Σ
)
=
1
(
2
π
)
1
2
∣
Σ
∣
1
2
e
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
2
p(x|\boldsymbol{\mu,Σ}) = \frac{1}{(2\pi)^\frac{1}{2}|\boldsymbolΣ|^\frac{1}{2}}e^{\frac{(x-\mu)^TΣ^{-1}(x-\mu)}{2}}
p(x∣μ,Σ)=(2π)21∣Σ∣211e2(x−μ)TΣ−1(x−μ)
μ
为
均
值
向
量
,
Σ
为
协
方
差
矩
阵
\mu为均值向量,\Sigma为协方差矩阵
μ为均值向量,Σ为协方差矩阵
一元高斯分布的多元是一致的,无非是均值和方差变成了均值向量和协方差矩阵
2、高斯混合聚类(Gaussian Mixed Cluster)-高斯混合模型
- 假设数据可分为k个簇,且每个簇都满足高斯分布
- 混合系数 a i a_i ai>0,且 Σ i = 1 k a i \Sigma_{i=1}^ka_i Σi=1kai= 1
- a i a_i ai表示样本属于第 i i i个高斯模型的概率
- 定义高斯混合分布:
p M ( x ) = ∑ i = 1 k a i p ( x ∣ μ i , Σ i ) p_M(x)= \sum_{i=1}^{k}a_ip(x|\boldsymbol{\mu_i,\Sigma_i}) pM(x)=i=1∑kaip(x∣μi,Σi)
3、高斯混合聚类(Gaussian Mixed Cluster)
-
现在有训练集D = { x , x 2 , … , x m x,x_2,…,x_m x,x2,…,xm},且由高斯混合模型生成
-
记 z j z_j zj∈{1,2, k}表示 x j x_j xj属 于高斯混合模型中的某个高斯模型
-
根据贝叶斯公式:
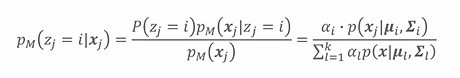
-
P M ( z j = i ∣ x j ) P_M(z_j = i|x_j) PM(zj=i∣xj)表示了样本 x j x_j xj由第i个高斯模型生成的概率,记为 γ j i \gamma_{ji} γji
-
若 p M ( x ) p_M(x) pM(x)已知,那么对于一个样本 x j x_j xj, 计算 γ j i \gamma_{ji} γji, 找到其中最大的 γ \gamma γ,记为 γ j k \gamma_{jk} γjk,
那么就把 x j x_j xj归为第k个高斯簇 -
如何从训练集D = { x 1 x_1 x1, x 2 x_2 x2…, x m x_m xm}中求解 p M ( x ) p_M(x) pM(x)(这意味着要求出 { a i , μ , Σ i } i = 1 k \{a_i,\mu,\Sigma_i\}_{i=1}^{k} {ai,μ,Σi}i=1k,共3k个参数)
4、使用EM算法求解高斯混合聚类问题-极大似然估计
- 已知训练集满足高斯混合模型,计算对数似然函数:
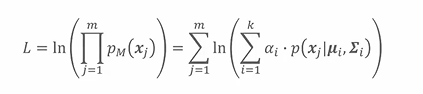
(1)、使用EM算法求解高斯混合聚类问题-求解μ;

(2)、使用EM算法求解高斯混合聚类问题-求解 Σ i \Sigma_i Σi
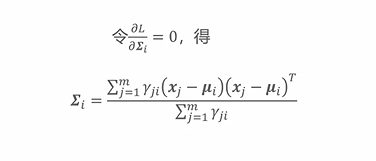
(3)、使用EM算法求解高斯混合聚类问题-求解 α i \alpha_i αi

上面的
λ
\lambda
λ是如何求得呢?下面给出得推导:
(4)、使用EM算法求解高斯混合聚类问题-求解 a i a_i ai-求解λ


如和使用EM算法求解高斯混合聚类问题?

5、K-Means与GMC的关系

K-Means和高斯混合分布的区别就是局部和整体的区别,当某些
γ
j
i
\gamma_{ji}
γji都等于零的时候,两者就相等了。
四、算法的代码实现
混合高斯分布模型
EM算法更多是一种思想,用概率来解决问题的一种方法,具体的代码看自己选用模型,所以并没有通用的模型,本此代码主要是讲解混合高斯分布模型的
这其中的M步 完全按照了 公式来计算。
import numpy as np
import random
import math
import time
'''
数据集:伪造数据集(两个高斯分布混合)
数据集长度:1000
------------------------------
运行结果:
----------------------------
the Parameters set is:
alpha0:0.3, mu0:0.7, sigmod0:-2.0, alpha1:0.5, mu1:0.5, sigmod1:1.0
----------------------------
the Parameters predict is:
alpha0:0.4, mu0:0.6, sigmod0:-1.7, alpha1:0.7, mu1:0.7, sigmod1:0.9
----------------------------
'''
def loadData(mu0, sigma0, mu1, sigma1, alpha0, alpha1):
'''
初始化数据集
这里通过服从高斯分布的随机函数来伪造数据集
:param mu0: 高斯0的均值
:param sigma0: 高斯0的方差
:param mu1: 高斯1的均值
:param sigma1: 高斯1的方差
:param alpha0: 高斯0的系数
:param alpha1: 高斯1的系数
:return: 混合了两个高斯分布的数据
'''
# 定义数据集长度为1000
length = 1000
# 初始化第一个高斯分布,生成数据,数据长度为length * alpha系数,以此来
# 满足alpha的作用
data0 = np.random.normal(mu0, sigma0, int(length * alpha0))
# 第二个高斯分布的数据
data1 = np.random.normal(mu1, sigma1, int(length * alpha1))
# 初始化总数据集
# 两个高斯分布的数据混合后会放在该数据集中返回
dataSet = []
# 将第一个数据集的内容添加进去
dataSet.extend(data0)
# 添加第二个数据集的数据
dataSet.extend(data1)
# 对总的数据集进行打乱(其实不打乱也没事,只不过打乱一下直观上让人感觉已经混合了
# 读者可以将下面这句话屏蔽以后看看效果是否有差别)
random.shuffle(dataSet)
#返回伪造好的数据集
return dataSet
# 高斯分布公式,没有什么特殊的
def calcGauss(dataSetArr, mu, sigmod):
'''
根据高斯密度函数计算值
依据:“9.3.1 高斯混合模型” 式9.25
注:在公式中y是一个实数,但是在EM算法中(见算法9.2的E步),需要对每个j
都求一次yjk,在本实例中有1000个可观测数据,因此需要计算1000次。考虑到
在E步时进行1000次高斯计算,程序上比较不简洁,因此这里的y是向量,在numpy
的exp中如果exp内部值为向量,则对向量中每个值进行exp,输出仍是向量的形式。
所以使用向量的形式1次计算即可将所有计算结果得出,程序上较为简洁
:param dataSetArr: 可观测数据集
:param mu: 均值
:param sigmod: 方差
:return: 整个可观测数据集的高斯分布密度(向量形式)
'''
# 计算过程就是依据式9.25写的,没有别的花样
result = (1 / (math.sqrt(2*math.pi)*sigmod**2)) * np.exp(-1 * (dataSetArr-mu) * (dataSetArr-mu) / (2*sigmod**2))
# 返回结果
return result
def E_step(dataSetArr, alpha0, mu0, sigmod0, alpha1, mu1, sigmod1):
'''
EM算法中的E步
依据当前模型参数,计算分模型k对观数据y的响应度
:param dataSetArr: 可观测数据y
:param alpha0: 高斯模型0的系数
:param mu0: 高斯模型0的均值
:param sigmod0: 高斯模型0的方差
:param alpha1: 高斯模型1的系数
:param mu1: 高斯模型1的均值
:param sigmod1: 高斯模型1的方差
:return: 两个模型各自的响应度
'''
# 计算y0的响应度
# 先计算模型0的响应度的分子
gamma0 = alpha0 * calcGauss(dataSetArr, mu0, sigmod0)
#print("gamma0=",gamma0.shape) # 1000, 维向量
# 模型1响应度的分子
gamma1 = alpha1 * calcGauss(dataSetArr, mu1, sigmod1)
# 两者相加为E步中的分布
sum = gamma0 + gamma1
# 各自相除,得到两个模型的响应度
gamma0 = gamma0 / sum
gamma1 = gamma1 / sum
# 返回两个模型响应度
return gamma0, gamma1
def M_step(muo, mu1, gamma0, gamma1, dataSetArr):
# 依据算法9.2计算各个值
# 这里没什么花样,对照书本公式看看这里就好了
# np.dot 点积:[1,2] [2,3] = [2,6]
mu0_new = np.dot(gamma0, dataSetArr) / np.sum(gamma0)
mu1_new = np.dot(gamma1, dataSetArr) / np.sum(gamma1)
# math.sqrt 平方根
sigmod0_new = math.sqrt(np.dot(gamma0, (dataSetArr - muo)**2) / np.sum(gamma0))
sigmod1_new = math.sqrt(np.dot(gamma1, (dataSetArr - mu1)**2) / np.sum(gamma1))
alpha0_new = np.sum(gamma0) / len(gamma0)
alpha1_new = np.sum(gamma1) / len(gamma1)
# 将更新的值返回
return mu0_new, mu1_new, sigmod0_new, sigmod1_new, alpha0_new, alpha1_new
## 训练主函数
def EM_Train(dataSetList, iter=500):
'''
根据EM算法进行参数估计
算法依据“9.3.2 高斯混合模型参数估计的EM算法” 算法9.2
:param dataSetList:数据集(可观测数据)
:param iter: 迭代次数
:return: 估计的参数
'''
# 将可观测数据y转换为数组形式,主要是为了方便后续运算
dataSetArr = np.array(dataSetList)
# 步骤1:对参数取初值,开始迭代
alpha0 = 0.5
mu0 = 0
sigmod0 = 1
alpha1 = 0.5
mu1 = 1
sigmod1 = 1
# 开始迭代
step = 0
while (step < iter):
# 每次进入一次迭代后迭代次数加1
step += 1
# 步骤2:E步:依据当前模型参数,计算分模型k对观测数据y的响应度
gamma0, gamma1 = E_step(dataSetArr, alpha0, mu0, sigmod0, alpha1, mu1, sigmod1)
# 步骤3:M步
mu0, mu1, sigmod0, sigmod1, alpha0, alpha1 = M_step(mu0, mu1, gamma0, gamma1, dataSetArr)
# 迭代结束后将更新后的各参数返回
return alpha0, mu0, sigmod0, alpha1, mu1, sigmod1
if __name__ == '__main__':
start = time.time()
# 设置两个高斯模型进行混合,这里是初始化两个模型各自的参数
# 见“9.3 EM算法在高斯混合模型学习中的应用”
# alpha是“9.3.1 高斯混合模型” 定义9.2中的系数α
# mu0是均值μ
# sigmod是方差σ
# 在设置上两个alpha的和必须为1,其他没有什么具体要求,符合高斯定义就可以
alpha0 = 0.3 # 系数α
mu0 = -2 # 均值μ
sigmod0 = 0.5 # 方差σ
alpha1 = 0.7 # 系数α
mu1 = 0.5 # 均值μ
sigmod1 = 1 # 方差σ
# 初始化数据集
dataSetList = loadData(mu0, sigmod0, mu1, sigmod1, alpha0, alpha1)
#打印设置的参数
print('---------------------------')
print('the Parameters set is:')
print('alpha0:%.1f, mu0:%.1f, sigmod0:%.1f, alpha1:%.1f, mu1:%.1f, sigmod1:%.1f' % (
alpha0, alpha1, mu0, mu1, sigmod0, sigmod1
))
# 开始EM算法,进行参数估计
alpha0, mu0, sigmod0, alpha1, mu1, sigmod1 = EM_Train(dataSetList)
# 打印参数预测结果
print('----------------------------')
print('the Parameters predict is:')
print('alpha0:%.1f, mu0:%.1f, sigmod0:%.1f, alpha1:%.1f, mu1:%.1f, sigmod1:%.1f' % (
alpha0, alpha1, mu0, mu1, sigmod0, sigmod1
))
# 打印时间
print('----------------------------')
print('time span:', time.time() - start)E步主要计算内容
其中我们定义
γ
j
k
^
\hat{\gamma_{jk}}
γjk^:
γ
j
k
^
=
E
(
γ
j
k
∣
y
,
θ
)
=
a
k
ϕ
(
y
i
∣
θ
k
)
∑
k
=
1
K
a
k
ϕ
(
y
i
∣
θ
k
)
j
=
1
,
2
,
.
.
,
N
;
k
=
1
,
2
,
.
.
.
,
K
n
k
=
∑
j
=
i
N
E
γ
j
k
\hat{\gamma_{jk}} = E(\gamma_{jk}|y,\theta)=\frac{a_k\phi(y_i|\theta_{k})}{\sum_{k=1}^{K}a_k\phi(y_i|\theta_{k}) }\\ j=1,2,..,N;k=1,2,...,K\\ n_k=\sum_{j=i}^{N}E\gamma_{jk}
γjk^=E(γjk∣y,θ)=∑k=1Kakϕ(yi∣θk)akϕ(yi∣θk)j=1,2,..,N;k=1,2,...,Knk=j=i∑NEγjk
M步 主要计算内容
这一步骤主要是对Q函数求导后的数据进行计算,利用了 E 步 的 γ j k ^ \hat{\gamma_{jk}} γjk^
import math
import copy
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
#生成随机数据,4个高斯模型
def generate_data(sigma,N,mu1,mu2,mu3,mu4,alpha):
global X #可观测数据集
X = np.zeros((N, 2)) # 初始化X,2行N列。2维数据,N个样本
X=np.matrix(X)
global mu #随机初始化mu1,mu2,mu3,mu4
mu = np.random.random((4,2))
mu=np.matrix(mu)
global excep #期望第i个样本属于第j个模型的概率的期望
excep=np.zeros((N,4))
global alpha_ #初始化混合项系数
alpha_=[0.25,0.25,0.25,0.25]
for i in range(N):
if np.random.random(1) < 0.1: # 生成0-1之间随机数
X[i,:] = np.random.multivariate_normal(mu1, sigma, 1) #用第一个高斯模型生成2维数据
elif 0.1 <= np.random.random(1) < 0.3:
X[i,:] = np.random.multivariate_normal(mu2, sigma, 1) #用第二个高斯模型生成2维数据
elif 0.3 <= np.random.random(1) < 0.6:
X[i,:] = np.random.multivariate_normal(mu3, sigma, 1) #用第三个高斯模型生成2维数据
else:
X[i,:] = np.random.multivariate_normal(mu4, sigma, 1) #用第四个高斯模型生成2维数据
print("可观测数据:\n",X) #输出可观测样本
print("初始化的mu1,mu2,mu3,mu4:",mu) #输出初始化的mu
# E 期望
# \hat{\gamma_{jk}}
def e_step(sigma,k,N):
global X
global mu
global excep
global alpha_
for i in range(N):
denom=0
for j in range(0,k):
# sigma.I 表示矩阵的逆矩阵
# np.transpose :矩阵转置 np.linalg.det():矩阵求行列式
denom += alpha_[j]* math.exp(-(X[i,:]-mu[j,:])*sigma.I*np.transpose(X[i,:]-mu[j,:])) /np.sqrt(np.linalg.det(sigma)) #分母
for j in range(0,k):
numer = math.exp(-(X[i,:]-mu[j,:])*sigma.I*np.transpose(X[i,:]-mu[j,:]))/np.sqrt(np.linalg.det(sigma)) #分子
excep[i,j]=alpha_[j]*numer/denom #求期望
print("隐藏变量:\n",excep)
def m_step(k,N):
global excep
global X
global alpha_
for j in range(0,k):
denom=0 #分母
numer=0 #分子
for i in range(N):
numer += excep[i,j]*X[i,:]
denom += excep[i,j]
mu[j,:] = numer/denom #求均值
alpha_[j]=denom/N #求混合项系数
# #可视化结果
def plotShow():
# 画生成的原始数据
plt.subplot(221)
plt.scatter(X[:,0].tolist(), X[:,1].tolist(),c='b',s=25,alpha=0.4,marker='o') #T散点颜色,s散点大小,alpha透明度,marker散点形状
plt.title('random generated data')
#画分类好的数据
plt.subplot(222)
plt.title('classified data through EM')
order=np.zeros(N)
color=['b','r','k','y']
for i in range(N):
for j in range(k):
if excep[i,j]==max(excep[i,:]):
order[i]=j #选出X[i,:]属于第几个高斯模型
probility[i] += alpha_[int(order[i])]*math.exp(-(X[i,:]-mu[j,:])*sigma.I*np.transpose(X[i,:]-mu[j,:]))/(np.sqrt(np.linalg.det(sigma))*2*np.pi) #计算混合高斯分布
plt.scatter(X[i, 0], X[i, 1], c=color[int(order[i])], s=25, alpha=0.4, marker='o') #绘制分类后的散点图
#绘制三维图像
ax = plt.subplot(223, projection='3d')
plt.title('3d view')
for i in range(N):
ax.scatter(X[i, 0], X[i, 1], probility[i], c=color[int(order[i])])
plt.show()
if __name__ == '__main__':
iter_num=1000 #迭代次数
N=500 #样本数目
k=4 #高斯模型数
probility = np.zeros(N) #混合高斯分布
u1=[5,35]
u2=[30,40]
u3=[20,20]
u4=[45,15]
sigma=np.matrix([[30, 0], [0, 30]]) #协方差矩阵
alpha=[0.1,0.2,0.3,0.4] #混合项系数
generate_data(sigma,N,u1,u2,u3,u4,alpha) #生成数据
#迭代计算
for i in range(iter_num):
err=0 #均值误差
err_alpha=0 #混合项系数误差
Old_mu = copy.deepcopy(mu)
Old_alpha = copy.deepcopy(alpha_)
e_step(sigma,k,N) # E步
m_step(k,N) # M步
print("迭代次数:",i+1)
print("估计的均值:",mu)
print("估计的混合项系数:",alpha_)
for z in range(k):
err += (abs(Old_mu[z,0]-mu[z,0])+abs(Old_mu[z,1]-mu[z,1])) #计算误差
err_alpha += abs(Old_alpha[z]-alpha_[z])
if (err<=0.001) and (err_alpha<0.001): #达到精度退出迭代
print(err,err_alpha)
break
# 画图
plotShow()
参考:
- https://www.cnblogs.com/zhsuiy/p/4822020.html
- https://www.bilibili.com/video/BV1Zt411L7tg?p=4
- http://www.dgt-factory.com/uploads/2018/07/0725/%E7%BB%9F%E8%AE%A1%E5%AD%A6%E4%B9%A0%E6%96%B9%E6%B3%95.pdf。















 1033
1033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









