






CLIP
-
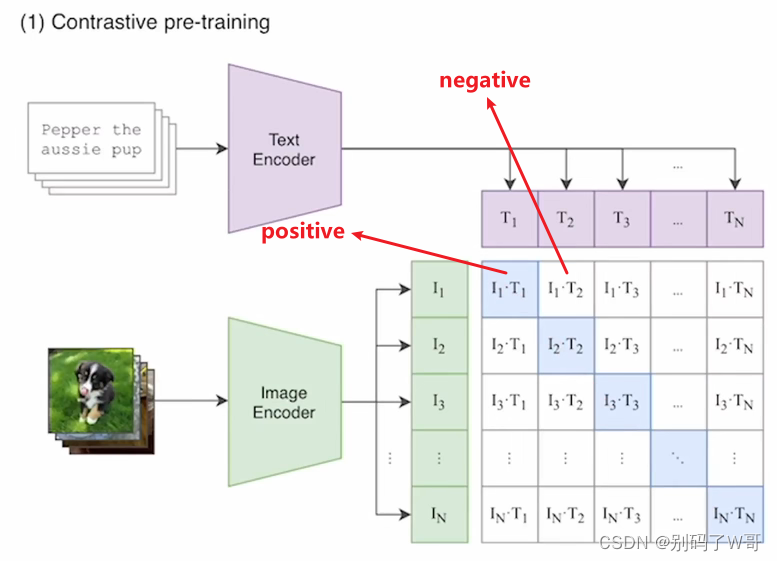
对比学习实现zero shot,图片-文本对构建正负样本,用对比学习进行训练。
-
对比学习:让模型抽取特征构建image-text pair,训练至positive pair余弦相似度高,反之negative pair余弦相似度低。
-
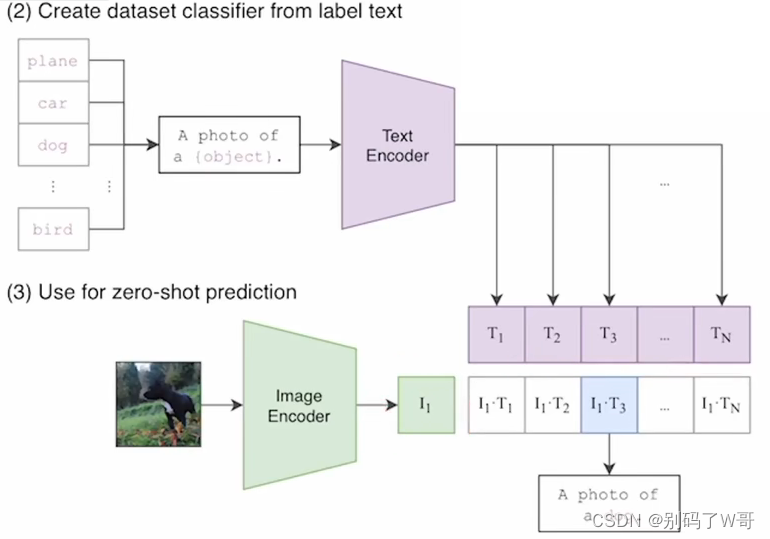
Zero shot inference:取余弦相似度最高的那个pair
-
精妙之处:摆脱了分类头对类别的限制,可以在推理的时候动态地加入新的类别,并且也可以做到正确的推理。搜集了4亿参数量的数据集进行预训练,CLIP具有非常强大的泛化能力,并且可以轻松应用与多种视觉下游任务中并且达到非常好的效果。
-
prompt engineering的重要性:使用一个句子(A photo of a {object})而不是单词,为了解决二义性的问题,同时也考虑到监督信号也是句子而不是单词。或者在特定任务用特定的提示模板,以及使用prompt ensembling(综合多种模板的结果,CLIP用了80种,为了适配各种可能的情况)。
ViLT
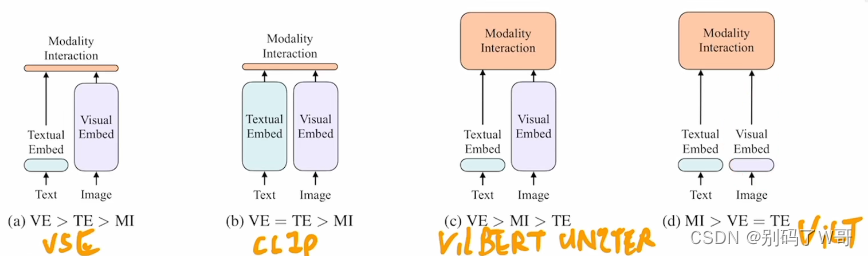
- CLIP对于图文匹配任务性能很好,但是对于VQA,VR,VE等任务性能不够好,因为缺少了模态融合交互;
- 视觉模型要大(ViT),模态融合模型也应该尽可能大,(c)结构显然是更好的结构;
- 损失函数:Mask Modeling Matching Loss,Image Text Matching Loss,Image-Text Contrastive Loss。
ALBEF
- 提出动机:由于先前大模型都是使用预先训练好的目标检测器作为图像的特征提取器,而缺乏一个与文本端到端的训练,从而导致visual tokens和word tokens是不对齐的,对于多模态encoder学习文本和图像的交互是有挑战的。因此,本文引入了对比学习,在特征融合之间对文本和图像任务进行了对齐。
- 用Momentum Model生成为标签,从而实现自训练,解决nosiy web data的问题。
- noisy web data:从网上爬下来的图像文本对中的文本是为了辅助搜索引擎搜索的关键词,但它不是一个对图像很好的描述。
- 模型结构(ALign the image and text representations BEfore Fusing)
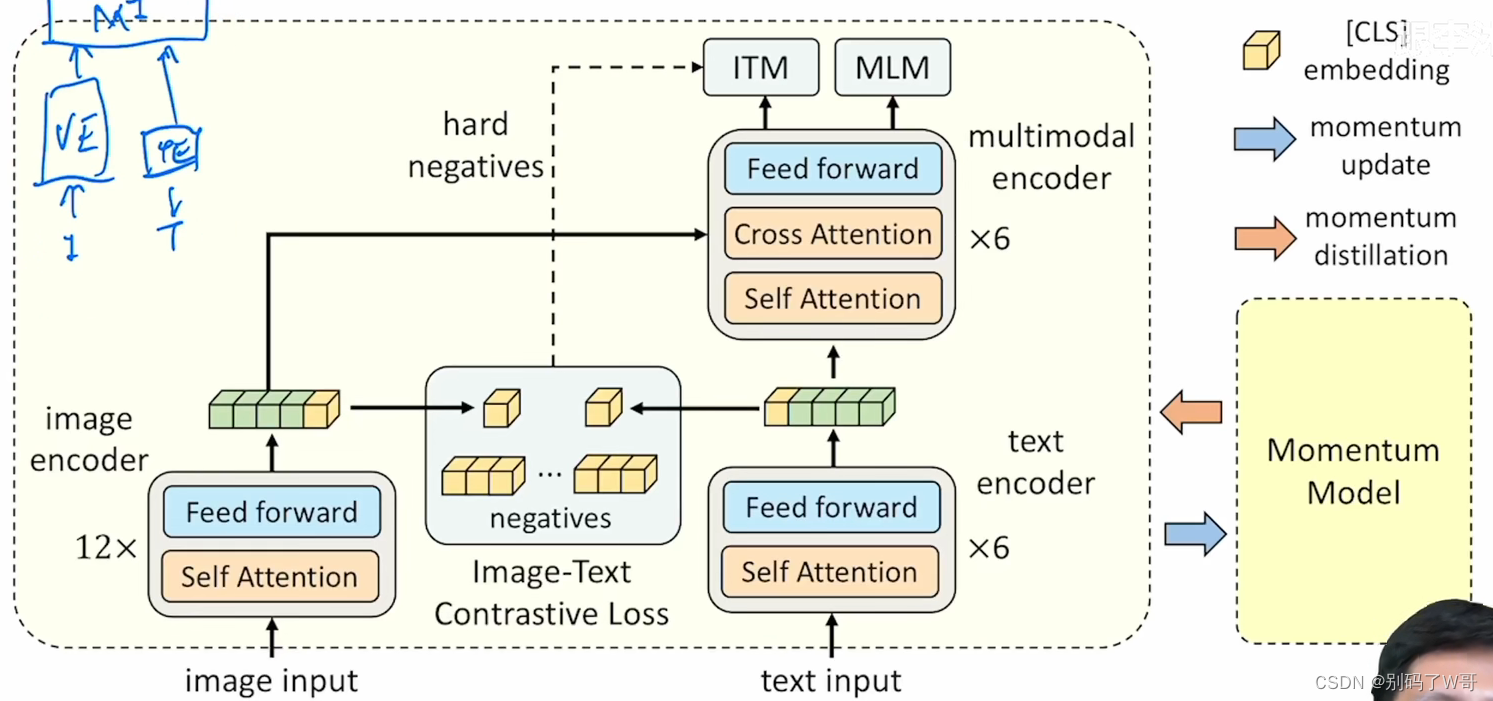
- ITC Loss
- CLS tokens被当做一个全局特征,进行下采样与正则之后,进行相似度计算;
- 在一个q中存储了65536对负样本,由momentum model产生,不占内存(没有梯度)。
- ITM Loss
- image和text经过multimodel encoder之后,经过一个fc层可以出来一个特征;
- 对这个特征进行二分类任务,判断这个image和text是否配对。但是由于任务太简单,需要找hard negatives进行训练;
- 在ITC Loss中,选择相似度最高的负样本作为hard negatives给ITM进行训练。
- MLM Loss
- 将text中的某些单词mask掉得到T’,让模型进行完形填空(预测mask的单词),与BERT类似;
- 由于ITM的输入是(I,T),而MLM输入是(I,T’),因此模型一次更新需要进行两次前向过程;
- Momentum Distillation
- 有的负样本反而比自己的one-hot label更好地描述了image中的信息,这对模型学习非常困难;
- 找一个mulit-hot的监督讯号,可以采取自训练模式。构建一个动量模型来生成为标签,从而实现multi-hot label;
- 在已有模型之上,做exponential-moving-aberage(EMA),从而构建动量模型。文章对ltc和mlm进行了这种训练:
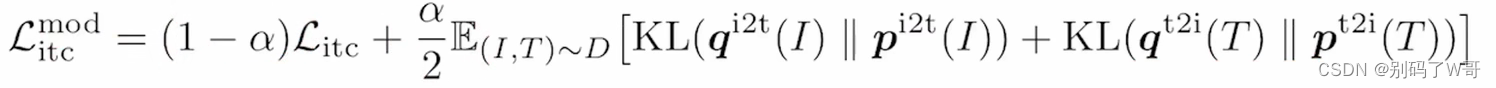
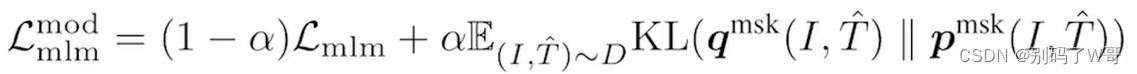

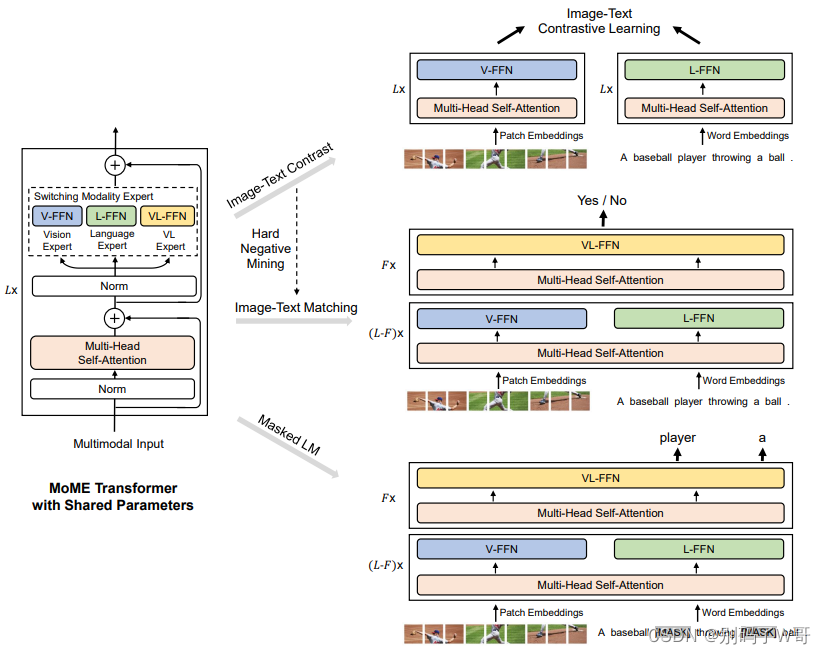
VLMo
- Mixture-of-Modality-Expert:灵活切换dual-encoder or fusion encoder。
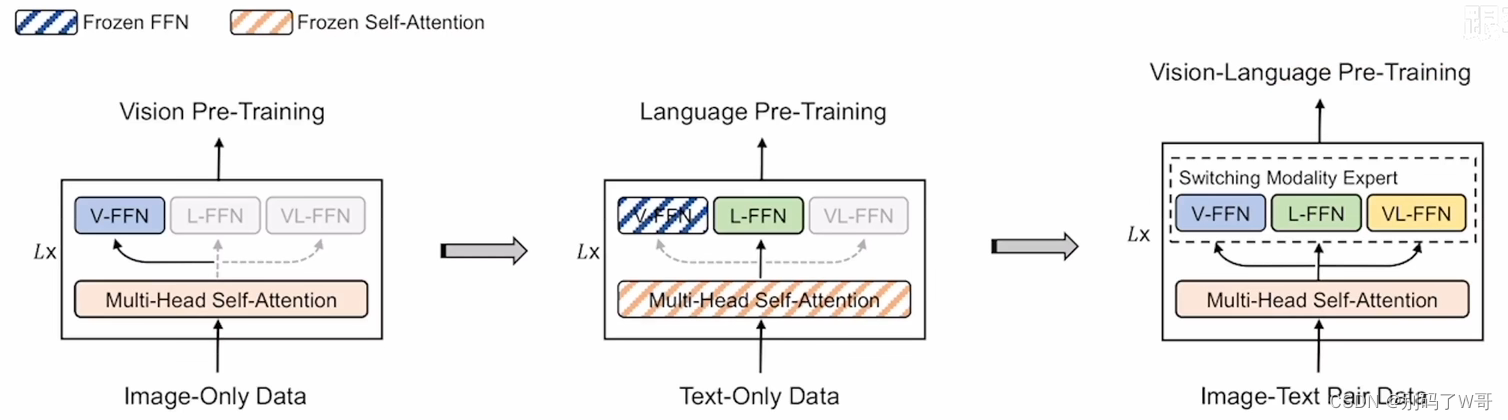
- 分阶段训练:视觉和NLP领域都有大数据集,那可以用他们进行分阶段训练,解决多模态数据集不够大的问题。
- 模型结构:
- 分阶段训练策略(都是无监督训练,采用BEiT的策略,即mask策略):
BLIP
- encoder-based和encoder-decode框架的模型都没有办法做到统一,实现多种不同的任务
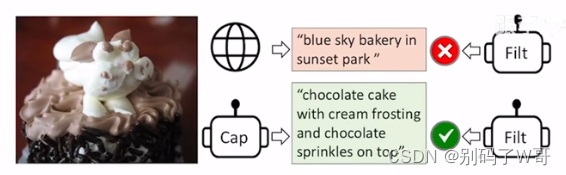
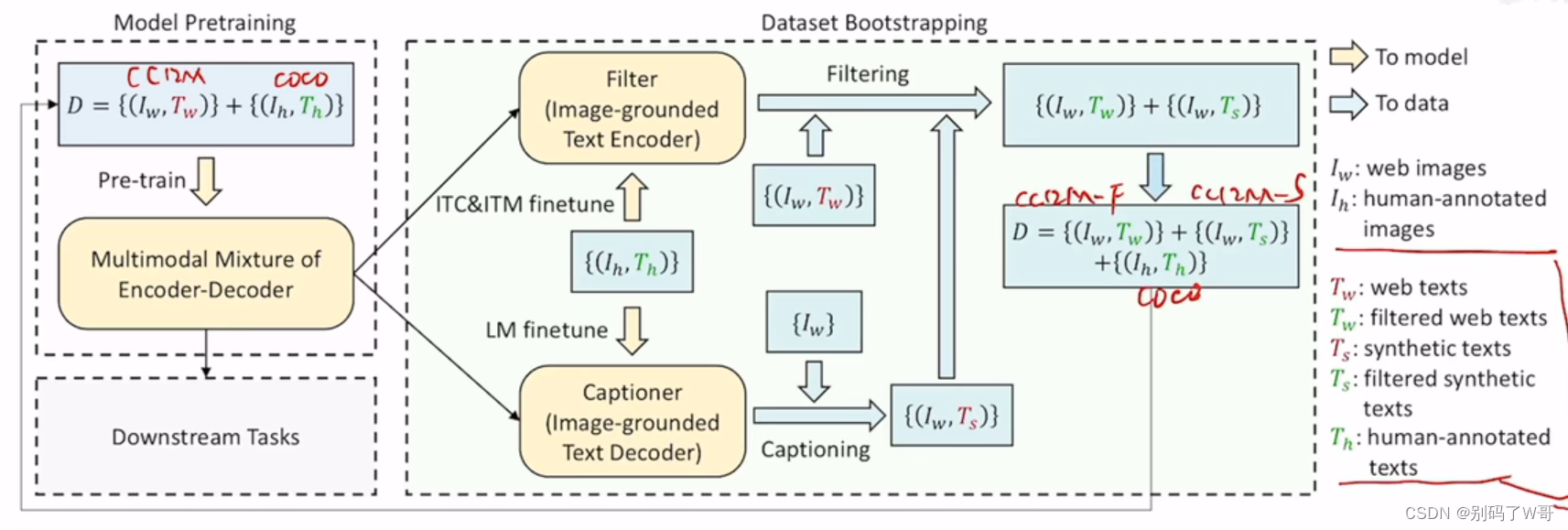
- 数据集生成以及筛选,用一个Captioner生成一些图片相应的文本,再用一个Filter进行筛选:
- 模型结构(一个视觉模型 + 三个文本模型【但是他们结构相同,共享参数】):
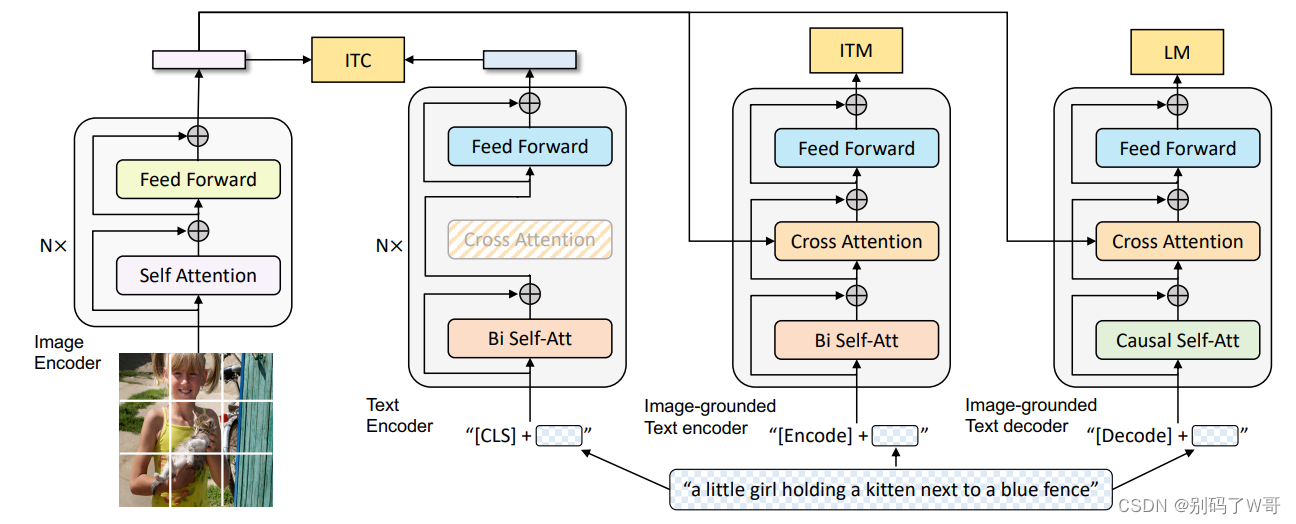
- Causal Self-Att:因果关系自注意力层,可以用于文本生成的任务。
- LM:language model,给定一些词,预测剩下的词,与MLM(完形填空)有区别。
- Data Bootstrapping(红色即被筛掉的,绿色即有效的,这一步将数据集清理得非常好):
CoCa
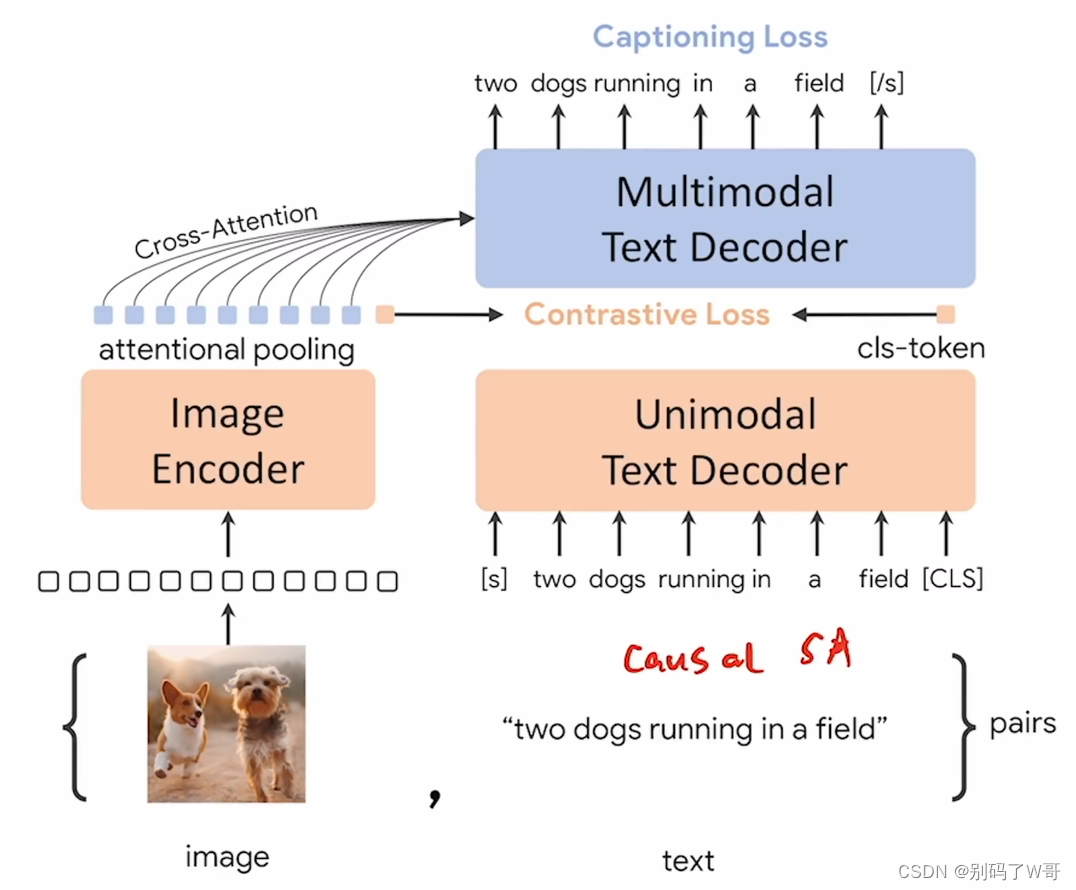
- 结构神似ALBEF,多了attnetional pooling【可学习】,以及使用Captioning Loss【Language Modeling】,并且text端使用的是decoder,从此解决训练效率的问题。
BEiT v3
- 大一统:模型形式、目标函数、模型规模提升。

多模态路线图
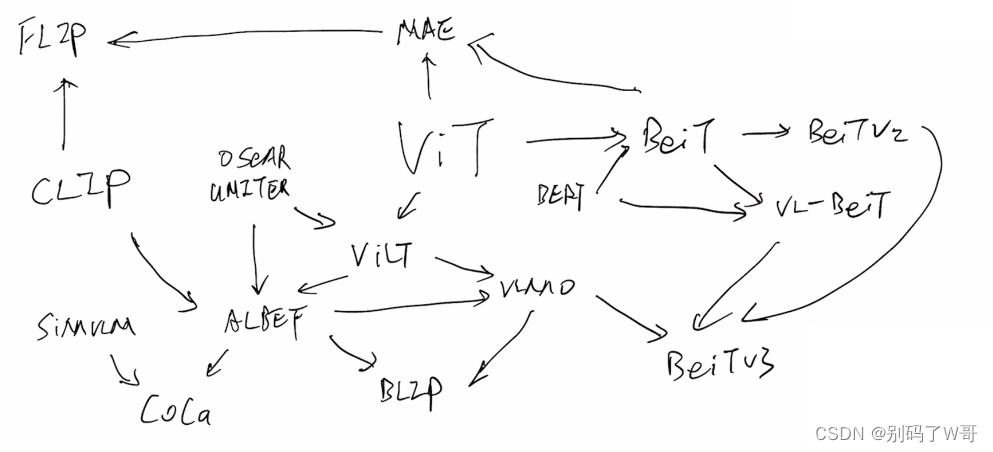














 280
280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









