







个人阅读笔记,如有错误欢迎指出!
来源:arxiv 2019
问题:
客户端的来源是不同的,因此难以避免标签分布不均衡
成员推理、重构攻击等只关注标签是否出现在训练中,容易被安全聚合策略等防御
联邦学习是资源受限的设备可以协同训练,但是会泄露标签分布信息
例:恶意商店可以通过FL方法训练出一个新的商品注册系统,计算出某种商品的供求关系 ,并据此调整其价格以获得不公平的优势
创新:
提出三种攻击(无需梯度):
推断某标签是否存在
确定每个标签的数量,即数量推断攻击确定单轮中所选客户端拥有的训练标签的组成比例
整体确定攻击确定整个训练过程的组成比例
方法:(可以单个可以整体)
攻击者知识:能够从服务器获取信息,更改本地模型和本地数据,知道每个参与方拥有标签的平均标签数量和每个标签的可能数量,知道单轮中被选中的客户端个数
使用稀有的“标签”来识别客户,因为这些标签通常由极少数人拥有。具体来说,如果攻击者在训练中检测到这样的标签,攻击者就可以知道谁参与了训练。
总览:攻击者利用辅助数据集训练局部模型, 本地梯度变化,然后与全局模型的更新变化
作比较,以判断哪些标签出现在当前轮次
中,并据此获得哪些客户端拥有这些标签。(当攻击者在联邦训练中被选中时,比较梯度需剔除掉攻击者的贡献)
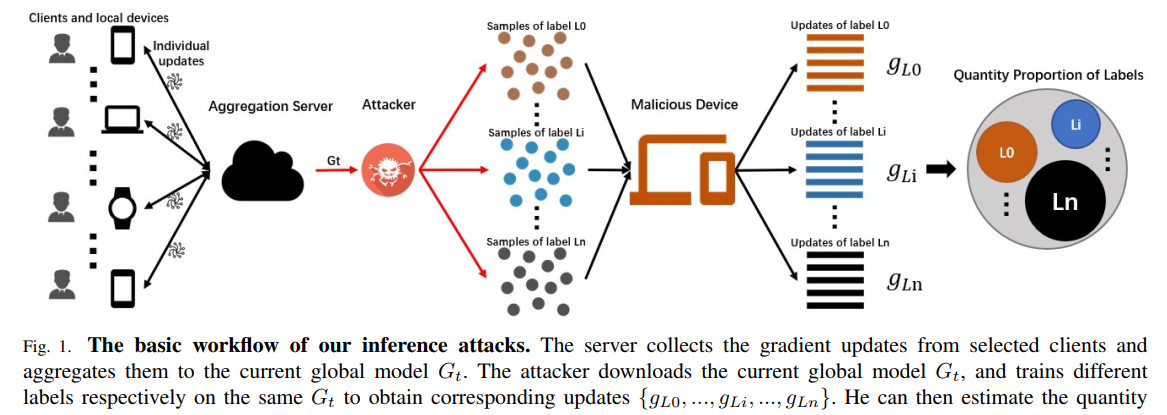
class sniffing类别嗅探:在单个训练轮中,对手能够推断出特定类别的训练数据 是否出现。
quantity inference数量推断:在单个训练轮中,攻击者可以判断某个训练标签是由一小群客户端拥有还是由一大群客户端拥有,并预测有多少客户端拥有该标签
whole determination整体确定:恶意参与者的目的是获取当前全局模型的数据集标签的构成比例
class sniffing类别嗅探
motivation:发现对于某一特定的标签L会使某一神经元权重增加,同时使其他神经元权重减少
目标:检测在单次训练轮次中是否出现了特定的标签。
方法:攻击者下载当前全局模型,使用辅助数据集训练模型,获得梯度更新。通过比较全局更新和辅助数据集训练得到的更新,推断特定标签是否参与了训练。若神经元更新变化超过阈值则该标签出现在训练中,若接近阈值则其在训练中缺席。阈值
为设定的worst case,即设定某标签L不出现在训练集中产生的更新
quantity inference数量推断
目标:确定在单次训练轮次中,特定标签由多少客户端拥有。
方法:类似于类别嗅探,但更进一步分析更新的幅度,以估计拥有特定标签的客户端数量。设置阈值来识别和排除异常值,并使用统计方法来估计客户端数量。
辅助数据集为单个标签数据组成,通过比较辅助数据集上的模型与全局模型来判断数据量的多少。表示增加量。
表示减少量。
计算比例:但更新变化容易受到影响,尤其是只有少量客户端拥有某一标签时,少数的增量很容易被大量的减量所抵消。因此设置比例和
设置阈值,比较每个神经元权重对于每个本地更新(辅助数据集)的
和
,如果
高于设定的阈值则值则将其删除初始集合以减少影响。
估计客户端数量:是用公式来估计拥有特定标签的客户端数量,其中
是总参与者数量,
是被选中的客户端比例,
是全局模型的更新量,
是被选中客户端平均拥有的标签数量。
验证估计:攻击者检查估计的客户端数量是否在合理范围内(例如,不大于总参与者数量,不小于0),对于不合理的估计值,从分析中删除相应的权重更新,并重新计算。基于剩余的权重更新,计算拥有特定标签的客户端数量的平均值作为最终估计。
whole determination整体确定:
目标:确定整个训练过程中不同标签的数据集组成比例。
方法:攻击者在训练的中后期,当模型接近收敛时,下载全局模型并使用辅助数据集进行训练。通过分析频繁和偶尔出现的标签在梯度更新中的差异,推断出数据集中不同标签的相对数量。
在训练的后期,模型可能会对数据出现过拟合,模型参数会过度反应训练数据的特征,攻击者利用过拟合现象,通过分析不同标签在模型参数中的反映,推断出数据集中不同标签的相对数量。
通过聚类结果,攻击者确定不同标签的数据样本数量之间的关系。聚类算法将相似的更新向量分到同一组,从而揭示拥有近似数量数据样本的标签。
实验:
数据集与backbone模型
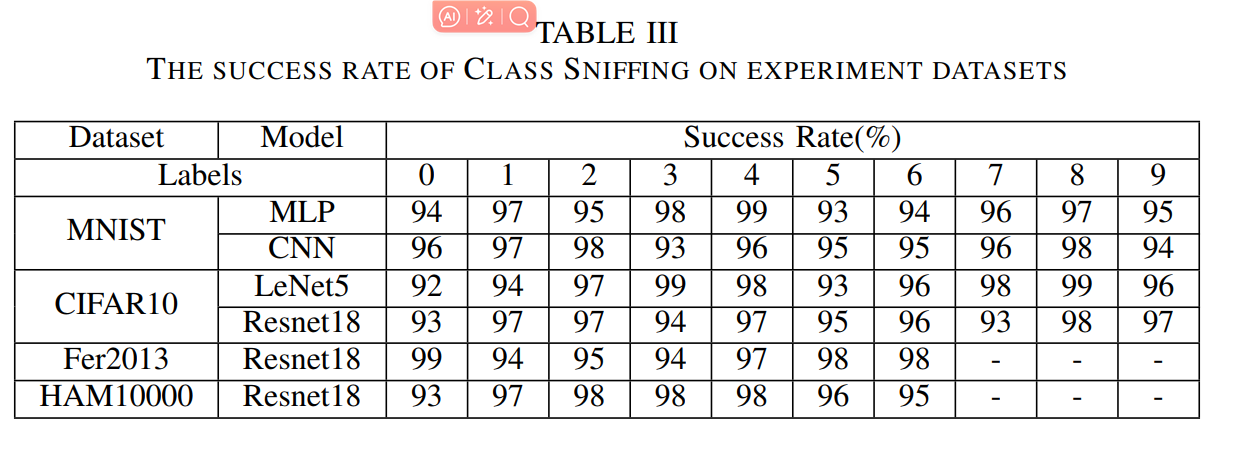
类别嗅探成功率,指标,预测标签成功次数
,失败次数
。
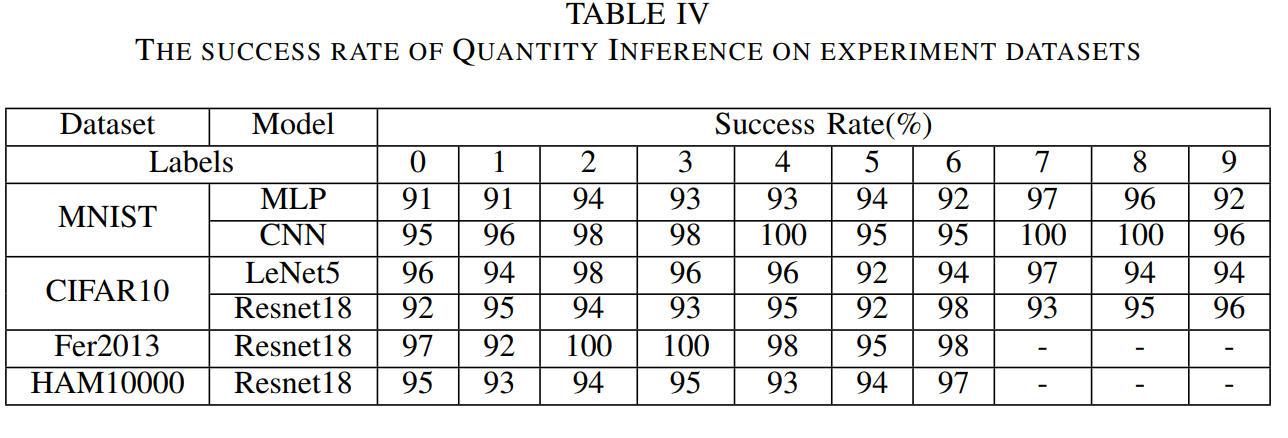
数量推断成功率,指标:假设在某指定轮次中有个客户端拥有标签
,推断出有
个客户端拥有,若
视为攻击成功,
为误差值设定为1,计算成功次数/总次数为评价指标
超参数对数量推断成功率的影响
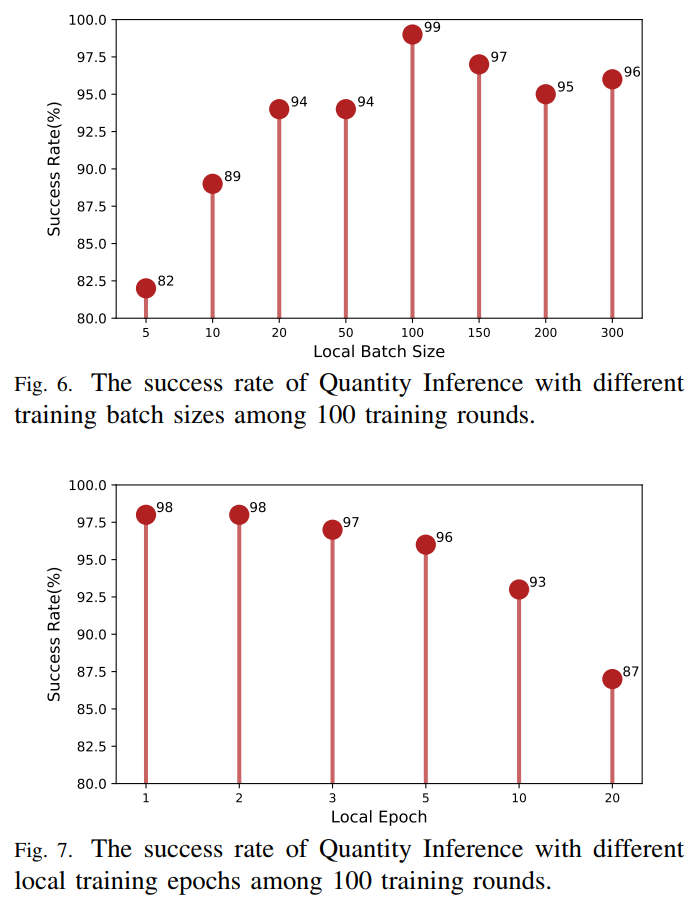
客户端参与比例对数量推断成功率的影响

整体确定攻击中,每个标签样本的数据量有差异,首先找到数量和比例之间的联系,实验中通过改变属于某一标签的样本数量,并记录相应的比例差异。如下图所示,当比例相差4倍时显示出明显差异。将整个标签随机分为3组 ,并确保第一组每个标签可以 分配Q个数据样本,第二组只能 获取Q/4个样本,最后一组只能获得Q/5个样本。这些组将用于训练学习模型,用于评估方法是否可以检测到该组比例。
指标:当聚类结果与训练前的数据分配完全相同时,认为攻击成功,包括聚类的数量和每个聚类中的特定标签。

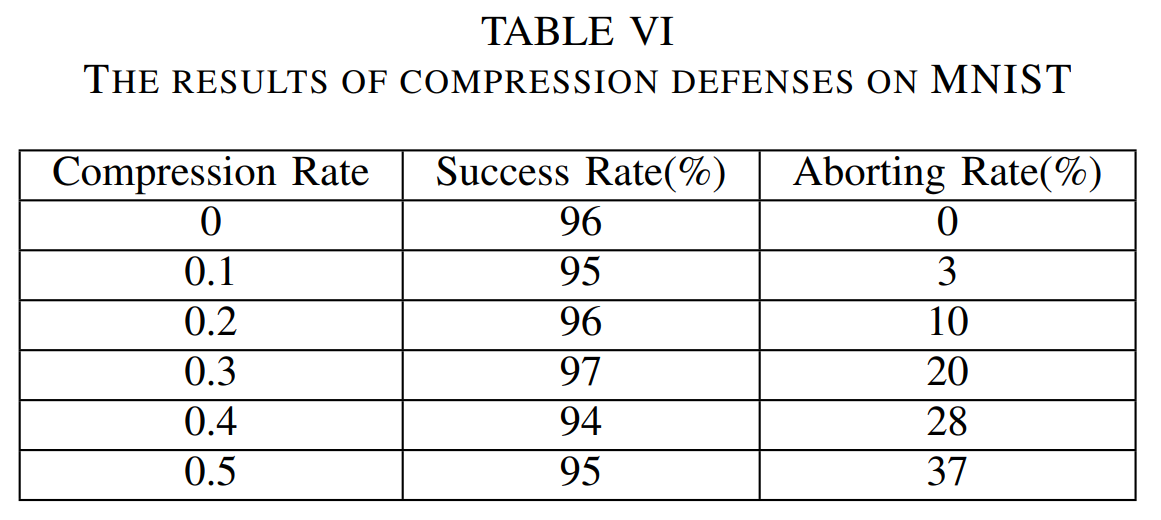
压缩梯度进行防御的效果
















 2005
2005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









