






MCScanX和RIdeogram—同物种不同品系间 共线性分析与可视化
所需软件
blast
link
MCScanX
link
R包 RIdeogram
流程
比对
#准备两个品系的蛋白序列
makeblastdb -in A.pep.fa -dbtype prot -out A.pep
blastp -query B.fa -db A.pep -outfmt 6 -num_threads 20 -evalue 1e-5 -num_alignments 5 -out A_B.raw.blast
过滤
identity≥80%,A coverage≥80%,B coverage≥80%
coverage 即 (query.end - query.start +1 )/query.length ≥0.8
(subject.end - subject.start +1 )/subject.length ≥0.8)
过滤后得到A_B.blast
简化gff
#得到A和B简化后的gff,第一列为染色体id,第二列gene id,三四列分别为起始坐标,如下所示
Chr01 A01110 10283 10858
Chr01 A01120 14247 17702
Chr01 A01130 19786 22962
Chr01 A01140 23827 25856
#合并A和B简化后的gff
cat A.gff B.gff > A_B.gff
MCScanX 共线性
#MCScanX会识别以A_B开头的A_B.blast和A_B.gff,切记blast与gff的前缀要保持一致
MCScanX A_B -s 10 #-s 过滤共线区域比较小的bolck
#结果如下
A_B.collinearity #记录了共线性信息
A_B.html #文件夹,不用管
具体结果在这里有详细说明
link
RIdeogram 可视化
准备如下两个文件
1.文件 len ,第一列染色体编号,二三列染色体起始位置,第四列染色体填充颜色,第五列物种,第六列可视化后物种名字大小,第七列物种名字填充的颜色
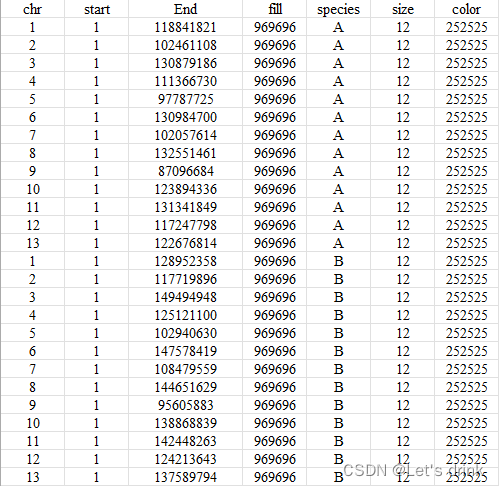
2.第一列A的染色体编号,二三列,具有共线性关系的A的gene_id的起始位置,第四列B的染色体编号,五六列共线性关系的B的gene_id的起始位置,第七列每个染色体填充的颜色
染色体编号须为数值,起始关系根据A_B.collinearity和gff文件可以提出

install.packages("devtools")
library(devtools) #或许需要安装usethis
devtools::install_github('TickingClock1992/RIdeogram')
install.packages("RIdeogram")
ideogram(karyotype = len, synteny = m)#计算处理
convertSVG("chromosome.svg", device = "png")#画图
svg2pdf("chromosome.svg")#svg转成pdf
可视化结果
上面为A
下面为B
















 2011
2011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









