







deepseek今年很火热,既然开源了,那就来试试微调吧。
用一个医学数据集微调推理模型R1系列。
后面会涉及数据集的准备,模型加载,LoRA加载,微调训练和推理过程。
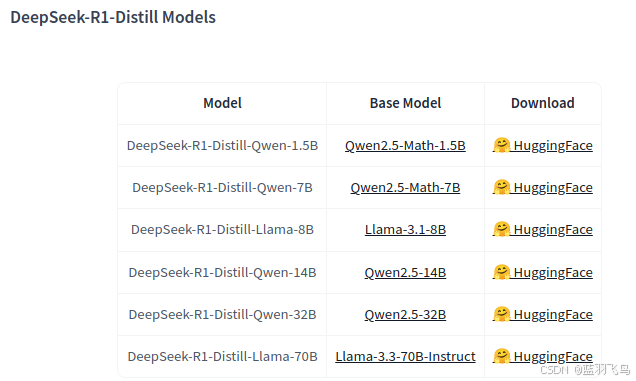
可以看到它有不同的尺寸,模型的硬件需求取决于它们的大小(参数量)以及加载方式(FP16、INT8、INT4等)。
GPU需求如下:
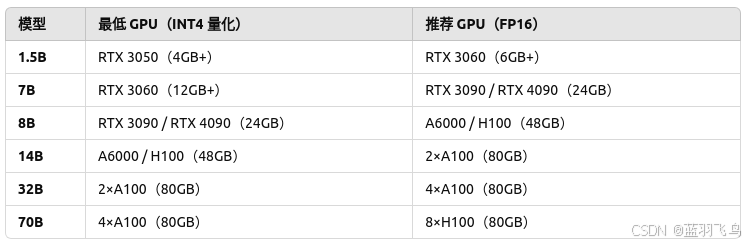
我们这里用3090微调一个7B的R1模型。
微调(Fine-Tuning)是对已经训练好的大模型进行特定任务的优化,以提高其在特定数据上的表现。
那么微调有哪些方法呢?
-
全参数微调(Full Fine-Tuning)
最标准的微调方式:对模型的 所有参数 进行训练
适用于:计算资源充足,任务与原始训练数据差异较大(如医学、法律)
缺点:
计算成本高(7B 需要 100GB+ GPU 内存)
训练数据量需要足够大(否则容易过拟合)
适用于少量任务,不能灵活切换任务 -
LoRA(Low-Rank Adaptation)
只在模型的 部分权重(如 QKV 矩阵) 上 添加可训练参数
通过 低秩矩阵(A×B) 来优化参数更新
优点:
极大降低显存消耗(7B 只需 10GB)
适用于多任务 LoRA 适配器切换
训练速度快 -
QLoRA(Quantized LoRA)
LoRA + INT4 量化,让 LoRA 微调时占用更少显存
允许 在 INT4 量化模型上训练 LoRA
比普通 LoRA 省 50% 显存
7B 只需 6GB 显存即可微调
另外还有Prefix Tuning(前缀微调),Adapter Tuning(适配器微调),BitFit(偏置微调),Adapter Fusion(适配器融合)。3090的话推荐LoRA或QLoRA。
Lora原理参考这里
数据集格式转换
使用医学数据集:medical-o1-reasoning-SFT
它长这个样子,有英文和中文两个子集,我们这里用中文(zh)的。
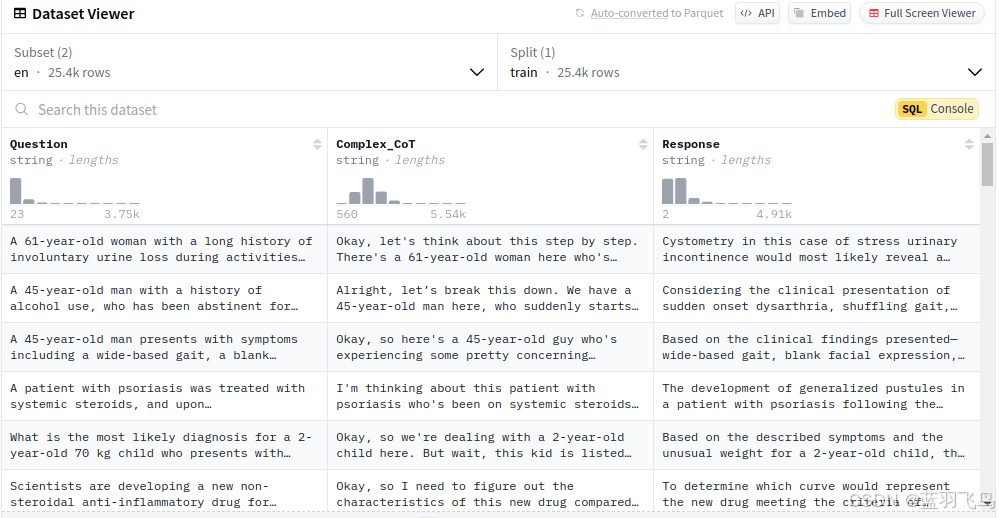
这里可以看到数据集有3列,“Question”,“Complex_CoT”, “Response”,
其中Question是对话时的问题,CoT是思维链,是思考过程的描述,Response是最后的回答。
不过大模型需要的数据格式是这样的,需要把上面的数据转为下面这样的格式:
train_prompt_style = """
以下是一个任务说明,配有提供更多背景信息的输入。
请写出一个恰当的回答来完成该任务。
在回答之前,请仔细思考问题,并按步骤进行推理,确保回答逻辑清晰且准确。
### Instruction:
你是一位具有高级临床推理,诊断和治疗规划知识的医学专家。
请回答以下医学问题。
### Question:
{}
### Response:
<think>
{}
</think>
{}
"""
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text" : texts,
}
dataset = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT", "zh", split="train")
dataset = dataset.map(formatting_prompts_func, batched=True)
我们来说明一下这段代码做了什么,
如果把数据集的3列写成提示词的形式,是这样的
### Question:
什么是心房颤动?
### Complex CoT:
心房颤动是一种常见的心律失常,可导致血栓形成和中风风险增加。
### Response:
心房颤动(Atrial fibrillation,AF)是一种快速、无规律的心跳状态,通常需要抗凝治疗。
<eos>
那现在大模型不需要Complex CoT,而是用Response里的 < think > < /think >代替,所以把Complex CoT的内容移到think里面, think结束后直接接上Response的内容。把Question对应的内容放到#Question下面,这就是train_prompt_style.format(input, cot, output)做的事情。
这是训练过程,< think >里面和“ ### Response”后面是有数据的,推理时只给到开头的< think >, 后面的部分让模型预测输出。
注:不要以为模型回答就是往Response里面填答案,不是填答案的。模型的预训练是根据前文预测下一个token, 那么这里也是一样,根据前文(到Response为止)预测后面的token。
其他数据部分的细节问题:
在每行数据的结尾加上一个EOS,为什么一定要加EOS?
如果 不加 EOS_TOKEN,训练时可能会把多个样本拼接成一个 连续文本,导致模型在推理时无法区分不同对话:
模型可能无法区分 一个问题的结束和下一个问题的开始,导致 输出混乱。
### Question:
什么是心房颤动?
### Response:
心房颤动是一种快速无规律的心跳状态,通常需要抗凝治疗。
### Question:
如何治疗高血压?
### Response:
...
为什么Question, Response等这些提示词前面都用“###”开头?
大部分 Instruction-Tuned(指令微调) 的大模型(如 GPT-4、LLaMA、Mistral、DeepSeek)在 训练时的数据格式 都使用了 ### 作为 分隔符。
“###” 明确标明不同的部分,模型不会把 Instruction 或 Question 当作需要回答的内容,从而提高稳定性。
为什么formatting_prompts_func一定要返回字典形式"text" : texts,而不是直接返回texts?
在 Hugging Face datasets 里,数据转换函数 必须返回字典格式,而 不能直接返回 list。
dataset = dataset.map(formatting_prompts_func, batched=True)这句会让数据集新增加一列"text", 批数据执行,返回一个新的数据集,为如下格式:
{
"Question": "如何治疗心脏病?",
"Complex_CoT": "心脏病治疗包括药物、手术等...",
"Response": "患者需要控制血压,并遵医嘱...",
"text": "### Question: 如何治疗心脏病?\n\n### Complex CoT: 心脏病治疗包括药物、手术等...\n\n### Response: 患者需要控制血压,并遵医嘱...\n\n<eos>"
}
下载deepseek模型
可以通过如下代码尝试一下deepseek问答,并测试微调前的回答。
这个模型的weight会下载到“~/.cache/huggingface/hub/models–deepseek-ai–DeepSeek-R1-Distill-Qwen-7B/snapshots/特定的hash值“。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
input_text = "<你要问的问题>" #the question
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output = model.generate(input_ids, max_new_tokens = 100)
print(tokenizer.decode(output[0], skip_special_tokens=True))
给模型添加LoRA适配器
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth",
random_state=3407,
use_rslora=False,
loftq_config=None,
)
get_peft_model() 的作用是给 model 添加 LoRA 适配器,指定 LoRA 的超参数(如 r、lora_alpha、lora_dropout)。
简单说明几个参数:
r : LoRA 低秩矩阵的维度. 一般 r=8 或 r=16
target_modules=[
"q_proj", "k_proj", "v_proj", # Attention 部分
"o_proj", # 输出层
"gate_proj", "up_proj", "down_proj", # FFN(前馈网络)
]
target_modules指定 LoRA 作用的模型层. 这些层是 Transformer 计算量最大的部分,使用 LoRA 进行低秩适配可以显著减少训练参数。
LoRA 影响力 = lora_alpha / r, 相当于新加入的低秩矩阵的scale.
use_rslora: True:使用 RS-LoRA(Rank-Stabilized LoRA),在训练中动态调整 LoRA 适配器的秩 r,提高训练稳定性。默认False.
loftq_config: 是否使用 LoftQ 量化, LoftQ(LoRA + QLoRA 量化) 是一种 结合 LoRA 和 QLoRA(量化)的方法,可以进一步 降低显存占用。
微调训练
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=2048,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
num_train_epochs=3,
warmup_steps=5,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs"
),
)
trainer_stats = trainer.train()
不显式地写保存位置的话,会在outputs文件夹下面保存checkpoints.
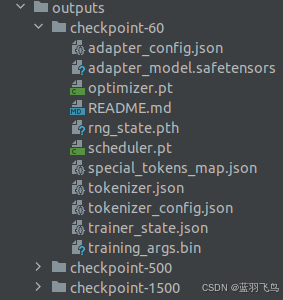
这些文件如下:

如果你想 在 checkpoint 60 的基础上继续训练,可以这样做:
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=2048,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=5,
max_steps=1000, # 继续训练更多步
learning_rate=2e-4,
fp16=True,
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
resume_from_checkpoint="outputs/checkpoint-60"
),
)
如果你想 在推理时加载微调后的 LoRA 适配器:
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
base_model_path = "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"
model = AutoModelForCausalLM.from_pretrained(base_model_path, torch_dtype=torch.float16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(base_model_path)
lora_model_path = "outputs/checkpoint-60"
model = PeftModel.from_pretrained(model, lora_model_path)
# inference
question = "<your question>"
inputs = tokenizer(question, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=100)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
如果你想保证 推理时和训练时的分词器设置一致:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("outputs/checkpoint-60")
当然也可以指定weight的保存路径:
save_path = "Deepseek-R1-Medical-CoT"
#保存lora的适配器,仅需几MB,推理时需要和原来的model合并,base_model+lora
model.save_pretrained(save_path)
tokenizer.save_pretrained(save_path)
#保存完整的7B模型(base_model+lora),会有pytorch_model.bin或.safetensors
#16bit保存大约需要13GB内存
#它的推理效果和base_model+lora完全一样
#model.save_pretrained_merged(save_path, tokenizer, save_method="merged_16bit")
来看一下训练过程吧,值得注意的是grad norm, 可以看到大部分时候梯度范数较低(< 5),表示训练比较稳定,但在某些地方有几个“尖刺”,出现瞬间的极高梯度(>50),可能是数据分布不均导致。

grad norm概念:

这时可以考虑加入梯度裁剪。gpt3的paper中就限制了这一项。

training_args = TrainingArguments(
output_dir="fine_tuned_model",
per_device_train_batch_size=2,
num_train_epochs=3,
learning_rate=5e-5,
max_grad_norm=1.0
)
推理
from peft import PeftModel
from unsloth import FastLanguageModel
local_model_path = ("<your downloaded deepseek weight path>")
max_seq_length = 2048
dtype=None
load_in_4bit=False
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=local_model_path,
max_seq_length=max_seq_length,
dtype="auto",
load_in_4bit=load_in_4bit,
)
FastLanguageModel.for_inference(model)
# load lora
lora_model_path = "outputs/checkpoint-60"
model = PeftModel.from_pretrained(model, lora_model_path)
# inference
prompt_style = """
以下是一个任务说明,配有提供更多背景信息的输入。
请写出一个恰当的回答来完成该任务。
在回答之前,请仔细思考问题,并按步骤进行推理,确保回答逻辑清晰且准确。
### Instruction:
你是一位具有高级临床推理,诊断和治疗规划知识的医学专家。
请回答以下医学问题。
### Question:
{}
### Response:
<think>{}
"""
question1 = ("<one medical question>")
inputs1 = tokenizer([prompt_style.format(question1,"")], return_tensors="pt").to(model.device)
outputs1 = model.generate(
input_ids=inputs1.input_ids,
attention_mask=inputs1.attention_mask,
max_new_tokens=1200,
use_cache=True
)
response1 = tokenizer.batch_decode(outputs1, skip_special_tokens=True)
print(response1[0].split("### Response:")[1])
参考资料:
训练定制化DeepSeek R1


















 2145
2145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











