






算力租赁请访问网页端:gpu.icloud.cn
模型训推请访问网页端:aiops.icloud.cn
直通车:
算力特惠活动 - 顺网智算 (icloud.cn)![]() https://gpu.icloud.cn/activity/school?activityId=1
https://gpu.icloud.cn/activity/school?activityId=1
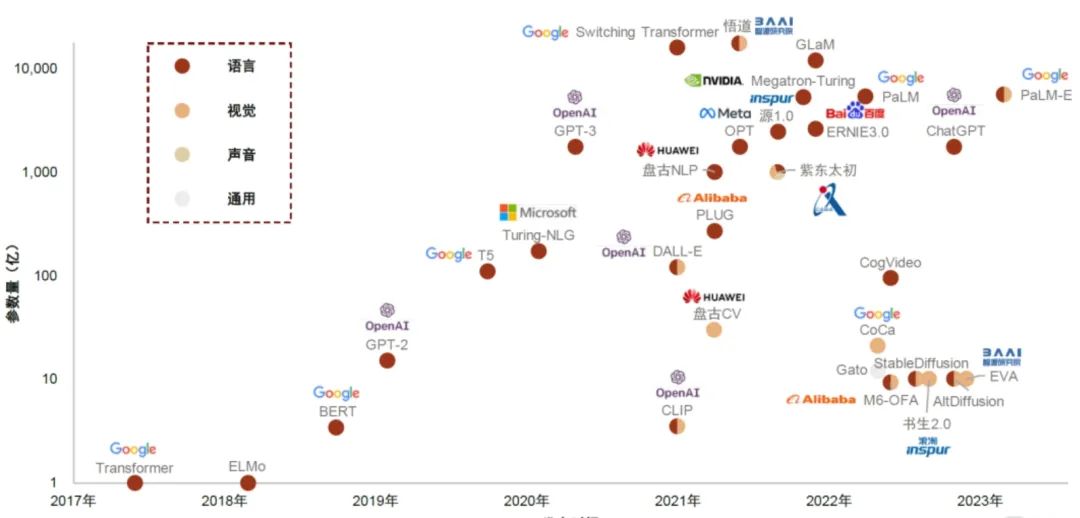
引言:随着2017年《Attention Is All You Need》文章提出transform模型,2022年的以transform为底座的ChatGPT出现,以此掀起了AI大模型浪潮,在大模型的实施背后一个重要的基础因素就是硬件条件,而算力是硬件运行大模型的核心基础。
01名词概念及背景
目前大模型用的最多的是使用NVIDIA算力显卡。
在使用显卡时大模型消耗算力的3个场景(预训练Pre-training构建基座模型实现通用能力、微调Fine-Tuning基于基座模型实现专业能力、推理Inference模型应用落地)。
如何针对现在不同量级的大模型训练或者推理选择合适的算力显卡,下面将从显卡的显存和算力资源角度去分析,并且提供相关指标的量化手段和选型指导。
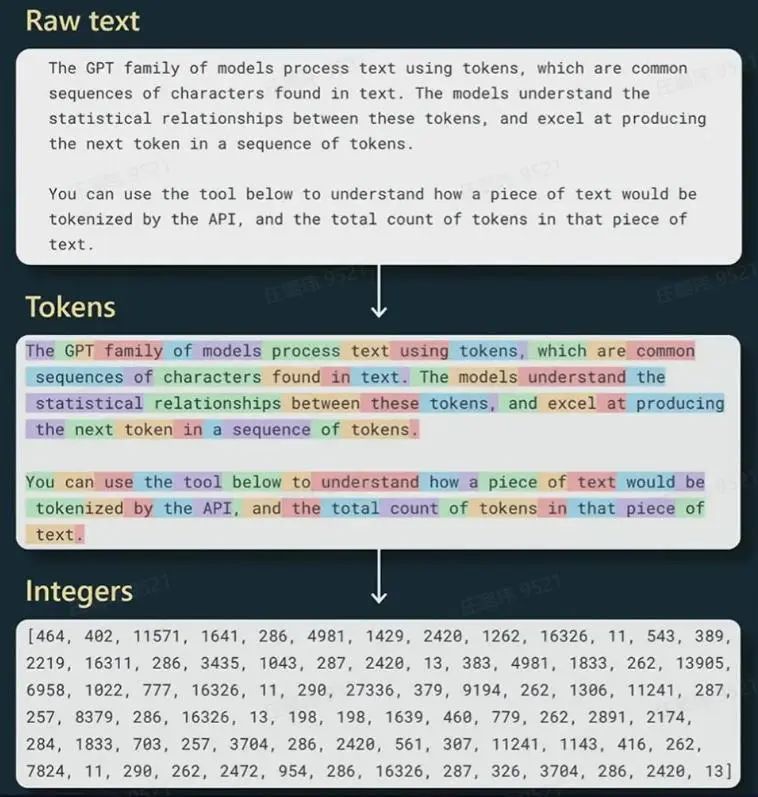
在计算算力之前需要了解大模型的参数量、大模型中的token和精度。
大模型参数量:
神经网络的权重或偏置项,如gpt-3.5-turbo的参数量在7B即70亿参数
token:
文本中最小的语义单元,经过tokenization(标记化)获得 1 token ≈ 0.75 英文单词 ≈ 1.x 汉字
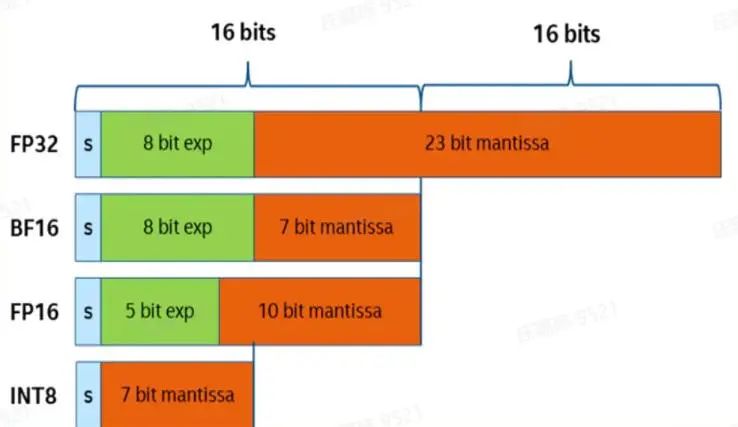
计算精度区分:
fp32 精度,一个参数需要 32 bits, 4 bytes.fp16 精度,一个参数需要 16 bits, 2 bytes.
bp16 精度,一个参数需要 16 bits, 2 bytes,更高的数值范围,数值范围跟FP32等同int8 精度,一个参数需要 8 bits, 1 byte.
一般显存有多少G/M是说有多少G/M个字节(byte),1个字节=8比特(bit),全精度训练(fp32),一个参数对应32比特,也就是4个字节
02大模型显卡需求计算
根据经验公式选择使用的显卡,显卡是决定大模型能不能运行不会出现OOM,而算力是决定模型的训练速度。可根据公式可以预估出所需要的资源多少,以决定选择什么类型的显卡。
显存
1.推理
显存(推理) = 模型大小 * 1.2 = 模型参数量 * 每参数精度位数 *1.2
显存(推理)= 模型大小 * 1.2 = (模型参数量 * 精度位数 / 8)*1.2
由2块组成:模型参数、模型中间计算结果
2.训练
显存(训练) ≈ 10 * 显存(推理)
由4块组成:模型参数、模型梯度、模型中间计算结果、优化器
3.举例
若正常推理要得到显存占用可根据公式计算,llama 7b fp16位半精度计算为例:
推理显存 = 1.2 * 2(fp16精度)*6*10^9(参数) / 1024^3 = 15.65GB
训练显存 = 15.65 * 10 = 156.5GB
算力
1.训练
计算量C(训练) ≈ 6 * P(模型参数量)* D(数据集大小)
T= C / ( MFU * S )
2.推理
计算量C(推理) ≈ 2 * P(模型参数量)* D(数据集大小)
注:
C:训练一个 Transformer 模型所需要的算力,单位是 FLOPs
P:一个 Transformer 模型中参数的数量
D:训练数据集的大小,也就是用多少 tokens 来训练
MFU: 算力利用率,一般通用集群利用率在0.3−0.55
S:训练模型所用集群的算力,卡的数量*每张卡的算力
3.举例:
若要得到训练时间则可根据公式计算举例:
Llama 2-7B训练,根据官方公布接受了2万亿个token训练,以FP16精度训练
计算量 C(训练)= 6 * 70亿参数 * ( 2* 10^12 ) tokens =8.4*10^7 PFLOPs
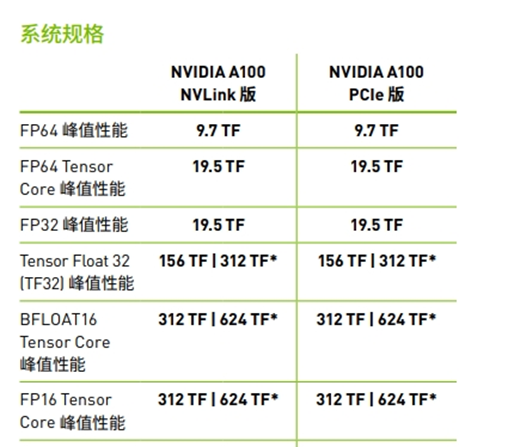
A100单卡训练耗时 T = 计算量C(训练)/ 单卡算力( 每秒运算次数 )/ 利用率= 8.4*10^7 PFLOPs / 0.6 PFLOPS(A100单卡) / 3600秒 / 24小时 / 1= 1620天(耗时4年多)
若有A100*10卡 T = 计算量C(训练)/ 单卡算力( 每秒运算次数 )/ 利用率= 8.4*10^7 PFLOPs / 0.6 PFLOPS(A100单卡) / 3600秒 / 24小时 / (0.55 * 10卡) = 535.5天(耗时1.5年左右)
其中A100的相关指标如图所示:
03需求计算的结论
1.模型能够训练或者推理不出现OOM最直接的方式可使用文中公式可以简单计算出需要的显存。
2.模型训练时间加快最直接的方式是用多机多卡缩短时间,可以根据文中公式计算出需要的时间。
3.随着使用框架的优化(deepspeed、megatron等),可以把更多的计算优化从GPU中释放,让更多的cpu和内存参与,把对应的GPU使用率提高。
版权声明:
除原创作品外,本平台所使用的文章、图片、视频及音乐属于原权利人所有,因客观原因或会存在不当使用的情况,如,部分文章或文章部分引用内容未能及时与原作者取得联系,或作者名称及原始出处标注错误等情况,非恶意侵犯原权利人相关权益,敬请相关权利人谅解并与我们联系。
算力租赁请访问网页端:gpu.icloud.cn
模型训推请访问网页端:aiops.icloud.cn
直通车:
算力特惠活动 - 顺网智算 (icloud.cn)![]() https://gpu.icloud.cn/activity/school?activityId=1
https://gpu.icloud.cn/activity/school?activityId=1

END















 1444
1444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









