






 本文围绕代码生成大模型训练所需的模型、数据、任务设计展开。指出代码生成大模型是语言模型特例,训练语料包括预训练和指令数据等。介绍了多种预训练和指令数据集,以及预训练和指令任务的设计方式,还结合例子给出数据设计思路。
本文围绕代码生成大模型训练所需的模型、数据、任务设计展开。指出代码生成大模型是语言模型特例,训练语料包括预训练和指令数据等。介绍了多种预训练和指令数据集,以及预训练和指令任务的设计方式,还结合例子给出数据设计思路。
代码生成大模型属于LLM模型的一个子类,理论来讲也是属于语言模型的一种特例。代码本身其实也是一种特殊的语言表示,所以代码模型的实现应该是具备通用自然语言和代码两部分的能力。实际的代码模型也是有两条路径来实现,让训练好的NLP LLM模型经过code的训练,或者让code LLM模型经过NLP语料的训练来实现代码生成模型。其实应该还有一条路径,就是把code也当成是nlp语料,不区分code和nlp直接来训练。
对于训练的语料其实和NLP的LLM模型是一样的至少包括三种:pretrain语料、instruct监督训练语料、RLHF的比较训练语料。实际上用的比较多的是前面两种:pretrain语料和instruct语料。
对于模型驯练来说比较重要的就三样东西和一条链路。所谓三样东西无非:模型、数据、任务设计,一条链路就是经过多少轮的数据训练,数据训练的配比和加入顺序。下面我们会围绕三样东西来展开介绍,为什么不讲解一条链路并非有什么秘密。问题在于这个东西很难稳定成一套理论,有点类似传统文化里的“火候”、“易观”这种东西跟实际情况结合很紧密,很难去讲什么时候该如何,就算能讲出来往往也是当时决定完后马后炮的总结,在下一次不一定就完全可用。所以没有更好办法只有你自己多练,自己多感悟自然用多了就知道那么一回事了,往往可能就是一个直觉的决定可能就有效,但是前提是你得碰到问题够多想的够多。
模型
基础模型
| 模型 | size | 架构 | pass@1 |
| codeT5+ | T5 | ||
| code-davinci-2 | GPT | 59.86% | |
| codegeex2 | 6B | GLM | |
| starcode | 15.5B | decode only | |
| codegen16b | 16B | decode only | 29.28% |
| InCoder-6.7B | 6.7B | Fairseq | 15.6% |
| Palm- coder | 540B | 36% | |
| Bloom |
指令模型
| 模型 | size | 指令集 | pass@1 |
| OctoCoder | 16B | CommitPack、CommitPackFT | 35.5% |
| OctoGeeX | 6B | CommitPack、CommitPackFT | 30.9% |
| WizardCoder | 16B | Evol-Instruct | 57% |
| InstructCodeT5+ | 16B | 22.3% | |
| PanGu-Coder2 | 15B | RRTF框架抽数据 | 61% |
| Instruct-Codegen-16B | 16B | code alpaca 250k | 37.1% |
数据
预训练数据
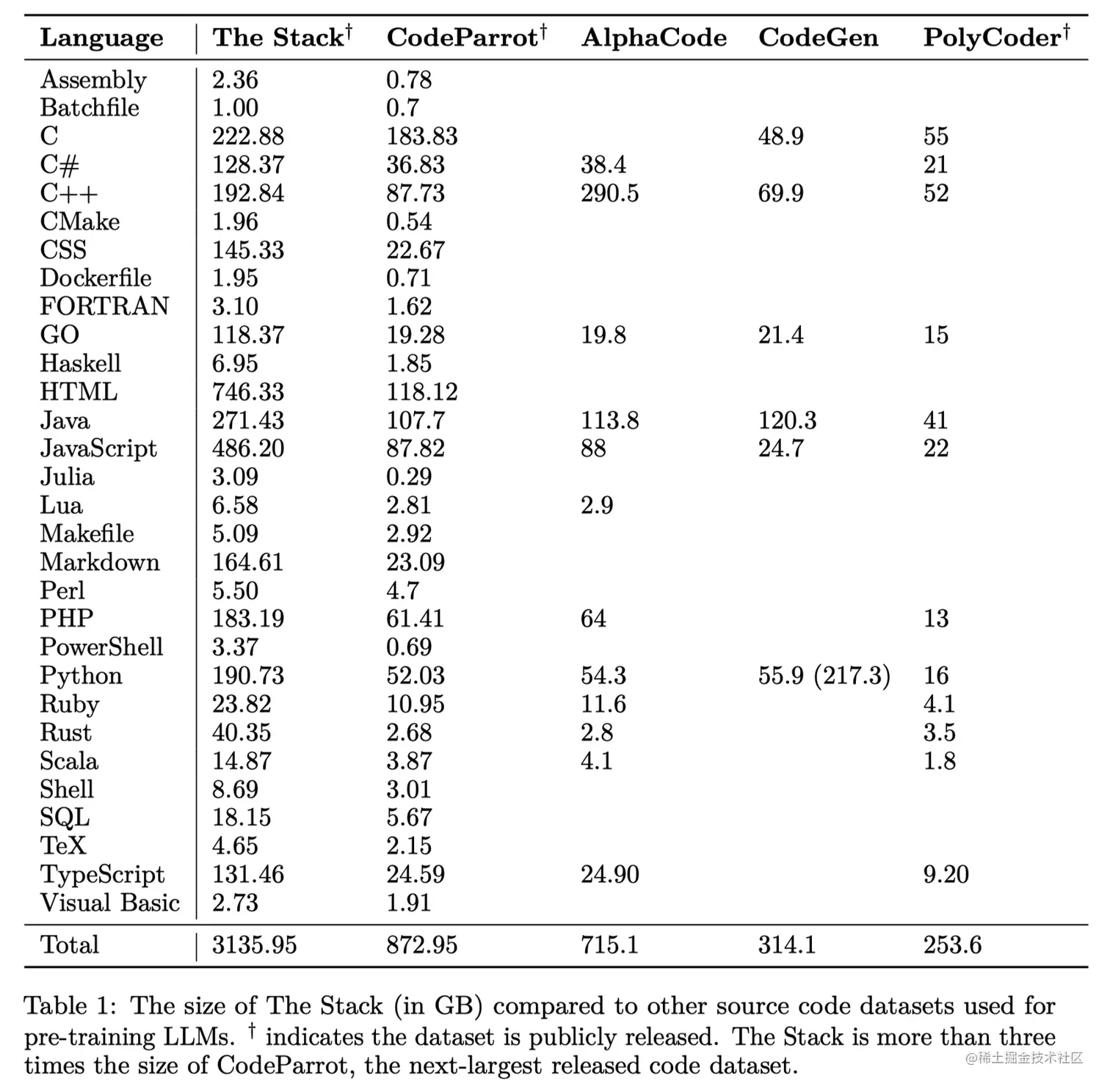
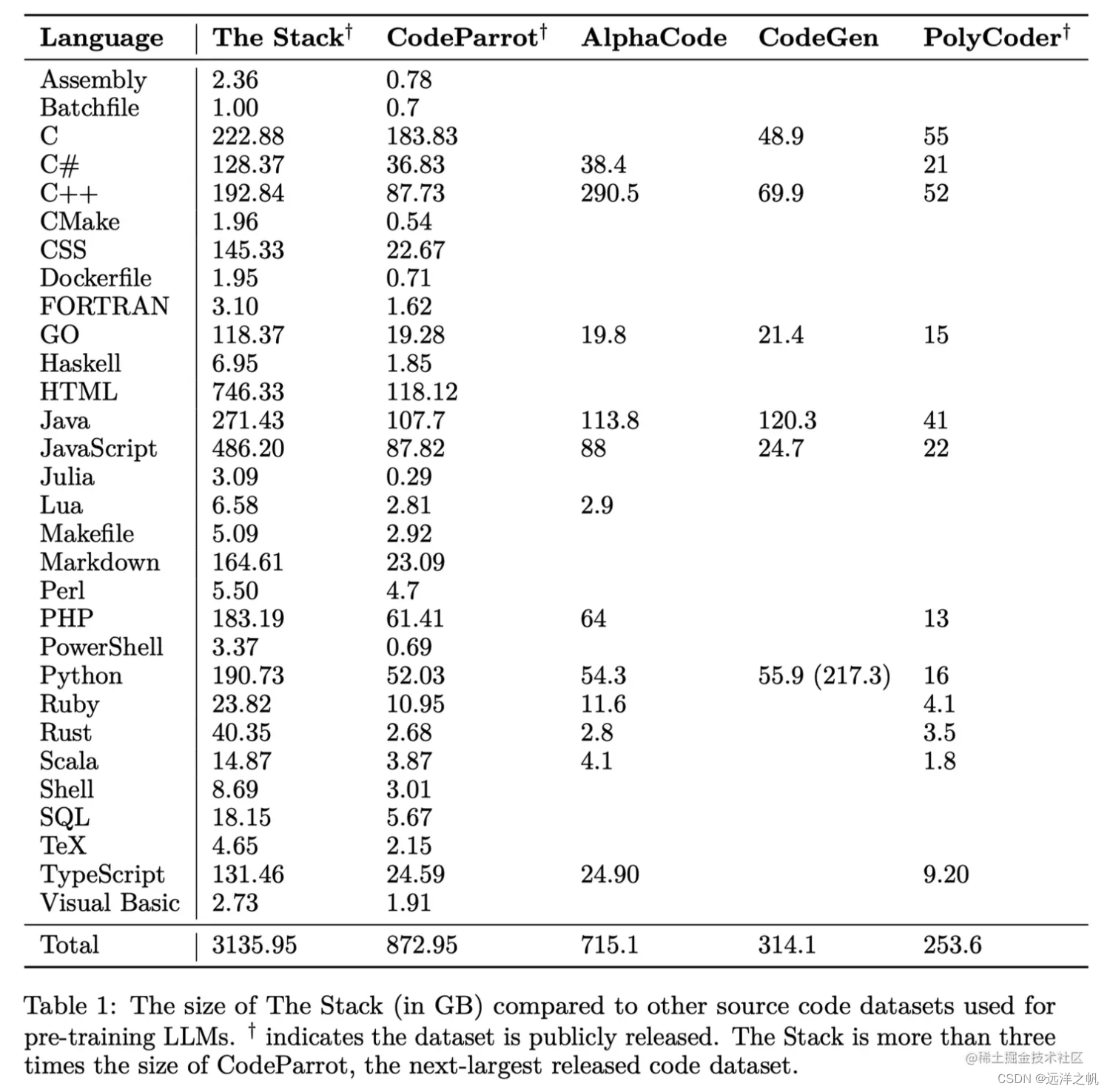
The Stack(6TB)
下载链接:https://huggingface.co/datasets/bigcode/the-stack
The Stack数据集,这是一个具有3.1TB的合法开源代码语料,拥有30种编程语言(注:最新版The Stack v1.1已经拓展到了308种语言,6TB数据);
CodeParrot github-code(500GB)
下载链接:https://huggingface.co/datasets/codeparrot/github-code
PolyCoder(249GB)
下载链接:https://github.com/VHellendoorn/Code-LMs
用的是GitHub上的公开代码,主要选取的是各种编程语言中比较受欢迎的库,每个库至少有50 Stars,采用了多种编程语言代码集来训练,一共有12种
Google BigQuery(2B文件)
Google BigQuery提供了GitHub上许可存储库的快照,可以通过SQL查询进行过滤。AlphaCode,BLOOM,InCoder、CodeGen)都在他们的预训练数据集中包括了这部分数据。
CodeSearchNet(20GB)
下载链接:https://github.com/github/CodeSearchNet
其中包含了约600万种函数,取自Go,Java,JavaScript,PHP,Python和Ruby这六种编程语言的开源代码。
ProjectCodeNet(5亿行)
下载链接:https://github.com/IBM/Project_CodeNet
该数据集包含 1400 万个代码样本,共有用 55 种编程语言编写的 5 亿行代码,其中 C++ 是样本中使用最多的语言,Python 位居第二。
CodeXGLUE
下载链接:GitHub - microsoft/CodeXGLUE: CodeXGLUE
microsoft 开源的,包含10个任务及14个数据集
The Pile
下载链接:The Pile
The Pile数据集也包含来自StackOverflow的问题、答案和评论组成这些问题和答案,但不包含注释。定性地说,作者发现注释。
指令数据
代码生成:
TnT/Multi_CodeNet4Repair · Datasets at Hugging Face
代码填空:
https://huggingface.co/datasets/code_x_glue_cc_cloze_testing_all
代码问答:
Dahoas/code-review-instruct-critique-revision-python · Datasets at Hugging Face
代码判断:
reshinthadith/pairwise-code-review-instruct-critique-revision-python · Datasets at Hugging Face
代码阅读理解:
代码测试:
codeparrot/apps · Datasets at Hugging Face
deepmind/code_contests · Datasets at Hugging Face
代码填空:
code_x_glue_cc_cloze_testing_all · Datasets at Hugging Face
综合性instruct:
nickrosh/Evol-Instruct-Code-80k-v1 · Datasets at Hugging Face
HuggingFaceH4/CodeAlpaca_20K · Datasets at Hugging Face
iamtarun/python_code_instructions_18k_alpaca · Datasets at Hugging Face
任务设计
预训练任务
前向生成
所谓前向生成,在训练形式上其实应该是最简单。就是让模型源码阅读,难点在于选出让他读什么,什么时候读,读几遍。
1.带注释源码阅读
2.带项目需求源码阅读
3.语言规则+代码例子
mask填补
这部分就是如何对源码mask掉一部分,可能是一个词或者几个词,也可能是一行或者几行。然后让代码来做填空。这个可以随机mask,也可以对代码汇总关键词mask或者是变量名mask,或者可以做一些语义理解随机mask。
1. strategyDecisionDrm.__________ 是什么?
2. getDefaultStrategyMap() 方法的返回值是什么类型?
3. 如何从一个 List<String> 中随机选择指定数量的字符串?
4. 请为以下变量添加类型声明:row, strategyCode, recommendCount
5. 使用 Java 8 中的什么方法可以将一个 List<String> 中的元素限制在指定数量?
段生成
这个和上面的mask填补任务很像,可以把整段代码mask或则核心实现mask,或者定义部分mask,更或者可以把代码注释mask,或者功能描述mask,让模型来填补。
判断
这部分可以在代码修复、代码复杂度选择中设计任务,比如可以判断哪个实现是对的,哪个实现会更快,哪个变量名是对的,哪个执行速度会更快,哪个测试结果是对的。
关键词抽取
这部分可以设计抽取指定语意对应的参数,识别关键词、识别摘要和代码的关系。
选择
多个变量选择一个合适的填入代码,代码多段实现选择填入
摘要
对代码结构框架抽起,对代码运行流程抽取,对代码核心实现抽取,抽取代码的实现逻辑。
指令任务
单问题点
生成:
NL-->Code 给文本生成代码
NL-->NL+code 给文本生成代码和描述
NL+code -->NL 生成代码的逻辑、流程,描述;生成代码功能描述
注释:
Code-->NL给代码生成注释
Code-->NL+code 给代码生成代码功能实现思路,代码续写
Code+NL-->code 代码填空,代码改写
问答:
Code+NL--> NL+code 给定代码,根据问题回答问题
改写:
Code+NL--> code 代码改写
Code+NL--> code 代码纠错
Code+NL--> code 代码翻译
Code+NL--> code 代码增加功能
多轮对话/CoT
NL-->NL+code 根据需求生成代码框架
NL-->code 根据需求描述生成带多个功能模块的类
NL+code-->NL+code 跟据功能描述和代码框架,补全细节
NL+code-->NL+code 根据输入输出描述,生成可执行小项目工程
{
"代码生成能力prompt": [
"1.根据以下需求生成一段代码:需要一个函数,该函数接受策略代码和推荐数量作为参数,然后从默认的策略地图中获取对应的股票,如果没有找到相应的策略代码,则返回预设的股票代码,并按照请求的推荐数量进行限制。"
],
"代码补全能力prompt": [
"1.我有一段未完成的代码,需要你帮助完成,代码如下:def useDefaultSymbolPool = { row, strategyCode, recommendCount -> 此处需要你的补全"
],
"代码续写能力prompt": [
"1.给定下面这段代码,能否进行逻辑续写:def ASSET_ID = 'finscprod.chooseStockCard'"
],
"代码纠错能力prompt": [
"1.这段代码中存在一个错误,能否帮助找出并修正:def useDefaultSymbolPool = { row, strategyCode, recommendCount -> def strategyDecisionDrm = row.get('strategyDecisionDrm') as StrategyDecisionStorm"
],
"代码注释能力prompt": [
"1.请为以下代码添加注释:def useDefaultSymbolPool = { row, strategyCode, recommendCount -> def strategyDecisionDrm = row.get('strategyDecisionDrm') as StrategyDecisionDrm"
],
"代码理解能力prompt": [
"1.请解释这段代码的功能:def useDefaultSymbolPool = { row, strategyCode, recommendCount -> def strategyDecisionDrm = row.get('strategyDecisionDrm') as StrategyDecisionDrm"
],
"代码问答能力prompt": [
"1.在本段代码中,getOrDefault方法是如何工作的?"
],
"注释生成代码prompt": [
"1.根据以下注释生成相应的代码:'使用默认的股票池,根据给定的策略代码和推荐数量从策略决策DRM获取股票代码,如果没有找到则返回预设的股票代码,并限制返回的数量'"
],
"功能描述生成代码prompt": [
"1.根据以下功能描述生成代码:'创建一个函数,该函数接受三个输入参数,即row,策略代码和推荐数量,从“strategyDecisionDrm”获取默认策略图,如果策略代码不存在,则返回默认的股票代码,并且返回的数量不超过推荐数量。'"
],
"摘要生成代码prompt": [
"1.从以下摘要生成代码:'这是一个使用默认股票池的函数,其基于输入的策略代码和推荐数量从策略决策DRM中提取股票代码,如果没有找到匹配的策略代码,将返回预定义的股票列表,并根据推荐数量进行限制。'"
],
"代码功能描述prompt": [
"1.为下面这段代码提供一个功能描述:def useDefaultSymbolPool = { row, strategyCode, recommendCount -> def strategyDecisionDrm = row.get('strategyDecisionDrm') as StrategyDecisionDrm"
],
"代码注释生成prompt": [
"1.请根据给定的功能描述生成相应的代码注释:'这个功能会从默认的策略决策DRM地图中获取股票代码,如果无法根据给定的策略代码找到,就会返回一个预设的股票代码数组,并且返回的数量不超过给定的推荐值。'"
],
"功能描述到代码COT prompt": [
"1.请根据以下的功能描述转化为具体的代码操作任务(COT):'我们需要一个函数来从默认的策略地图中获取策略代码,如果没有找到相应的策略代码,则返回预设的股票代码,并按照请求的推荐数量进行限制。'"
]
}例子:
可以通过以下三个层次来对一份代码分析,设计合适的prompt抽取和生成数据,来训练模型的综合能力。
1.需求描述、api描述、代码实现、魔法例子
2.api描述包括:input、output、rpc、service
3.rpc是调用流程链路、service是服务实现函数
4.code实现部分包括import函数包部分、各功能块实现函数、为了支撑服务的各种小服务、pipeline串接执行流程
5.魔法例子是参考的实现服务例子
问题:
a.这份代码实现什么功能、包括了哪些功能模块、功能模块之间调用顺序和逻辑是什么样的
b.每个功能模块实现逻辑是什么,输入输出参数和参数的类型
c.api描述包括了哪些部分,每部分功能是什么
d.给每个功能函数上生成详细注释
e.给定service名或者rpc名把实现代码拎出来
f.生成代码执行流程描述
g.给定描述生成源码
h.给定代码流程生成框架代码
i.给定代码按要求代码
j.代码问答,莫某功能在哪实现,原理是什么,某某函数包含什么参数
小结:
这篇文章比较全面的把code生成大模型实践性需要的东西梳理了一遍。从模型、数据、任务设计给出了可执行层面的梳理,给出了目前主流的一些代码生成模型、和可以用来训练的数据、以及为了让模型具备能力应该要考虑设计的任务,同时也结合一个例子给出了数据如何设计的思路。
1.对于模型的考量从两个维度:预训练、instruct的训练使用企业应用的不同需求。
2.对于数据设计给出了预训练、instruction两部分,同时对两大部分做了更下一个粒度细分
3.对于任务设计也给出了单点任务设计、多轮对话/cot两部分
4.对于模型训练块留在下一篇文章介绍

















 1407
1407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









