






摘要
抽象是素描的核心,因为线条画的简单和最小化特性。抽象涉及识别对象或场景的基本视觉属性,这需要语义理解和对高级概念的先验知识。因此,抽象表现对艺术家来说是具有挑战性的,对机器来说更是如此。我们提出了CLIPasso,这是一种能够实现不同抽象程度的对象素描方法,通过几何和语义简化来指导。虽然素描生成方法通常依赖于显式的素描数据集进行训练,但我们利用了CLIP(Contrastive-Language-Image-Pretraining)的显著能力,从素描和图像中提取语义概念。我们将素描定义为一组贝塞尔曲线,并使用可微分光栅化器直接优化曲线参数,以CLIP为基础的感知损失为导向。抽象程度通过改变笔画的数量来控制。生成的素描展示了多个抽象层次,同时保持了可识别性、基础结构和主题的基本视觉组成部分。

图1:我们的工作将一个物体的图像转换成草图,允许不同程度的抽象,同时保留其关键视觉特征。即使是非常简化的表示(最右边的火烈鸟和马只用几笔就画出来了),人们仍然可以识别出所描绘主题的语义和结构。
1 引言
自由手绘是一种表达想法、概念和行为的宝贵视觉工具[10, 18, 43, 15]。由于草图仅由线条组成,而且通常只有有限的线条数量,因此抽象过程是草图绘制的核心。艺术家必须做出表征决策,选择所画主题的关键视觉特征,以捕捉她希望表达的相关信息,同时省略(许多)其他信息[6]。例如,在著名的“Le Taureau”系列(图2)中,毕加索描绘了牛的渐进式抽象。在这个系列的石版画中,艺术家将一头牛从具体的、完全渲染的解剖图,转变为几条线条组成的草图构图,但仍然设法捕捉到牛的本质。
在本文中,我们提出了一个问题——计算机渲染能否模仿这样的草图抽象过程,将一张照片从具体的描绘转换成抽象的描绘?

图2:“Le Taureau”(公牛)由毕加索创作——请注意,通过逐步移除元素,同时保留公牛的本质,抽象过程是如何实现的。
今天,机器可以通过对输入照片应用数学和几何操作来渲染逼真的草图[42, 5]。然而,对于机器来说,创建抽象更为困难。抽象过程表明艺术家选择视觉特征来捕捉对象或场景的底层结构和语义意义,以产生一个最小的、但具有描述性的渲染。这需要对主题的语义理解,这比简单地对图像应用几何操作更为复杂。为了填补这一语义鸿沟,我们使用了CLIP[34],这是一个在各种风格的图像与文本配对上训练的神经网络。CLIP在编码视觉描述的语义意义方面表现出色,无论其风格如何[14]。
以往尝试复制人类风格草图的作品通常使用所需抽象程度的草图数据集来指导生成草图的形式和风格[3, 25, 30]。虽然这种数据驱动的方法确实可以模仿人类艺术作品的最终渲染,但它需要相关数据集的存在和可用性,并且它限制了输出风格以匹配这些数据。相比之下,我们提出了一种基于优化的从照片到草图生成技术,该技术在不依赖于显式草图数据集的情况下实现了不同层次的抽象。
我们的方法使用CLIP图像编码器来指导将照片转换为抽象草图的过程。CLIP编码提供了概念描述的语义理解,而照片本身提供了草图到具体主题的几何基础。
我们的草图使用一组细长的黑色笔触(贝塞尔曲线)放置在白色背景上定义,抽象的层次由使用的笔触数量决定。给定要绘制的目标图像,我们使用可微分光栅器[24]直接优化笔触参数(控制点位置)以实现CLIP基础的损失。我们结合了预训练CLIP模型的最终和中间激活,以实现几何和语义简化。为了提高鲁棒性,我们提出了一种基于预训练视觉变换器模型的局部注意力图的显著性引导初始化过程。
生成的草图展示了捕捉输入对象本质的语义和视觉特征的组合,同时仍然保持最小,并提供良好的类别和实例级对象识别线索。

图3:我们方法产生的不同抽象层次。从左到右:输入图像和通过将笔画数量减半来实现的更高抽象层次。
相关工作
与基于几何的边缘图提取方法[42, 5]不同,自由手绘草图生成旨在产生结构和语义解释上抽象的草图,以模仿人类风格。这个高层次的目标在不同的作品中有所不同,因为可以产生许多风格和抽象层次。因此,现有的作品倾向于根据给定的数据集选择所需的输出风格:从高度抽象的——仅由基于类别的文本提示引导[16],到更具体的[1],这由轮廓检测引导。图4展示了这个范围。虽然依赖草图数据集的方法受限于存在的抽象层次,但我们的方法是基于优化的。因此,它能够产生多个抽象层次,而不需要依赖于合适的草图数据集的存在,也不需要进行漫长的新的训练阶段。

图4:草图数据集中的风格和抽象层次变化——示例按照抽象程度从左到右排列:从基于边缘的到基于类别的草图。对于有图像参考的数据集,输入图像与草图并排放置;否则,输入仅仅是类别标签(例如,“大象”)。
表1:草图合成算法的比较。(A)不限于训练数据集中的类别,(B)可以产生不同层次的抽象,(C)不限于数据集中的抽象层次,(D)可以产生矢量草图,(E)可以产生序列草图,(F)不直接依赖于边缘图。
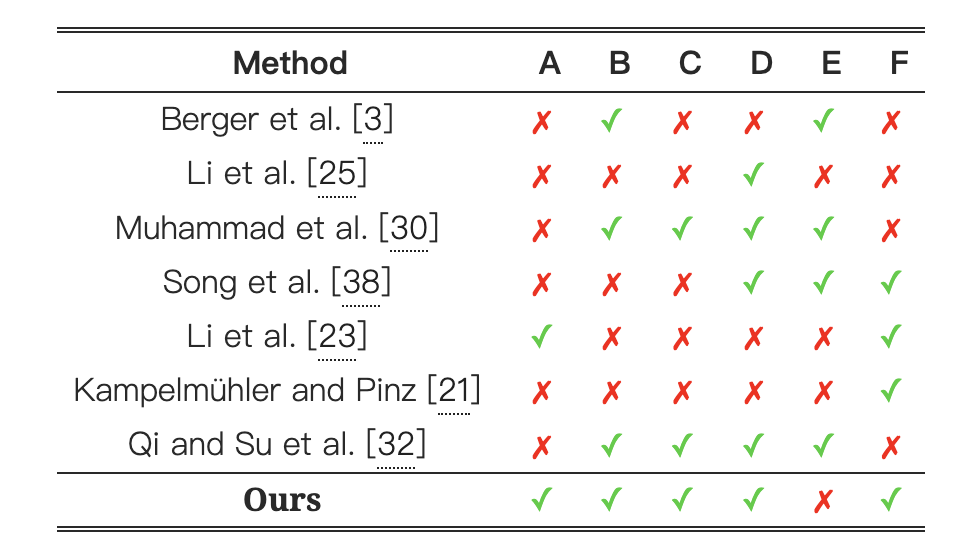
我们对现有的相关照片-素描合成工作进行了简要回顾,这些工作都依赖于素描特定的数据集。表1总结了这些方法的高级特征,以区分它们。
照片-素描合成 早期方法通过学习显式模型来合成面部素描[8, 3]。为了推广到面部以外的类别,Li等人[25]基于感知分组学习了可变形的笔画模型。
在深度学习时代,将照片-素描生成视为域转换任务是直观的。然而,素描的高度稀疏和抽象性质给简单方法[20, 41]带来了适应素描域的挑战,因此必须进行素描特定的调整。
Song等人[38]提出了一种混合监督-非监督的多任务学习方法,带有快捷循环一致性约束。Li等人[23]提出了一种基于学习的轮廓生成算法,以解决数据集中人类绘画的多样性。Kampelmuhler和Pinz[21]提出了一种编码器-解码器架构,其中损失由预训练的素描分类器网络引导。Qi和Su等人[32]提出了一种用于素描的格子表示,使用LSTM和图模型从边缘图中采样的点生成矢量素描。点的密度决定了素描的抽象水平。
矢量图形 在总结Hertzmann[17]和Bénard和Hertzmann[2]的调查中,有大量的文献关于基于笔画的渲染、轮廓可视化和特征线渲染。矢量表示广泛用于各种素描任务和应用,使用了包括RNN[16]、BERT[26]、Transformers[4, 35]、CNNs[9]、GANs[40]和强化学习算法[46, 27, 12]在内的许多深度学习模型。最近开发的不同可微渲染算法[45, 28, 24]使得可以使用基于光栅的损失函数来操作或合成矢量内容。我们使用Li等人[24]的方法,因为它可以处理包括贝塞尔曲线在内的各种曲线和笔画。
素描抽象 只有两项先前的工作提出了一个统一的模型,以在不同的抽象水平上产生给定图像的素描。Berger等人[3]收集了一个由专业艺术家绘制的肖像数据集,这些肖像以不同的抽象水平绘制。对于每位艺术家,创建了一个由形状、曲率和长度索引的笔画库,并用这些笔画替换从图像边缘图中提取的曲线。他们的方法仅限于肖像,并且需要为每个抽象水平创建新的数据集。
Muhammad等人[30]提出了一种笔画级素描抽象模型。通过强化学习代理训练,以选择可以从输入图像的边缘图表示中移除哪些笔画,而不会影响其可识别性。识别信号由在QuickDraw数据集[16]的9个类别上训练的素描分类器提供,因此要操作新类别,需要一个微调阶段。
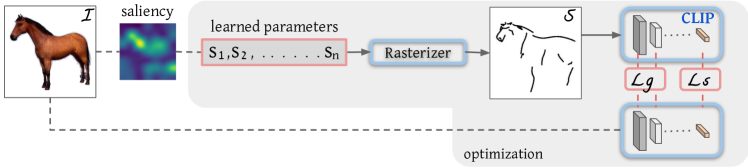
图5:方法概述 - 给定一个目标图像ℐ和笔画数量n,使用显著性图作为分布来采样初始笔画位置{s1,…,sn}。使用可微分光栅器ℛ创建一个光栅化草图𝒮。将草图和图像都输入到预训练的CLIP模型中,以评估两者之间的几何距离𝐿𝑔和语义距离𝐿𝑠。损失通过ℛ反向传播以优化笔画参数直到收敛。学习的参数和损失项用红色高亮显示,而蓝色组件在整个优化过程中保持冻结,实线用于标记反向传播路径。
基于CLIP的图像抽象CLIP[34]是一个神经网络,它在互联网上收集的400百万图像-文本对上进行训练,目的是使用对比学习创建一个联合潜在空间。由于在广泛的图像领域和语言概念上进行了训练,CLIP模型对于各种零样本任务非常有用。在我们的上下文中最相关的工作是Frans等人[11](CLIPDraw)和Tian和Ha[39]。CLIPDraw优化了一组随机贝塞尔曲线,以创建一个草图,该草图最大化了给定文本提示的CLIP相似性。同样,我们也使用了可微分光栅器[24]和基于CLIP的损失。然而,虽然CLIPDraw完全是文本驱动的,但我们允许控制输出外观,以输入图像为条件。为此,我们引入了一个新的几何损失项和一个显著性引导的初始化过程。
Tian和Ha[39]结合使用进化算法和CLIP来产生由彩色三角形表示的创意抽象概念,这些概念由文本或形状引导。他们的结果仅限于完全语义(使用CLIP的文本编码器)或完全几何(使用L2),而我们能够整合两者。
3方法
我们定义一个草图为一组n个黑色笔画{s1,…,sn}放置在白色背景上。我们使用二维贝塞尔曲线来表示每个笔画,该曲线具有四个控制点𝑠𝑖={𝑝𝑖𝑗}𝑗=14={(𝑥𝑖,𝑦𝑖)𝑗}𝑗=14。为了简化,我们只优化控制点的位置,并选择保持笔画的度数、宽度和不透明度固定。然而,这些参数可以在稍后用于实现风格上的变化(见图10(a))。笔画的参数被输入到可微分光栅器ℛ中,它形成了光栅化草图𝒮=ℛ({𝑝1𝑗}𝑗=14,…,{𝑝𝑛𝑗}𝑗=14)=ℛ(𝑠1,…,𝑠𝑛)。正如通常惯例[39, 27, 30],我们通过改变笔画数量n来创建不同级别的抽象。
我们的方法概述如图5所示。给定一个目标图像ℐ,我们的目标是合成相应的草图𝒮,同时保持主题的语义和几何属性。我们首先提取输入图像的显著性区域,以定义笔画的初始位置。接下来,在优化的每一步中,我们将笔画参数输入到可微分光栅器ℛ中,以产生光栅化草图。然后,将生成的草图以及原始图像输入到CLIP中,以定义基于CLIP的感知损失。我们通过可微分光栅器反向传播损失,并在每一步直接更新笔画的控制点,直到损失函数收敛。
3.1损失函数
由于草图非常稀疏和抽象,像素级度量不足以衡量草图和图像之间的距离。此外,尽管像LPIPS[44]这样的感知损失可以编码图像的语义信息,但它们可能不适合编码抽象草图,如图6所示(更多分析请参见补充材料)。一种解决方案是训练特定任务的编码器,以学习图像和草图的共享嵌入空间,在该空间下可以计算两种模态之间的距离[21, 38]。这种方法依赖于此类数据集的可用性,并且需要额外的努力来训练模型。
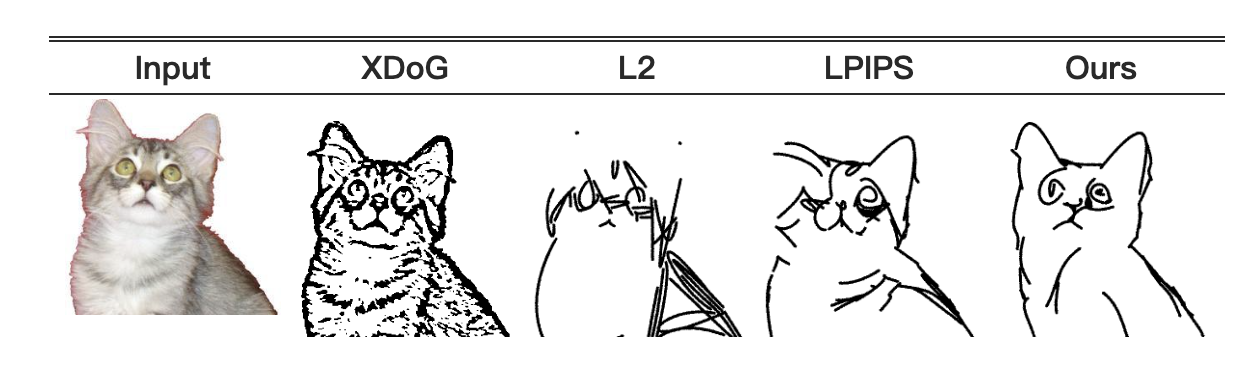
图6:损失函数比较——我们通过最小化不同的损失来优化笔画:L2损失只是鼓励填充彩色像素,LPIPS在语义上更敏感,但生成的草图仍然接近边缘图(比较XDog边缘)。相比之下,我们的CLIP基损失在保持对象形态的同时,能够更好地描绘语义。
相反,我们利用CLIP预训练的图像编码模型,该模型在各种图像模态上进行了训练,因此它可以编码来自自然图像和草图的信息,而不需要进一步的训练。由于CLIP在图像和文本上进行了训练,因此在最后一层编码了高级语义属性。因此,我们将草图的嵌入和图像的嵌入之间的距离定义为:
Lsemantic=dist(CLIP(I),CLIP(R({s_i}i=1n)),(1)
其中dist(x,y)=1−x⋅y‖x‖⋅‖y‖是余弦距离。然而,网络的最终编码对低级空间特征(如姿势和结构)是不可知的。为了测量图像和草图之间的几何相似性,从而对输出的外观进行一定程度的控制,我们计算CLIP中间层激活之间的L2距离:
Lgeometric=∑l‖CLIPl(I)−CLIPl(R(s_i}i=1n))‖22,(2)
其中CLIPl是CLIP编码器在层l处的激活。具体来说,我们使用了ResNet101 CLIP模型的第3层和第4层。优化的最终目标是:
min{s_i}i=1nLgeometry+w_s⋅Lsemantic,(3)
其中w_s=0.1。我们在补充材料中分析了不同层和权重的贡献,以及使用不同CLIP模型的结果。
3.2优化
我们的目标是优化参数集{s_i}i=1n={p_i_j}j=14}i=1n,以定义一个草图,使其在几何和语义上都与目标图像I相似。在优化的每一步中,我们使用现成的基于梯度的求解技术来计算损失相对于笔画参数{s_i}i=1n的梯度。我们遵循CLIPDraw[11]中建议的数据增强方案,在将草图和目标图像输入CLIP之前对其进行增强。这些增强可以防止生成对抗性草图,这些草图可以最小化目标函数,但对人类没有意义。我们重复这个过程直到收敛,即当优化误差没有显著变化时(通常需要~2000次迭代)。图7显示了优化过程中生成的草图的进展情况。
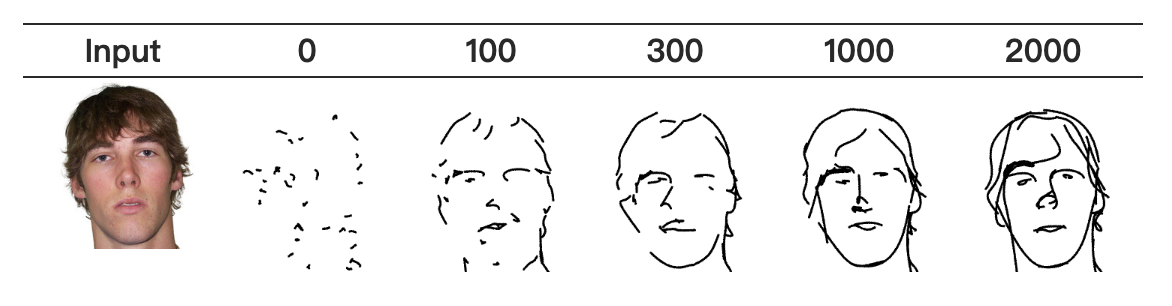
图7:优化迭代过程中的草图外观。
3.3 笔画初始化
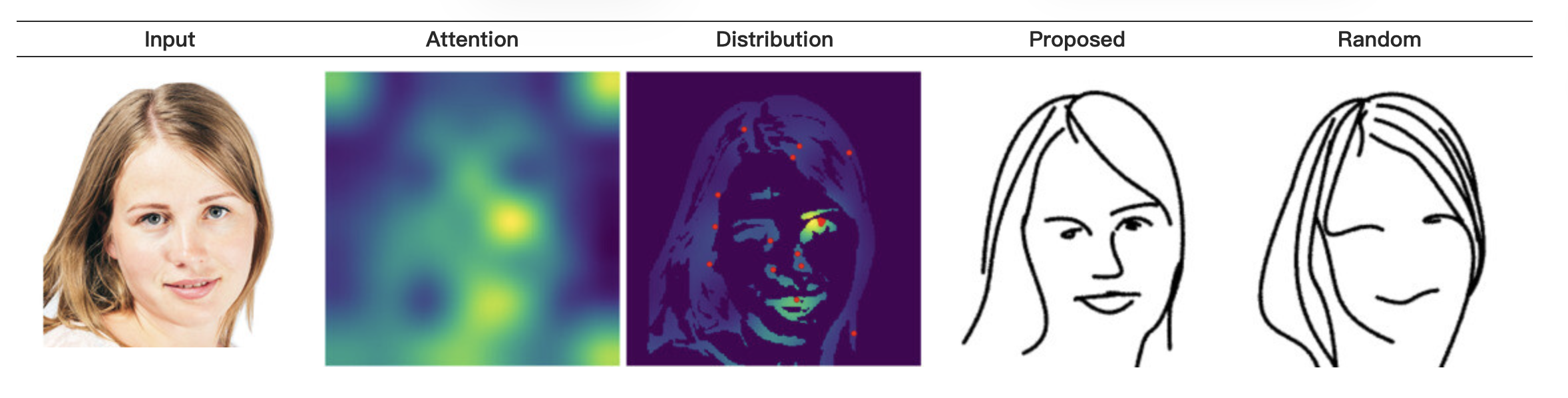
我们的目标函数高度非凸。因此,优化过程对初始化(即笔画的初始位置)非常敏感。在更高级别的抽象中这一点尤为重要——在这些级别上,必须巧妙地放置非常少的笔画来强调语义组件。例如,在图8(a)中,最后两列的草图使用了相同数量的笔画,然而,在“随机”初始化的情况下,更多的笔画被用于头发,而眼睛、鼻子和嘴巴是人脸的关键和显著特征。
为了提高对语义描述的收敛性,我们根据目标图像的显著区域放置初始笔画。我们使用了预训练的视觉变换器[22] CLIP的ViT-B/32模型,该模型使用自注意力机制对给定图像的补丁进行全局上下文建模,以捕捉有意义的特征。我们使用Chefer等人[7]最近的变换器可解释性方法,从自注意力头中提取相关性图,无需任何文本监督。
我们的最终分布图是通过将相关性图与使用XDoG[42]提取的图像边缘图相乘,然后进行softmax归一化得到的。XDoG用于加强笔画的形态定位,这是基于这样的假设:边缘在预测人们在哪里画线方面是有效的[19]。
图8(a)展示了这一过程。可以看出,我们的基于显著性的初始化对最终草图的质量贡献显著,优于随机初始化。
这种基于采样的方法也适用于提供结果的变异性。在我们的所有示例中,我们通常使用3个初始化,并自动选择产生最低损失的那一个(见图8(b))。我们将在补充材料中进一步分析初始化过程和变异性。
(a) 显著性引导初始化

(b) 最终草图的自动选择过程
图8:笔触初始化。 (a) 从左到右:输入图像、由CLIP ViT激活产生的显著性图、调整以符合图像边缘的最终分布图(红色为采样的初始笔触位置)、使用建议初始化过程生成的草图,以及使用随机初始化生成的草图。 (b) 三个不同初始化的结果,笔触数量相同。蓝色标记的草图产生了最低的损失值,因此将用作最终输出。

图9:我们的方法为不常见类别生成的草图。
4 结果
第4.1节提供定性评估。在第4.2节中,我们将我们的方法与所有在特定草图数据集上训练的现有图像到草图方法进行比较。在第4.3节中,我们对我们的方法能够产生可识别草图的能力进行了定量评估,测试了类别和实例识别。对于带有背景的图像,我们使用自动方法(U2-Net [33])来遮蔽它们的背景。我们在补充文件中提供了我们方法的进一步分析、额外结果以及与其他方法的扩展比较。
4.1 定性评估
我们的方法与传统草图方法不同,因为它不使用草图数据集进行训练,而是在CLIP的指导下进行优化。因此,我们的方法不受训练期间观察到的特定类别的限制,因为在任何阶段都没有引入类别定义。这使得我们的方法对各种输入具有鲁棒性,如图1和图9所示。
在图1和图3中,我们展示了我们的方法在不同抽象层次上生成草图的能力。随着笔触数量的减少,最小化损失的任务变得更加具有挑战性,迫使笔触捕捉对象的本质。例如,在图1中火烈鸟的抽象过程中,从16笔触到4笔触的过渡导致了眼睛、羽毛和脚等细节的移除,同时保持了火烈鸟的重要视觉特征,如一般的姿势、颈部和腿,这些是火烈鸟的标志性特征。
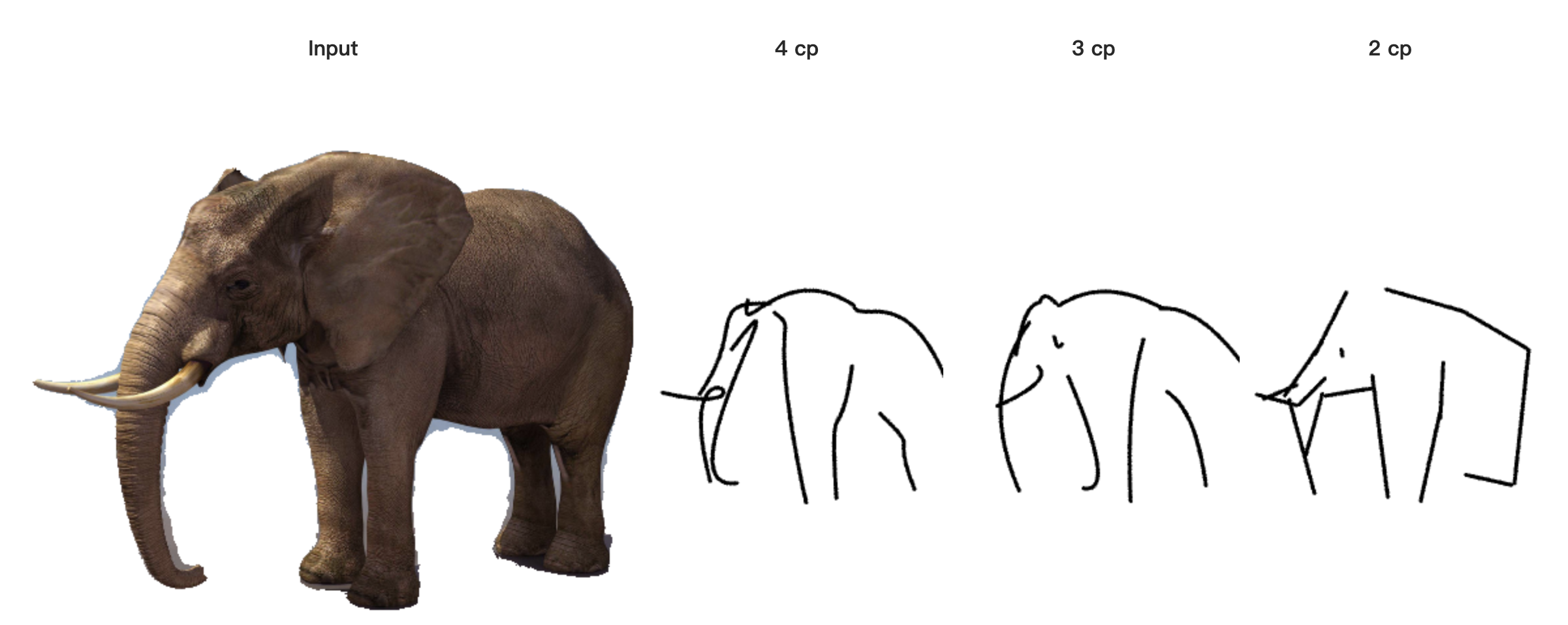
除了改变笔触的数量外,还可以通过改变笔触的粗细程度(图10(a))或在矢量笔触上使用画笔风格(图10(b))来实现不同的草图风格。
(a)改变曲线的度数


(b)编辑SVG中的画笔样式
图10:改变草图风格。(a)从左到右分别是使用具有4、3和2个控制点(cp)的Bézier曲线时,我们的方法产生的结果。我们可以看到这如何影响输出草图的风格。(b)使用Adobe Illustrator,马——铅笔羽毛,火烈鸟——干刷。
4.2与现有方法的比较
具有不同抽象层次的草图。
只有少数作品尝试在不同的抽象层次上勾勒物体。在图11中,我们与Muhammad等人[30]和Berger等人[3]进行了比较。Muhammad等人的结果展示了在两个简单输入——一只鞋和一把椅子上四种抽象层次(在没有他们的代码的情况下,结果直接从论文中获取)。我们使用32、16、8和4笔触产生四种抽象层次的草图。Muhammad等人的草图与图像的几何形状一致;但为了达到更高的抽象层次,他们只是从生成的草图中移除笔触,而不改变剩余的笔触。这可能会导致在更高的抽象层次上失去类级别的可识别性(最右边的草图)。这种方法是次优的,因为对于更少的笔触可能有更好的安排。我们的方法成功地产生了一个可识别的主体描绘,同时保留了其几何形状,即使在具有挑战性的4笔触情况下(最右边的草图)。
在图11的右下部分,我们与Berger等人[3]的方法进行了比较。他们的结果由作者提供,并展示了基于特定艺术家风格的两种抽象层次。我们分别使用64和8笔触来达到两种可比较的抽象层次,并在生成的草图上放置铅笔风格,以更好地适应艺术家的风格。如图所示,我们的方法在保持几何一致性的同时,仍然允许抽象。他们的结果更适合特定的风格,但只能用于面部,并且仅限于收集的数据集。
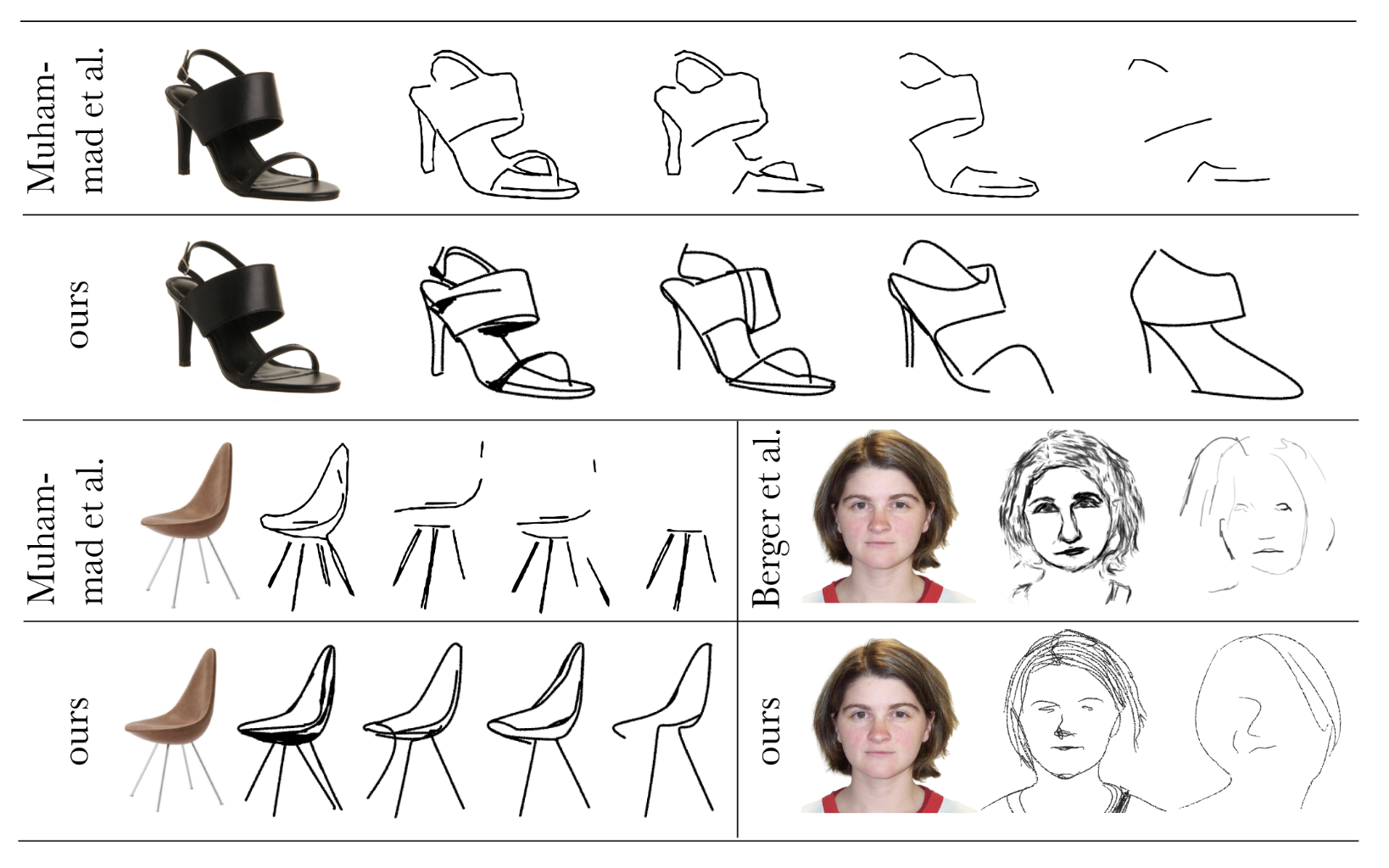
图11:抽象层次比较 — 顶部和左侧部分是与Muhammad等人[30]的比较。最左侧的列显示输入图像,接下来的四列显示不同的抽象层次。对于鞋子和椅子,我们的结果使用了32、16、8和4条曲线(从左到右)。右下部分是与Berger等人[3]的比较,我们使用64和8笔触来生成我们的草图。
照片-草图合成。
在图12中,我们展示了与表1中概述的五项工作的比较。Kampelmühler和Pinz[21](A)、Li等人[25](B)和Li等人[23](C)的结果是基于作者的实现和最佳实践生成的。由于SketchLattice[32](E)的公开实现缺乏,他们的结果直接从论文中获取。我们展示了Song等人[38](D)在鞋子图像上的草图,因为他们的方法只适用于鞋子和椅子。
这些方法中的每一种都定义了一个特定的目标,这影响了他们的数据集选择和最终输出风格。Li等人[23](C)的目标是类似边界的绘图,确实,与输入图像的几何一致性得到了实现,捕捉了显著的轮廓。其他方法旨在产生非专家的人类风格草图,确实,合成的草图表现出“涂鸦式”的风格。此外,这些方法学习了高度抽象的概念(如突出眼睛),同时保持与输入对象的几何形状的一定关系。
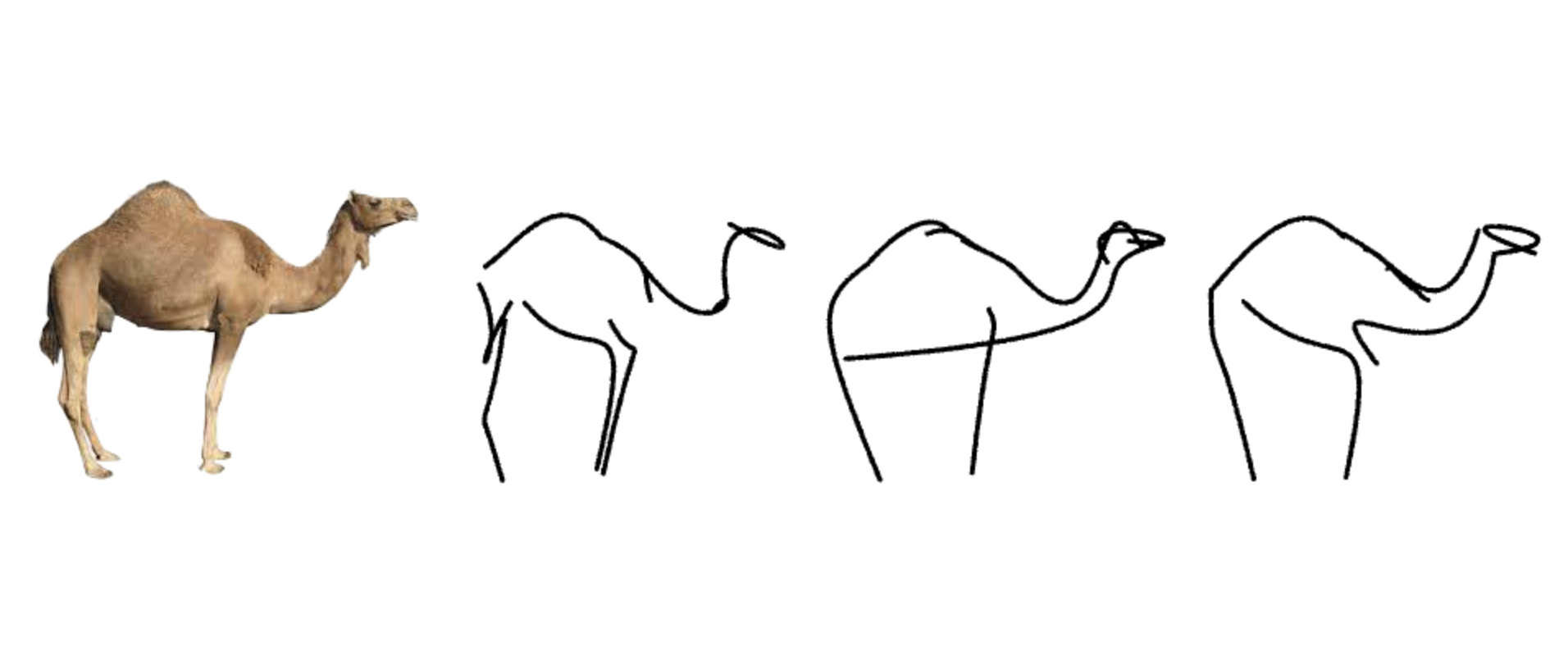
每种方法都实现了它们各自的目标,但我们希望强调我们方法的特定优势。首先,上述所有方法都依赖于草图数据,这意味着它们只能用于训练中观察到的风格和抽象层次。使用我们的框架,我们可以处理所有类别的图像,并通过改变笔触的数量来产生不同抽象层次的草图。虽然每种方法都可以用新数据集重新训练,但这既不方便也不实用,并且取决于这些数据集的可用性。其次,虽然每种方法倾向于更语义或更几何的绘图风格,但我们的方法可以提供两者。例如,我们的方法没有像(C)那样完美地对齐马的腿,但它以最小的方式捕捉了马的运动。
在图13中,我们与CLIPDraw[11]进行了比较。CLIPDraw的文本输入被替换为目标图像。这是可能的,因为CLIP将文本和图像编码到相同的潜在空间。为了提供可比较的可视化,我们以与我们定义笔触相同的方式约束CLIPDraw的输出基元。如图所示,尽管使用CLIPDraw可以识别主题的部分,但由于没有几何基础与图像相对应,整体结构被破坏。关于CLIPDraw结合文本和颜色的进一步比较可以在补充文件中找到。
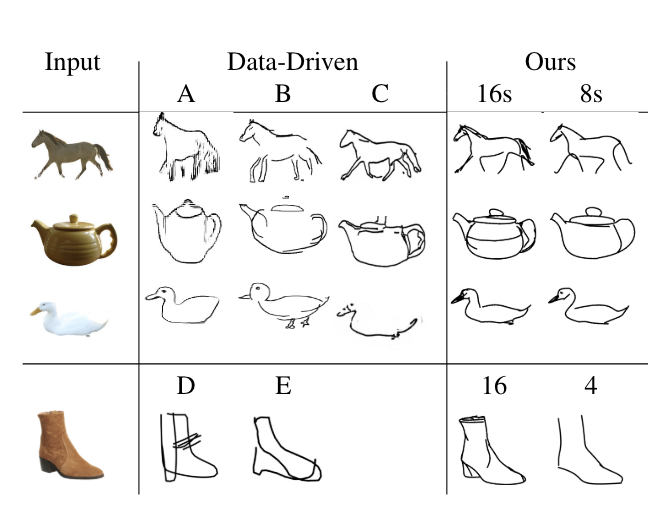
图12:与现有图像到草图作品的比较 — 左边第一列显示了输入图像。展示的方法有:(A) Kampelmühler和Pinz [21],(B) Li等人 [25],© Li等人 [23] (D) Song等人 [38],(E) SketchLattice [32]。
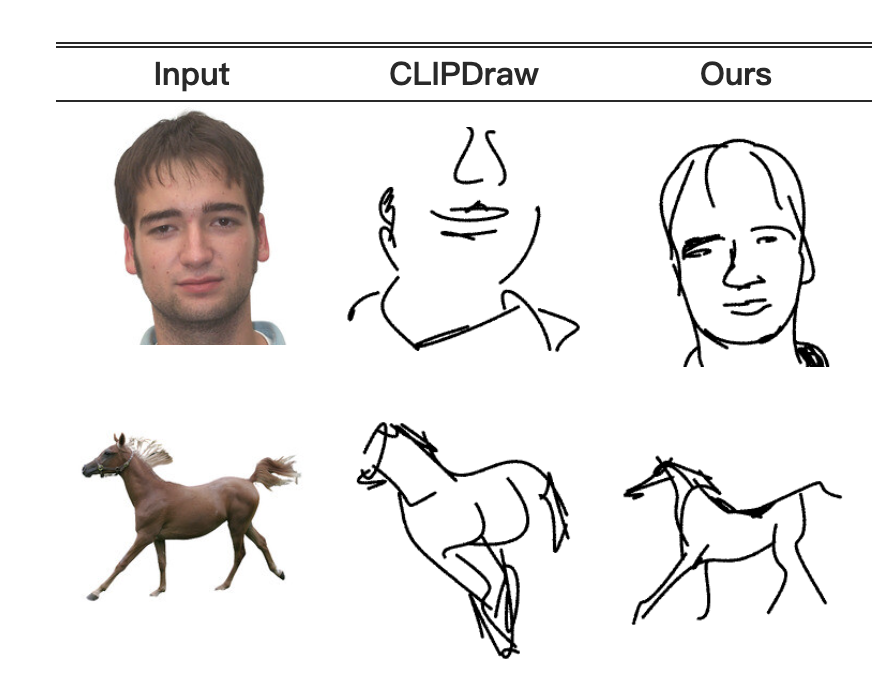
图13:与CLIPDraw [11]的比较。所有草图都是使用16笔画制作的。
4.3 定量评估
我们进行了一项用户研究,共有121名参与者,以评估我们的方法在不同抽象水平下生成的草图在类别级和实例级可识别性。此外,与之前的图像到草图作品类似 [21, 38, 30],我们也使用预训练的分类器网络来评估我们的方法生成的草图的类别级可识别性。
用户研究
我们从SketchyCOCO数据集 [13]中选择了五个流行的动物类别,并随机抽取每个类别的五张图像。我们为每张图像合成四个不同抽象水平的草图,分别使用4、8、16和32笔画。我们比较了识别率与Kampelmühler和Pinz [21]以及Li等人 [23]的两种最新的照片到草图合成方法。草图的抽象水平与方法的能力相适应。
每位参与者被随机展示了一种方法的草图。为了检查类别级识别,参与者被要求选择正确的类别文本描述以及四个混淆类别和“无”选项。对于实例级识别实验,干扰项是同一对象类别的图像。表2显示了用户研究中获得的平均识别率。类别级和实例级的可识别性都与抽象水平成反比。在四笔画时,我们的草图在类别级几乎无法识别(36%),这说明了我们方法的“临界点”。在八笔画及以上时,实例级和类别级的识别率都很高。Li等人 [23]在实例级展示了完全的识别,这是可以理解的,因为草图是基于轮廓的,而不是抽象的。在16和32笔画时,我们达到了可比的识别率,即使在使用仅八笔画的高抽象水平时,我们也实现了95%的实例级可识别性。Kampelmühler和Pinz的草图更抽象,这解释了他们在实例级和类别级的低准确率。
草图分类器
我们使用了两种分类器来评估合成的草图;一种是Kampelmühler和Pinz [21]在Sketchy-Database [37]上训练的ResNet34分类器,包含125个类别,另一种是使用定义为“一个类名的草图”的文本提示的CLIP ViT-B/32零样本分类器。请注意,这不是我们用于训练的CLIP模型。表3比较了基于SketchyCOCO数据集 [13]中随机选择的200张图像的草图分类器识别准确率,这些图像来自10个类别。还计算了SketchyCOCO数据集中人类草图的识别准确率作为基线。Kampelmühler和Pinz的方法在ResNet34分类器上获得了最高分,可能是因为他们在训练时使用了相同的模型和数据集。尽管存在分布差异,我们的方法在该分类器下仍然取得了良好的识别率。在CLIP分类器上,我们的方法在16笔画时实现了78%的高准确率,在32笔画时实现了91%的高准确率。更多细节和分析请参考补充材料。
表2:用户研究结果 — 平均识别率。(A) Kampelmühler和Pinz [21],(B) Li等人 [23]。
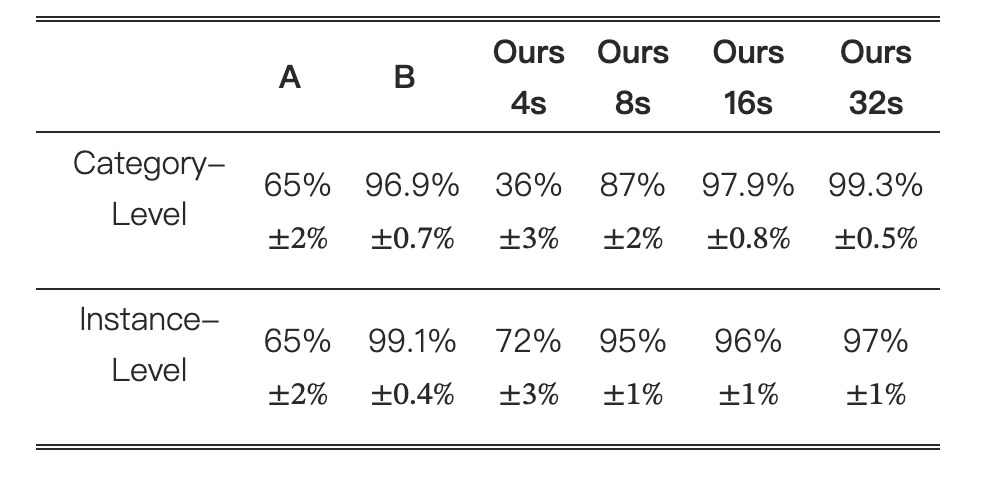
表3:使用ResNet34和CLIP ViT-B/32在来自10个类别的200张草图上计算的Top-1和Top-3草图识别准确率。(A) Kampelmühler和Pinz [21],(B) Li等人 [23]。
5 限制
对于带有背景的图像,我们的方法在更高的抽象水平上性能会降低。这一限制可以通过使用自动遮罩来解决。然而,一个潜在的发展是将这样的补救措施包含在损失函数中。此外,我们的草图不是按顺序创建的,所有笔画都是同时优化的,这与传统的草图方式不同。而且,为了达到所需的抽象水平,必须预先确定笔画的数量。另一个可能的扩展是将这个数量作为一个可学习的参数,因为不同的图像可能需要不同数量的笔画才能达到类似的抽象水平。
6 结论
我们提出了一种照片到草图合成的方法,能够产生不同抽象水平的草图,而无需在特定的草图数据集上进行训练。我们的方法可以推广到各种类别,并能够应对具有挑战性的抽象水平,同时保持允许实例级和类别级识别的语义视觉线索。















 678
678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









