







 本文介绍了一种自主人工智能研究代理,旨在解决基于大型文本语料库的复杂问题,特别是涉及深度多跳推理的KBQA。通过对比不同的代理方法,如ReAct和Self-Ask,作者探讨了如何实现更准确的推理和答案生成。研究代理模仿人类研究过程,通过迭代提问和答案验证来逐步接近最终答案,减少了幻觉和错误的发生。
本文介绍了一种自主人工智能研究代理,旨在解决基于大型文本语料库的复杂问题,特别是涉及深度多跳推理的KBQA。通过对比不同的代理方法,如ReAct和Self-Ask,作者探讨了如何实现更准确的推理和答案生成。研究代理模仿人类研究过程,通过迭代提问和答案验证来逐步接近最终答案,减少了幻觉和错误的发生。
原文地址:https://towardsdatascience.com/the-research-agent-4ef8e6f1b741
2023 年 8 月 29 日
问题简介
在2021年,开始应对基于大量文本回答问题的挑战。在预训练transformers之前的时代,这个问题很难破解。
人工智能和大型预训练transformers的快速进步正在从根本上深刻地改变技术世界。
应对基于大量文本回答问题的总体思路是制作个可以处理任何复杂知识库的自主研究代理。
研究代理
在这里,我将讨论一个自主人工智能研究代理的设计和实现,它可以解决具有深度推理能力的多跳KBQA问题。
需要研究代理的原因
向 ChatGPT 询问了几个有关《摩诃婆罗多》的问题。我对一些问题得到了很好的答案。然而,他们大多数人缺乏严谨性。这是预期的。GPT 在通用数据集上进行训练。它可以很好地理解和解释自然语言。它也可以很好地推理。然而,它并不是任何特定领域的专家。因此,虽然它可能对《摩诃婆罗多》有一些了解,但它可能不会给出经过深入研究的答案。有时 GPT 可能根本没有任何答案。在这些情况下,它要么谦虚地拒绝回答问题,要么自信地编造问题(幻觉)。
实现 KBQA 的第二个最明显的方法是使用检索 QA 提示。这就是 LangChain 开始变得非常有用的地方。
检索质量保证
对于那些不熟悉 LangChain 库的人来说,这是在代码中使用 GPT 等 LLM 的最佳方法之一。这是使用 LangChain 的 KBQA 实现。
总而言之,以下是在任何文档主体上实现 KBQA 的步骤:
- 将知识库拆分为文本块。
- 为每个块创建数字表示(嵌入)并将其保存到矢量数据库中。
如果您的数据是静态的,则步骤 1 和 2 是一次性的工作。 - 使用用户对此数据库的查询运行语义搜索并获取相关文本块。
- 将这些文本块与用户的问题一起发送给法学硕士,并要求他们回答。
这是此过程的图形表示。
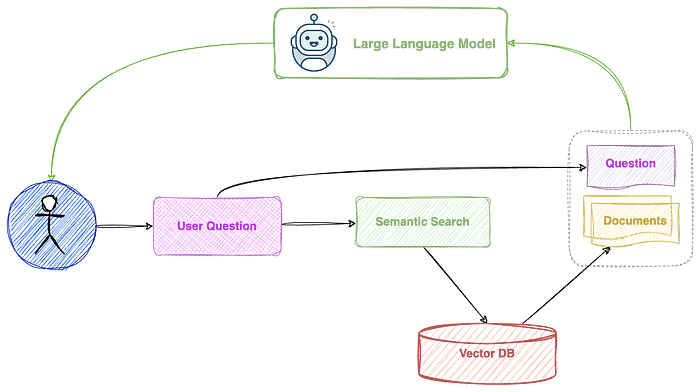
这种方法非常适合解决简单且是事实的知识库上的简单问题。然而,它不适用于更复杂的知识库和需要更深入、多跳推理的更复杂的问题。多跳推理是指采取多个步骤的逻辑或上下文推理来得出问题的结论或答案的过程。
此外,LLMs可以在一篇提示中咀嚼的文本长度受到限制。当然,您可以一次发送一份文件,然后在每次通话时“完善”或“减少”答案。然而,这种方法不允许复杂的“多跳”推理。在某些情况下,使用“优化”或“减少”方法的结果比简单地将所有文档填充到单个提示中要好,但差距并不大。
对于复杂的知识库,用户的问题本身可能不足以找到所有可以帮助LLM得出准确答案的相关文档。例如:
阿朱那是谁?
这是一个简单的问题,可以在有限的上下文中回答。然而,有以下问题:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1296
1296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









