









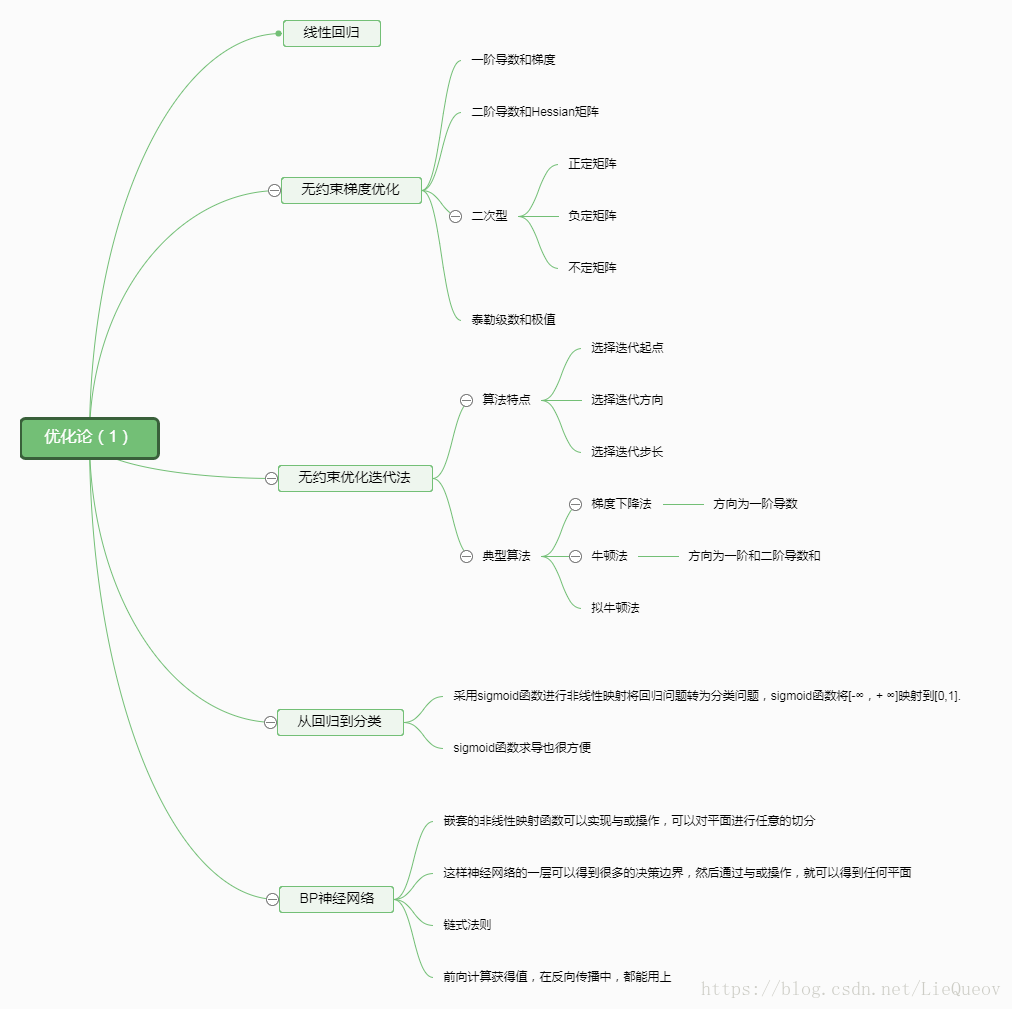
一、思维导图
二、补充笔记
1、梯度的定义
$$\nabla f(x) = \frac{{\partial f(x)}}{{\partial x}} = \left[ \begin{array}{l}\frac{{\partial f(x)}}{{\partial {x_1}}}\\{\rm{ }} \vdots \\\frac{{\partial f(x)}}{{\partial {x_n}}}\end{array} \right]$$
2、Hessian矩阵定义
$${\nabla ^2}f(x) = \frac{{\partial f(x)}}{{\partial x}} = \left[ \begin{array}{l}\frac{{{\partial ^2}f(x)}}{{\partial x_1^2}} \cdots \frac{{{\partial ^2}f(x)}}{{\partial {x_1}\partial {x_n}}}\\{\rm{ }} \vdots {\rm{ }} \ddots {\rm{ }} \vdots \\\frac{{{\partial ^2}f(x)}}{{\partial {x_n}\partial {x_1}}} \cdots \frac{{{\partial ^2}f(x)}}{{\partial x_n^2}}\end{array} \right]$$
3、正定矩阵
给定对称矩阵$$A \in {R^{n \times n}}$$ 如果对于所有的$$x \in {R^n}$$ 有$${x^T}Ax \ge 0$$为半正定矩阵 特征值$$\lambda (A) \ge 0$$ 如$$x \ne 0$$ 有$${x^T}Ax > 0$$ 则为正定矩阵。同样可以定义负定矩阵和不定矩阵。
四、常见梯度求解
向量a和x无关,那么$$\nabla ({a^T}x) = a$$ $${\nabla ^2}({a^T}x) = 0$$
对称矩阵A和x无关,那么$$\nabla ({x^T}Ax) = 2Ax$$ $${\nabla ^2}({x^T}Ax) = 2A$$
五、从泰勒级数看待极值问题。
通过泰勒级数和极小值的定义进行判断极值点。若极值点一阶导数等于0,二阶导数大于0,为极小值。当然,如果二阶导数等于0,再判断三阶导数。
而对于向量形式的泰勒级数而言,当梯度为0时,根据Hessian矩阵的正定性来判断极值点,如果Hessian矩阵为不定矩阵,那么此点为鞍点。
六、梯度下降法
梯度下降法是一个迭代优化方法,每一次迭代都在逼近最优值(以最小值为例)。一般分为设置初始下降点,选取下降方向,确定下降步长。梯度下降法的方向选择为负梯度的方向。
以标量为例子,如果第一步计算f(x0),那么下一步计算f(x0+αd)。其中为初始点x0,α为步长,d为方向。根据只保留了1阶导数的泰勒级数f(x0+αd)=f(x0)+f'(x0)αd,那么就要保证无论的正负f'(x0)αd<=0。那么d=-f'(x0)。那么如果为矢量,则一阶导数就换成了梯度。
牛顿法中取的方向是根据保留了2阶导数的泰勒级数得到的。
拟牛顿法,因为牛顿法需要求解Hessian矩阵的逆,在实际的工程中,非常难求。拟牛顿法使用一阶导数逼近二阶导数,也就是通过梯度去逼近Hessian矩阵。
步长选择可以使用Armijo条件进行判断。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









