










第一章:人工智能之不同数据类型及其特点梳理
第二章:自然语言处理(NLP):文本向量化从文字到数字的原理
第三章:循环神经网络RNN:理解 RNN的工作机制与应用场景(附代码)
第四章:循环神经网络RNN、LSTM以及GRU 对比(附代码)
第五章:理解Seq2Seq的工作机制与应用场景中英互译(附代码)
第六章:深度学习架构Seq2Seq-添加并理解注意力机制(一)
第七章:深度学习架构Seq2Seq-添加并理解注意力机制(二)
第八章:深度学习模型Transformer初步认识整体架构
第九章:深度学习模型Transformer核心组件—自注意力机制
第十章:理解梯度下降、链式法则、梯度消失/爆炸
第十一章:Transformer核心组件—残差连接与层归一化
第十二章:Transformer核心组件—位置编码
第十三章:Transformer核心组件—前馈网络FFN
第十四章:深度学习模型Transformer 手写核心架构一
第十五章:深度学习模型Transformer 手写核心架构二
一、总体思路
实现 Transformer模型 的核心架构,包含编码器(Encoder)、解码器(Decoder)、多头注意力(MultiHeadedAttention)、位置编码(PositionalEncoding)等关键组件,支持动态掩码生成和序列到序列(Seq2Seq)任务。主要特点如下:
- 模块化设计:通过类封装编码器、解码器、注意力等模块,结构清晰。
- 动态掩码:支持输入填充掩码(
src_mask)和解码器未来词掩码(subsequent_mask)。 - 残差连接与层归一化:每个子层(注意力、前馈)后均包含残差连接和层归一化。
- 位置编码:通过正弦/余弦函数为输入序列注入位置信息。
- 可扩展性:支持自定义模型参数(如层数、维度、头数)。
二、实现步骤分解
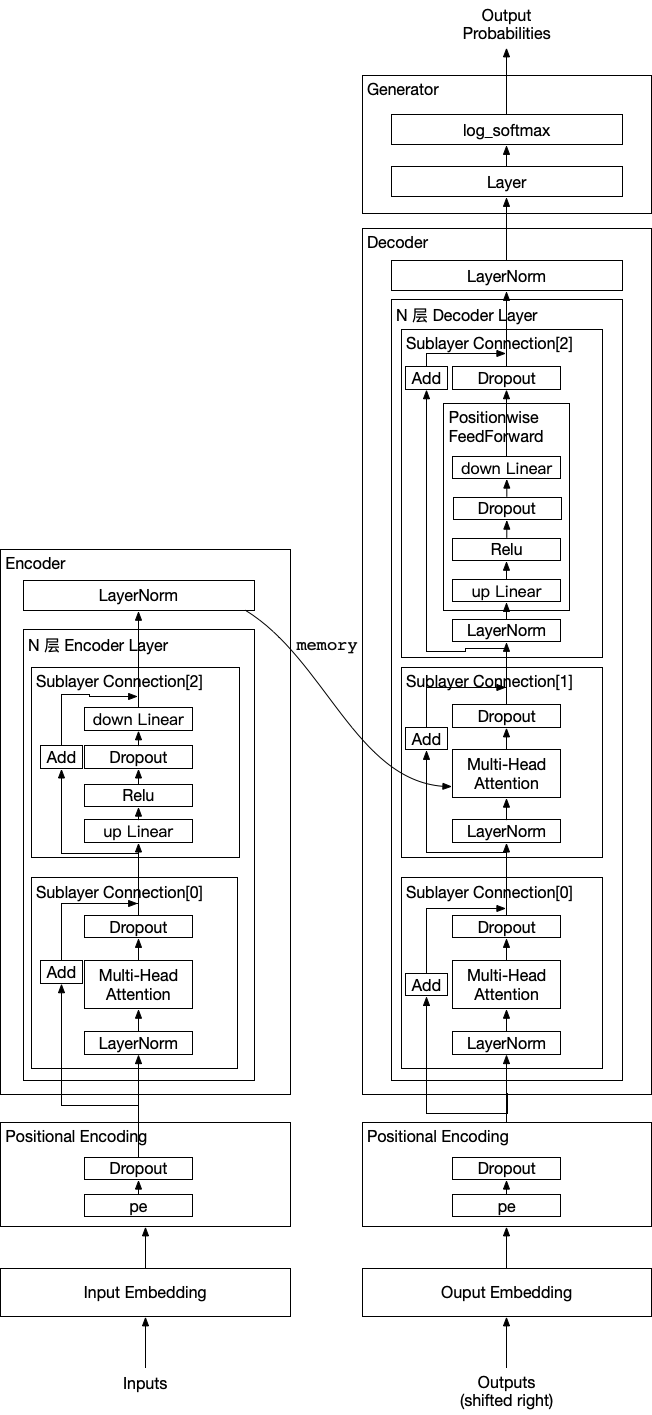
以下是代码实现Transformer的关键步骤:
2.1. 基础组件定义
- 嵌入层(Embedding):将词索引映射为向量,并缩放以匹配位置编码的尺度。
- 位置编码(PositionalEncoding):生成固定位置向量,与嵌入向量相加。
- 层归一化(LayerNorm):自定义层归一化,稳定训练过程。
- 前馈网络(PositionwiseFeedForward):两层线性变换,中间使用ReLU激活。
2.2. 注意力机制实现
- 缩放点积注意力(attention函数):计算查询、键、值的注意力权重。
- 多头注意力(MultiHeadedAttention):
- 将输入拆分为多头,并行计算注意力。
- 合并多头结果并通过线性层输出。
2.3. 编码器与解码器构建
- 编码器(Encoder):
- 由
N个编码器层堆叠而成。 - 每层包含自注意力(Self-Attention)和前馈网络。
- 残差连接和层归一化封装在
SublayerConnection中。
- 由
- 解码器(Decoder):
- 由
N个解码器层堆叠而成。 - 每层包含自注意力、编码器-解码器注意力(交叉注意力)和前馈网络。
- 使用
subsequent_mask屏蔽未来词。
- 由
2.4. 模型整合与生成器
- EncoderDecoder类:整合编码器、解码器、嵌入层和生成器。
- Generator类:将解码器输出映射为目标词表的概率分布(
log_softmax)。
2.5. 模型实例化与推理
- make_model函数:组合所有组件生成完整Transformer模型。
- 主程序示例:
- 输入序列编码(
encode)生成中间表示(memory)。 - 自回归解码(
decode),逐词生成输出序列(如翻译结果)。
- 输入序列编码(
三、Encoder-Decoder
import os
import torch
from torch import nn
from torch.nn import functional as F
from torch.nn.functional import log_softmax, pad
import math
import time
import copy
from torch.optim.lr_scheduler import LambdaLR
import pandas as pd
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import warnings
class EncoderDecoder(nn.Module):
"""
定义一个公共的 Encoder-Decoder 架构的框架
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
"""
初始化方法:
- encoder: 编码器(对象),是 Encoder 的一个实例
- decoder: 解码器(对象),是 Decoder 的一个实例
- src_embed: 输入预处理(对象),是 Sequential(Embedding, PositionalEncoding) 的一个实例
- tgt_embed: 输出侧的输入预处理(对象),是 Sequential(Embedding, PositionalEncoding) 的一个实例
- generator: 生成处理(对象),是 Generator 的一个实例
"""
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"""
输入并处理带掩码的输入和输出序列
"""
# 1,通过 encoder 获取中间表达
memory = self.encode(src, src_mask)
# 2,通过 decoder 获取最终结果
result = self.decode(memory, src_mask, tgt, tgt_mask)
return result
def encode(self, src, src_mask):
"""
编码器处理过程
src:[batch_size, seq_len]
"""
# 1,把输入的 id序列 变为向量并且加入位置编码
# src_embed_pos 形状 [batch_size, seq_len, d_model]
src_embed_pos = self.src_embed(src)
# 2,通过 encoder 获取中间表达
memory = self.encoder(src_embed_pos, src_mask)
return memory
def decode(self, memory, src_mask, tgt, tgt_mask):
"""
解码过程
"""
# 1,把 已经生成了的上文 id序列 变为 向量,再加上位置编码
# tgt_embed_pos 形状 [batch_size, seq_len, d_model]
tgt_embed_pos = self.tgt_embed(tgt)
# 2,通过 decoder 进行加码
result = self.decoder(tgt_embed_pos, memory, src_mask, tgt_mask)
return result
这段代码定义 EncoderDecoder 的类,它是基于PyTorch的 nn.Module 类构建的,用于实现一个通用的编码器-解码器架构。
主要功能
-
初始化 (
__init__方法):- 接受并初始化五个主要组件:编码器 (
encoder)、解码器 (decoder)、源输入嵌入层 (src_embed)、目标输入嵌入层 (tgt_embed) 和生成器 (generator)。 src_embed和tgt_embed都包含了词嵌入和位置编码步骤,以将输入的词ID转换为向量表示,并添加位置信息以便模型理解词序。
- 接受并初始化五个主要组件:编码器 (
-
前向传播 (
forward方法):- 处理带掩码的输入和输出序列。
- 首先调用
encode方法对源序列进行编码,得到中间表示memory。 - 然后调用
decode方法,结合中间表示memory和目标序列,生成最终输出结果。
-
编码 (
encode方法):- 对源序列进行预处理(包括词嵌入和位置编码),然后通过编码器获取中间表示
memory。 memory是编码器对输入序列的理解,它会被传递给解码器以帮助生成目标序列。
- 对源序列进行预处理(包括词嵌入和位置编码),然后通过编码器获取中间表示
-
解码 (
decode方法):- 对目标序列进行预处理(同样包含词嵌入和位置编码),然后与编码器的中间表示
memory结合,通过解码器生成最终输出。 - 解码器利用
memory来关注源序列的相关部分,从而指导目标序列的生成过程。
- 对目标序列进行预处理(同样包含词嵌入和位置编码),然后与编码器的中间表示
组件说明
- 编码器 (
encoder):负责将输入序列转换为一系列隐藏状态,这些隐藏状态捕捉了输入序列的所有信息。 - 解码器 (
decoder):逐步生成输出序列,每个时间步都会参考编码器提供的隐藏状态以及之前生成的部分输出。 - 源输入嵌入层 (
src_embed) 和 目标输入嵌入层 (tgt_embed):将输入的词ID映射为固定维度的向量,并添加位置编码,使模型能够理解输入序列中词的顺序。 - 生成器 (
generator):用于从解码器的输出中生成最终的预测结果(例如,在机器翻译任务中,将解码器的输出转换为目标语言的词)。
四、Generator
class Generator(nn.Module):
"""
把向量维度转换为词表长度,输出每个词的概率
"""
def __init__(self, d_model, dict_len):
"""
初始化
d_model:模型的向量维度,比如:512
dict_len:词表长度,比如:2万
"""
super(Generator, self).__init__()
self.proj = nn.Linear(in_features=d_model, out_features=dict_len)
def forward(self, x):
"""
前向映射过程
"""
# 1,特征映射(最后一个维度看作是特征维度)
x = self.proj(x)
# log_softmax 确保了即使输入中有极端值,log_softmax 仍然能够提供稳定的数值输出,并且不会导致数值溢出或下溢的问题。
# softmax 输出的是概率值,范围在 (0, 1) 之间;而 log_softmax 输出的是负数。
# 参数说明
# x: 输入张量,通常是模型的最后一层输出。
# dim: 指定在哪个维度上应用 log-softmax。dim=-1 表示在最后一个维度上进行操作。对于二维张量(如批量大小 × 类别数),这意味着它会沿着类别维度计算 log-softmax。
return log_softmax(x, dim=-1)
这段代码定义 Generator 的类,它继承自 PyTorch 的 nn.Module 类。该类的主要功能是将模型的输出向量映射到词汇表大小的概率分布上,以便于生成下一个词或字符的概率预测。
主要功能
-
初始化 (
__init__方法):- 接受两个参数:
d_model和dict_len。d_model:输入向量的维度,即模型中使用的特征维度大小,例如512。dict_len:目标词汇表的长度,即模型可以生成的不同词的数量,例如20000。
- 初始化一个线性层
proj,用于将输入的高维向量映射到词汇表长度的向量上。这一步实现了从模型内部表示到词汇表概率分布的转换。
- 接受两个参数:
-
前向传播 (
forward方法):- 输入张量
x经过线性层proj的变换,将其特征维度从d_model映射到dict_len。 - 使用
log_softmax函数对输出进行归一化处理,确保每个位置上的输出是一个有效的概率分布。log_softmax在数值稳定性和计算效率方面优于直接使用softmax后再取对数的方法,特别是在处理极端值时能够避免数值溢出或下溢的问题。 - 最终返回每个词在词汇表中的概率分布,其中
dim=-1指定操作是在最后一个维度上进行的,这个维度通常对应着模型预测的各个类别(在这个场景中即为词汇表中的词)。
- 输入张量
组件说明
- 线性层 (
proj):通过线性变换将输入的高维向量映射到与词汇表大小相匹配的维度上。这是从模型内部表示到最终输出空间的关键步骤。 - Log Softmax:用于将线性层的输出转换为概率分布,并且采用对数形式以提高数值稳定性。这对于训练过程中的损失计算(如交叉熵损失)特别有用,因为它可以直接与负对数似然损失函数结合使用,简化了计算流程。
五、clones
def clones(module, N):
"""
定义一个层的复制函数
- nn.ModuleList
"""
# nn.ModuleList 是 PyTorch 中的一个容器模块,用于存储和管理多个 nn.Module 子模块(如层或网络组件)。
# 它类似于 Python 的内置列表,但专门为包含 nn.Module 对象而设计,并且能够正确处理这些模块的参数注册、优化器更新等。
# 主要特点:
# 参数注册:会自动将添加到其中的所有 nn.Module 对象注册为子模块。
# 这意味着它们的参数会被正确地包含在模型的参数集合中,可以被优化器访问和更新。
# 状态保存:当保存和加载模型的状态字典时,nn.ModuleList 内部的所有子模块及其参数也会被正确地保存和恢复。
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
这段代码定义 clones 的函数,其主要功能是创建一个给定模块的多个副本,并将这些副本存储在 nn.ModuleList 中。
主要功能
-
复制模块:
- 函数接受两个参数:
module和N。module: 需要被复制的nn.Module对象。它可以是一个单独的层、一个复杂的子网络或者任何实现了nn.Module接口的对象。N: 需要创建的该模块的副本数量。
- 函数接受两个参数:
-
使用
copy.deepcopy进行深拷贝:- 使用
copy.deepcopy(module)来确保每个副本都是独立的,避免所有副本共享相同的权重或其他内部状态。这对于构建如多层堆栈或多头机制等结构至关重要,因为每一层或每个头都需要有自己的可训练参数。
- 使用
-
存储到
nn.ModuleList:- 将所有的副本存储在一个
nn.ModuleList容器中。nn.ModuleList是 PyTorch 提供的一种特殊列表类型,专门用于管理神经网络中的模块集合。 nn.ModuleList不仅可以像普通列表一样访问和操作其中的元素,还能自动处理其包含的所有模块的参数注册和优化器更新等问题。这意味着当你调用模型的.parameters()方法时,nn.ModuleList内的所有子模块的参数都会被正确地包含进来。
- 将所有的副本存储在一个
六、Encoder
class Encoder(nn.Module):
"""
第一个 Encoder,其由N个encoder layer 构成~
"""
def __init__(self, encoderLayer, N):
super(Encoder, self).__init__()
# 克隆 N 个层
# layer 是 EncoderLayer 的一个实例
self.layers = clones(encoderLayer, N)
# 定义一个 norm 层
self.norm = LayerNorm(encoderLayer.size)
def forward(self, x, mask):
"""
传入x及其mask,通过N层encoder layer 处理
x 形状 [batch_size, seq_len, d_model]
mask: pad_mask 消除 pad 的影响
"""
# 经历 N 层处理
for encoderLayer in self.layers:
x = encoderLayer(x, mask)
# 返回前,做一次 Norm 处理
return self.norm(x)
这段代码定义 Encoder 的类,继承自 PyTorch 的 nn.Module 类。该类实现了一个由多个编码层(encoderLayer)组成的编码器模块,它通过堆叠多个相同的编码层,并在最终输出前进行一次层归一化(Layer Normalization),来增强模型的表达能力和训练稳定性。
主要功能
-
初始化 (
__init__方法):- 接受两个参数:
encoderLayer和N。encoderLayer: 编码层的一个实例,实现了单个编码层逻辑的模块。N: 堆叠的编码层的数量。
- 使用
clones函数复制N个encoderLayer实例,并将它们存储在self.layers中。这允许构建深度为N的编码器堆栈,每个层都是独立但结构相同的。 - 初始化一个层归一化(
LayerNorm)层self.norm,其作用是对整个编码器的输出进行归一化处理,以稳定和加速训练过程。
- 接受两个参数:
-
前向传播 (
forward方法):- 输入张量
x及其对应的掩码mask被传递给每个编码层进行处理。 x的形状通常为[batch_size, seq_len, d_model],其中batch_size是批次大小,seq_len是序列长度,d_model是模型的维度。mask用于消除填充(padding)的影响,确保模型不会因为输入序列中存在填充部分而产生偏差。- 每个
encoderLayer都会对输入x进行处理,包括但不限于应用多头自注意力机制、前馈神经网络以及残差连接和归一化等步骤。 - 在所有编码层处理完毕后,对最终输出执行一次层归一化操作,并返回结果。
- 输入张量
七、LayerNorm
class LayerNorm(nn.Module):
"""
自定义 LayerNorm 层,该类继承自 PyTorch 的 nn.Module,这是所有神经网络模块的基类。
实现了 层归一化(Layer Normalization)。层归一化是一种用于神经网络中的正则化技术,
旨在通过规范化每一层的输入来稳定和加速训练过程
"""
def __init__(self, features, eps=1e-6):
"""
序列维度上做的
features: 特征的维度或个数
eps: epsilon 防止 标准差为零,用于防止除零错误,确保数值稳定性。
"""
super(LayerNorm, self).__init__()
# self.w 和 self.b:分别是可学习的缩放参数(权重)和平移参数(偏置)
# 使用全1来初始化 类似于 weight
# nn.Parameter 定义可学习的参数
# 创建一个形状由 features 指定、所有元素均为 1 的张量,并将其标记为模型的可训练参数。
# 这使得该张量能够参与模型的训练过程,包括梯度计算和参数更新。
self.w = nn.Parameter(torch.ones(features))
# 使用全0来初始化 类似与 bias
self.b = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
"""
前向传播方法
处理过程:
- 1,减去均值
- 2,除以标准差
- 3,可以在一定程度上还原
"""
# 分别计算输入张量 x 在最后一个维度上的均值和标准差。dim=-1 表示沿最后一个维度计算,
# keepdim=True 保持输出形状与输入相同,只是在指定维度上只有一个元素。
# 1, 计算均值
mean = x.mean(dim=-1, keepdim=True)
# 2, 计算标准差
std = x.std(dim=-1, keepdim=True)
# 归一化公式:将输入 x 减去其均值后除以标准差(加上小常数 eps 以保证数值稳定性),
# 然后乘以可学习的缩放参数 self.w 并加上平移参数 self.b。
# 最终输出是经过归一化和重新缩放、平移后的张量。
# 层归一化的意义:为了改善梯度传播,减少内部协变量偏移,从而加快模型的收敛速度并提高性能。
# 相比于批量归一化(Batch Normalization),层归一化不依赖于批次内的统计信息,
# 因此更适合处理序列数据(如自然语言处理任务中的句子或文档)以及较小的批次大小。
return self.w * (x - mean) / (std + self.eps) + self.b
这段代码定义 LayerNorm 的类,它继承自 PyTorch 的 nn.Module 类。该类实现了层归一化(Layer Normalization)。
主要功能
-
初始化 (
__init__方法):- 接受两个参数:
features和eps。features: 特征维度的数量,即需要进行归一化的最后一个维度的大小。eps: 一个小常数(默认为 1 × 10 − 6 1 \times 10^{-6} 1×10−6),用于防止除以零的标准差时出现数值不稳定的情况。
- 初始化两个可学习的参数
self.w和self.b:self.w: 可学习的缩放参数(权重),初始值为全1的张量,形状由features决定。self.b: 可学习的平移参数(偏置),初始值为全0的张量,形状同样由features决定。
- 这些参数允许模型在训练过程中调整归一化的尺度和偏移,以适应不同的数据分布。
- 接受两个参数:
-
前向传播 (
forward方法):- 输入张量
x经过以下步骤进行归一化处理:- 计算均值:使用
x.mean(dim=-1, keepdim=True)计算输入张量x在最后一个维度上的均值。dim=-1表示沿最后一个维度计算,keepdim=True确保输出形状与输入相同,只是在指定维度上只有一个元素。 - 计算标准差:使用
x.std(dim=-1, keepdim=True)计算输入张量x在最后一个维度上的标准差。 - 归一化公式:将输入
x减去其均值后除以标准差,并加上小常数eps以保证数值稳定性。然后乘以可学习的缩放参数self.w并加上平移参数self.b,得到最终的归一化结果。
- 计算均值:使用
- 输入张量
组件说明
nn.Parameter:用于定义可学习的参数,这些参数会被自动包含在模型的参数集合中,并且可以在训练过程中进行优化更新。mean和std:分别表示输入张量在最后一个维度上的均值和标准差,是层归一化的核心计算部分。eps:一个小常数,用于防止除零错误并确保数值稳定性。
八、SublayerConnection
class SublayerConnection(nn.Module):
"""
短接结构定义,
负责子层之间的连接,上一层的输出,在传递给下一层之前,需要经过本层的处理,add & norm
size:指定了输入张量最后一个维度的大小,即每个样本特征的数量。这与 LayerNorm 中的 features 参数对应。
dropout:指定了 dropout 的概率,默认情况下会将一部分输出随机置为零,以防止过拟合。
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
# 定义一个 norm 层
self.norm = LayerNorm(size)
# 定义一个 dropout 层
# 每一个元素有dropout的概率输出位0,没有输出为0的元素的值=xi/(1-dropout)
# 比如dropout=0.5,每一个元素有50%的概率输出位0,没有输出为0的元素的值=xi*2
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"""
x 形状 [batch_size, seq_len, embed_dim]
sublayer:是匿名函数 lambda x: self.self_attn(x, x, x, mask),调用sublayer()就会调用 MultiHeadedAttention 的一个实例
执行过程:
层归一化:首先对输入 x 进行层归一化处理,self.norm(x) 返回的是经过归一化的张量。
子层操作:然后将归一化后的张量传递给 sublayer 函数或模块,执行特定的子层操作。
这可以是任何形式的变换,比如在 Transformer 中的多头注意力机制或前馈神经网络。
dropout:对子层操作的结果应用 dropout,通过 self.dropout(...) 来实现。
这有助于防止过拟合,增加模型的泛化能力。
残差连接:最后,将原始输入 x 与经过上述处理后的结果相加,形成残差连接。
这样做的好处是可以缓解深层网络中的梯度消失问题,帮助信息更好地传递到更深的层。
残差连接的意义
残差连接的基本思想是直接将输入添加到输出上,形成跳跃连接。这样做有几个优点:
缓解梯度消失:在深度网络中,随着层数的增加,反向传播时梯度可能会变得越来越小,导致难以更新前面层的权重。残差连接可以让梯度更容易地向前传递,从而改善了训练效果。
促进信息流动:即使某些层学到了不重要的变换,原始输入仍然可以通过残差连接直接传递到后续层,确保重要信息不会丢失。
"""
return x + self.dropout(sublayer(self.norm(x)))
这段代码定义 SublayerConnection 的类,它继承自 PyTorch 的 nn.Module 类。该类实现了 Transformer 模型中的子层连接机制(包括层归一化、Dropout 和残差连接),用于处理编码器和解码器中各子层之间的连接。
主要功能
-
初始化 (
__init__方法):- 接受两个参数:
size和dropout。size: 输入张量最后一个维度的大小,对应于特征的数量。这个参数用于初始化层归一化(LayerNorm)。dropout: Dropout 的概率,用于防止过拟合。在前向传播过程中,部分输出会被随机置为零,以增加模型的鲁棒性。
- 初始化一个层归一化层
self.norm,用于对输入进行标准化处理,确保每一层的输入具有稳定的分布。 - 初始化一个 Dropout 层
self.dropout,用于在子层操作后应用 Dropout,进一步增强模型的泛化能力。
- 接受两个参数:
-
前向传播 (
forward方法):- 输入张量
x及其对应的子层操作sublayer被传递给该方法。 x的形状通常为[batch_size, seq_len, embed_dim],其中batch_size是批次大小,seq_len是序列长度,embed_dim是嵌入维度。- 执行过程如下:
- 层归一化:首先对输入
x进行层归一化处理,使用self.norm(x)来标准化输入。 - 子层操作:将归一化后的张量传递给
sublayer函数或模块,执行特定的子层操作(例如多头注意力机制或前馈神经网络)。 - Dropout:对子层操作的结果应用 Dropout,通过
self.dropout(...)实现,以防止过拟合并增加模型的泛化能力。 - 残差连接:最后,将原始输入
x与经过上述处理后的结果相加,形成残差连接。这有助于缓解深层网络中的梯度消失问题,帮助信息更好地传递到更深的层。
- 层归一化:首先对输入
- 输入张量
九、EncoderLayer
class EncoderLayer(nn.Module):
"""
定义一个Encoder Layer
"""
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
# self_attn:MultiHeadedAttention 实例,多头自注意力机制的实例,用于计算输入序列中的注意力分布。
self.self_attn = self_attn
# feed_forward:PositionwiseFeedForward 实例,前馈神经网络的实例,通常是一个简单的两层全连接网络。
self.feed_forward = feed_forward
# self.sublayer_conns:创建了两个 SublayerConnection 实例,用于在自注意力层和前馈层之后添加残差连接和层归一化。
# 这里使用了 clones 函数来复制相同的配置两次,分别应用于自注意力层和前馈层1。
# dropout:指定了 dropout 的概率,默认情况下会将一部分输出随机置为零,以防止过拟合。
self.sublayer_conns = clones(SublayerConnection(size, dropout), 2)
# size:指定了输入张量最后一个维度的大小,即每个样本特征的数量。
self.size = size
def forward(self, x, mask):
"""
encoder layer 的执行过程
x 的形状 [batch_size, seq_len, d_model]
"""
# 1,先计算多头注意力
# 使用 lambda 表达式定义了一个匿名函数,该函数接收 x 并返回经过自注意力机制处理后的结果。
x = self.sublayer_conns[0](x, lambda x: self.self_attn(x, x, x, mask))
# 2,再做 前馈处理
return self.sublayer_conns[1](x, self.feed_forward)
这段代码定义名为 EncoderLayer 的类,它继承自 PyTorch 的 nn.Module 类。该类实现了一个编码器层(Encoder Layer),这是Transformer架构中的核心组件之一,负责处理输入序列并通过多头自注意力机制和前馈神经网络来提取特征。
主要功能
-
初始化 (
__init__方法):- 接受四个参数:
size,self_attn,feed_forward, 和dropout。size: 输入张量最后一个维度的大小(即特征数量),用于初始化子层连接(SublayerConnection)。self_attn: 多头自注意力机制的实例(MultiHeadedAttention),用于计算输入序列中的注意力分布。feed_forward: 前馈神经网络的实例(PositionwiseFeedForward),通常是一个简单的两层全连接网络,用于进一步处理经过注意力机制后的输出。dropout: Dropout 的概率,用于防止过拟合,在子层连接中应用。
- 初始化两个
SublayerConnection实例,并通过clones函数复制两次。这两个实例分别用于处理多头自注意力机制和前馈神经网络之后的残差连接和层归一化。
- 接受四个参数:
-
前向传播 (
forward方法):- 输入张量
x及其对应的掩码mask被传递给该方法。 x的形状通常为[batch_size, seq_len, d_model],其中batch_size是批次大小,seq_len是序列长度,d_model是模型的维度。- 执行过程如下:
- 多头自注意力:首先使用
self.sublayer_conns[0]对输入x应用多头自注意力机制。这里使用了 lambda 表达式定义了一个匿名函数,该函数接收x并返回经过自注意力机制处理后的结果。处理后的结果还会通过 Dropout 和残差连接进行增强和标准化。 - 前馈神经网络:然后将上述结果传递给
self.sublayer_conns[1],通过前馈神经网络进行进一步处理。同样地,处理结果也会经过 Dropout 和残差连接。
- 多头自注意力:首先使用
- 输入张量
组件说明
MultiHeadedAttention:实现了多头自注意力机制,允许模型在不同的表示子空间中并行地关注输入的不同部分。PositionwiseFeedForward:一个两层的全连接网络,用于对每个位置的嵌入向量进行非线性变换,增加模型的表达能力。SublayerConnection:实现了残差连接和层归一化,确保每一层的输出具有稳定的分布,并缓解深层网络中的梯度消失问题。
解码器部分记录在《深度学习模型Transformer 手写核心架构二》

















 3069
3069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









