







目录
老规矩,先上一张图:
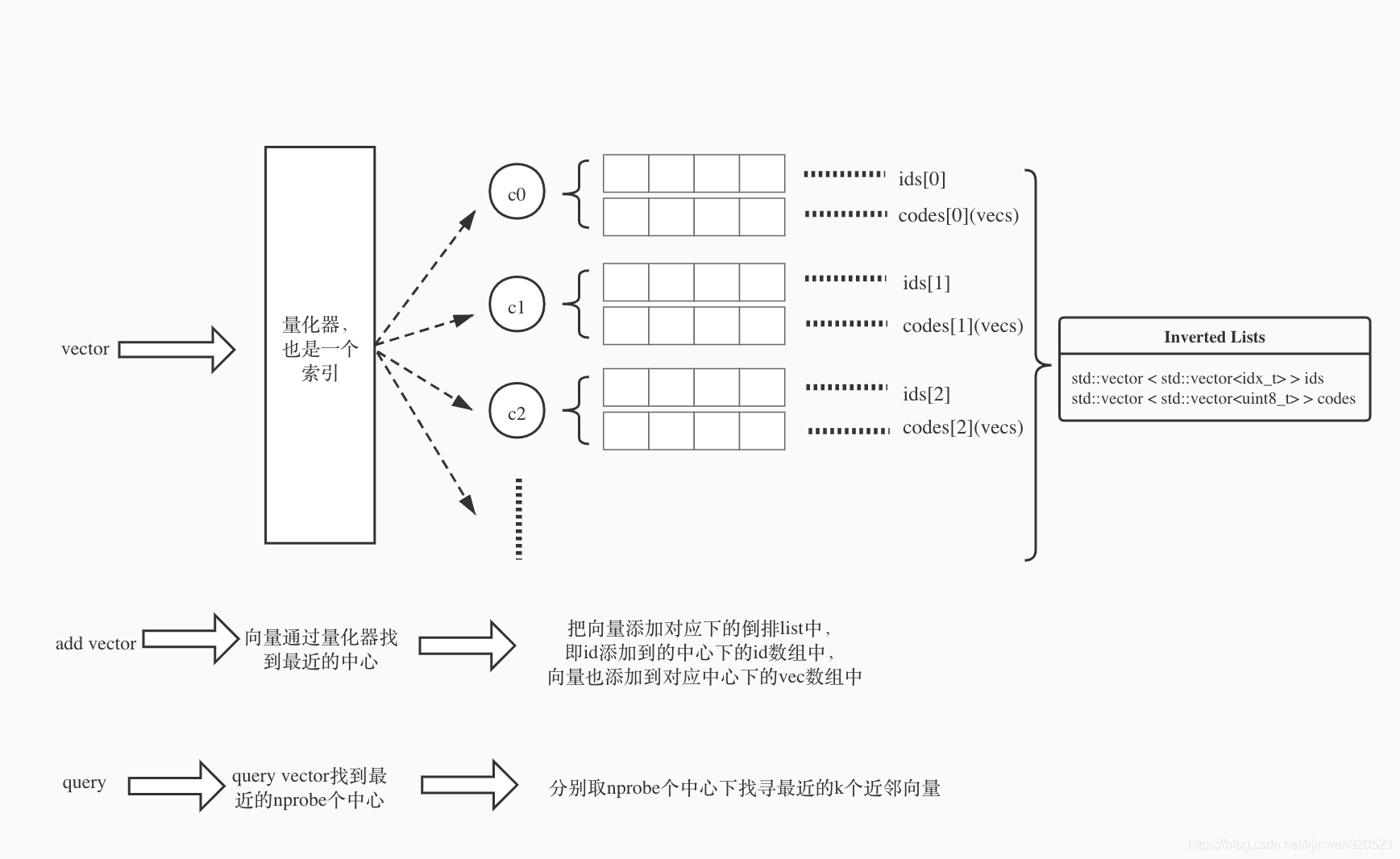
总的概括:IVF主要利用倒排的思想保存每个聚类中心下的向量(id,vector),每次查询向量的时候找到最近的几个中心,分别搜索这几个中心下的向量。通过减小搜索范围,大大提升搜索效率。
本文依次从IVF索引的构建(初始化),训练,添加向量,搜索四个方面剖析IVF索引。
1. 构建
先呈上一张IVF索引相关的几个类的关系图:
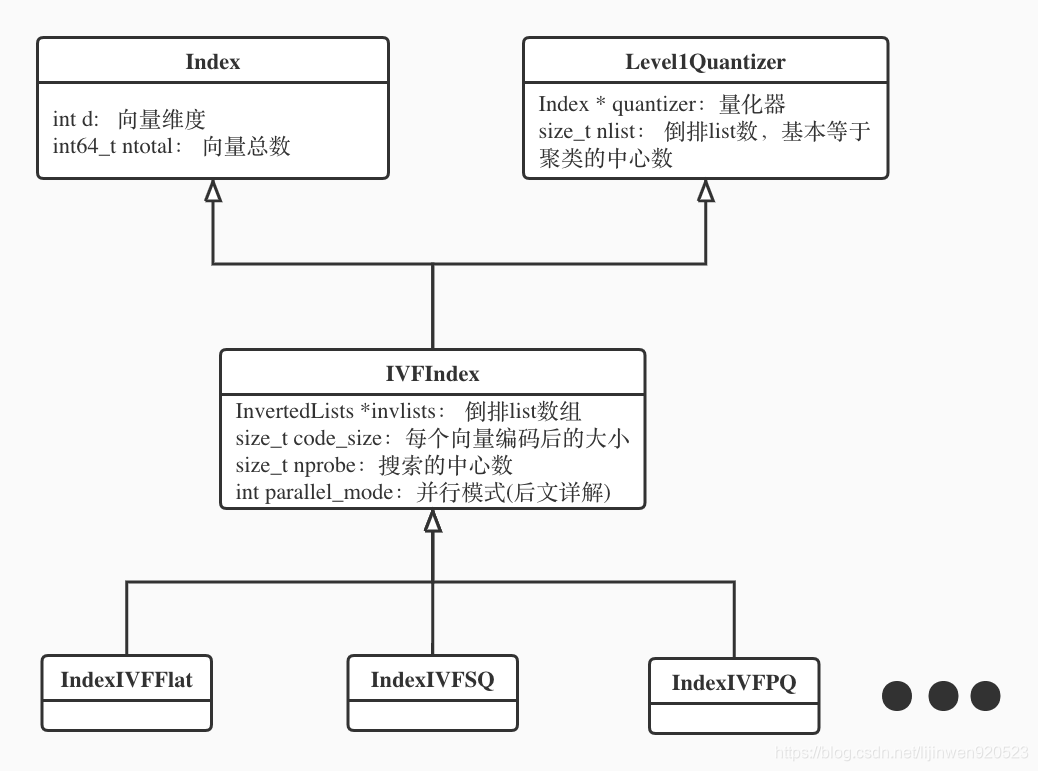
IVFIndex主要继承自一个通用的Index类和一个量化器类。Index类是所有索引的基类,提供了一些通用的接口,比如添加,查询;量化器类根据quantizer成员负责向量的编码与存储。本文主要介绍IVFIndex这个类,但是在实际使用过程中都是通过IVFIndex的子类来实例化索引的,不同的子类指定不同的quantizer,code size以及invlists类型等参数。IndexIVFFlat是最朴实的子类,选用的quantizer是最简单的Flat索引,也就是暴力索引,实际invert list里存储的是向量本身,所以code size就是向量本身的大小。本文中涉及到这些地方,如无特殊指定,均指IVFFlat下选定的参数。
struct IndexIVF: Index, Level1Quantizer {
/// Access to the actual data
InvertedLists *invlists; //由各中心的倒排list组成的数组
size_t code_size; ///< code size per vector in bytes
size_t nprobe; ///< number of probes at query time
/** Parallel mode determines how queries are parallelized with OpenMP
*
* 0 (default): parallelize over queries
* 1: parallelize over inverted lists
* 2: parallelize over both
*
* PARALLEL_MODE_NO_HEAP_INIT: binary or with the previous to
* prevent the heap to be initialized and finalized
*/
int parallel_mode;
}以上参数在上面的关系图中均有解释。
2. 训练
训练的作用主要是事先找到各个聚类中心。主要分两步, 训练量化器和残差训练
void IndexIVF::train (idx_t n, const float *x)
{
train_q1 (n, x, verbose, metric_type); //训练量化器
train_residual (n, x); //训练残差
is_trained = true;
}2.1 训练量化器
train_q1, 训练量化器。前文已经介绍过,量化器其实也是一个索引,用来找寻向量最近的聚类中心的。那么量化器的训练,在IVF索引中其实就是对量化器采用kmeans聚类,具体的聚类实现参见另一篇文章。
Clustering clus (d, nlist, cp);
quantizer->reset();
...
clus.train (n, x, *quantizer); // kmeans聚类
quantizer->is_trained = true;2.2 训练残差
train_residual, 训练残差,IVFIndex不同的子类会有不同的实现,在IVFIndex和IndexIVFFlat中啥也没干。
void IndexIVF::train_residual(idx_t /*n*/, const float* /*x*/) {
if (verbose)
printf("IndexIVF: no residual training\n");
// does nothing by default
}所以说,IVF索引的训练其实就是对量化器的一次聚类,获取各聚类中心。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1524
1524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











