









前言
2012年,Alex Krizhevsky、Ilya Sutskever在多伦多大学Geoff Hinton的实验室设计出了一个深层的卷积神经网络AlexNet,夺得了2012年ImageNet LSVRC的冠军,且准确率远超第二名(top5错误率为15.3%,第二名为26.2%),引起了很大的轰动。AlexNet可以说是具有历史意义的一个网络结构,在此之前,深度学习已经沉寂了将近20年,自2012年AlexNet诞生之后,后面的ImageNet冠军都是用卷积神经网络(CNN)来做的,并且层次越来越深,使得CNN成为计算机视觉领域(CV)的核心算法模型,在今后20年的发展中,CNN在CV的地位始终是统治性的,可以说AlexNet带来了深度学习的大爆发。
一、AlexNet理论
AlexNet其实跟LeNet很像,几乎可以说是LeNet的升级版,都是由卷积和全连接组成。AlexNet之所以能够成功,跟这个模型设计的特点有关,主要有:
(1)使用了非线性激活函数:ReLU
(2)随机失活:Dropout
(3)数据扩充:Data augmentation
(4)其他:多GPU实现,LRN归一化层的使用
1.激活函数:ReLU
传统的神经网络普遍使用Sigmoid或者tanh等非线性函数作为激励函数,然而它们容易出现梯度弥散或梯度饱和的情况。以Sigmoid函数为例,如下图所示,当输入的值非常大或者非常小的时候,值域的变化范围非常小,使得这些神经元的梯度值接近于0(梯度饱和现象)。由于神经网络的计算本质上是矩阵的连乘,一些近乎于0的值在连乘计算中会越来越小,导致网络训练中梯度更新的弥散现象,即梯度消失。
但是relu不存在这个缺陷,它在第一象限近似函数:y=x,不会出现值域变化小的问题。relu函数直到现在也是学术界和工业界公认的最好用的激活函数之一,在各个不同领域不同模型下的使用非常之多。
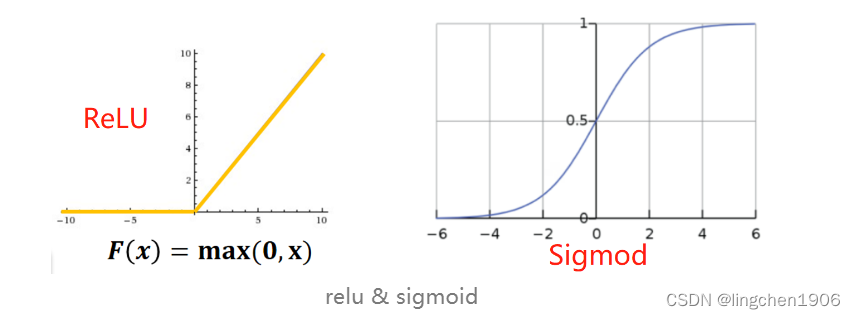
其实,对于relu函数的设计思想我们可以寻求一个生物学解释,初中的一个生物实验:生物学家们用电流刺激青蛙的大腿肌肉,当电流强度不够强时,肌肉组织不反应(即relu函数在x<0时,输出恒等于0的表现);当电流强度到达一定的阈值,肌肉组织开始抽搐,且电流强度越大,抽搐反应越强(即relu函数在x>0时,输出为y=x的表现)。本质上,这是一种非线性的体现。
2. 随机失活:Dropout
引入Dropout主要是为了防止网络在训练过程中出现的过拟合现象。过拟合现象出现的原因有两方面:
(1)数据集太小。
(2)模型太复杂。
至于产生过拟合的原因我们可以类别生活中的一个场景去解释:
高三的时候,老师出了一套题库给大家做练习,并说期末考试的题就是从题库中抽出来的。但是,这个题库的题量非常少,且都是选择题,那么这时候想要期末考高分的最快捷方法是什么呢?其实并不是把每道题都理解,都学会,而是单纯的背答案!
所以模型也是一样的,当数据太小时,模型就不会去学习数据中的相关性,不会尝试去理解数据,提取特征。最便捷的一种方式是把数据集中的所有数据强行记忆下来,这就叫过拟合。可以想象,一个过拟合的模型是没有举一反三的能力的,即对数据的泛化能力太差,只能对训练数据集中的数据做很好的处理,一旦换一批新的类似数据,模型的处理能力会很差。
那如何解决呢?两个方案:
(1)提升数据集容量。
让模型难以记忆所有的数据,这时候它就会尝试学习数据,理解数据了,因为相较于记忆所有数据,这是种更容易的解决方案。
(2)把模型变的简单些。
我们想:之所以高三的学生会选择背答案,其实是因为高三的学生比较聪明,如果换个小学生来,他八成是想不到背答案的。因此模型也是一样的,模型会选择记忆数据一方面是因为模型太复杂,他有能力去记忆所有数据。当我们降低模型的复杂度时,他就不会出现过拟合现象。
总之,过拟合的本质是数据集与模型在复杂度上不匹配。
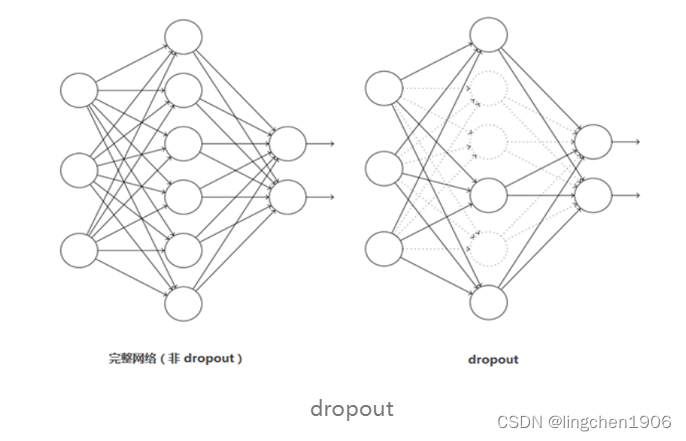
在神经网络中Dropout是通过降低模型复杂度来防止过拟合现象的,对于某一层的神经元,通过一定的概率将某些神经元的计算结果乘0,这个神经元就不参与前向和后向传播,就如同在网络中被删除了一样,同时保持输入层与输出层神经元的个数不变,然后按照神经网络的学习方法进行参数更新。在下一次迭代中,又重新随机删除一些神经元(置为0),直至训练结束。
3. 数据扩充:Data augmentation
由于神经网络算法是基于数据驱动的,因此,有一种观点认为神经网络是靠数据喂出来的,如果能够增加训练数据,提供海量数据进行训练,则能够有效提升算法的准确率,因为这样可以避免过拟合,从而可以进一步增大、加深网络结构。而当训练数据有限时,可以通过一些变换从已有的训练数据集中生成一些新的数据,以快速地扩充训练数据。
其中,最简单、通用的图像数据变形的方式:水平翻转图像,从原始图像中随机裁剪、平移变换,颜色、光照变换,如下图所示:
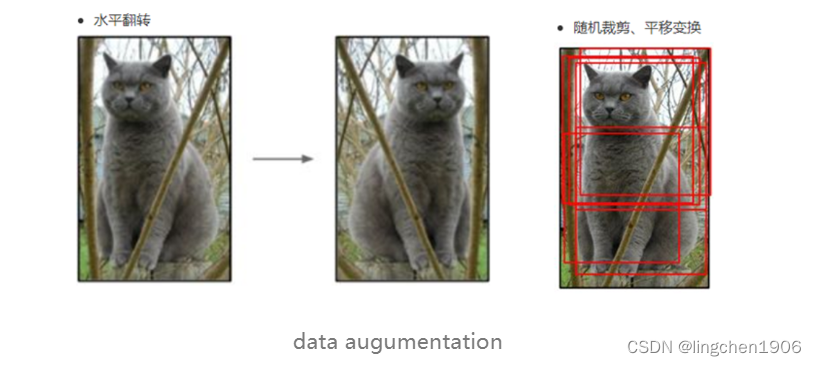
数据增广确实是提升模型的有效手段,而且最近的增广方式也不仅限于这种随即裁剪,也可以使用生成对抗网络进行图像生成来达到图像增广的目的。
4. 多GPU实现 : Distributed training
AlexNet当时使用了GTX580的GPU进行训练,由于单个GTX 580 GPU只有3GB内存,这限制了在其上训练的网络的最大规模,因此他们将模型拆成两部分,分别放进两个GPU硬件中进行训练,在训练过程中会通过交换feature maps进行两个硬件中子网络的信息交流,大大加快了AlexNet的训练速度。当时其实纯属硬件设备限制的无奈之举,但是,现在看来,这种拆成两组的训练方式跟现代的一种卷积变体非常非常类似:组卷积(group convolution)。个人认为,这也是AelxNet效果好的一个主要原因,不过作者当时并没有发现,也算是无心插柳柳成荫了。
5. 局部响应归一化 : LRN
Local Response Normalization(LRN)技术主要是深度学习训练时的一种提高准确度的技术方法。LRN一般是在激活、池化后进行的一种处理方法。LRN归一化技术首次在AlexNet模型中提出这个概念。通过实验确实证明它可以提高模型的泛化能力,但是提升的很少,以至于后面不再使用,甚至有人觉得它是一个“伪命题”,因而它饱受争议。现在基本上已经被Batch Normalization代替。
1. 局部归一化的灵感来源:
在神经生物学中,有一个概念叫做侧抑制(lateral inhibitio ),指的是被激活的神经元会抑制它周围的神经元,而归一化(normalization)的目的就是“抑制”大值,两者不谋而合,这就是局部归一化的动机,它就是借鉴“侧抑制”的思想来实现局部抑制,当我们使用RELU损失函数的时候,这种局部抑制显得很有效果。
2. 归一化的好处
(1)为了后面数据处理的方便,归一化的确可以避免一些不必要的数值问题。
(2)为了程序运行时收敛加快。
(3)同一量纲。样本数据的评价标准不一样,需要对其量纲化,统一评价标准。这算是应用层面的需求。
(4)避免神经元饱和。就是当神经元的激活在接近0或者1时会饱和,在这些区域,梯度几乎为0,这样,在反向传播过程中,局部梯度就会接近0,这会有效地“杀死”梯度。
(5)保证输出数据中数值小的不被吞食。
3. 实验总结
由于LRN模仿生物神经系统的侧抑制机制,对局部神经元的活动创建竞争机制,使得响应比较大的值会更大,提高了模型的泛化能力,Hinton在ImageNet中的实验准确率分别提升了1.4%和1.2%。但之后的工作却并不怎么认同这门技术,以至于直到现在都是一个争议性的技术,使用的很少。
二、基于pytorch搭建AlexNet模型
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[96, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[96, 27, 27]
nn.Conv2d(96, 256, kernel_size=5, padding=2), # output[256, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[256, 13, 13]
nn.Conv2d(256, 384, kernel_size=3, padding=1), # output[384, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, padding=1), # output[384, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1), # output[256, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[256, 6, 6]
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def alexnet(num_classes):
model = AlexNet(num_classes=num_classes)
return model
三、基于pytorch的模型训练代码
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdm
# 将创建AlexNet模型的python脚本导入进来
from classic_models.alexnet import AlexNet
def main():
# 判断可用设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
# 注意改成自己的数据集路径
data_path = 'D:\\Datasets\\flower'
assert os.path.exists(data_path), "{} path does not exist.".format(data_path)
# 数据预处理与增强
"""
ToTensor()能够把灰度范围从0-255变换到0-1之间的张量.
transform.Normalize()则把0-1变换到(-1,1). 具体地说, 对每个通道而言, Normalize执行以下操作: image=(image-mean)/std
其中mean和std分别通过(0.5,0.5,0.5)和(0.5,0.5,0.5)进行指定。原来的0-1最小值0则变成(0-0.5)/0.5=-1; 而最大值1则变成(1-0.5)/0.5=1.
也就是一个均值为0, 方差为1的正态分布. 这样的数据输入格式可以使神经网络更快收敛。
"""
data_transform = {
"train": transforms.Compose([transforms.Resize(224),
transforms.CenterCrop(224), #数据增强
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # val不需要任何数据增强
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
# 使用ImageFlolder加载数据集中的图像,并使用指定的预处理操作来处理图像, ImageFlolder会同时返回图像和对应的标签。 (image path, class_index) tuples
train_dataset = datasets.ImageFolder(root=os.path.join(data_path, "train"), transform=data_transform["train"])
validate_dataset = datasets.ImageFolder(root=os.path.join(data_path, "val"), transform=data_transform["val"])
train_num = len(train_dataset)
val_num = len(validate_dataset)
# 使用class_to_idx给类别一个index,作为训练时的标签: {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
# 创建一个字典,存储index和类别的对应关系,在模型推理阶段会用到。
cla_dict = dict((val, key) for key, val in flower_list.items())
# 将字典写成一个json文件
json_str = json.dumps(cla_dict, indent=4)
with open( os.path.join(data_path, 'class_indices.json') , 'w') as json_file:
json_file.write(json_str)
batch_size = 64 # batch_size大小,是超参,可调,如果模型跑不起来,尝试调小batch_size
num_workers = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # 用于加载数据集的进程数量
print('Using {} dataloader workers every process'.format(num_workers))
# 使用 DataLoader 将 ImageFloder 加载的数据集处理成批量(batch)加载模式
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers)
validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=4, shuffle=False, num_workers=num_workers) # 注意,验证集不需要shuffle
print("using {} images for training, {} images for validation.".format(train_num, val_num))
# 实例化模型,并送进设备
net = AlexNet(num_classes=5, init_weights=True)
net.to(device)
# 指定损失函数用于计算损失;指定优化器用于更新模型参数;指定训练迭代的轮数,训练权重的存储地址
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0002)
epochs = 70
save_path = os.path.abspath(os.path.join(os.getcwd(), './results/weights/alexnet'))
if not os.path.exists(save_path):
os.makedirs(save_path)
best_acc = 0.0 # 初始化验证集上最好的准确率,以便后面用该指标筛选模型最优参数。
for epoch in range(epochs):
############################################################## train ######################################################
net.train()
acc_num = torch.zeros(1).to(device) # 初始化,用于计算训练过程中预测正确的数量
sample_num = 0 # 初始化,用于记录当前迭代中,已经计算了多少个样本
# tqdm是一个进度条显示器,可以在终端打印出现在的训练进度
train_bar = tqdm(train_loader, file=sys.stdout, ncols=100)
for step, data in enumerate(train_bar):
images, labels = data
sample_num += images.shape[0]
optimizer.zero_grad()
outputs = net(images.to(device)) # output_shape: [batch_size, num_classes]
pred_class = torch.max(outputs, dim=1)[1] # torch.max 返回值是一个tuple,第一个元素是max值,第二个元素是max值的索引。
acc_num += torch.eq(pred_class, labels.to(device)).sum()
loss = loss_function(outputs, labels.to(device)) # 求损失
loss.backward() # 自动求导
optimizer.step() # 梯度下降
# print statistics
train_acc = acc_num.item() / sample_num
# .desc是进度条tqdm中的成员变量,作用是描述信息
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1, epochs, loss)
# validate
net.eval()
acc_num = 0.0 # accumulate accurate number per epoch
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc_num += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc_num / val_num
print('[epoch %d] train_loss: %.3f train_acc: %.3f val_accuracy: %.3f' % (epoch + 1, loss, train_acc, val_accurate))
# 判断当前验证集的准确率是否是最大的,如果是,则更新之前保存的权重
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), os.path.join(save_path, "AlexNet.pth") )
# 每次迭代后清空这些指标,重新计算
train_acc = 0.0
val_accurate = 0.0
print('Finished Training')
if __name__ == '__main__':
main()
四、基于pytorch的模型推理代码
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
# 将创建AlexNet模型的python脚本导入进来
from classic_models.alexnet import AlexNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 加载一种图片用于推理
img_path = "测试图片的路径"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# 扩张一个batch维度,因为训练模型时使用的小批量随机梯度下降有batch维度,所以推理时也需要有
img = torch.unsqueeze(img, dim=0)
# 加载模型预测值与真实类别的对应关系,json文件详见我的github代码
json_path = '生成的json文件的路径'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# 实例化模型
model = AlexNet(num_classes=5).to(device)
# 加载模型的权重
weights_path = "生成的权重文件AlexNet.pth的路径"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path))
model.eval()
with torch.no_grad():
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
# 取分类可能性最大的类别作为模型的识别结果
predict_cla = torch.argmax(predict).numpy()
# 以图片的方式输出识别结果
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)], predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)], predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()















 4451
4451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











