







最大似然法(Maximum likelihood,ML)也称为最大概率估计、极大似然估计,基本思想是:当从参数模型 y=f(m; x) 中随机抽取几组样本观测值(数据)后,最合理的参数a的估计值,应该使得从模型中抽取该观测值的概率最大。
也就是说,我们已知结果(y1,y2,y3…),求最可能的参数值a,这里的最大可能即为 最大似然。
举个例子,有两个外形完全相同的箱子,A箱子有99个白球,1个黑球;B箱子有99个黑球,1个白球;从一个箱子里又放回的抽样,连续抽取4次,结果是{ 黑、白、黑、黑 },那么哪个箱子的可能性最大?
也就是说,我们已知结果(y1,y2,y3…),求最可能的参数值a,这里的最大可能即为 最大似然。
举个例子,有两个外形完全相同的箱子,A箱子有99个白球,1个黑球;B箱子有99个黑球,1个白球;从一个箱子里又放回的抽样,连续抽取4次,结果是{ 黑、白、黑、黑 },那么哪个箱子的可能性最大?
在这里 m = A | B,y1,y2,y3,y4 = { 黑、白、黑、黑 },我们能够直观得到的结论 m=B,那么过程如何推导呢?
• 离散情况
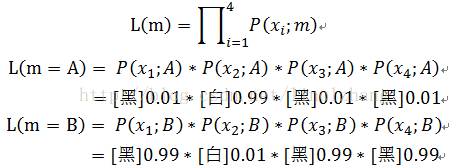
根据最大概率原则,m=B。
• 连续情况
类似,得到联合概率密度:
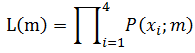
加上一个不改变趋势的ln函数,感谢张老师拍脑袋的神奇结论,感谢ln把累乘变成了累加,由此我们得到:

ok,问题变简单了,只需要使m的似然函数最大化,即求 H(m) 对应的极大值,就能得到我们估计的m值。
那么怎么求极值呢?当然是求导,然后让导数为0,对应多个m参数就是针对每一个参数求偏导,使其=0,求解k个参数,即对应k个方程,当然这里我们有一个前提假设,那就是L(m)本身是连续可微的。
求最大似然函数估计值的一般步骤可以概括为:
1. 写出似然函数;
2. 对似然函数求对数,并整理;
3. 求导数,另导数为0,得到似然方程;
4. 解似然方程,得到参数即为所求;
简单起见,假设似然函数符合直线分布,即 P(x; m) = x*m1+m2,代入上面公式能够得到:
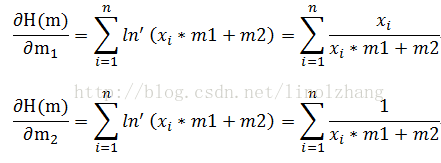
另方程=0,求解m1、m2即可。















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









