






error:GPU 0 has a total capacity of 23.64 GiB of which 1.61 GiB is free. Process 1624541 has 22.02 GiB memory in use. Of the allocated memory 20.13 GiB is allocated by PyTorch, and 1.47 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management
一,直接从根本入手
1.查看本电脑内存使用情况
nvidia-smi
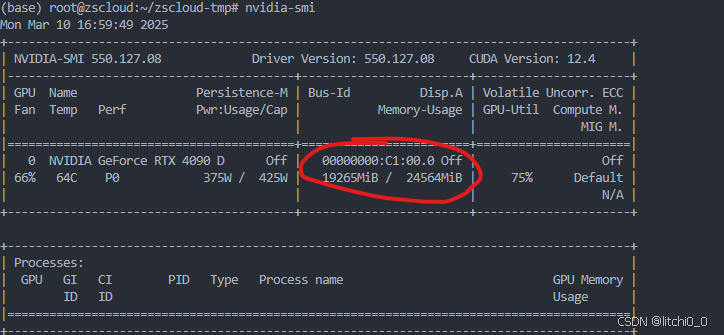
2.使用代码发现对应进程号
ps aux|grep python

kill掉对应的进程号
kill -9 进程号
二、关键参数调节:从根源降低显存占用
-
批处理大小(Batch Size)
• 作用原理:单次输入样本量直接影响激活值存储和梯度计算需求。
• 调整建议:
◦ 将per_device_train_batch_size设为1-2
◦ 配合gradient_accumulation_steps梯度累积(如设置为16-32)模拟大批量效果 -
序列截断长度(Cutoff Length)
• 关键影响:多模态场景下,图像/视频编码后的token序列极易突破预设值。
• 优化策略:
◦ 从默认2048缩减至512-1024(网页1案例将100000长度缩减到4096解决OOM)
◦ 使用动态填充策略dynamic_packing替代静态截断 -
LoRA微调参数
• 数学关系:LoRA参数量=2×rank×(hidden_size),7B模型hidden_size=4096时:
◦ rank=8时单层参数量≈65K,rank=4时降为32K
• 调优方案:
◦ 将lora_rank从8降为4-6,lora_alpha从16降为8-12(网页4建议16-32范围)
◦ 禁用非必要模块的适配(如仅保留q_proj/v_proj)
三、高级优化技术:突破硬件限制
-
混合精度训练
• 启用bf16可减少50%显存占用(需GPU支持)
• 备选方案fp16需设置adam_epsilon=1e-5防止梯度溢出 -
梯度检查点(Gradient Checkpointing)
• 通过时间换空间策略,减少50%激活值存储
• 添加--gradient_checkpointing true参数启用 -
量化训练(QLoRA)
• 4-bit量化可将模型显存需求压缩至原1/4
• 设置quantization_bit=4并选择nf4量化格式
四、数据预处理优化:减少隐性消耗
-
数据加载工作线程
• 将preprocessing_num_workers从16降为4-8
• 设置dataloader_pin_memory=False禁用内存锁 -
动态数据加载
• 对大规模数据集启用streaming=True流式加载
• 设置max_samples=1000-5000限制单epoch样本量
五、配置参考模板
# 内存优化版配置示例(Qwen2.5-VL-7B)
llamafactory-cli train \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 32 \
--cutoff_len 512 \
--lora_rank 4 \
--lora_alpha 8 \
--gradient_checkpointing true \
--bf16 true \
--preprocessing_num_workers 8 \
--quantization_bit 4

















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









