










 DETR是一种端到端的目标检测模型,利用Transformer结构和集合预测方法,避免了传统检测模型的先验知识。文章介绍了DETR的工作原理、优点、缺点及其实现流程,包括mmdetection中的应用。
DETR是一种端到端的目标检测模型,利用Transformer结构和集合预测方法,避免了传统检测模型的先验知识。文章介绍了DETR的工作原理、优点、缺点及其实现流程,包括mmdetection中的应用。
继上一章Transformer应用于图像分类后(ViT),本章开启对DEtection TRansformer的学习之旅(DETR --Transformer应用于图像目标检测的开山之作)。
论文地址:https://arxiv.org/pdf/2005.12872.pdf
github实现版本有很多,推荐大家使用mmdetection的版本。
概述
DETR是Meta AI研究院提出的CV通用框架,论文中将其应用于目标检测与全景分割。DETR舍弃了以往一阶段,二阶段检测模型的先验trick,比如anchor的设置,nms极大值抑制,也没有多尺度特征融合(由于Swin transformer在其后发表)以及复杂的数据增强,其整个pipeline简洁,直观,得到后人称赞并应用于cv各个task中。
总结来说,DETR将目标检测任务(分类与回归)看作集合预测问题。输入一张图片,经过cnn的backbone输出32倍下采样的深度特征,将其输入到DETR的Encoder-Decoder Transformer中,结合Object Query并行输出固定尺寸的预测特征。
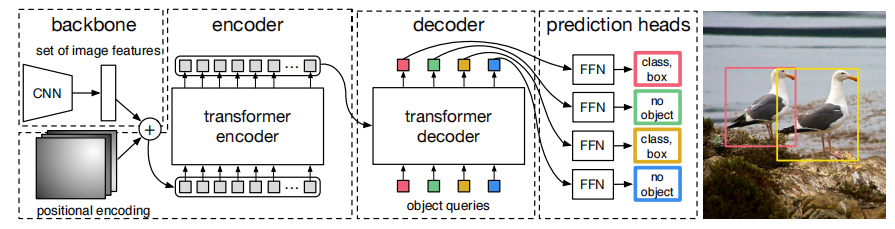
DETR优点:
1.首次将Transformer结构引入到图像目标检测中,并真正实现端到端的目标检测,去除了NMS以及anchor人工先验知识,网络结构简洁明了。
2.提出基于集合的损失函数,通过二分图匹配的方法将模型输出的预测框与GT根据Cost Matrix进行一对一匹配,每个物体只会产生一个预测框,成功将目标检测问题转换为集合预测问题。
3.引入Object Query,在decoder中引入可学习的Object Query,与encoder输出的全局自注意力特征结合,以并行方式输出100个预测框。
4.由于self-attention提供的全局语义,使得detr在大物体检测性能提高。
5.在coco数据上的速度与精度和Faster RCNN相媲美,并且DETR框架可以简单扩展到CV领域多种任务中。
DETR缺点:
1.DETR对小物体的检测效果不好。由于输入到Transformer中的特征已经经过CNN的32倍下采样了,其对图像细节的把控有所缺失,导致对小物体不友好。
2.训练时间长,收敛相对困难。由于DETR放弃了先验anchor,相对于anchor,Object Query更难收敛。因为DETR通过二分图匹配方法将输出与GT对应,没有anchor的指引,DETR很难将损失与语义对应,且Object Query随机初始化,只有通过长时间的训练,才能让Object Query获得一定的位置语义信息。
训练流程
1.输入图像经过CNN的backbone获得32倍下采样的深度特征;
2.将图片给拉直形成token,并添加位置编码送入encoder中;
3.将encoder的输出以及Object Query作为decoder的输入得到解码特征;
4.将解码后的特征传入FFN得到预测特征;
5.根据预测特征计算cost matrix,并由匈牙利算法匹配GT,获得正负样本;
6.根据正负样本计算分类与回归loss。
推理流程
1-4与训练流程相同;
5.去除预测特征背景类,将其余类别进行softmax,若softmax后的最大得分超过阈值(0.7)认为是前景,rescale box并输出前景,否则判定为背景。
代码实现
下面我结合mmdetection代码跟大家详细介绍DETR的实现过程,首先讲解训练流程1:图像经过CNN的backbone获得32倍下采样的深度特征。
代码如下所示,输入img通过self.extract_feat从resnet50的Backbone中输出32倍下采样[2,2048,22,38]维度的特征。之后进入self.bbox_head中,该对象来自于/mmdet/models/dense_heads/detr_head.py:中。
def forward_train(self,
img,
img_metas,
gt_bboxes,
gt_labels,
gt_bboxes_ignore=None):
super(SingleStageDetector, self).forward_train(img, img_metas)
x = self.extract_feat(img)
losses = self.bbox_head.forward_train(x, img_metas, gt_bboxes,
gt_labels, gt_bboxes_ignore)
return losses
下面代码是class DETRHead(AnchorFreeHead):def forward_single(self, x, img_metas):为了方便介绍,只截取训练步骤2(将图片给拉直并添加位置编码送入encoder中)中的相关代码。x是步骤1中产生[2,2048,22,38]维度的特征,self.input_proj:Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1)),通过1x1卷积将x降维至[2,256,22,38]。
batch_size = x.size(0)
input_img_h, input_img_w = img_metas[0]['batch_input_shape']
masks = x.new_ones((batch_size, input_img_h, input_img_w))
for img_id in range(batch_size):
img_h, img_w, _ = img_metas[img_id]['img_shape']
masks[img_id, :img_h, :img_w] = 0
x = self.input_proj(x)
# interpolate masks to have the same spatial shape with x
masks = F.interpolate(
masks.unsqueeze(1), size=x.shape[-2:]).to(torch.bool).squeeze(1)
# position encoding
pos_embed = self.positional_encoding(masks) # [bs, embed_dim, h, w]
# outs_dec: [nb_dec, bs, num_query, embed_dim]
outs_dec, _ = self.transformer(x, masks, self.query_embedding.weight,
pos_embed)
如下图所示,由于detr多尺度训练,图片需要padding,右边黑色即为padding部分,需要用mask区分图片有效区域。为了与x尺寸保持一致,利用F.interpolate插值操作将mask进行缩放。


self.positional_encoding(masks)来自class SinePositionalEncoding(BaseModule):
detr对x进行位置编码生成pos_embed 。代码中注释了位置编码的每个步骤。
class SinePositionalEncoding(BaseModule):
"""Position encoding with sine and cosine functions.
See `End-to-End Object Detection with Transformers
<https://arxiv.org/pdf/2005.12872>`_ for details.
Args:
num_feats (int): The feature dimension for each position
along x-axis or y-axis. Note the final returned dimension
for each position is 2 times of this value.
temperature (int, optional): The temperature used for scaling
the position embedding. Defaults to 10000.
normalize (bool, optional): Whether to normalize the position
embedding. Defaults to False.
scale (float, optional): A scale factor that scales the position
embedding. The scale will be used only when `normalize` is True.
Defaults to 2*pi.
eps (float, optional): A value added to the denominator for
numerical stability. Defaults to 1e-6.
offset (float): offset add to embed when do the normalization.
Defaults to 0.
init_cfg (dict or list[dict], optional): Initialization config dict.
Default: None
"""
def __init__(self,
num_feats,
temperature=10000,
normalize=False,
scale=2 * math.pi,
eps=1e-6,
offset=0.,
init_cfg=None):
super(SinePositionalEncoding, self).__init__(init_cfg)
if normalize:
assert isinstance(scale, (float, int)), 'when normalize is set,' \
'scale should be provided and in float or int type, ' \
f'found {type(scale)}'
self.num_feats = num_feats # 128维度 x/y = d_model/2
self.temperature = temperature # 常数 正余弦位置编码公式里面的10000
self.normalize = normalize # 是否对向量进行max规范化 True
self.scale = scale # 规范化参数 2*pi
self.eps = eps
self.offset = offset
def forward(self, mask):
"""Forward function for `SinePositionalEncoding`.
Args:
mask (Tensor): ByteTensor mask. Non-zero values representing
ignored positions, while zero values means valid positions
for this image. Shape [bs, h, w].
Returns:
pos (Tensor): Returned position embedding with shape
[bs, num_feats*2, h, w].
"""
# For convenience of exporting to ONNX, it's required to convert
# `masks` from bool to int.
mask = mask.to(torch.int) # [bs, 22, 38] 用于记录矩阵中哪些地方是填充的(原图部分值为False,填充部分值为True)
not_mask = 1 - mask # logical_not # True的位置才是真实有效的位置
# 考虑到图像本身是2维的 所以这里使用的是2维的正余弦位置编码
# 这样各行/列都映射到不同的值 当然有效位置是正常值 无效位置会有重复值 但是后续计算注意力权重会忽略这部分的
# 而且最后一个数字就是有效位置的总和,方便max规范化
# 计算此时y方向上的坐标 [bs, 22, 38]
y_embed = not_mask.cumsum(1, dtype=torch.float32)
x_embed = not_mask.cumsum(2, dtype=torch.float32) # 计算此时x方向的坐标 [bs, 22, 38]
if self.normalize:# 最大值规范化 除以最大值 再乘以2*pi 最终把坐标规范化到0-2pi之间
y_embed = (y_embed + self.offset) / \
(y_embed[:, -1:, :] + self.eps) * self.scale
x_embed = (x_embed + self.offset) / \
(x_embed[:, :, -1:] + self.eps) * self.scale
dim_t = torch.arange(
self.num_feats, dtype=torch.float32, device=mask.device)
dim_t = self.temperature**(2 * (dim_t // 2) / self.num_feats)# 0 1 2 .. 127
pos_x = x_embed[:, :, :, None] / dim_t
pos_y = y_embed[:, :, :, None] / dim_t
# use `view` instead of `flatten` for dynamically exporting to ONNX
B, H, W = mask.size()
# x方向位置编码: [bs,19,26,64][bs,19,26,64] -> [bs,19,26,64,2] -> [bs,19,26,128]
pos_x = torch.stack(
(pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()),
dim=4).view(B, H, W, -1)
# y方向位置编码: [bs,19,26,64][bs,19,26,64] -> [bs,19,26,64,2] -> [bs,19,26,128]
pos_y = torch.stack(
(pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()),
dim=4).view(B, H, W, -1)
# concat: [bs,19,26,128][bs,19,26,128] -> [bs,19,26,256] -> [bs,256,19,26]
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
return pos

这里是通过mask来构建位置编码的,mask中记录了特征图中每个像素位置是否是pad的,只有在为False的位置,才是有效的位置,才需要构建位置编码;这样,对于每个位置(x,y),其所在列对应的编码值就在通道维度的前128维,其所在行的编码值就在通道这个维度的后128维。这样这个特征图上各个位置就都对应到不同的维度的编码值了。
self.query_embedding.weight是维度为[100,256]的可学习编码,其功能类似于传统检测中的anchor,这里设置了100个需要预测的目标。self.transformer(x, masks, self.query_embedding.weight,pos_embed),将括号内参数送入Transformer的forward中。由于篇幅原因,下节我们继续再详细解读self.transformer。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









