







提示词是什么?
就是和大模型交互时,我们的问题描述。这说简单也简单,说难也很难的,如何让大模型理解我们说的问题,是一个门槛低,天花板很高的任务。在描述中一个字的不同就可能产生不同的结果。就像和人交流一样,也就是把AI当人看,如何让别人理解我们说的话,如何让他理解的意思更接近我们的想法。
比如请给我一个漂亮的女生图片。文心一言输出的图片如下:
 这可能不是我们想要的,因为我们没有说漂亮女生的标准,所以可以再详细的描述,例如女生是不带帽子的,且是圆脸,大模型又给我了一副图
这可能不是我们想要的,因为我们没有说漂亮女生的标准,所以可以再详细的描述,例如女生是不带帽子的,且是圆脸,大模型又给我了一副图

就这样逐渐描述。逐渐调整描述信息, 一步步接近心里想要的答案。调优是一个漫长的过程。一个理想的结果可能需要几个小时,甚至一天的时间。
提示词的典型构成
大家经过几年的摸索。逐渐摸索出一条规则,就是提示词中增加如下描述能是大模型更懂我。
**角色:**给 AI 定义一个最匹配任务的角色,比如:「你是一位软件工程师」「你是一位小学数学老师」
**指示:**对任务进行描述
**上下文:**给出与任务相关的其它背景信息(尤其在多轮交互中)
**例子:**必要时给出举例,学术中称为 Few-Shot Learning 或 In-Context Learning;对输出正确性有很大帮助
输入:任务的输入信息;在提示词中明确的标识出输入
输出:输出的风格、格式描述,引导只输出想要的信息,以及方便后继模块自动解析模型的输出结果,比如(JSON、XML)
对话系统的思路
把大模型用于软件系统的核心思路:
- 把输入的自然语言对话,转成结构化的信息(NLU[自然语言理解])
- 用传统软件手段处理结构化信息,得到处理策略
- 把策略转成自然语言输出(NLG)

实例及代码
引用课上老师的例子:
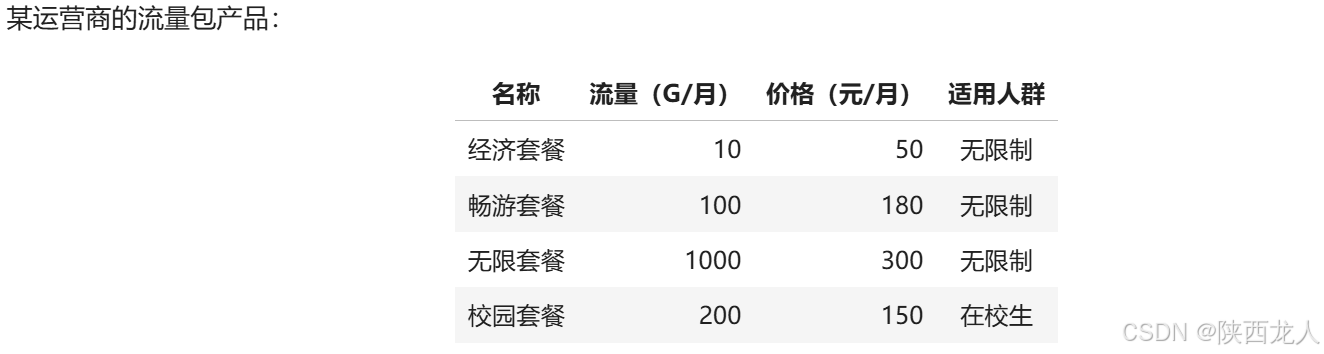
智能客服根据用户的咨询,推荐最适合的流量包。
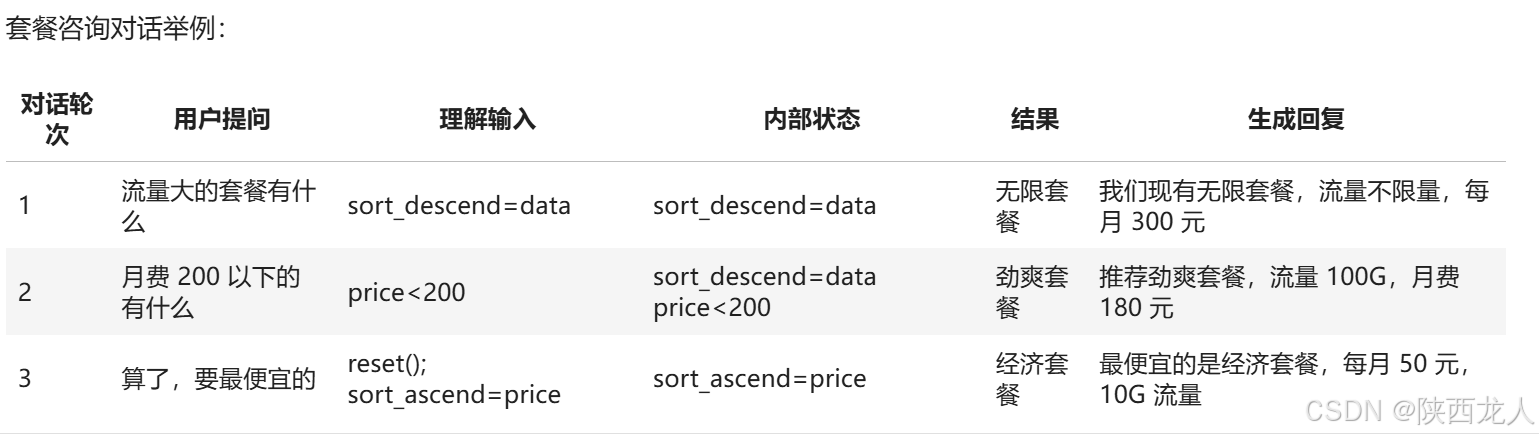
用 Prompt 实现
# 导入依赖库
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv
# 加载 .env 文件中定义的环境变量,这里记载这登录大模型的OPENAI_API_KEY和OPENAI_BASE_URL
_ = load_dotenv(find_dotenv())
# 初始化 OpenAI 客户端
client = OpenAI() # 默认使用环境变量中的 OPENAI_API_KEY 和 OPENAI_BASE_URL
上面两行代码相当于如下
client = OpenAI(
api_key=os.getenv(“OPENAI_API_KEY”)
base_url= os.getenv(“OPENAI_BASE_URL”)
)
对于python工程,env就是存放环境变量的文件.
对于代码不做过多的解释了,刚开始都不太懂,但是多练习,多测试就慢慢的懂了
# 基于 prompt 生成文本
# 默认使用 gpt-4o-mini 模型
def get_completion(prompt, response_format="text", model="gpt-4o-mini"):
messages = [{"role": "user", "content": prompt}] # 将 prompt 作为用户输入
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0, # 模型输出的随机性,0 表示随机性最小
response_format={"type": response_format},# 返回消息的格式,text 或 json_object
)
return response.choices[0].message.content # 返回模型生成的文本
上面两段代码就是大模型的调用,我们通过传递提示词prompt,给大模型,大模型就把最终结果返回出来.
注意:roles的类型有四种
1.user:对话或交互过程中,用户是主要的参与者,提供输入并接收输出,
2.assistant:助手角色通常是指帮助用户完成特定任务的智能体,它根据用户的输入提供相应的反馈或执行任务。助手角色可以是大模型本身,也可以是用户界面的一部分, 在应用过程中通常认为是在这里插入代码片大模型.
3.system:系统角色代表整个大语言模型或其运行环境。它负责处理用户的请求,协调AI和用户之间的交互,并提供必要的资源和功能
4.tool:通常指的是在该角色下可供使用的一系列工具或资源,用于执行特定任务或支持角色的功能。比如,在一个聊天机器人系统中,"Role"可能是“客服代表”,那么对应的"tool"可能包括客服知识库、快速回复模板、客户信息管理系统等,这些都是为了帮助该角色更有效地完成其工作,一般用于function calling
下面描述Prompt;
# 任务描述
instruction = """
你的任务是识别用户对手机流量套餐产品的选择条件。
每种流量套餐产品包含三个属性:名称,月费价格,月流量。
根据用户输入,识别用户在上述三种属性上的需求是什么。
"""
# 用户输入
input_text = """
办个100G的套餐。
"""
# prompt 模版。instruction 和 input_text 会被替换为上面的内容
prompt = f"""
# 目标
{instruction}
# 用户输入
{input_text}
"""
print("==== Prompt ====")
print(prompt)
print("================")
# 调用大模型
response = get_completion(prompt)
print(response)
prompt多多少少遵从了提示词典型构成.最终根据用户提供的Prompt,产生了结果
结果:用户的需求是选择一个月流量为100G的套餐。关于其他属性(名称和月费价格),用户没有明确说明。
这里其实每次执行产生的结果可能都不一样.
在上述代码中可以也定格式,例如以json格式输出,如下
# 输出格式
output_format = """
以 JSON 格式输出
"""
# 稍微调整下咒语,加入输出格式
prompt = f"""
# 目标
{instruction}
# 输出格式
{output_format}
# 用户输入
{input_text}
"""
# 调用大模型,指定用 JSON mode 输出
response = get_completion(prompt, response_format="json_object")
print(response)
结果会按着我们的意思输出,结果如下
{
“名称”: “100G套餐”,
“月费价格”: null,
“月流量”: “100G”
}
下面对instruction和输出格式做了严格的说明
# 任务描述增加了字段的英文标识符
instruction = """
你的任务是识别用户对手机流量套餐产品的选择条件。
每种流量套餐产品包含三个属性:名称(name),月费价格(price),月流量(data)。
根据用户输入,识别用户在上述三种属性上的需求是什么。
"""
# 输出格式增加了各种定义、约束
output_format = """
以JSON格式输出。
1. name字段的取值为string类型,取值必须为以下之一:经济套餐、畅游套餐、无限套餐、校园套餐 或 null;
2. price字段的取值为一个结构体 或 null,包含两个字段:
(1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于)
(2) value, int类型
3. data字段的取值为取值为一个结构体 或 null,包含两个字段:
(1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于)
(2) value, int类型或string类型,string类型只能是'无上限'
4. 用户的意图可以包含按price或data排序,以sort字段标识,取值为一个结构体:
(1) 结构体中以"ordering"="descend"表示按降序排序,以"value"字段存储待排序的字段
(2) 结构体中以"ordering"="ascend"表示按升序排序,以"value"字段存储待排序的字段
输出中只包含用户提及的字段,不要猜测任何用户未直接提及的字段,不输出值为null的字段。
"""
input_text = "办个100G以上的套餐"
# input_text = "有没有便宜的套餐"
# 这条不尽如人意,但换成 GPT-4-turbo 就可以了
# input_text = "有没有土豪套餐"
prompt = f"""
# 目标
{instruction}
# 输出格式
{output_format}
# 用户输入
{input_text}
"""
response = get_completion(prompt, response_format="json_object")
print(response)
我们要求办个100G以上的套餐,最终大模型给的结果如下:
{
“data”: {
“operator”: “>=”,
“value”: 100
}
}
提示词的典型构成:角色,指示,.上下文,例子,输入输出.
我们再进一步增加增加例子,让结果更加稳定
examples = """
便宜的套餐:{"sort":{"ordering"="ascend","value"="price"}}
有没有不限流量的:{"data":{"operator":"==","value":"无上限"}}
流量大的:{"sort":{"ordering"="descend","value"="data"}}
100G以上流量的套餐最便宜的是哪个:{"sort":{"ordering"="ascend","value"="price"},"data":{"operator":">=","value":100}}
月费不超过200的:{"price":{"operator":"<=","value":200}}
就要月费180那个套餐:{"price":{"operator":"==","value":180}}
经济套餐:{"name":"经济套餐"}
土豪套餐:{"name":"无限套餐"}
"""
# 有了例子,gpt-4o-mini 也可以了
input_text = "有没有土豪套餐"
# input_text = "办个200G的套餐"
# input_text = "有没有流量大的套餐"
# input_text = "200元以下,流量大的套餐有啥"
# input_text = "你说那个10G的套餐,叫啥名字"
# 有了例子
prompt = f"""
# 目标
{instruction}
# 输出格式
{output_format}
# 举例
{examples}
# 用户输入
{input_text}
"""
response = get_completion(prompt, response_format="json_object")
print(response)
输出结果:{“name”:“无限套餐”}
自己也可以通过多次修改input_text,查看结果.
在上面的例子中无非就是开始的两段基础代码,然后不断的修改Prompt,查看输出结果.代码非常简单
支持多轮对话
把多轮对话放到Prompt的例子中,增加了上下文,
instruction = """
你的任务是识别用户对手机流量套餐产品的选择条件。
每种流量套餐产品包含三个属性:名称(name),月费价格(price),月流量(data)。
根据对话上下文,识别用户在上述三种属性上的需求是什么。识别结果要包含整个对话的信息。
"""
# 输出描述
output_format = """
以JSON格式输出。
1. name字段的取值为string类型,取值必须为以下之一:经济套餐、畅游套餐、无限套餐、校园套餐 或 null;
2. price字段的取值为一个结构体 或 null,包含两个字段:
(1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于)
(2) value, int类型
3. data字段的取值为取值为一个结构体 或 null,包含两个字段:
(1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于)
(2) value, int类型或string类型,string类型只能是'无上限'
4. 用户的意图可以包含按price或data排序,以sort字段标识,取值为一个结构体:
(1) 结构体中以"ordering"="descend"表示按降序排序,以"value"字段存储待排序的字段
(2) 结构体中以"ordering"="ascend"表示按升序排序,以"value"字段存储待排序的字段
输出中只包含用户提及的字段,不要猜测任何用户未直接提及的字段。不要输出值为null的字段。
"""
# 多轮对话的例子
examples = """
客服:有什么可以帮您
用户:100G套餐有什么
{"data":{"operator":">=","value":100}}
客服:有什么可以帮您
用户:100G套餐有什么
客服:我们现在有无限套餐,不限流量,月费300元
用户:太贵了,有200元以内的不
{"data":{"operator":">=","value":100},"price":{"operator":"<=","value":200}}
客服:有什么可以帮您
用户:便宜的套餐有什么
客服:我们现在有经济套餐,每月50元,10G流量
用户:100G以上的有什么
{"data":{"operator":">=","value":100},"sort":{"ordering"="ascend","value"="price"}}
客服:有什么可以帮您
用户:100G以上的套餐有什么
客服:我们现在有畅游套餐,流量100G,月费180元
用户:流量最多的呢
{"sort":{"ordering"="descend","value"="data"},"data":{"operator":">=","value":100}}
"""
input_text = "哪个便宜"
# input_text = "无限量哪个多少钱"
# input_text = "流量最大的多少钱"
# 多轮对话上下文
context = f"""
客服:有什么可以帮您
用户:有什么100G以上的套餐推荐
客服:我们有畅游套餐和无限套餐,您有什么价格倾向吗
用户:{input_text}
"""
prompt = f"""
# 目标
{instruction}
# 输出格式
{output_format}
# 举例
{examples}
# 对话上下文
{context}
"""
response = get_completion(prompt, response_format="json_object")
print(response)
这会输出如下结果
{
“data”: {
“operator”: “>=”,
“value”: 100
},
“sort”: {
“ordering”: “ascend”,
“value”: “price”
}
}
这里都是非常简单的代码,着重是找一下Prompt提示词的感觉
在这一讲中,主要代码就是是前两断.操作大模型的方法一般写到类中.
提示词的构成,通过给定的例子要好好体会一下.

















 1506
1506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









