






将额外模态(如图像输入)融入大语言模型(LLMs)被认为是 AI 研究和发展的一个关键新领域
将大语言模型 (LLMs) 扩展到多种数据类型,从而得到所谓的多模态大模型 (LMMs)。
DeepMind 的 Flamingo、Salesforce 的 BLIP、微软的 KOSMOS-1、Google 的 PaLM-E,还有腾讯的 Macaw-LLM。甚至像 ChatGPT 和 Gemini 这样的聊天机器人也采用了这种技术
不是所有多模态系统都属于 LMM。例如,像 Midjourney、Stable Diffusion 和 Dall-E 这样的文本到图像模型虽然是多模态的,但并不包含语言模型组件 这些是多模态系统
多模态可能指的是:
- 输入和输出属于不同模态(如文本到图像,图像到文本);
- 输入为多模态(例如,能同时处理文本和图像的系统);
- 输出为多模态(例如,能同时生成文本和图像的系统)。
多模态系统,包括 LMM
1、多模态的重要性
1、很多应用场景如果没有多模态技术支持几乎难以实现,尤其是在需要处理多种类型数据的领域,例如医疗、机器人、电商、零售、游戏等
2、综合使用多种数据模式的信息,可以显著提升模型的性能。比如,一个能够同时处理文本和图片的模型,其效果不是应该比只能处理文本或只能处理图片的模型更出色吗?
3、交互更加灵活多样,可以根据自己的喜好或场合选择交互方式,比如键盘输入、语音对话或者拍照识别
4、借助多模态技术,视力受损的人也能轻松浏览网络,甚至在真实世界中进行导航。
2、数据的多种模式
数据有多种形式,例如:文本、图片、音频、数据表格等。这些数据的一种形式有时可以转换或 模拟 成另一种形式。例如:
-
音频可以转化为图像形式,如音谱图。
-
语音内容可以转写为文字,但这样做可能会丢失某些信息,如声音的响度、语调和停顿等。
-
图像可以转化为向量,并进一步被转换为一串文本词元(Token)序列。
-
视频实际上是一系列的图片加上音频。但现在,很多机器学习模型只把视频看作是图片的连续播放。这真的大大限制了它们的能力,因为研究表明,声音在视频中起到的作用与画面一样重要。
-
其实,只要你为一段文字拍张照,它就能被视为一张图片。
-
你知道吗,数据表格也可以变成图表,也就是我们常说的图像。
3、其他的数据模态
事实上,所有的数字数据都可以用一系列的 0 和 1(即比特串)或者字节序列来表示
图形和三维(3D)素材,以及用于表示气味和触觉(如触觉反馈设备)的数据格式。
音频大多只被当作是语音的另一种形式。大多用于把人声转化为文字,或是把文字转化为人声。而非语音的应用,比如创作音乐。
图片则可以说是最多用途的输入方式了,它不仅可以代表文字、数据表,还可以代表音频和部分视频
谈到输出时,文本就显得更有力量了。一个只能生成图片的模型其实用途有限,但如果一个模型能输出文本,它就能完成许多任务,如摘要、翻译、逻辑推理和问答等
4、多模态任务
常看到把与视觉和语言相关的任务分为两类:生成 和 视觉语言理解(VLU)
1、生成
对于生成任务,输出可以是单模态(例如只是文本、图像或 3D 图)或多模态结合。现在,单模态的输出已经很普遍,但多模态的输出还在发展中
从文本生成图像
比如:Dall-E、Stable Diffusion 和 Midjourney 。
文本生成
视觉问题回答。比如,你可以随时拍摄任何东西,并提出问题:“我的车怎么不动了,是怎么回事?”、“这道菜怎么做?”或“这个梗是什么意思?”。
帮助搜索特定的图片。想象一个大公司,可能有上百万甚至十亿的图片:产品照片、统计图、设计稿、团队合影、宣传海报等等。AI 能够自动为这些图片生成描述和相关信息,这样你就可以轻松地找到你需要的图片了。
2、视觉语言理解
两种任务类型:分类和基于文本的图像检索(Text-based Image Retrieval, TBIR)。
分类:
OCR(光学字符识别)系统就是来判断某个图像上的字符是不是我们已知的字符,如数字或字母。
与图像分类相似的另一任务是 图像到文本检索:也就是根据给定的图像,从一堆文字中找出最匹配的描述。这种技术在搜索商品图片时特别有用,可以从图片中找出相关的商品评论。
基于文本的图像检索(图像搜索)
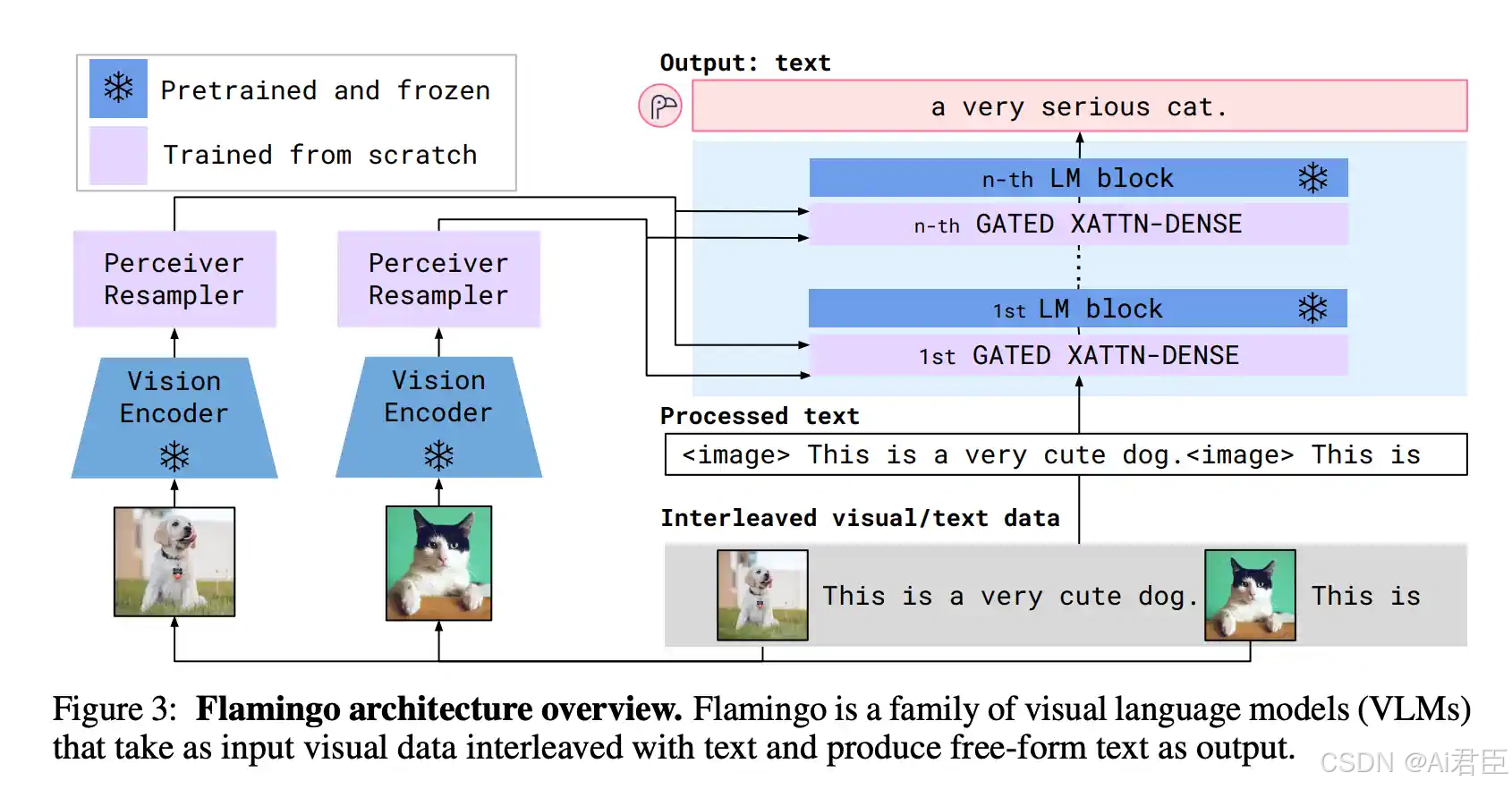
Flamingo:多模态大语言模型



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











