






1.Lora+
LoRA+[2]通过为矩阵a和b引入不同的学习率
2、VeRa
VeRA(Vector-based Random Matrix Adaptation)[3],引入了一种方法来大幅减少LoRA参数大小。他们没有训练矩阵A和B而是用共享的随机权值初始化这些矩阵(即所有层中所有矩阵A和B都具有相同的权值),并添加两个新的向量d和B,微调的时候只训练向量d和B
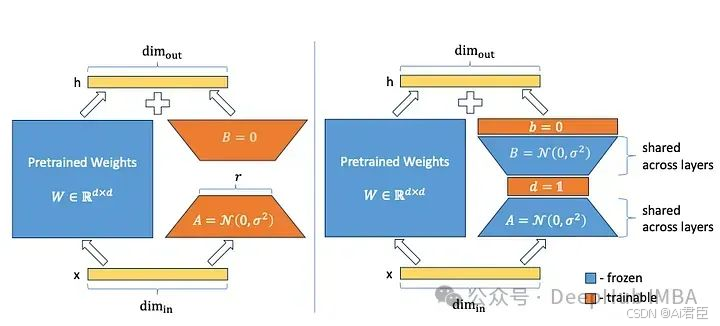
3、LoRA-FA
LoRA- fa[4],是LoRA与Frozen-A的缩写,在LoRA-FA中,矩阵A在初始化后被冻结,因此作为随机投影。矩阵B不是添加新的向量,而是在用零初始化之后进行训练(就像在原始LoRA中一样)。这将参数数量减半,同时具有与普通LoRA相当的性能。
4、LoRa-drop
Lora矩阵可以添加到神经网络的任何一层。LoRA-drop[5]则引入了一种算法来决定哪些层由LoRA微调,哪些层不需要
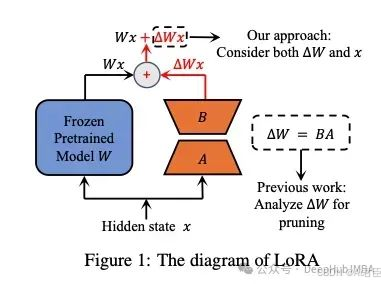
LoRA-drop包括两个步骤。在第一步中对数据的一个子集进行采样,训练LoRA进行几次迭代。然后将每个LoRA适配器的重要性计算为BAx,其中A和B是LoRA矩阵,x是输入。这是添加到冻结层输出中的LoRA的输出。如果这个输出很大,说明它会更剧烈地改变行为。如果它很小,这表明LoRA对冻结层的影响很小可以忽略。
选择最重要的LoRA层也有有不同的方法:可以汇总重要性值,直到达到一个阈值(这是由一个超参数控制的),或者只取最重要的n个固定n的LoRA层。无论使用哪种方法,还都需要在整个数据集上进行完整的训练(因为前面的步骤中使用了一个数据子集),其他层固定为一组共享参数,在训练期间不会再更改。
LoRA-drop算法允许只使用LoRA层的一个子集来训练模型。根据作者提出的证据表明,与训练所有的LoRA层相比,准确度只有微小的变化,但由于必须训练的参数数量较少,因此减少了计算时间。
5、AdaLoRA
有很多种方法可以决定哪些LoRA参数比其他参数更重要,AdaLoRA[6]就是其中一种,AdaLoRA的作者建议考虑将LoRA矩阵的奇异值作为其重要性的指标。
与上面的LoRA-drop有一个重要的区别是在LoRA-drop中层的适配器要么被完全训练,要么根本不被训练。而AdaLoRA可以决定不同的适配器具有不同的秩(在原始的LoRA方法中,所有适配器具有相同的秩)。
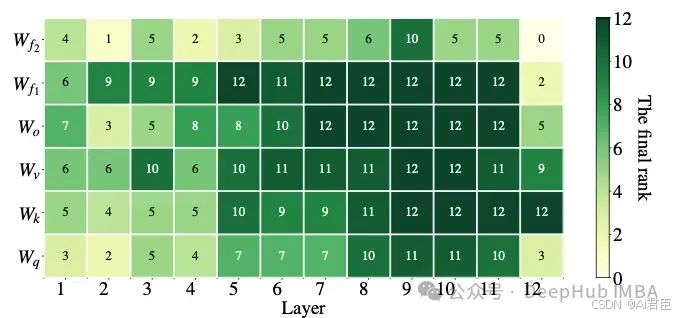
AdaLoRA与相同秩的标准LoRA相比,两种方法总共有相同数量的参数,但这些参数的分布不同。在LoRA中,所有矩阵的秩都是相同的,而在AdaLoRA中,有的矩阵的秩高一些,有的矩阵的秩低一些,所以最终的参数总数是相同的。经过实验表明AdaLoRA比标准的LoRA方法产生更好的结果,这表明在模型的部分上有更好的可训练参数分布,这对给定的任务特别重要。下图给出了AdaLoRA如何为给定模型分配排名的示例。正如我们所看到的,它给接近模型末尾的层提供了更高的秩,表明适应这些更重要。
6、Delta-LoRA
Delta-LoRA[8]引入了另一种改进LoRA的思想,让预训练矩阵W再次发挥作用。LoRA的主要思想是不要调整预训练矩阵W,因为这太费资源了。LoRA引入了新的较小的矩阵A和b,这些较小的矩阵学习下游任务的能力较差,所以LoRA训练的模型的性能通常低于微调模型的性能。
Delta-LoRA的作者提出用AB的梯度来更新矩阵W, AB的梯度是A*B在连续两个时间步长的差。这个梯度用超参数λ进行缩放,λ控制新训练对预训练权重的影响应该有多大。
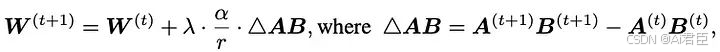



















 7520
7520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











