







 本文概述了自动驾驶中从视觉深度估计到BEV视角感知的转变,介绍了LSS、BEVDet、BEVerse和DETR3D等模型,展示了如何利用transformer和深度学习解决3D目标检测、语义分割等问题,以及这些模型如何简化pipeline并提升性能。
本文概述了自动驾驶中从视觉深度估计到BEV视角感知的转变,介绍了LSS、BEVDet、BEVerse和DETR3D等模型,展示了如何利用transformer和深度学习解决3D目标检测、语义分割等问题,以及这些模型如何简化pipeline并提升性能。
自动驾驶感知新范式——BEV感知经典论文总结和对比(一)
博主之前的博客大多围绕自动驾驶视觉感知中的视觉深度估计(depth estimation)展开,包括单目针孔、单目鱼眼、环视针孔、环视鱼眼等,目标是只依赖于视觉环视摄像头,在车身周围产生伪激光雷达点云(Pseudo lidar),可以模拟激光雷达的测距功能,辅助3D目标检测等视觉定位任务,而且比激光雷达更加稠密。这是自动驾驶视觉感知的一个热门研究方向。
关于自动驾驶视觉感知,最近两三年另外一个热门方向便是更为直接的bev视角下的视觉感知。不同于深度估计先显式获取各个像素点的深度,再支持其他相关任务,bev视角下可以实现端到端的目标检测、语义分割、轨迹预测等各项任务。由于这种方法pipline更加简单直接,且能够更好地被下游规控所使用(在同一个坐标系),近期相关研究工作达到井喷趋势,霸占各大SOTA榜单。现按照大致发展顺序介绍一系列经典模型,帮助感兴趣的小伙伴快速了解相关内容。

0 为什么要在bev视角下做感知
对于纯视觉的感知来说,准确地测距是最关键也是最难的问题。对单目测距来说,这是一个病态问题,对于图像中的物体,难以判断它是一个远处的大目标,还是一个近处的小目标。例如下图的场景,以我们的经验(对于车、人和建筑物尺度的大致判断)来说,镜头离道路上的车大概有几米到十几米的距离,但细看会发现这是一个仿真场景,假如人和车都是玩具的仿真,只有十几厘米高,那这个距离也就只有几十厘米而已了。

解决这个问题的一个方法是使用双目测距。传统方法是对双目进行严格的标定,利用特征点匹配+对极几何进行计算,但这种方法计算量很大,且严重依赖于标定质量,同时基线的长度限制了测距的范围,所以实际应用有较大的局限性。目前常用的视觉3D检测主要有以下两种方法:
1.基于视觉几何的方法
这种方法依赖很多假设和先验知识:
假设1:地面平坦,没有起伏和坑洞
假设2:目标接地,且可以看到接地点
先验1:目标的实际高度(或宽度,可以通过分类的方式与经验平均值回归得到),或照相机高度
先验2:相机的焦距
满足了以上假设并且已知相关先验,即可通过2D检测的结果,经过相似三角形关系,估算目标大致深度(如下图,深度Z=H *f / h),再通过内参转换,估算出3D box的位置。
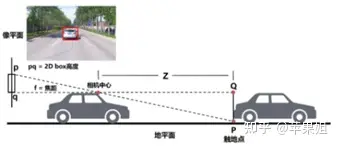
视觉几何深度估计
显而易见,这种方法局限性很多,首先两个假设和先验知识就很难获取,其次对于多视角目标检测来说,同一个目标可能同时出现在两个视角中,且都不完整,对其做拼接也非常困难。再次这种方法还依赖于2D检测的结果,即使检测框很准,由于目标角度的千变万化,也难以表征目标在2D空间中的实际高度,所以还需要大量的后处理工程进行优化。
2.基于深度估计的方法
即本文开头提到的方法:先得到伪激光雷达点云,再使用点云3D检测的方法,这类方法最大问题就是严重依赖于深度估计的结果,不能进行端到端的调优。由于深度估计方法的潜能目前并未挖掘充分,所以也对结果产生了局限性。
基于以上问题,具有上帝视角的鸟瞰图bird-eye-view(bev)是一个很好的解决方案。关于如何获取bev,传统方法是进行逆透视变换(IPM),即通过多相机的内外参标定,求得相机平面到地平面的单应性矩阵,实现平面到平面的转换,再进行多视角图像的拼接。效果如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5451
5451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









