







导言
最近一直在研究BEV的相关工作,导师给我推了这篇文章,是基于纯相机的。这里初步读一下论文,若有翻译或理解不准确的,请大家指正!
论文链接:2307.11477.pdf (arxiv.org)
下面按照李沐读论文的步骤,先看摘要,再看结论,顺便扫一眼实验和图,最后顺读。
Abstract
最近,基于纯摄像头的鸟瞰图(BEV)感知为经济型自动驾驶提供了可行的解决方案。然而,现有的基于BEV的多视角3D检测器一般将所有图像特征全转换为BEV特征,没有考虑大比例背景信息可能淹没目标信息的问题。本文提出了语义感知的BEV池化(SA-BEVPool),它可以根据图像特征的语义分割过滤出背景信息,并将图像特征转化为语义感知的BEV特征。相应的,我们提出了一种有效的数据增强策略BEV- paste,可与语义感知的BEV特征紧密匹配。此外,我们设计了一个多尺度交叉任务头(Multi-Scale Cross-Task, MSCT),将特定任务和跨任务信息相结合,更准确地预测深度分布和语义分割,进一步提高了语义感知BEV特征的质量。最后,我们将上述模块集成到一个新的多视图3D目标检测框架中,即SA-BEV。在nuScenes上的实验表明,SA-BEV达到了SOTA。
Conclusion and Discussion
为充分利用图像的语义信息,本文提出了SA-BEV。SA-BEVPool过滤背景虚拟点,生成语义感知的BEV特征。然后,BEV- Paste将两帧的语义感知BEV特征进行粘贴,以增强数据的多样性。MSCT头引入了多任务学习,促进了语义感知BEV特征的优化。
我们提出的内容具有很强的通用性。SA-BEVPool和BEV-Paste可以很容易地嵌入到大多数基于bev的检测器中,并带来稳定提升。此外,我们认为将多任务学习引入到语义感知BEV特征的生成中增加了一个有价值的视角,并将对未来的工作产生启发。
尽管如此,SA-BEV仍有局限性。SA-BEVPool使用的阈值是手动设置的,很难达到最佳性能。当将语义感知的BEV特征从一帧粘贴到另一帧时,可能会导致不正确的对象重叠和遮挡,这些就是我们接下来要解决的问题。我们还希望将SA-BEV扩展为多模态探测器,以激活图像和LiDAR之间的互补性。
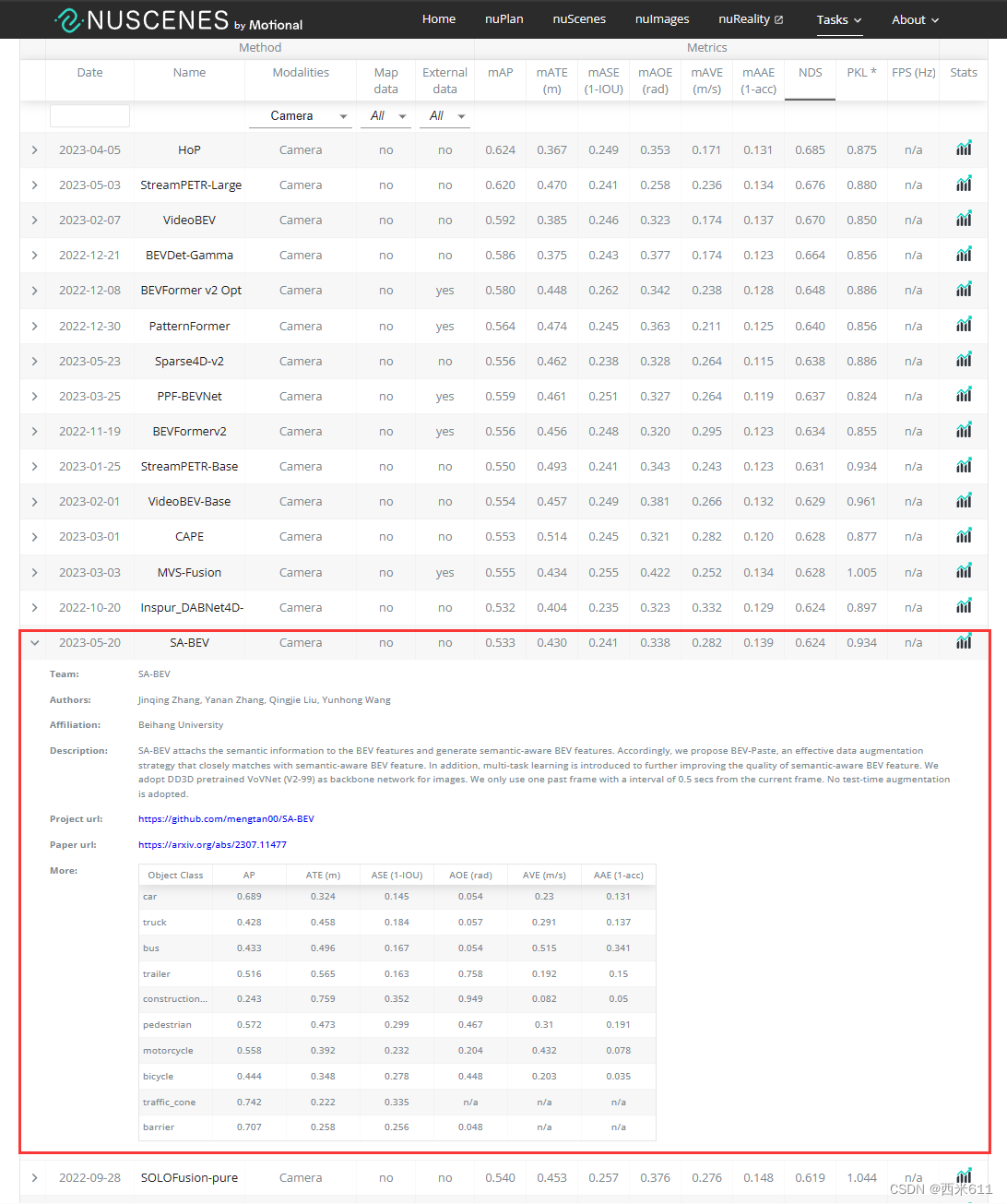
(根据文章给出的表格数据,可以看出SA-BEV相比其他多视角3D检测器精度更高)
Introduction
摄像头和激光雷达是两种最常用的3D物体检测传感器,这对自动驾驶系统至关重要。基于激光雷达的方法由于点云的空间结构信息准确,获得了优异的性能,但昂贵的激光雷达传感器降低了其通用性。相比之下,基于相机的方法成本相对较低,并且具有丰富的语义信息,但因缺乏几何深度线索而受到限制。
考虑到相机和激光雷达之间的性能差距,鸟瞰图模式将多视角图像特征转换为BEV特征,使后续的3D感知更加容易。这种实用且可调整的仅摄像头范例越来越受欢迎,数不清的优势使其能够达到高感知精度。BEV范式的核心步骤是从图像特征中生成虚拟点,这些虚拟点将被投影到“柱化”的BEV空间中,然后将同一柱子中虚拟点特征累积为BEV特征。然而,这种操作并没有充分利用图像特征的语义信息,而且会注入大量的背景信息,淹没了物体信息。
为了充分利用图像特征有价值的语义信息,本文提出了语义感知的BEV池化(SA-BEVPool)来生成语义感知的BEV特征,以取代常规的BEV特征进行3D检测。在将虚拟点投影到BEV空间之前,首先对图像特征的语义分割进行预测。如果一个虚拟点是由属于背景的图像元素生成的,它将不会被投影到BEV空间中。同样,具有低深度分数的虚拟点也将被忽略。正常的BEV特征与语义感知BEV特征的对比如图1所示。SA-BEVPool可以明显滤除大部分背景BEV特征,缓解背景信息占比过大淹没目标信息的问题,有效提高检测性能。一些多模态3D目标器在结合LiDAR特征时也会对图像进行分割,但它们通常使用CenterNet2等功能强大的实例分割网络来预测大尺度图像的分割。相比之下,SA-BEVPool可以很容易地应用于当前基于BEV的检测器,如BEVDepth和BEVStereo,通过使用它们的深度分支同时预测小尺度图像特征的语义分割。

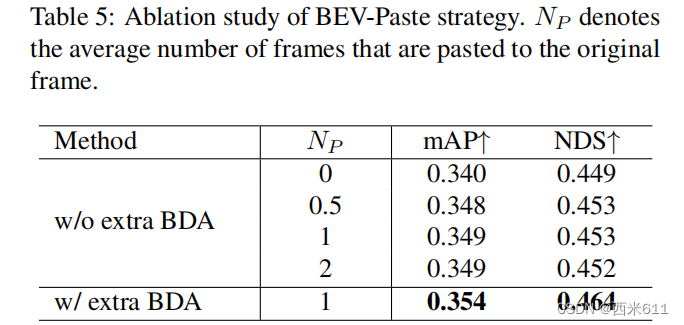
GT-Paste是一种成功的数据增强策略,已被各种基于雷达的3D探测器频繁采用。然而,由于模态的区别,它不能直接适应基于相机的3D探测器。在我们的工作中,幸于有可靠的深度分布和基于图像特征的语义分割,语义感知的BEV特征可以近似地表示在BEV空间中适当位置的所有对象的信息。因此,将另一帧的语义感知BEV特征添加到当前语义感知BEV特征中,相当于将另一帧的所有对象粘贴到当前帧中。这种策略,我们称之为BEV-Paste,以类似于GT-Paste的方式增强数据多样性。
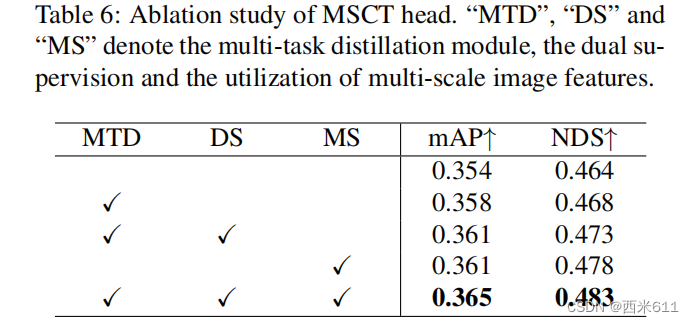
虽然用同一分支预测深度分布和语义分割很方便,但这样做可能会导致非最优的语义感知BEV特征。多任务学习领域的研究结论表明,特定任务和跨任务信息的整合更有利于多个预测任务的最优解。受此启发,我们设计了一个多尺度交叉任务头(MSCT) ,通过多任务蒸馏和对多尺度预测的双重监督来结合特定任务和跨任务信息。
我们将提出的模块集成为一个整体,并将其命名为SA-BEV。在nuScenes数据集上的大量实验表明,SA-BEV达到了SOTA。综上所述,本文的主要贡献有:
- 我们提出了SA-BEVPool,它利用语义信息过滤掉不必要的虚拟点,并生成语义感知的BEV特征,从而缓解了大比例背景信息淹没目标信息的问题。
- 我们提出了一种有效、便捷的数据增强策略BEV-Paste,该策略与语义感知的BEV特征紧密匹配,增强了数据的多样性,进一步提高了检测性能。
- 我们提出了通过多任务学习在多尺度上结合特定任务和跨任务信息的MSCT头,促进了语义感知BEV特征的优化。
Related Work
Vision-based 3D Object Detection
(这一部分主要介绍了以前的基于相机一些工作,都是一笔带过。然后讲他们都忽略了什么,从而提出本文的创新点。我曾细读过BEVFormer,大家想了解可以看这篇)
虽然相机不能像LiDAR那样提供可靠的环境深度,但图像所携带的丰富语义信息仍然支持基于视觉的3D物体探测器达到相当高的精度。早期基于视觉的3D检测器直接从2D图像特征预测3D物体的属性。例如,CenterNet,一个2D检测器,可以不加很多修改就用来预测3D物体。而FCOS3D检测3D物体的2D中心,并利用中心周围的特征来预测3D属性。PGD通过建立几何关系图来改善深度估计结果,从而更好地检测3D物体。DETR3D遵循DETR,通过Transformer来检测3D物体。PETR引入了3D位置感知表示,提高了检测精度。PETRv2进一步引入了时间信息,提高了效率。
最近,LSS提出了一种将图像特征转化为BEV特征的方法,BEVDet利用CenterPoint的检测头从BEV特征中预测3D物体。该范式无需繁琐的操作即可达到相当高的精度,并且易于扩展,因此受到欢迎。BEVDet4D对多个关键帧进行处理,引入时间信息。BEVFormer利用可变形注意力机制生成BEV特征。BEVDepth对预测的潜在深度分布进行显式深度监督,提高了检测精度。BEVStereo通过在相邻关键帧上应用多视图立体,进一步提高了深度质量。PolarFormer使用极坐标生成BEV特征,以获得更精确的定位。然而,这些方法都将所有图像特征投影到BEV特征中,没有考虑到大比例背景信息可能淹没目标信息的问题。在本文中,我们提出了SA-BEVPool,它可以根据图像特征的语义分割来过滤背景信息,并生成语义感知的BEV特征。
Data Augmentation in 3D Object Detection
数据集的多样性对模型的泛化性能至关重要。除了随机缩放、翻转和旋转等常规数据增强外,GT-Paste是基于Lidar的探测器经常使用的另一种有效策略。它根据地面真实的3D包围框裁剪点,并将其粘贴到其他帧以创建新的训练数据。最近,有人提出了一种改进的方法来生成能见度图,以纠正GT-Paste引入的错误遮挡关系。还有人提出了对单个对象的增强,将对象点分成多个部分,并对其进行dropout、swap、mix等操作。
由于GT-Paste在增加数据多样性方面表现出优异的效果,因此已经有一些尝试将其应用于仅相机的3D检测器中。Box-Mixup和BoxCut-Paste是直接根据图像的2D边界框将物体从图像中剪切出来,粘贴到其他帧中。为了精确粘贴,对象被它们的实例蒙版裁剪。Pointaugmenting采用了一种更复杂的方法来处理原始物体和粘贴物体的遮挡关系。然而,这些将GT-Paste扩展到图像空间的尝试并不能轻易克服激光雷达和相机之间的差距所带来的问题。在本文中,我们提出了BEV-Paste,可以借助SA-BEVPool将GT-Paste有效扩展到基于BEV的方法。
Multi-task Learning
多任务学习通常通过多任务之间的交互学习来实现更好的预测。特定任务信息和跨任务信息对于在多任务中获得最佳结果都很重要。PAD-Net提出了多模态蒸馏模块来自动补充跨任务信息。PAP-Net提取跨任务关联模式,并通过相似度矩阵递归地传递模式。MTI-Net对不同尺度的任务相互作用进行建模,并聚合多尺度信息以进行精确预测。
一些方法还将多任务学习引入到3D目标检测中。MMF通过对多个任务同时进行监督,将图像和激光雷达特征深度融合。而有的工作中估计了潜在支撑面,以帮助提高3D检测的精度。还有人提出了多任务LiDAR网络,对3D检测和道路理解进行预测,可以相互补充。一些基于BEV的3D检测器也采用BEV分割来获得更好的BEV表示。在本文中,我们提出了结合多尺度的特定任务和跨任务信息的MSCT头进行深度估计和语义分割,促进了语义感知BEV特征的优化。
Method
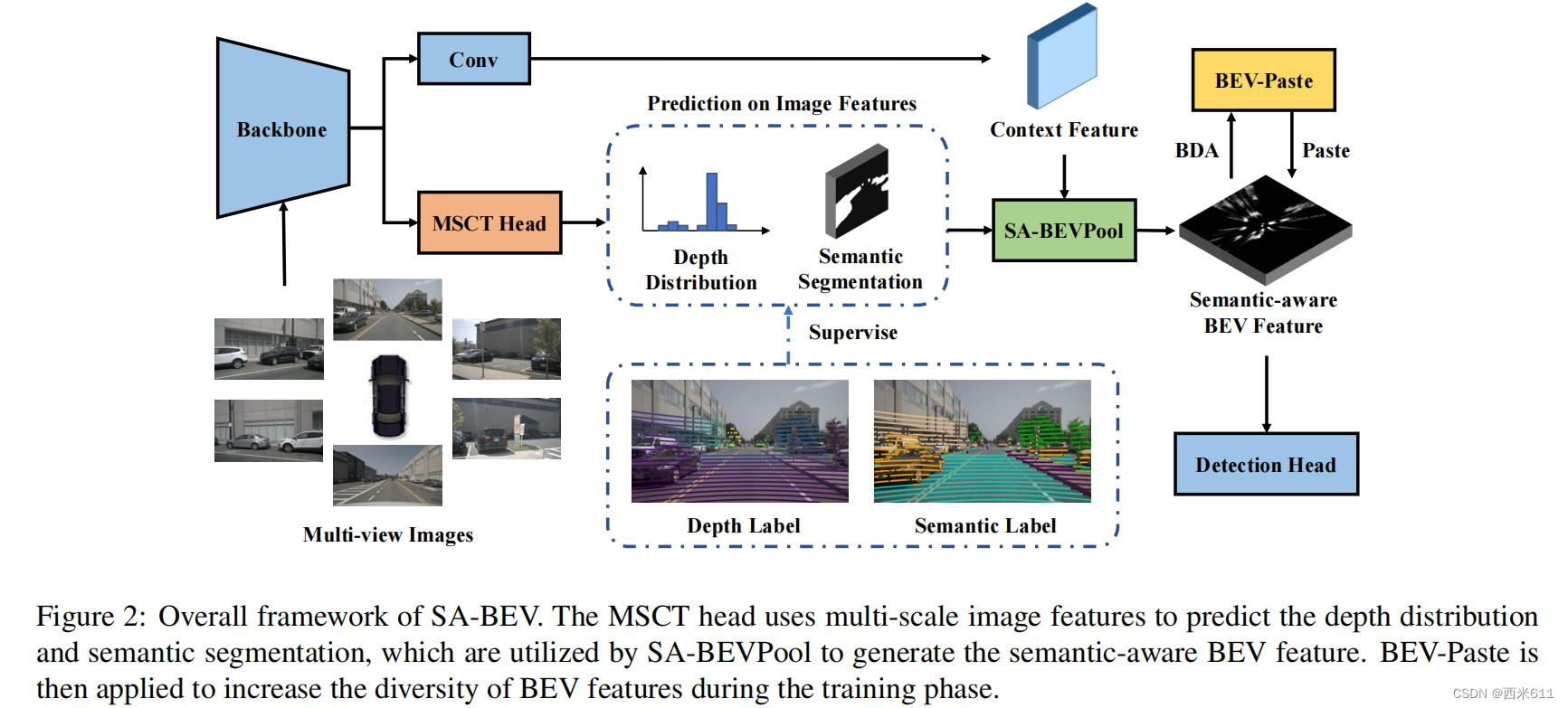
在这项工作中,我们提出了SA-BEV,这是一种新的多视图3D物体检测框架,可以生成语义感知的BEV特征,以获得更好的检测性能。它包含语义感知的BEV池化(SA-BEVPool)、数据增强策略BEV-Paste和多尺度交叉任务头(MSCT)。SA-BEV的总体框架如图2所示。
Semantic-Aware BEV Pooling
将图像特征转化为BEV特征以获得更好感知的方法是由LSS首先提出的。它预测每个图像特征元素的深度分布和上下文特征c。每个元素在不同深度生成虚拟点,深度d处的点的特征被表示为
。之后,所有的虚拟点将被投影到BEV空间中,而BEV空间被划分为柱子。同一支柱中虚拟点的特征将被积累作为BEV特征,这个过程被称为BEV池化。
随后的基于BEV的3D检测器显著提高了BEV池化的效率和准确性。但不变的是,这些方法坚持将所有虚拟点投影到BEV空间中。然而,我们认为这对于3D检测任务是不必要的。相反,如果将所有属于背景的虚拟点都投影出来,那么占虚拟点总数不到2%的前景虚拟点就会被淹没,从而混淆后面的检测头,降低检测精度。
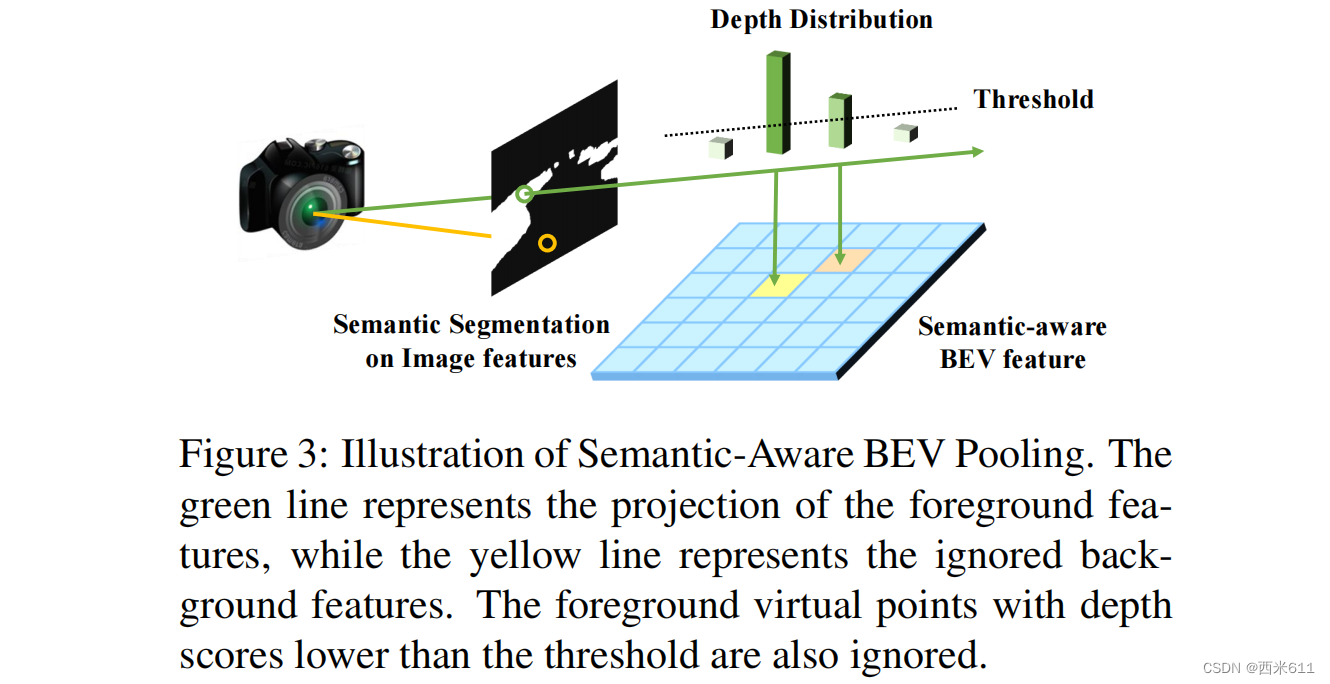
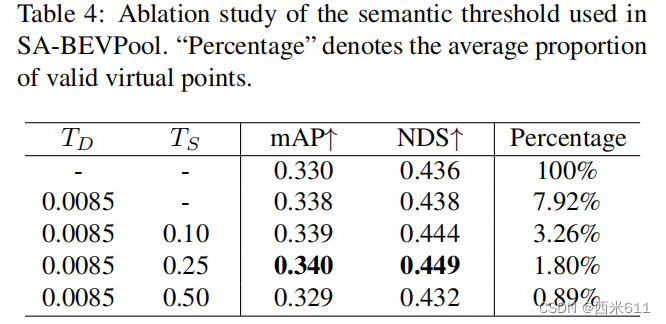
为了突出BEV特征中有价值的前景信息,我们提出了一种新的语义感知BEV池化(SA-BEVPool),如图3所示。它对图像特征进行语义分割,得到每个元素的前景分数ß。低分数的元素更有可能携带无用的检测信息,在BEV池化过程中,由其产生的虚拟点将被忽略。同样,值低的虚拟点提供的信息也不重要,也将被忽略。将过滤函数记为:
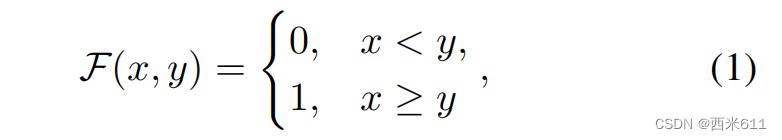
过滤后的点特征被改为:
![]()
其中和
是
和β的阈值。只有非空的
才会构造BEV特征。由于对相对低值的虚拟点进行过滤的操作将语义信息附加到了生成的BEV特征上,因此可以将其称为语义感知的BEV特征。
正常BEV特征与语义感知BEV特征的区别如图1所示。第一行的正常BEV特征一般在中心有一圈光,代表地面。它占了特征中大部分的信号强度,却没有为检测提供有用的信息。相比之下,语义感知的BEV特征去除了大部分背景信息,强调了目标信息。此外,在语义感知的BEV特征中,目标信息的位置与地面真实情况匹配良好,使得检测头更容易预测准确。
BEV-Paste
GT-Paste是基于Lidar的3D探测器常用的数据增强策略。实验证明,通过对3D包围框中的点进行采样并粘贴到其他帧中,可以有效地增加数据集的多样性。然而,一些问题阻碍了GT-Paste在基于摄像机的方法中的应用。首先,在图像上用边界框对物体进行采样,不能像点云那样得到物体的纯数据。另一个问题是,将物体粘贴到另一张图像上可能会错误地遮挡原始物体,导致数据丢失。此外,不同帧的光照变化也给粘贴的物体带来了不自然的外观。一些多模态3D探测器努力解决了这些问题,但普遍缺乏方便性和准确性。
在这里,我们提出了BEV-Paste,它成功地将GT-Paste应用于仅相机的3D探测器中,而无需复杂的步骤。利用SA-BEVPool,由图像特征变换而来的语义感知BEV特征近似表示了帧内所有物体的信息,如图1所示。它使得在训练阶段添加任意两帧的语义感知BEV特征等同于将两帧中包含的对象聚合到一起。BEV-Paste在有效增加整个训练数据集多样性的同时,不会增加推理阶段的计算成本。
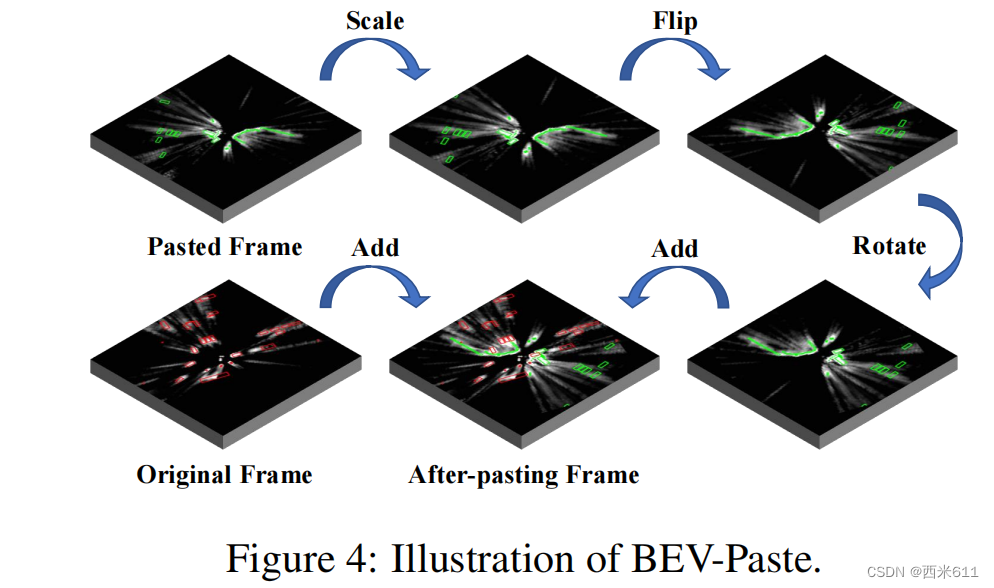
在实践中,我们从同一批次中随机选择原始的语义感知BEV特征Bo和用于粘贴的语义感知BEV特征Bp。这是为了保证Bo和Bp遵循相同的分布。我们不是直接将Bp粘贴到Bo上,而是首先将图4所示的额外BEV数据增强(BDA)应用到Bp上,得到,以防止Bp的数据重复。对粘贴的帧Gp进行同样的增强,得到
。BEV-Paste后的检测损失可表示为:
![]()
其中Det包括BEV编码器和检测头,Go为原始帧的ground truth。
Multi-Scale Cross-Task Head
利用深度分支同时预测语义分割,是获得语义感知的BEV特征的一种便捷方法,但其结果往往非最优。让我们把生成语义感知的BEV特征看作是一个多任务学习应用。根据研究结论,任务特定信息和跨任务信息对于获得多任务全局最优解都很重要。如果深度分布和语义分割由同一网络分支预测,则网络只能从图像特征中提取跨任务信息,不能在每个任务上都实现最优。
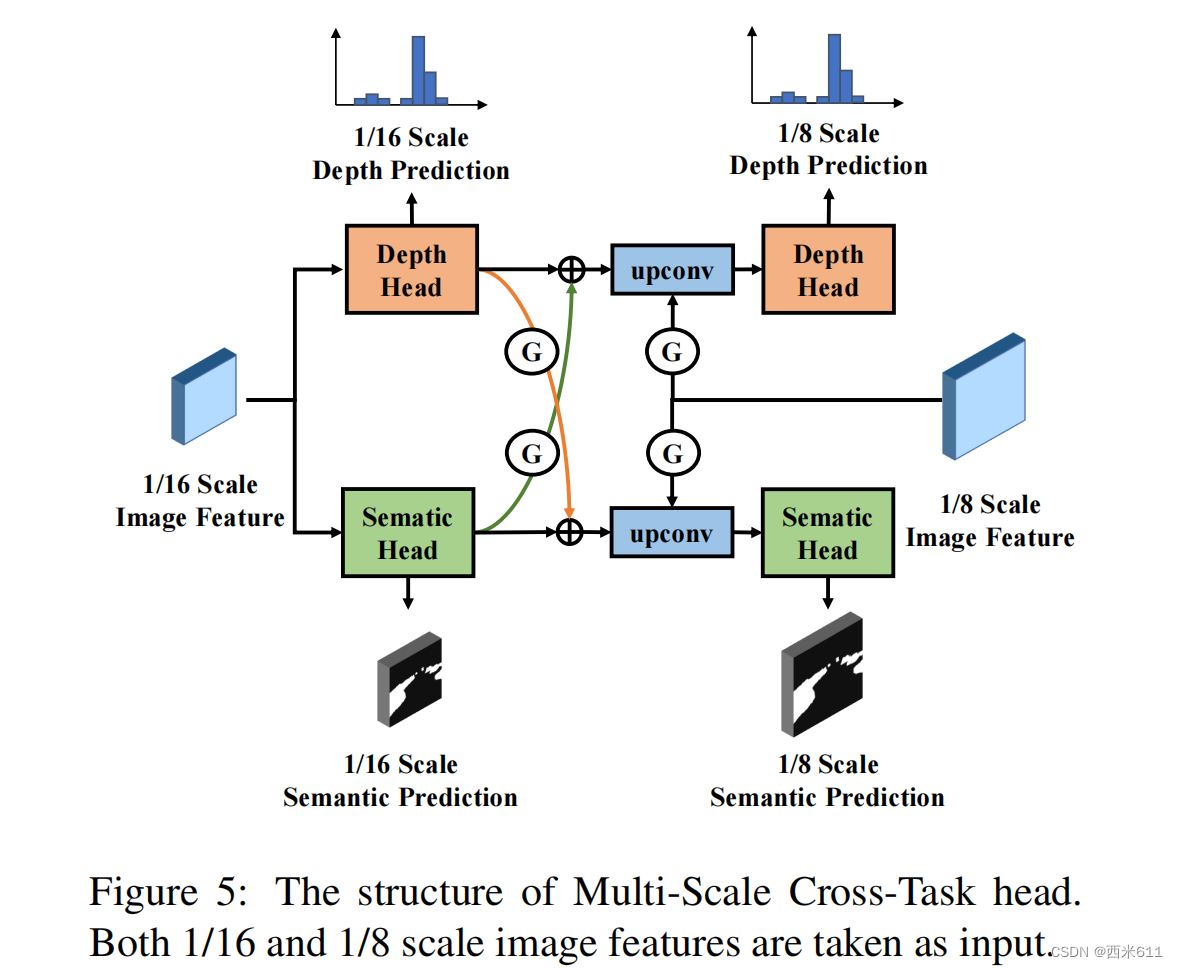
受多任务学习原理的启发,我们设计了一个多尺度交叉任务头(MSCT),如图5所示。在第一阶段,头部以1/16尺度的图像特征作为输入,对深度分布和语义分割进行较为粗略的预测。之后,将
转化为深度特征
和语义特征
,分别携带各自任务的特定任务信息。为了补充跨任务信息,在
和
之间应用多任务蒸馏(Multi-Task Distillation, MTD)模块,它由多个自注意块组成,通过下式生成门图:
![]()
其中为门卷积,σ为sigmoid函数。跨任务信息补充的特征可表述为:
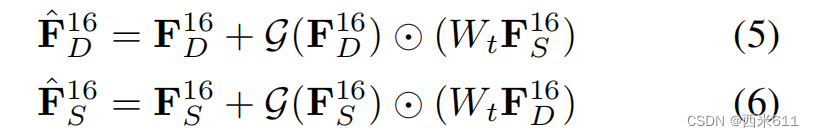
其中,其中Wt为任务卷积,表示元素乘法。很明显,MTD使用这些自注意块从一个任务特征中自动提取跨任务信息,并将其添加到其他任务特征中。
任务特征交互之后,和
获取任务特定信息和跨任务信息。在将它们输入到第二阶段预测头之前,它们被上采样到1/8尺度,并使用相同的自注意块与1/8尺度的图像特征
相结合。特征可以表述为:
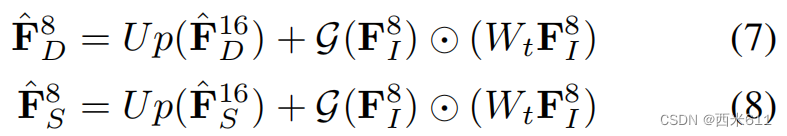
第二阶段头随后预测相对精细的深度分布和语义分割,这些深度分布和语义分割将用于生成语义感知的BEV特征。
在训练过程中,对1/16和1/8尺度的预测都进行监督。它保证了第一级头可以获取特定任务信息,第二阶段头可以将特定任务信息与跨任务信息相结合。监督信号是通过在图像上投影点云获得的。投影点的深度值为深度标签,三维方框中的点为前景。总损失可表示为:
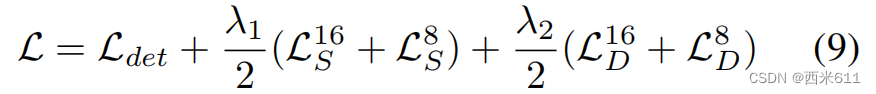
Experiments
在本节中,我们首先介绍我们的实验设置。然后,与先前最先进的多视角3D探测器进行了比较。最后,对SA-BEV进行了全面的实验和详细的消融研究,以展示SA-BEVPool、BEV-Paste和MSCT头各部分的有效性。
Experimental Settings
Dataset and Metrics
nuScenes数据集是一个大规模的自动驾驶基准。它包含750个训练场景,150个验证场景和150个测试场景。每个场景持续约20秒,关键样本以2Hz注释。每个样本都有6个摄像头、1个激光雷达和5个雷达收集的数据。对于3D目标检测,提出了nuScenes检测分数(NDS)来捕捉nuScenes检测任务的各个方面。除平均精度(mAP)外,NDS还与5类真阳性度量(TP度量)相关,包括平均平移误差(mATE)、平均尺度误差(mASE)、平均方向误差(mAOE)、平均速度误差(mAVE)、平均属性误差(mAAE)。
Implementation Detail
我们完成了对BEVDepth网络结构的改进。我们的实验是基于MMDetection3D和8个NVIDIA GeForce RTX 3090 GPU实现的。使用AdamW优化器训练模型,使用梯度修剪。我们对图像和BEV特征采用的通用数据增强遵循[10]中的配置。对于消融研究,我们使用ResNet-50作为图像主干,图像尺寸下采样到256x704。用于消融研究时,这些模型在没有CBGS策略的情况下进行了24个epoch的训练。当与其他方法相比时,采用CBGS策略对模型进行了20个epoch的训练。
Main Results
Comparison with State-of-the-Arts
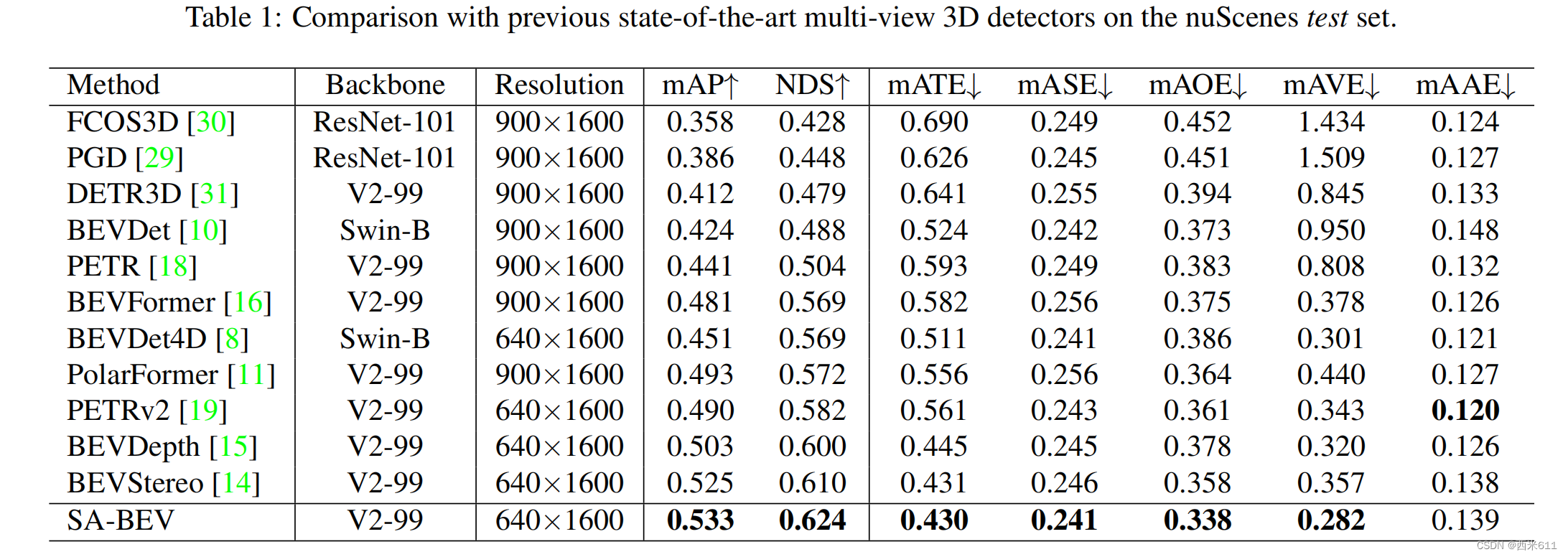
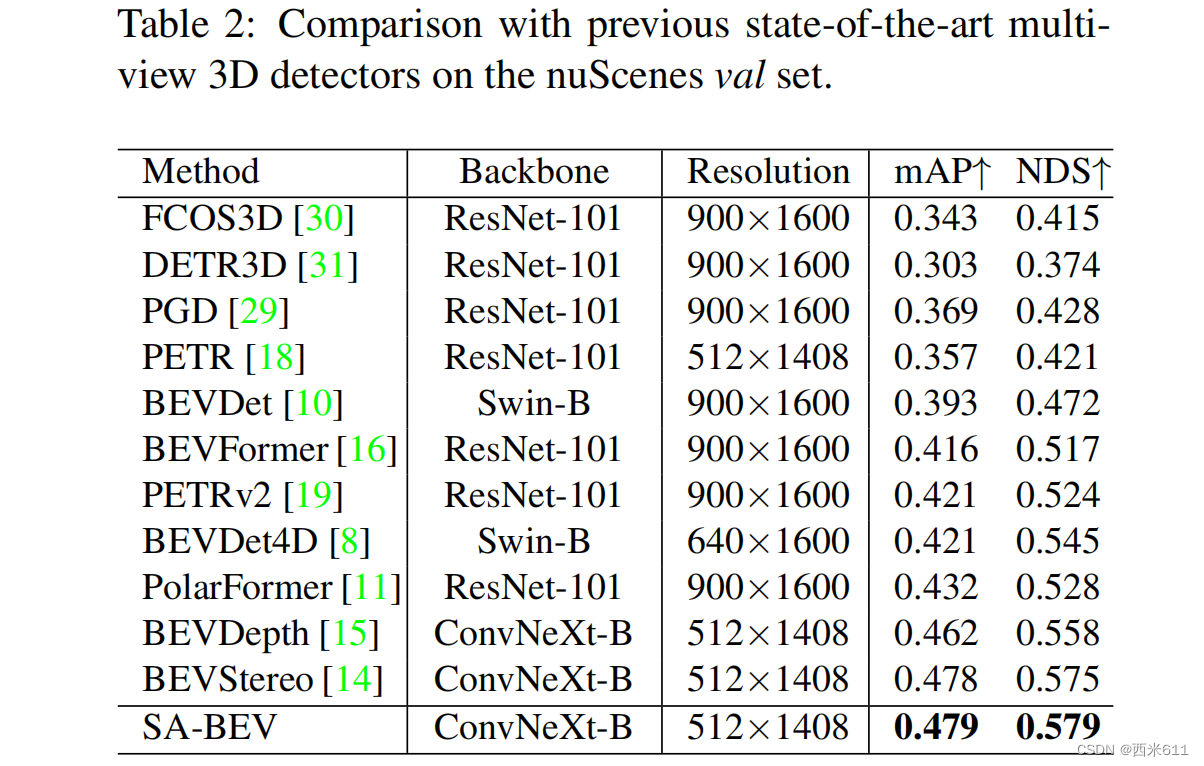
我们将SA-BEV与nuScenes测试集上最先进的多视图3D探测器进行了比较,并将结果显示在表1中。我们以640×1600分辨率图像为输入,以VoVNet-99为图像主干。SA-BEV获得了最好的mAP和NDS,分别比其基线(即BEVDepth)高3.0%和2.4%。它也比BEVStereo高出0.8%的mAP和1.4%的NDS,后者采用复杂的多视点立体结构,深度估计更加准确。nuScenes验证集的比较见表2。可以发现,SA-BEV也达到了最好的检测精度。良好的结果突出了SA-BEV的优势。
Visualization
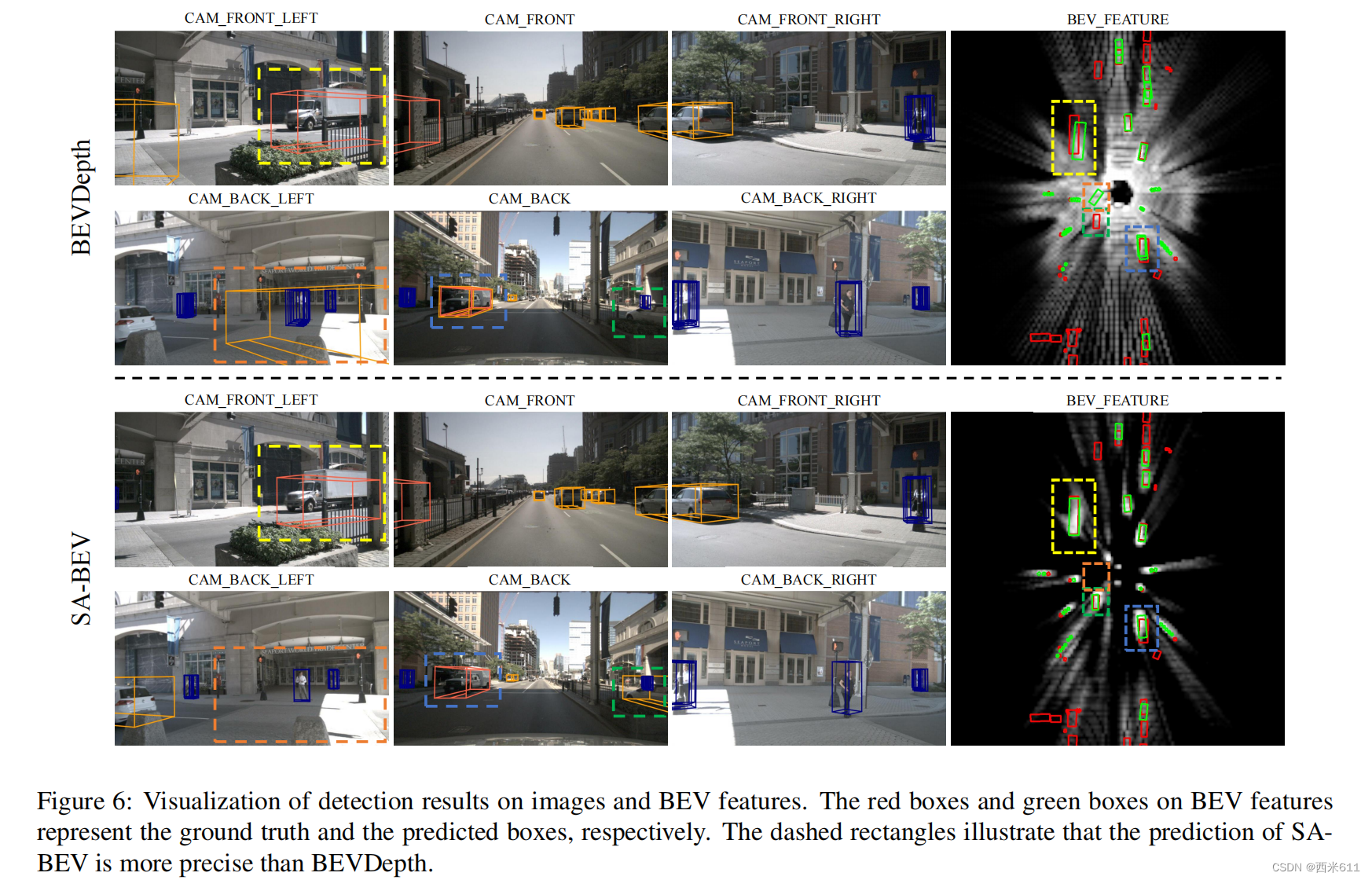
我们在图6中可视化图像和BEV特征上的检测结果。与BEVDepth相比,SA-BEV可以借助语义感知的BEV特征做出了更精确的预测。例如,橙色的虚线矩形表明,背景的过滤可以防止SA-BEV误检。黄色虚线矩形表示语义感知的BEV特征正确地强调了卡车的位置,从而实现了精确的检测。此外,绿色/蓝色虚线矩形显示SA-BEV可以成功召回缺失的对象并移除冗余检测框。
Ablation Study
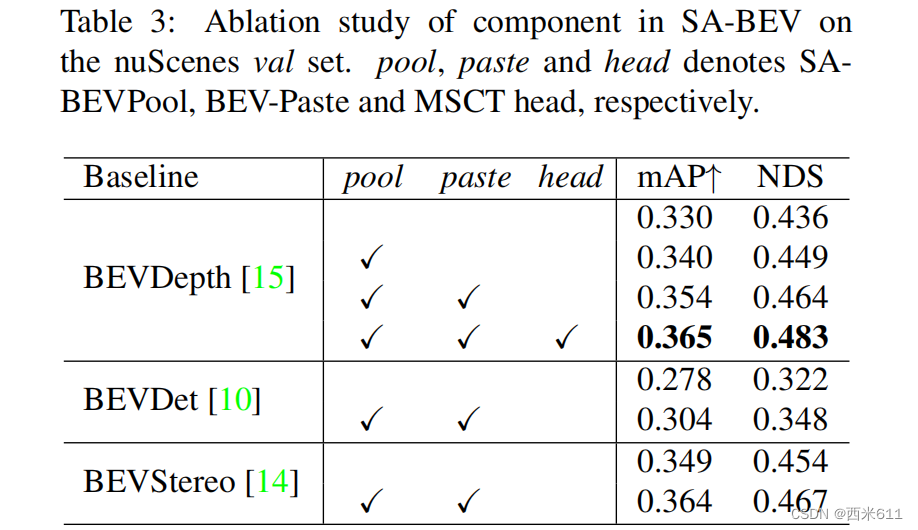
Component Analysis
(此部分我只放了表格数据)
Semantic-Aware BEV Pooling
BEV-Paste
Multi-Scale Cross-Task Head
结语
阅读笔记到这里就分享完毕了。其实这篇文章还是挺简洁明了的,我个人觉得多模态的会更有难度。但是,要想深挖细节,还是要去看源码,最好能自己跑一下。之后有机会,我也会去试验一下。感谢观看:)















 1311
1311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









