









文章目录
使用Python实现LLM的对抗训练:生成对抗网络(GAN)结合
引言
近年来,大型语言模型(LLM)在自然语言处理(NLP)领域取得了显著的进展。然而,随着模型规模的增大,如何进一步提升模型的鲁棒性和生成质量成为了一个重要的研究方向。对抗训练(Adversarial Training)作为一种有效的技术手段,已经在图像生成和分类任务中取得了成功。本文将探讨如何将生成对抗网络(GAN)与LLM结合,通过对抗训练提升语言模型的性能。
1. 生成对抗网络(GAN)简介
生成对抗网络(GAN)由Ian Goodfellow等人于2014年提出,其核心思想是通过两个神经网络的对抗训练来生成数据。GAN由两个主要部分组成:生成器(Generator)和判别器(Discriminator)。生成器的任务是生成与真实数据相似的假数据,而判别器的任务是区分真实数据和生成器生成的假数据。通过这种对抗过程,生成器逐渐学会生成更加逼真的数据。
1.1 GAN的基本结构
-
生成器(Generator):生成器通常是一个神经网络,它接收随机噪声作为输入,并生成与真实数据相似的输出。在图像生成任务中,生成器的输出是一张图像;在文本生成任务中,生成器的输出是一段文本。
-
判别器(Discriminator):判别器也是一个神经网络,它接收真实数据和生成器生成的假数据作为输入,并输出一个概率值,表示输入数据是真实数据的概率。
1.2 GAN的训练过程
GAN的训练过程可以看作是一个极小极大博弈(Minimax Game)。生成器试图最小化判别器的判别能力,而判别器试图最大化其判别能力。具体来说,GAN的训练目标可以表示为以下损失函数:
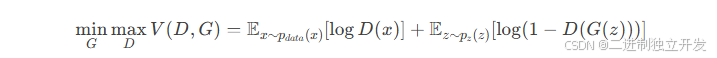
其中,( p_{data}(x) ) 是真实数据的分布,( p_z(z) ) 是随机噪声的分布,( D(x) ) 是判别器对真实数据的输出,( D(G(z)) ) 是判别器对生成器生成的假数据的输出。
2. 大型语言模型(LLM)简介
大型语言模型(LLM)如GPT-3、BERT等,已经在各种NLP任务中展现了强大的能力。这些模型通常基于Transformer架构,通过大规模预训练和微调来实现对自然语言的理解和生成。
2.1 Transformer架构
Transformer架构由Vaswani等人于2017年提出,其核心是自注意力机制(Self-Attention Mechanism)。自注意力机制允许模型在处理输入序列时,动态地关注序列中的不同部分,从而捕捉长距离依赖关系。
2.2 预训练与微调
LLM通常通过两个阶段进行训练:预训练和微调。在预训练阶段,模型在大规模文本数据上进行无监督学习,学习语言的通用表示。在微调阶段,模型在特定任务的有标签数据上进行有监督学习,以适应特定任务的需求。
3. GAN与LLM的结合
将GAN与LLM结合,可以通过对抗训练提升语言模型的生成质量和鲁棒性。具体来说,生成器可以是一个语言模型,负责生成文本;判别器可以是另一个神经网络,负责区分生成的文本和真实文本。
3.1 生成器的设计
在GAN与LLM结合的场景中,生成器通常是一个预训练的语言模型,如GPT-2或GPT-3。生成器的任务是生成与真实文本相似的假文本。生成器的输入可以是随机噪声或特定的提示文本(Prompt),输出是一段生成的文本。
3.2 判别器的设计
判别器可以是一个基于Transformer的神经网络,负责区分生成的文本和真实文本。判别器的输入是一段文本,输出是一个概率值,表示输入文本是真实文本的概率。判别器的设计需要考虑文本的语义和语法特征,以便准确区分真假文本。
3.3 对抗训练过程
在对抗训练过程中,生成器和判别器交替进行训练。具体步骤如下:
-
训练判别器:固定生成器,使用真实文本和生成器生成的假文本训练判别器,使其能够准确区分真假文本。
-
训练生成器:固定判别器,使用生成器生成假文本,并通过判别器的反馈调整生成器的参数,使其生成的文本更加逼真。
通过这种交替训练过程,生成器逐渐学会生成更加逼真的文本,而判别器也逐渐提高其判别能力。
4. 使用Python实现GAN与LLM的结合
接下来,我们将使用Python和PyTorch实现一个简单的GAN与LLM结合的模型。我们将使用GPT-2作为生成器,并设计一个基于Transformer的判别器。
4.1 环境准备
首先,我们需要安装所需的Python库:
pip install torch transformers
4.2 加载预训练的GPT-2模型
我们将使用Hugging Face的transformers库加载预训练的GPT-2模型作为生成器。
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# 加载预训练的GPT-2模型和分词器
model_name = "gpt2"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
generator = GPT2LMHeadModel.from_pretrained(model_name)
4.3 设计判别器
我们将设计一个基于Transformer的判别器。判别器的输入是一段文本,输出是一个概率值,表示输入文本是真实文本的概率。
import torch
import torch.nn as nn
class Discriminator(nn.Module):
def __init__(self, hidden_size=768, num_classes=1):
super(Discriminator, self).__init__()
self.transformer = nn.TransformerEncoderLayer(d_model=hidden_size, nhead=8)
self.fc = nn.Linear(hidden_size, num_classes)
self.sigmoid = nn.Sigmoid()
def forward(self, input_ids):
# 通过Transformer编码器
transformer_output = self.transformer(input_ids)
# 取最后一个时间步的输出
last_hidden_state = transformer_output[:, -1, :]
# 通过全连接层和Sigmoid激活函数
logits = self.fc(last_hidden_state)
prob = self.sigmoid(logits)
return prob
4.4 对抗训练过程
接下来,我们将实现对抗训练过程。我们将交替训练判别器和生成器。
# 初始化判别器
discriminator = Discriminator()
# 定义优化器
optimizer_G = torch.optim.Adam(generator.parameters(), lr=1e-5)
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=1e-5)
# 定义损失函数
criterion = nn.BCELoss()
# 训练过程
for epoch in range(num_epochs):
for real_text in real_texts:
# 训练判别器
optimizer_D.zero_grad()
# 生成假文本
fake_text = generator.generate(input_ids, max_length=50)
fake_text_ids = tokenizer.encode(fake_text, return_tensors="pt")
# 计算判别器的输出
real_prob = discriminator(real_text_ids)
fake_prob = discriminator(fake_text_ids)
# 计算判别器的损失
real_loss = criterion(real_prob, torch.ones_like(real_prob))
fake_loss = criterion(fake_prob, torch.zeros_like(fake_prob))
d_loss = real_loss + fake_loss
# 反向传播和优化
d_loss.backward()
optimizer_D.step()
# 训练生成器
optimizer_G.zero_grad()
# 生成假文本
fake_text = generator.generate(input_ids, max_length=50)
fake_text_ids = tokenizer.encode(fake_text, return_tensors="pt")
# 计算判别器的输出
fake_prob = discriminator(fake_text_ids)
# 计算生成器的损失
g_loss = criterion(fake_prob, torch.ones_like(fake_prob))
# 反向传播和优化
g_loss.backward()
optimizer_G.step()
4.5 结果分析
通过对抗训练,生成器逐渐学会生成更加逼真的文本,而判别器也逐渐提高其判别能力。我们可以通过观察生成器生成的文本质量来评估模型的性能。
5. 总结
本文探讨了如何将生成对抗网络(GAN)与大型语言模型(LLM)结合,通过对抗训练提升语言模型的生成质量和鲁棒性。我们使用Python和PyTorch实现了一个简单的GAN与LLM结合的模型,并通过对抗训练过程展示了模型的训练过程。未来,我们可以进一步探索如何优化生成器和判别器的设计,以及如何将对抗训练应用于更复杂的NLP任务中。
通过本文的介绍,希望读者能够理解GAN与LLM结合的基本原理,并能够在实际项目中应用这一技术,提升语言模型的性能。


















 899
899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











