







混淆矩阵
| . | 预测正确(接受) | 预测错误(拒绝) | |
|---|---|---|---|
| 真 | TP T P | TN T N (第一类分类错误,去真) | P P |
| 假 | (第二类分类错误,存伪) | FN F N | N N |
列表示:实际属性
行表示:预测值
第一类分类错误TN T N
第二类分类错误FP rate F P r a t e
FP Rate=FPN=FPTN+FP F P R a t e = F P N = F P T N + F PSpecificity S p e c i f i c i t y
Specificity=1−FP Rate=TNN=TNFN+FP S p e c i f i c i t y = 1 − F P R a t e = T N N = T N F N + F PRecall R e c a l l
Recall=TPP=TPTP+TN R e c a l l = T P P = T P T P + T NPrecision P r e c i s i o n
Precision=TPTP+FP P r e c i s i o n = T P T P + F PAccuracy A c c u r a c y
- Accuracy=TP+FNP+N A c c u r a c y = T P + F N P + N
-
F−score
F
−
s
c
o
r
e
F−Score=Precision×Recall F − S c o r e = P r e c i s i o n × R e c a l l
以上这些都属于静态的指标,当正负样本不平衡时它会存在着严重的问题。极端情况下比如正负样本比例为1:99(这在有些领域并不少见),那么一个基准分类器只要把所有样本都判为负,它就拥有了99%的精确度,但这时的评价指标是不具有参考价值的。另外就是,现代分类器很多都不是简单地给出一个0或1的分类判定,而是给出一个分类的倾向程度,比如贝叶斯分类器输出的分类概率。对于这些分类器,当你取不同阈值,就可以得到不同的分类结果及分类器评价指标,依此人们又发明出来ROC曲线以及AUC(曲线包围面积)指标来衡量分类器的总体可信度。
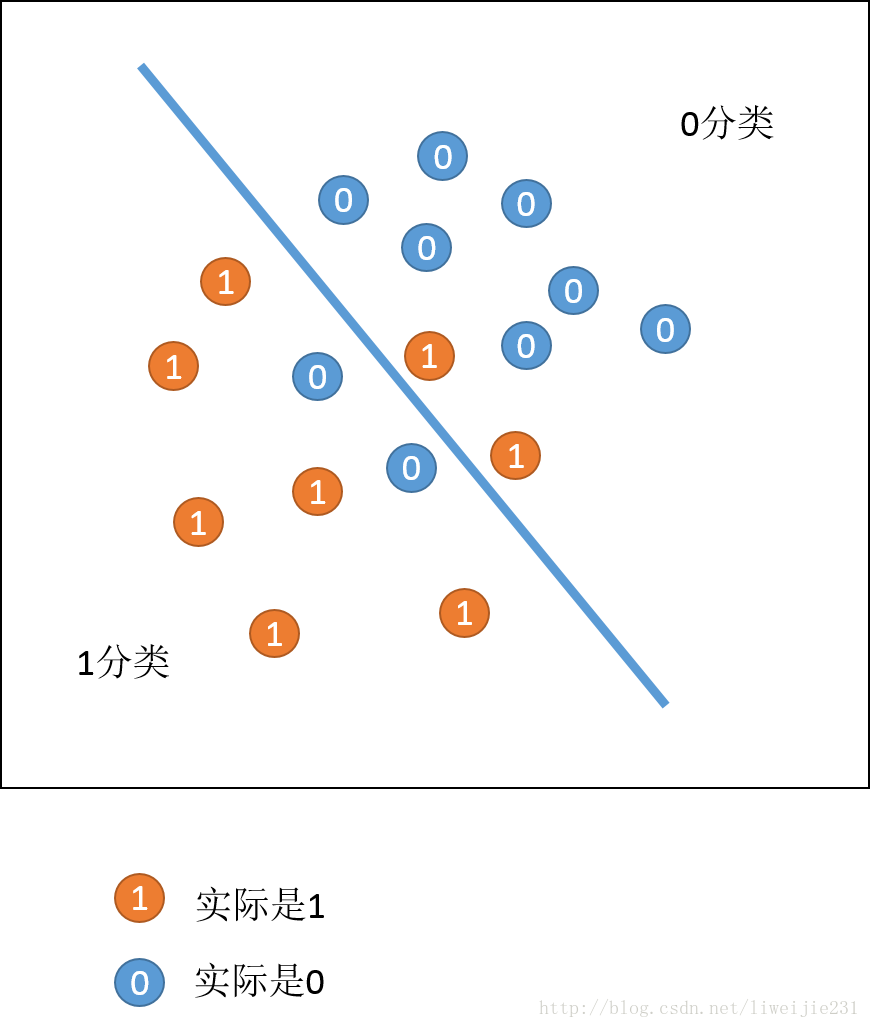
可视化解释
- 图表示
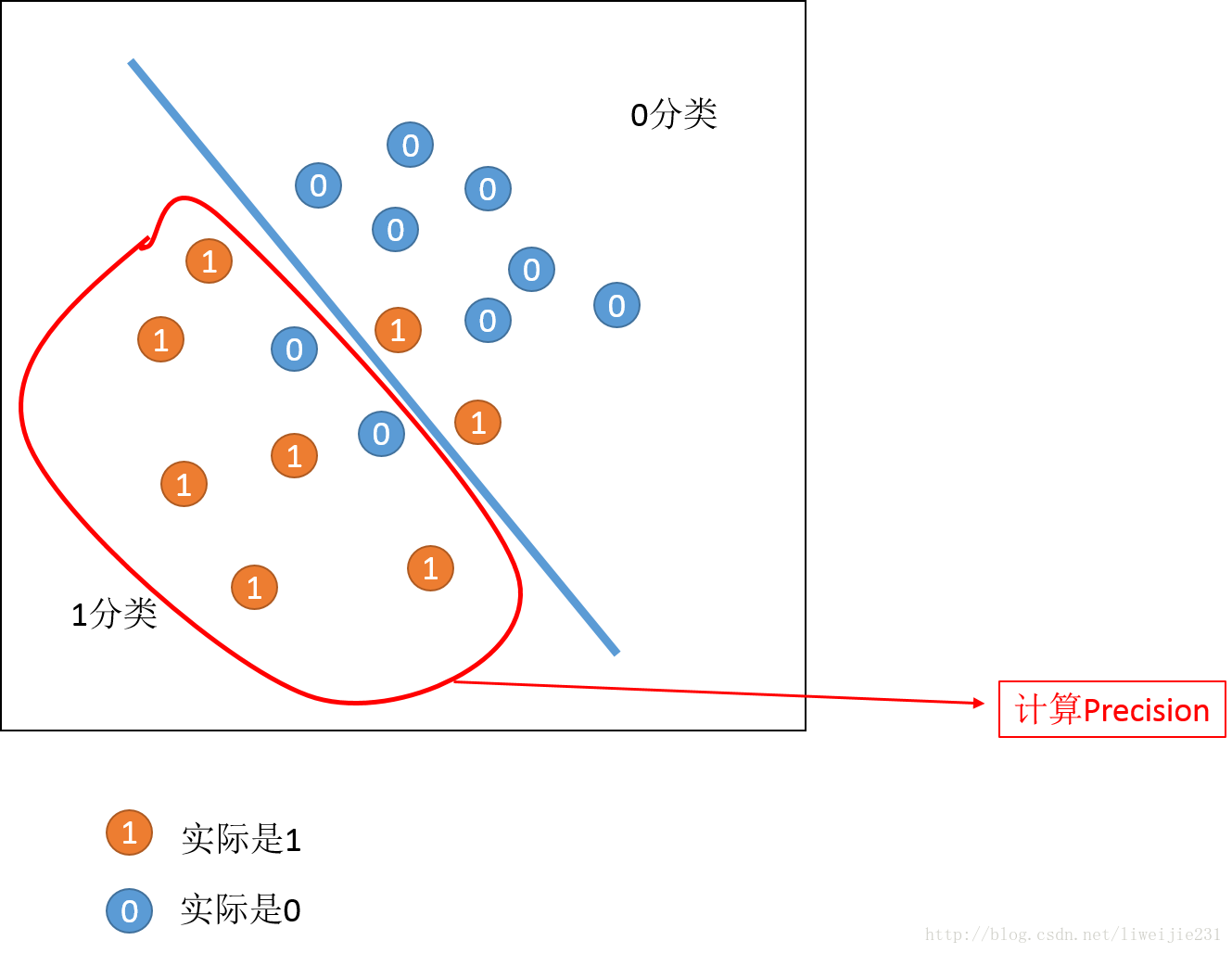
- 计算Precision 的点
Precision=分类1中1的数量分类1中1的数量+分类1中0的数量 P r e c i s i o n = 分 类 1 中 1 的 数 量 分 类 1 中 1 的 数 量 + 分 类 1 中 0 的 数 量- 计算Recall的点
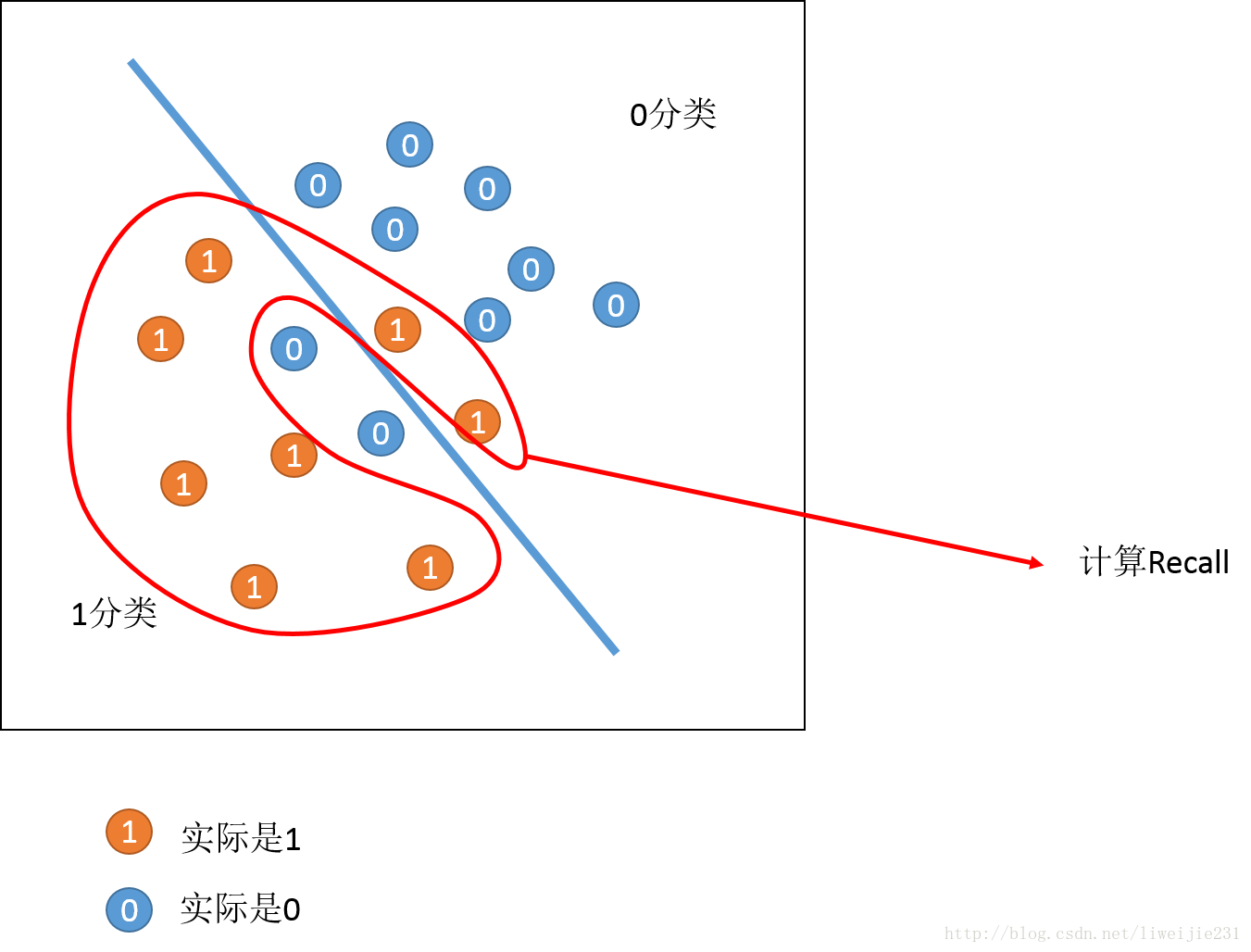
Recall=分类1中1的数量分类1中1的数量+分类0中1的数量 R e c a l l = 分 类 1 中 1 的 数 量 分 类 1 中 1 的 数 量 + 分 类 0 中 1 的 数 量 -
F−score
F
−
s
c
o
r
e















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









