







在CO的分摊应用中有一个统计指标。在应用上一直有些模糊。近期有时间做了一些应用分析和测试,对此有了更清晰的认识。我的个人理解是如下:
统计指标在CO的分摊应用中是一种选择性测略,也就是根据需求,可以用,可以不用。通常这取决于分摊的维度。代入到具体应用中,比如公司有5个部门,公司中产生的所有的电费如果按部门来分摊,那么就可以不用统计指标。每个部门在系统中基本都有对应的成本中心,这种规则完全可以直接在KSU1中定义。但在应用中,这种分摊又不太均衡。因为每个人都用电,如果按人头分配似乎更加合理。这时,系统中并不知道各个部门(成本中心)具体有多少人,并且这个人数也是有变化的。所以,此时就需要用来统计指标来告诉系统上述问题的答案。从下面截图中可以窥见在定义分摊规则时用或不用统计指标上的区别。
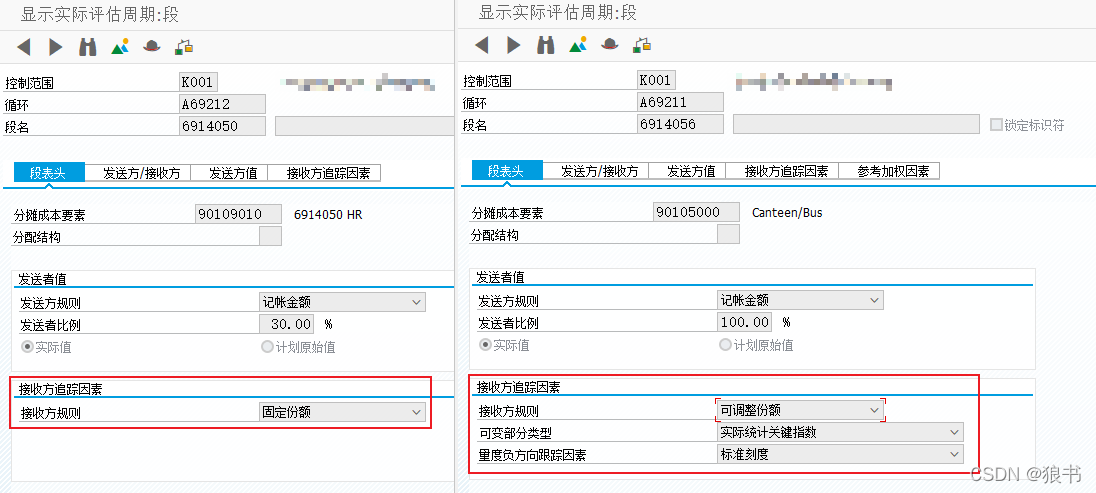
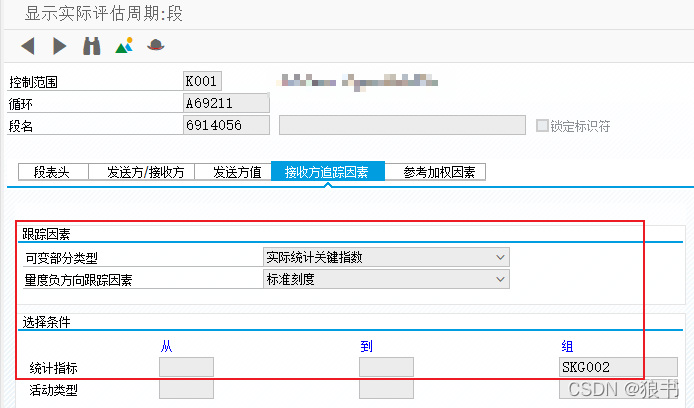
这时可以看到,在分摊规则中,指向了一个统计指标组,这个组当然就包含了不止一个统计指标。这时又产生了疑惑,即然按人头来统计,那设定一个统计指标就可以了,为何还有设定多个呢?从本公司的应用来说,在人头的基础上进行了细分,比如生产人员,劳务派遣,管理人员等。从下面截图中可以看到统计指标比如正式员工定义了以人为计量单位,而正式员工属于员工组中的一种。这个倒不用深究,就认为是一个统计指标更好理解。都是人,不分生产人员,劳务派遣,管理人员。
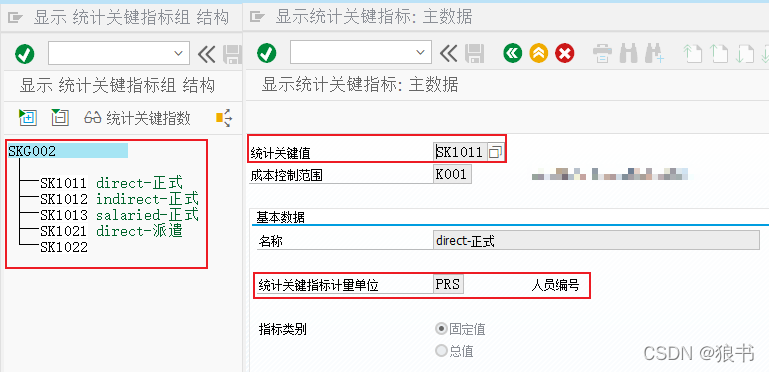
到这里,接下来就要来定义具体的分配方法了,即每个成本中心有多少员工就是在系统事务KB31N里面定义的。KB31N输入具体统计指标数据,比如以成本中心为对象输入每个成本中心的人数;这里请注意,由于这个是周期性的数据,因为人数是变化的,所以应用上CO部门会在结算前来定义,现炒现卖。当次数据输入后会以凭证号的形式保存在系统中在分摊时调用;
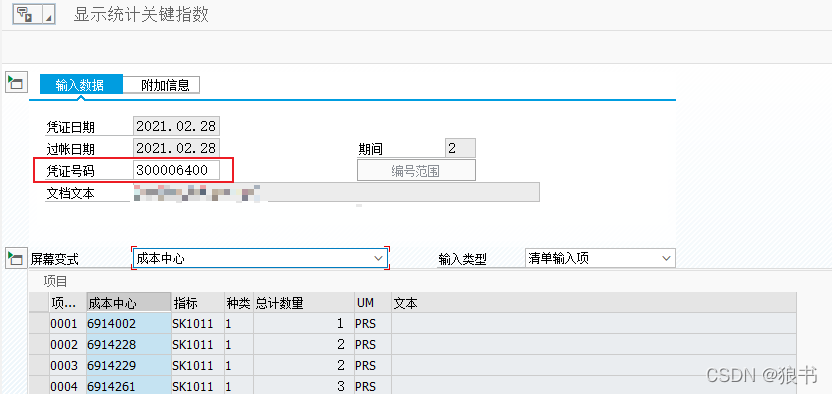
相信有了上面的分析,对于分摊统计指标,一个应用框架就出来了。每次分摊时,用KB31N建立新的统计文档。完成后,再执行分摊时来调用这个统计指标文档,系统就把分摊总额除以总人数,得到人均分摊额。用人均分摊额去乘以成本中心人数,得到各部门的具体分摊金额,完成分摊。



















 1695
1695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











