







重点更新部分,增加用红色注明,删除的使用括号【】包含。
本文提出了AirVO,一个基于点和线特征的光照稳健和准确的双目视觉里程计系统。为了对光照变化具有鲁棒性,引入了基于学习的特征提取和匹配方法,并设计了一个新的VO,包括特征跟踪、三角测量、关键帧选择和图优化等。我们还采用了环境中的长线特征来提高系统的准确性,其中点特征跟踪以及点和线特征的分布被用来匹配线。
一、Introduction
由于其准确性和低成本,视觉里程计(VO)已经被广泛地应用,特别是在增强现实(AR)和机器人领域[1]。尽管已经提出了许多优秀的解决方案,如MSCKF[2]、VINS-Mono[3]和OKVIS[4],但现有的解决方案在长期应用中不够强大[5]。例如,在动态光照环境中,视觉跟踪变得更具挑战性,因此,估计轨迹的质量受到严重影响[6]。
另一方面,卷积神经网络(CNN)在许多计算机视觉任务中取得了很大的进展,这引发了另一种研究趋势[7]。很多基于学习的特征提取和匹配方法已经被提出,并在很多应用中取得了优异的性能[8][11]。然而,它们往往需要巨大的计算资源,对于低功率机器人(如无人机)的实时应用是不现实的。因此,我们采用了一种混合解决方案,结合了传统优化的效率和基于学习的方法的鲁棒性。
在本文中,我们提出了AirVO,一种光照稳健且准确的双目视觉里程计,基于基于学习的特征提取和匹配算法。与FAST[12]和ORB[13]等用于VO或SLAM的手工特征相比,基于学习的特征对大的光照变化表现出更好的鲁棒性[9], [14], [15]。在特征跟踪阶段,基于学习的方法可以同时使用特征的外观和几何信息,因此它可以比传统的数据关联方法(如光流跟踪和最小化特征描述子距离)取得更好的性能[11]。为了更好地将基于学习的方法应用于我们的系统,我们改进了帧跟踪、特征三角测量和关键帧选择。为了提高精确度,我们采用了线特征,并提出了一个新的线处理,线条跟踪对变化的光线条件具有鲁棒性。最后,利用传统的SLAM后端来优化局部地图。总之,我们的贡献如下:
·我们介绍了一种基于学习的特征点提取和匹配方法以及线特征的双目VO,它在动态光照环境中非常稳健和准确。
·我们提出了一种新的线匹配方法,其中我们采用了点匹配和特征点与线条的分布相关联,以使线条跟踪对变化的光照条件具有鲁棒性。
·我们使用Nvidia TensorRT工具箱加速特征提取和匹配网络,使我们的系统能够比原有工作快5倍以上的速度。该系统在低功耗嵌入式设备上可以以15Hz左右的速率运行,在笔记本电脑上可以以40Hz左右的速率运行。https://github.com/xukuanHIT/ AirVO。
更多试例在: https://youtu.be/5zn_Q2KJlBI.
二、Related works
A. Feature Extraction and Tracking for Visual SLAM
各种关键点特征被提出并应用于不同的计算机视觉任务中。其中,ORB [ 13 ]、FAST [ 14 ]、BRISK [ 15 ]等特征因其兼顾有效性和效率而被应用于VO和SLAM系统中,如ORB - SLAM [ 16 ]、VINS - Mono [ 3 ]等。两种方法被广泛用于特征点的跟踪。第一种是利用光流[ 3 ],另一种是通过描述符[ 2 ] [ 17 ]进行匹配。然而,目前基于上述方法的视觉SLAM系统大多是在光照良好的环境下进行评估,并做出亮度一致性假设。因此,它们的性能受到具有挑战性的光照条件的显著影响,例如黑暗、过亮或动态光照条件。
随着深度学习技术的发展,许多基于学习的特征提取和匹配方法被提出,并开始应用于视觉SLAM。Kang等[ 18 ]引入TFeat网络[ 19 ]来提取传统VSLAM管道中FAST角点的描述子。Tang等[ 20 ]使用神经网络提取具有相同形状ORB的鲁棒关键点和二进制特征描述子。Han等[ 21 ]将超点[ 9 ]特征提取器与传统的后端结合。Bruno等人提出了LIFT - SLAM [ 22 ],他们使用LIFT [ 8 ]来提取特征。Li等[ 23 ]在ORB - SLAM2中使用SuperPoint替换ORB特征,并使用Intel OpenVINO工具包优化特征提取。然而,上述方法仍然采用传统的方法来跟踪或匹配这些基于学习的特征,使得它们对变化的光照不够鲁棒。Sarlin等人提出了HF-Net[24],他们将SuperPoint和SuperGlue[10]整合到COLMAP[25](一个structure from motion(SFM)的软件)。HF-Net在视觉位置识别(VPR)任务中取得了良好的性能,但需要巨大的计算资源,并且不能实时建立地图。
与目前的方法不同,AirVO在VO系统中引入了基于学习的特征提取和匹配方法,这使得我们的系统在光照挑战的环境中具有足够的鲁棒性。通过加速CNN和GNN部分,我们的系统可以在低功耗平台上进行位姿估计和实时建图。
B、Line Matching for Visual SLAM
线特征广泛存在于人造环境中,它可以提供额外的约束。在视觉SLAM中使用线特征的挑战之一是如何进行线匹配。目前许多SLAM系统[12][26]-[28]中使用的方法是通过LBD[29]描述符来匹配线条。这种方法可能会使线条匹配失败,因为传统的线条检测方法,如LSD[11],可能是不稳定的。为了克服这个问题,一些系统[30]-[32]对线上的一些点进行采样,然后通过跟踪这些点来跟踪线。然而,使用沿核线最小化光度误差或ZNCC(零归一化互相关)匹配方法[33]都不能确保在动态光照环境中进行稳健的线跟踪。
C、Visual SLAM for Dynamic Illumination
已经提出的几种方法来提高VO和SLAM对光照变化的鲁棒性。[34][35]对局部或全局的亮度变化进行建模,并联合优化相机姿势和光度参数。[36]-[39]尝试不同的方法,如ZNCC、局部尺度平方差和计算稠密描述符,以实现鲁棒跟踪。[40][41]利用图像增强对输入图像进行预处理。这些方法主要是针对各种图像的全局或局部光照变化,然而,光照条件往往对不同区域的场景有不同影响[42]。
其他相关的方法包括Huang和Liu[43],他们提出了一种多特征提取算法,当单特征算法无法提取足够的特征点时,可以提取两种图像特征。Kim等人[44]在直接运动估计过程中采用了一个基于Patch的仿射光照度模型。Chen等人[45]用非线性最小二乘优化法使归一化信息距离(NID)最小化,用于图像配准(image registration?)。
Ⅲ、Methodology
A、System Overview
旧版:
新版:个人觉得更清晰了
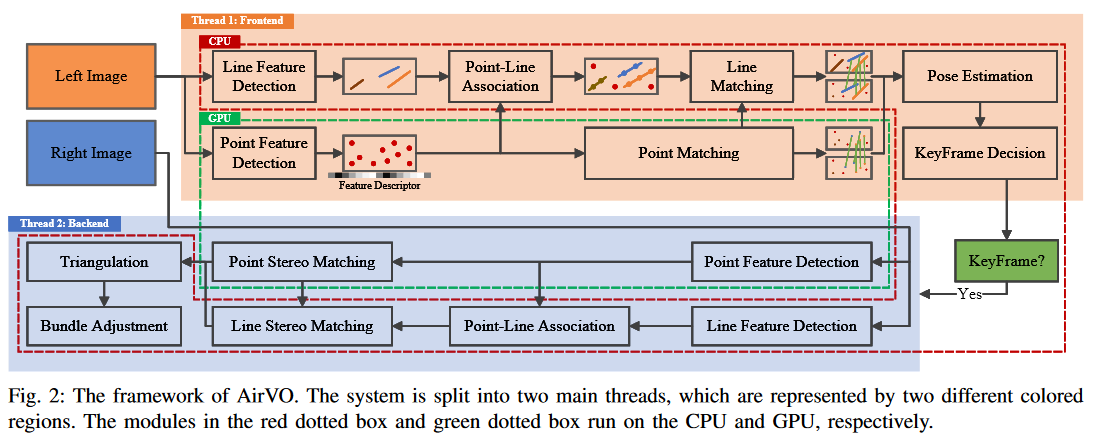
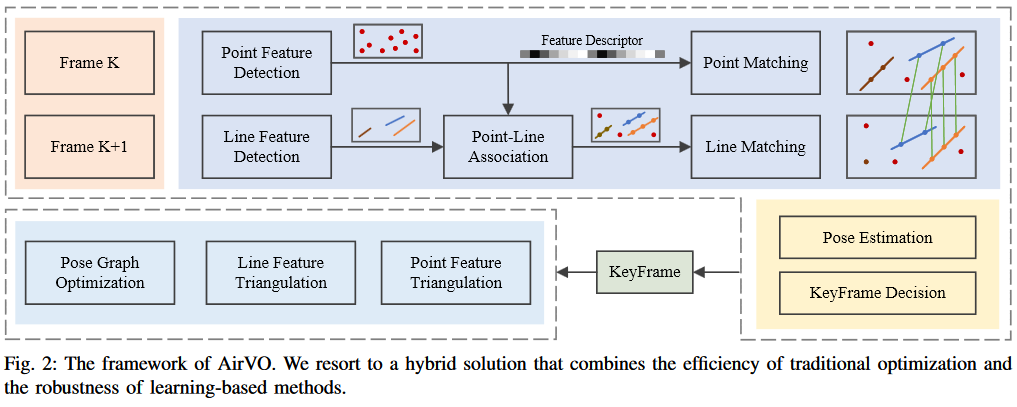
框架如图2所示。这是一个融合VO系统,我们同时利用基于学习的前端和传统的优化后端。对于每一对立体图像,我们首先采用一个CNN(如SuperPoint)在左图像上提取特征点,并使用特征匹配网络(如SuperGlue)将其与最后一个关键帧进行匹配。【这里跳过关键点检测和匹配网络的细节,它们是预先训练好的模型。在我们的系统中也利用了线特征来提高准确率。】并行地,我们还提取线特征。【观察到我们系统中提取的许多关键点位于边缘,在检测到线特征的地方,这两种特征会根据它们的距离进行关联。】然后将两种特征根据它们的距离进行关联,并使用关联的点的匹配结果对线特征进行匹配。【双目图像或不同帧上的线特征可以使用其相关点的匹配结果进行匹配或跟踪,以获得更好的光照稳定性。为了提高系统效率,我们只对不同帧的左侧图像进行特征跟踪。】之后,我们进行初始位姿估计并剔除异常值。基于结果,我们选择关键帧,在右图像上提取特征并对关键帧的2D点和线进行三角剖分。最后,进行局部光束法平差,优化点、线和关键帧位姿。【基于特征跟踪的结果,我们选择关键帧,并对点、线和这些关键帧进行BA优化。该系统可以结合传统优化的效率和基于学习的方法的鲁棒性。】
为了提高系统效率,我们将系统中(superpoint和superglue)CNNs和GNNs的32位浮点运算替换为16位浮点运算,使得特征提取和跟踪在嵌入式设备上的速度比原始代码提高了5倍以上。我们还设计了一个同时利用CPU和GPU资源的多线程流水线。采用producer-consumer模型将系统拆分为两个主线程,即特征线程和优化线程。在特征线程中,我们使用两个子线程分别处理点特征和线特征。其中一个子线程将最后一帧的点特征提取和匹配放在GPU上,另一个子线程并行地在CPU上提取线特征。在优化线程中,我们执行初始位姿估计和关键帧决策。如果选择了一个新的关键帧,则在其右图像上同时提取点特征和线特征,并用局部地图优化其位姿。
B、2D Line Processing
首先给出系统中2D线处理的细节,其中包括线段检测和匹配。
1)线检测。AirVO的线段检测是基于传统的方法(即LSD[11]),以提高效率。LSD是一种流行的线检测算法。然而,它存在着将一条线分成多段的问题。因此,如果满足以下条件,我们通过合并两个线段L1和L2来改进:
- L1 和 L2的角度差小于某个阈值 δθ。
- 一条直线的中点到另一条直线【的中点】距离不大于某个值δd。
- 如果L1 和 L2在X坐标轴和Y坐标轴上的投影不重叠,但两个最近的端点的距离小于一定的阈值δep。

在我们的系统中检测到的线特征以及与LSD的比较如图3所示。我们认为长线段比短线段具有更高的重复性,受噪声的影响更小,因此合并后长度小于预设阈值的线段会被过滤掉,从而在后续阶段只使用长线段。
2) 线匹配:
目前大多数VO和SLAM系统使用LBD描述符或跟踪样本点来匹配或跟踪线条。【它们在良好的光照条件下表现良好,但受到光照变化问题的影响。为了克服这个问题,我们设计了一个用于动态光照环境的新型线匹配pipline。】LBD算法从线条的局部带状区域中提取描述子,因此在线条长度可能变化的动态光照环境中存在不稳定的线条检测,从而导致局部带状区域在两帧之间存在差异。跟踪样本点可以在两帧中跟踪不同长度的直线,但目前的SLAM系统通常采用光流法跟踪样本点,当光照条件变化较快或剧烈时,跟踪效果较差。一些基于学习的线特征匹配方法[ 46 ],[ 47 ]也被提出,但是由于需要巨大的计算资源,它们在目前的SLAM系统中很少被使用。我们也不使用它们,因为如果同时使用基于学习的点特征和基于学习的线特征,很难使系统在低功耗的嵌入式平台上实时运行。
因此,为了同时解决有效性问题和效率问题,我们设计了一种适用于动态光照环境的快速鲁棒线匹配方法。首先,我们通过点和线之间的距离将点的特征与线段联系起来。假设检测图像上有M个关键点和N条线,其中每个点表示为pi = (xi, yi),每个线段表示为 ,其中(Aj, Bj,Cj)是
的线参数,
是两个端点。我们首先通过计算pi和lj之间的距离。
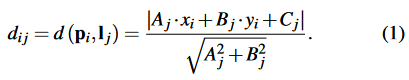
如果dij<3,并且pi在坐标轴上的投影位于线段端点的投影范围内,即min( x(j,1), x(j,2) ) ≤ xi ≤ max( x(j,1), x(j,2) ) 或 min( y(j,1)), y(j,2) ) ≤ yi ≤ max(y(j,1), y(j,2) ),我们将说pi属于l j。然后可以根据这两个图像的点匹配结果来匹配两个图像中的线段。然后根据这两幅图像的点匹配结果对两幅图像上的线段进行匹配。对于图像k上的和图像k+1上的
,我们计算一个分数来表示它们是同一条直线的置信度:匹配数 ÷ 属于线的特征点数。
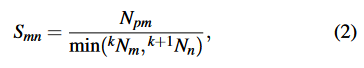
其中Npm是属于的点特征和属于
的点特征之间的匹配数。
和
分别是属于
和
的点特征的数量。如果Smn>δS,Npm>δN,其中δS和δN是两个预设的阈值,我们将把
和
视为同一条线。
由于点匹配具备光照鲁棒性,而且特征关联不受光照变化的影响,所以所提出的线条跟踪方法对动态光照环境非常稳健,如图4所示。

图4:AirVO在挑战性场景中的线条匹配。匹配的线条以相同的颜色绘制。线条上的圆圈是与该线条相关的点。半径越大,说明该点与更多的线条有关。
C、3D Line Processing
在这一部分,我们将介绍我们的3D线条处理方法。与三维点相比,三维线有更多的自由度,因此我们首先介绍它们在不同阶段的表示方法。然后,我们将详细说明线的三角化,即把二维线段转换为三维线,以及线的重投影,即把三维线投射到图像平面。
1)表示法。我们使用普吕克坐标来表示一个三维空间线。
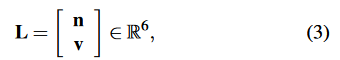
其中v是线的方向矢量,n是由线和原点决定的平面的法向量[48]。普吕克坐标用于三维线的三角化、转换和投射到图像上。它是一个6维的向量,所以是过度参数化的,但一条3D线只有四个自由度。在图优化阶段,额外的自由度会增加计算成本并导致系统的数值不稳定[27]。因此,我们也使用正交表示法[48]来表示三维线:
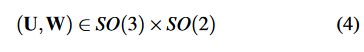
普吕克坐标和正交表示的关系类似于SO(3)和so(3)(李群和李代数,一 一对应)。正交表示可以通过以下方式从普吕克坐标得到。
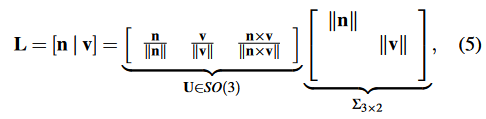
其中Σ3×2是一个对角矩阵,其两个非零元素(按照比例)可以由SO(2)矩阵W表示。在实践中,这种转换可以用QR分解完成。
2) 三角化。
三角化是通过两个或更多的二维线观测来初始化一个三维线。在系统中,有两种方法用于三角化一个三维线。第一种方法类似于[12]中的线段三角化算法B,可以从两个平面计算出一条三维线。为了实现这一点,我们在两幅图像上选择两个线段,l1和l2,这是一条三维线的两个观测。l1和l2可以被反投影到两个平面π1和π2。然后,三维线可以被看作是π1和π2的交线。
然而,三角化一个三维线比三角化一个三维点更难,因为它受到更多的退化运动的影响[12]。因此,如果上述方法失败,我们还采用了第二种线的三角测量方法,即利用点来计算三维线。在第IIIB.2节中,我们将点的特征与线的特征联系起来。因此,为了初始化一条三维线,我们选择了两个属于这条线并且在图像平面上距离最短的三角化的点X1和X2,其中X1=(x1,y1,z1),X2=(x2,y2,z2)。那么这条直线的普吕克坐标就可以通过以下方式得到。
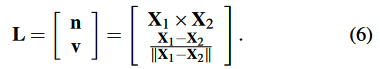
因为选定的三维点已经在点三角化阶段被三角化了,所以这种方法只需要很少的额外计算。它是非常有效和稳健的。
3)重投影。我们使用普吕克坐标来转换和重投影三维线。首先,我们将三维线从世界坐标系转换到相机坐标系。
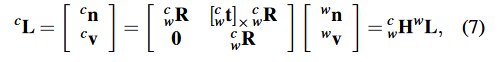
其中,和
分别是3D线在相机坐标系和世界坐标系中的普吕克坐标。
∈SO(3)是世界坐标系到相机坐标系的旋转矩阵,
∈
是平移矢量。
表示一个向量的反对称矩阵(也就是十四讲中的
),
表示三维线从世界系到相机系的变换矩阵。
补充:
然后,三维线可以通过线投影矩阵
投影到图像平面。
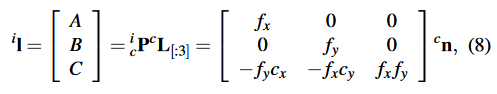
其中是在图像平面上重新投影的二维线。
指的是
的前三行。
D. Key-Frame Selection
观察到基于学习的数据关联方法能够跟踪具有大基线的两个帧,因此与其他VO或SLAM系统中使用的逐帧跟踪策略不同,我们只将当前帧与关键帧相匹配,因为这可以减少跟踪误差。如果满足以下任何一个条件,一个帧将被选为关键帧:
①与最后一个关键帧的距离大于给定的阈值。
②与最后一个关键帧的角度大于给定的阈值。
③追踪的地图点的数量小于上限值,大于下限值
。
④追踪的地图点多于,但最后一帧追踪丢失,即最后一帧追踪的地图点少于
。
【⑤从最后一个关键帧开始,已经过了以上的帧。】
E. Graph Optimization
我们选择个关键帧,构建一个类似于ORB-SLAM(1代)[17]的共视图,其中地图点、三维线和关键帧是顶点,约束是边。【图中使用了四种约束,包括单目线约束(monocular line constraint)、双目线约束(stereo line constraint)、单目点约束(mono point constraint)和双目点约束(stereo point constraint)。】我们系统中同时使用了点约束和线约束,相关的误差项定义如下:(不分单目和双目了)
1) 【Monocular 】Line Constraint:如果【只有左目相机的】第k帧可以观察到三维线,那么重投影误差定义为:
新版: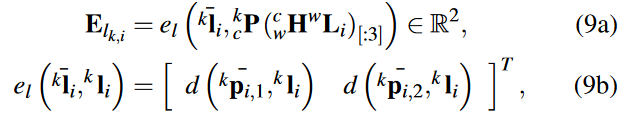
其中是
在第k帧上的观测值,d(p,l)是点p和线l之间的距离,
,
是
观测值的端点。【左目相机是主相机,所以如果只有右边的相机观察到一个三维线或点,那么在我们的系统中,该观察不被视为一个约束。】
【 2) Stereo Line Constraint: 如果第k帧的左相机和右相机都能观察到三维线,则重投影误差定义为:
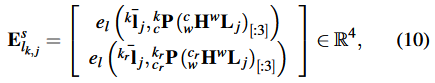
其中是
在第k帧右相机图像上的观测值。
和
分别是右相机的线投影矩阵和变换矩阵。】
3) 【Monocular】Point Constraint:如果一个三维点被【左相机】第k帧观察到,那么重投影误差定义为:
新版: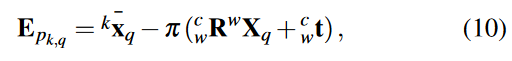
其中 = (
,
) 是
在第k帧上的观测值,
表示将一个三维点投影到左相机拍摄的图像上。
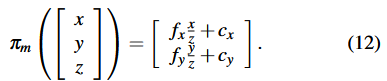
【 4) Stereo Point Constraint:如果一个三维点同时被第k帧的左相机和右相机观察到,那么重投影误差定义为:

其中 = (
,
,
)是
在第k帧上的观测值,
是右图中的横坐标,
表示将一个三维点投影到双目图像上。
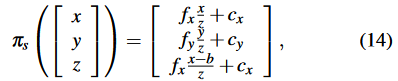
其中,b是双目基线长度。】
【 5) Cost Function:假设观察结果服从高斯分布,最终的成本函数可以定义为:
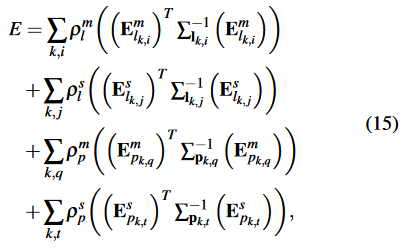
其中,
,
,
是稳健的Huber成本函数,
,
,
,
分别是协方差矩阵的逆。】(Huber函数我理解为降低异常重投影误差值的影响)
 https://blog.csdn.net/u013841196/article/details/89923475
https://blog.csdn.net/u013841196/article/details/89923475IV、EXPERIMENTS
在本节中,将介绍实验结果以证明我们的方法的性能。我们采取预训练的SuperPoint和SuperGlue来检测和匹配特征点,无需任何微调。实验是在两个数据集上进行的。OIVIO数据集[51]和UMA视觉-惯性数据集[6]。为了证明所提出的线处理流水线的效率,我们将提出的方法与先进的点线视觉系统PL-SLAM[26]、【VINS-Fusion[3]】、StructVIO[31]和UV-SLAM[28]【和Stereo ORB-SLAM2[19]】的定位精度进行比较。PL-SLAM和UV-SLAM使用LBD描述符匹配直线特征,而StructVIO通过跟踪直线上的采样点来跟踪直线特征。我们还添加了双目-VINS-Fusion [ 3 ]、ORB-SLAM2 [ 17 ]、Basalt-VIO [ 39 ]和VIO模式-OKVIS [ 50 ]。为了处理动态光照问题,VINS-Fusion采用故障检测与恢复模块,StructVIO采用ZNCC方法,Basalt-VIO采用LSSD KLT(光流)方法。下面的实验将证明,在有光照挑战的环境中,AirVO优于这些方法。由于所提出的方法是一个VO系统,我们从上述基线中禁用了闭环部分和重新定位。
值得注意的是,由于缺乏动态光照环境下的线匹配和三角化的地面真值(没有真实值的意思吧),我们通过与其他点线系统的比较和消融研究来证明所提出的线处理方法的有效性,而不是设计额外的线匹配或三角化比较。与[ 51 ] - [ 53 ]一样,我们与ORB - SLAM2而不是ORB - SLAM3 [ 54 ]进行比较,因为ORB - SLAM3中新增加的地图集和IMU与仅视觉里程计相比是不公平的,并且由于高耦合系统而难以移除。由于DX - SLAM [ 23 ]和GCNv2 - SLAM [ 20 ]是基于RGB - D输入的,无法在立体数据集上运行,因此我们也没有在基线上添加DX - SLAM [ 23 ]和GCNv2 - SLAM [ 20 ]。【由于提出的方法是一个VO系统,我们取消了上述基线中的循环闭合部分。请注意,我们不能与DX-SLAM[15]和GCNv2-SLAM[22]比较,因为它们是基于RGB-D输入的。】
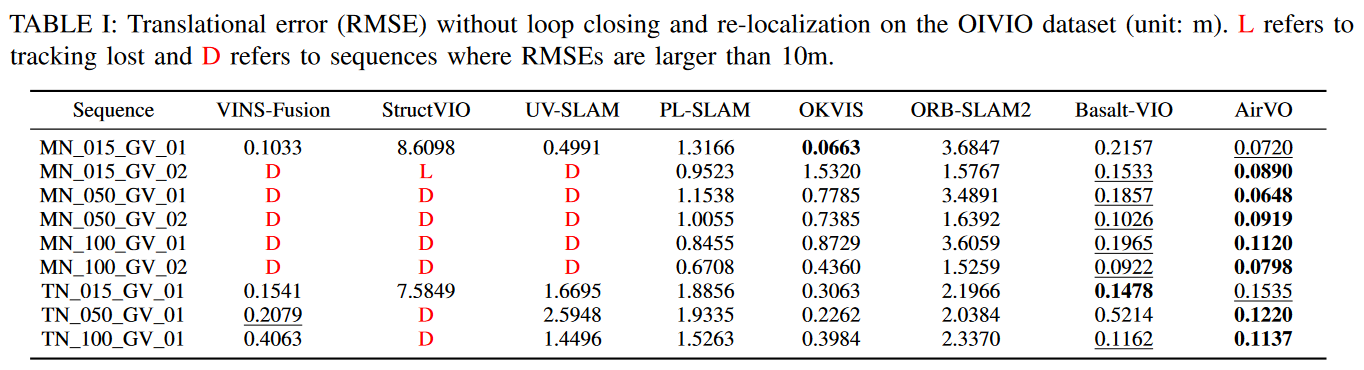
A、Results on OIVIO Benchmark
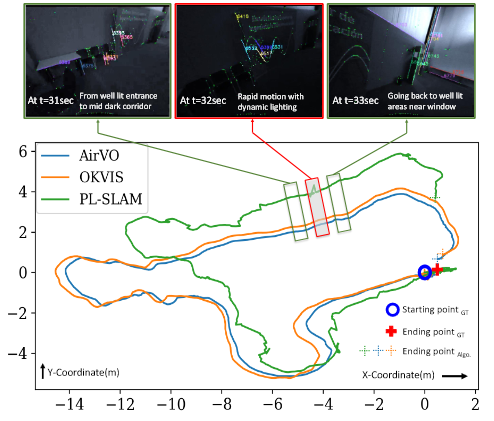
OIVIO数据集收集了隧道和矿井中的视觉-惯性数据。在每个序列中,场景被一个大约1300、4500或9000 lumens(亮度)的机载灯照亮。我们选择了由徕卡TCRP1203 R300获得的所有九个序列的GT实测数据。表Ⅰ中列出了平移误差的表现。两个最准确的结果分别以高亮和下划线表示。AirVO在【6】7个序列上取得了最佳性能,在其他【3】2个序列上取得了第二好的性能,超过了其他最先进的算法。我们注意到,VINS-Fusion、StructVIO和UV-SLAM在许多序列上的跟踪效果不佳,这可能是因为它们的特征跟踪方法,即KLT稀疏光流、ZNCC、LBD描述符,【不具有光照稳定性】在光照挑战的环境中不够鲁棒。
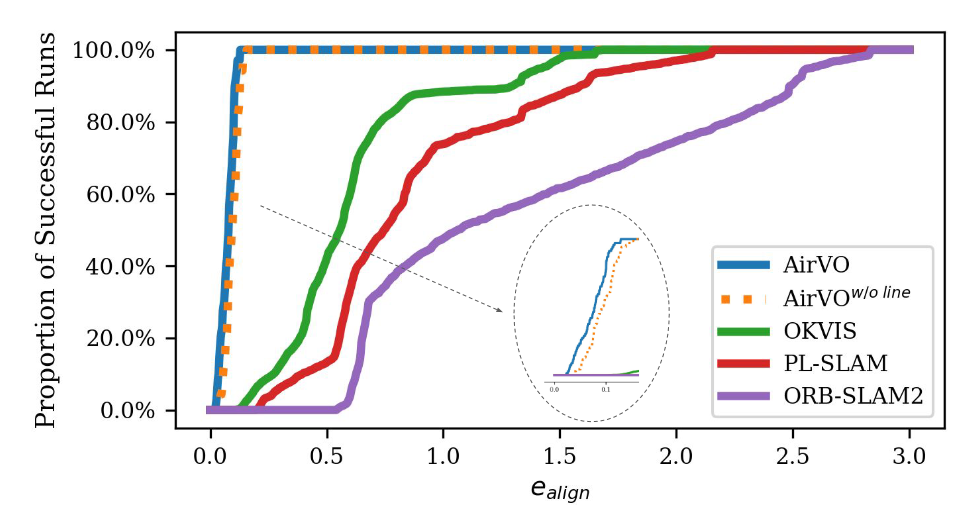
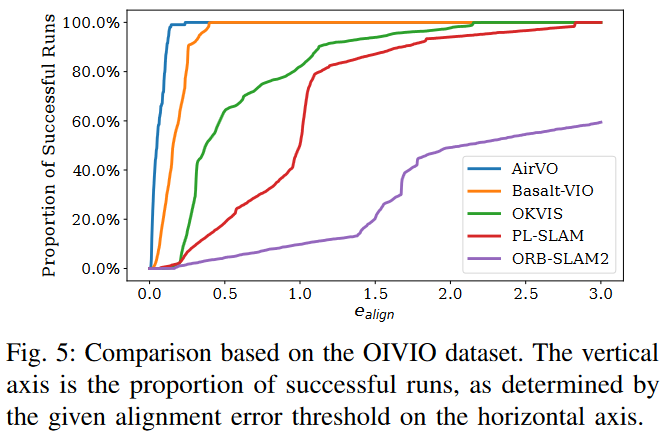
我们在图5中展示了我们的方法与选定的基线在OIVIO MN_050_GV_01序列上的比较。在该情况下,机器人通过一个带有车载照明的矿井。距离约为83米,平均速度约为0.5m/s。该图显示了水平轴上对齐误差阈值所确定的成功运行比例,AirVO在该序列上实现了最准确的结果。
【为了显示所提出的线处理方法的有效性,我们从AirVO中去除线条特征,并将其命名为AirVOw/o line。可以看出,加入线特征后,平均平移误差下降了13.2%,这验证了采用线特征可以提高我们系统的准确性。】
旧版: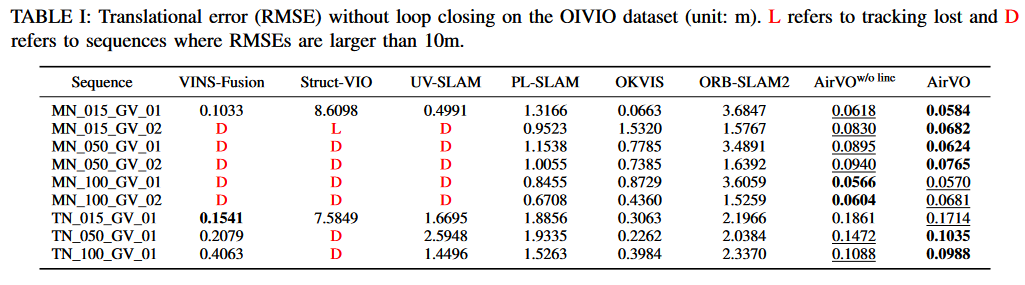
新版:(为什么会比旧版更差?我猜测是旧版使用更多约束,而且使用了32位浮点的superpoint网络,可能为了提高是速度,所以降低了。下面速度分析中,使用了比旧版更弱的嵌入式设备,但是差不多的时间。)
【 图5中展示了我们的方法在OIVIO MN_050_GV_02序列中与选定基线的比较。在这种情况下,机器人在机载照明下穿过一个矿井。行驶距离约为83米,平均速度约为0.5米/秒。该图在纵轴上显示了成功运行的比例,横轴上是对齐误差阈值决定的。AirVO在这个序列上取得了最精确的结果。】
旧版:
新版:
B、Results on UMA-VI Benchmark
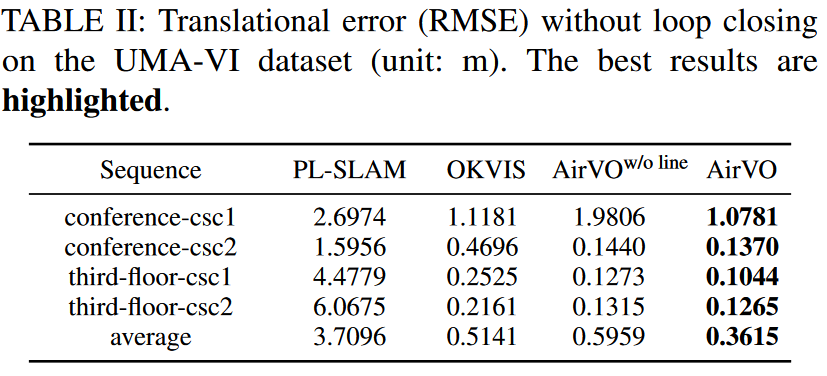
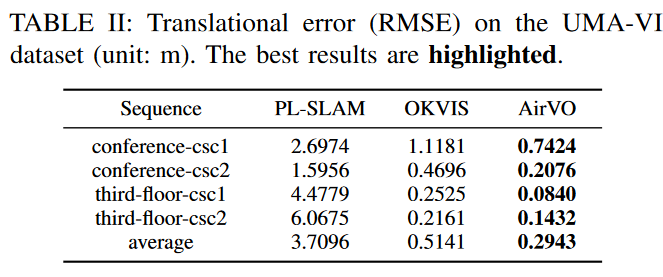
UMA-VI数据集是一个在手持自定义传感器下收集的视觉惯性数据集,我们在光照变化的挑战性场景中收集了该数据集。如图6所示,它包含许多子序列,其中图像突然变暗是由于关闭灯光而引起的。这比OIVIO数据集更具挑战性,因此我们只选择在第IV-A节中证明是光照鲁棒的方法作为基线,即PL-SLAM、OKVIS和Basalt-VIO。表II中展示了平移误差。由于Basalt-VIO在所有4个序列上都跟踪丢失,因此我们不列出其结果。可以看出,AirVO优于其他方法。其平均平移误差仅为PL-SLAM的7.9%和OKVIS的57.2%。我们注意到,与OIVIO数据集相比,对齐误差更大。这是因为UMA-VI数据集只给出了每个序列的开头和结尾的真实情况,而这些场景对VO或VIO系统来说更难。
【UMA-VI数据集是一个视觉惯性数据集,它是在有光照挑战的情况下用手持式定制传感器收集的。我们使用有光照变化的序列来评估我们的系统。如图6所示,它包含许多子序列,其中图像因关灯而突然变暗。这比OIVIO数据集更具挑战性,所以我们只选择了在第四章A节中被证明具有光照强度的方法作为基线,即PL-SLAM、OKVIS和AirVOw/o线。表Ⅱ中列出了平移误差。可以看出,AirVO优于其他方法。它的平均平移误差只有PL-SLAM的9.8%,AirVOw/o line的61.0%和OKVIS的70.7%。我们注意到,对齐的误差比OIVIO数据集上的误差要大。这是因为UMA-VI数据集只给出了每个序列的开头和结尾的真实情况,而这些场景对VO或VIO系统来说更难。】
旧版:

新版:

旧版:
新版:
我们还比较了AirVO与OKVIS和PL-SLAM在Conference-csc2序列上的轨迹,如图1所示。该序列的行驶距离约为50米,平均速度约为0.75米/秒。这清楚地表明,在这个具有挑战性的案例中,AirVO产生了最好的精度。AirVO的漂移误差约为【0.58%】1.0%。OKVIS和PL-SLAM分别为【1.6%和8.1%】1.5%和7.1%。
C、Ablation Study
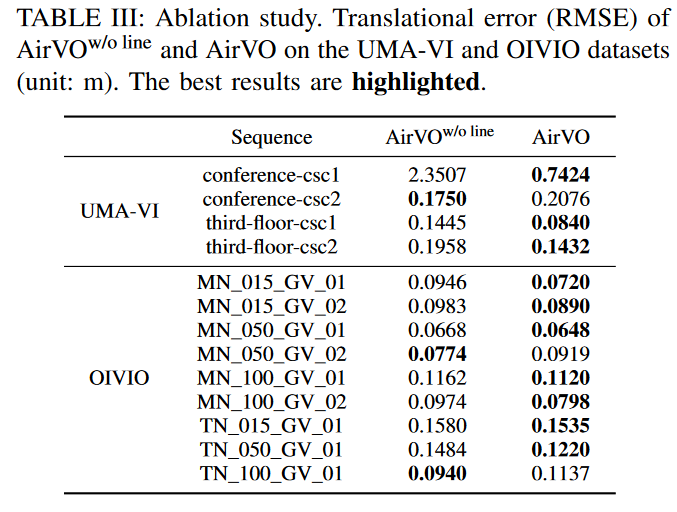
为了说明本文提出的线处理方法的有效性,我们从AirVO中去除线特征,并将其命名为AirVO w/o线。AirVO和AirVO w/o线在OIVIO和UMA - VI数据集上的对比结果如表3所示。可以看出,在13个序列中有10个序列上,AirVO优于AirVOw / o线,利用线特征平均降低了45.6 %的平移误差,说明本文提出的线处理方法能够提高系统的性能。
D、Runtime Analysis
【本节介绍了系统的运行时间。评估是在一台装有AMD Ryzen Threadripper PRO 3975WX处理器和NVIDIA Geforce RTX 3090 GPU的笔记本电脑上进行的。输入图像的分辨率为752×480。我们首先验证了点检测和匹配网络的加速性。在我们的系统中,检测和跟踪一个图像的特征点需要15ms,而原始的python代码需要40ms。因此,时间成本进一步减少了62.5%。然后,我们在表Ⅲ中列出了每个模块的运行时间。注意,特征检测模块包括检测双目图像的点和线。跟踪模块包括双目匹配和帧与帧之间的特征跟踪。可以看出,整个系统可以实时运行(20 FPS)。】
旧版:
 本部分给出了所提系统的运行时间分析。评估在Nvidia Jetson AGX Xavier ( 2018 )上进行,该平台是一个低功耗嵌入式平台,具有8核ARM v8.2 64位CPU和低功耗512核NVIDIA Volta GPU。输入图像序列的分辨率为640 × 480。对于所有算法,我们提取了200个点,并禁用了回环、重新定位和可视化部分,以便进行公平的比较。
本部分给出了所提系统的运行时间分析。评估在Nvidia Jetson AGX Xavier ( 2018 )上进行,该平台是一个低功耗嵌入式平台,具有8核ARM v8.2 64位CPU和低功耗512核NVIDIA Volta GPU。输入图像序列的分辨率为640 × 480。对于所有算法,我们提取了200个点,并禁用了回环、重新定位和可视化部分,以便进行公平的比较。
1 ) CNN和GNN加速:我们首先验证了点检测和匹配网络的加速。在我们的系统中,检测和跟踪一幅图像的特征点需要64ms,而原始码字需要342ms。因此它比原方法大约快5.3倍。
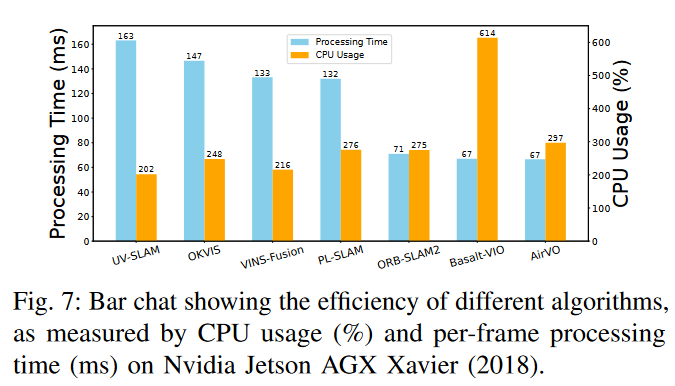
2 )效率比较:我们还比较了算法效率,通过CPU使用率和每帧处理时间来衡量。结果如图7所示。可以看出,AirVO是速度最快的(约15 FPS)方法之一,但由于利用了GPU资源,其CPU使用量与其他方法大致相同。注意到只有Struct - VIO的二进制可执行文件是可用的,它是在x86计算机上编译的,无法在Jetson平台上运行,所以我们没有将其添加到本次比较中。
3 )详细运行时间:表4给出了PL - SLAM和Air VO各模块的详细运行时间,其中PE为点提取,LE为线提取,PM为点匹配,LM为线匹配,IPE为初始位姿估计,BA为关键帧处理和局部光束法平差。可以看出,AirVO的线处理流水线比PL - SLAM的效率要高得多。注意这些模块是并行运行的,而BA模块是一个非实时的后端线程,因此整个系统的运行时间不是各个模块的简单累加。

V、CONCLUSIONS
提出了一个基于学习的关键点检测和匹配方法的光照稳健的视觉导航系统。为了提高精确度,我们的系统还利用了线特征。我们提出了一种新的线匹配方法,使线跟踪在动态环境中足够稳健。在实验中,我们表明所提出的方法在动态光照环境中取得了卓越的性能,并且【可以实时运行】可以在低功耗设备上实时运行。我们开放了源代码,并期望该方法在机器人应用中发挥重要作用。在未来的工作中,我们将通过增加闭环、重新定位和地图重用,将AirVO扩展到SLAM系统中。我们希望为长期定位建立一个光照稳定的视觉地图。



















 1528
1528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











