







MMPreTrain
MMPreTrain算法库介绍
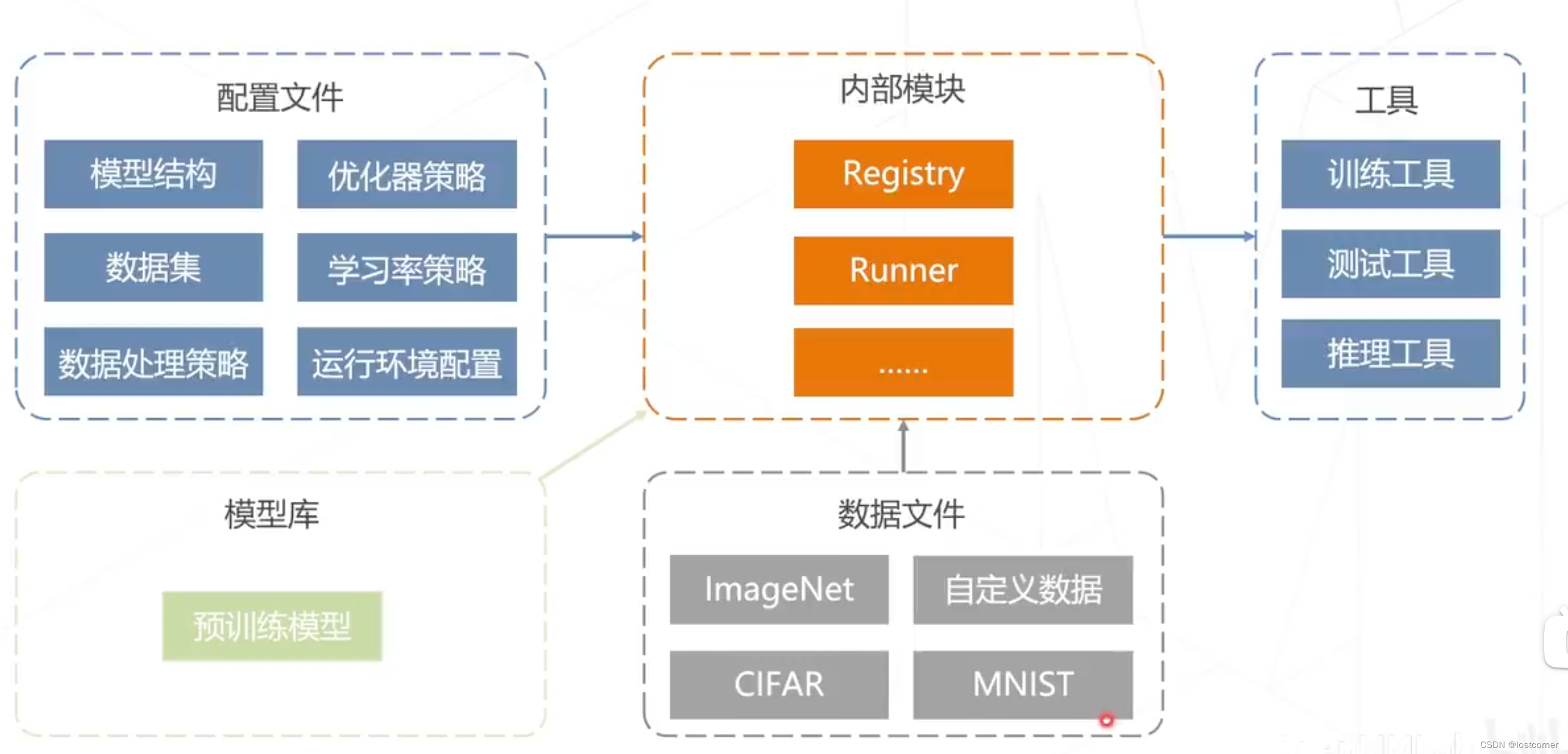
算法库与任务组成
MMPreTrain是源自MMClassification和MMSelfSup的一个全新升级的预训练算法框架,能够提供各种强大的预训练主干网络。目前,预训练阶段对于视觉任务至关重要,凭借丰富而强大的预训练模型,能够对各种下游任务进行改进。


在MMPreTrain中,包含了很多内容,有主流的backbone模型,如VGG、ResNet,还有轻量化的MobileNet等。也有自监督学习算法MoCo等,还有多模态算法CLIP等。同时也提供了各类数据集,例如COCO、ImageNet,也有多模态的数据集ScienceQA等,还有训练技巧与策略和各种用于模型训练、推理的小工具。
框架概览
以下是OpenMMLab软件栈以及MMPreTrain的安装步骤

其中有个重要概念就是配置文件,可以对配置文件进行修改来得到自己的模型

所以整个算法的数据流如下:

当我们配置好了定义文件,同时选取好了预训练模型并准备好了数据集,就可以通过Registry、Runner等模块以及训练、测试、推理工具来实现算法。
经典主干网络
深度学习早期的网络都比较浅,后来通过堆叠网络能够获得更好的效果如AlexNe、VGG等等。但是人们发现,模型层数增加到一定程度后,分类正确率不增反降。
ResNet
通过实验,得到了残差建模。也就是残差网络
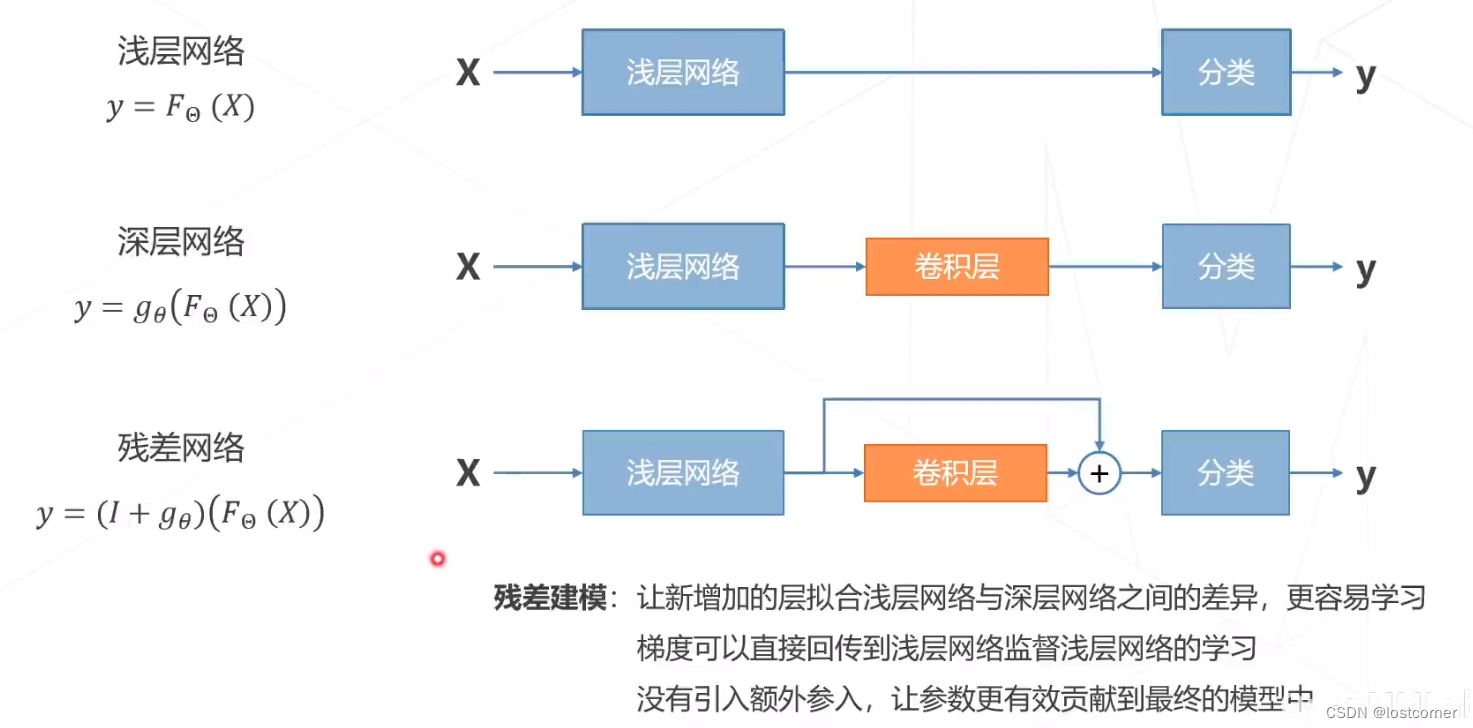
这样的残差结构大大解决了梯度回传的问题,因为在梯度的链式求导法则中,梯度可能越来越小。但是这样的跨层网络,让梯度能够提前传回前面的浅层网络。这种设计是有效的 ,直到现在这种残差的思想仍然存在。
以下是ResNet中的两种残差模块:
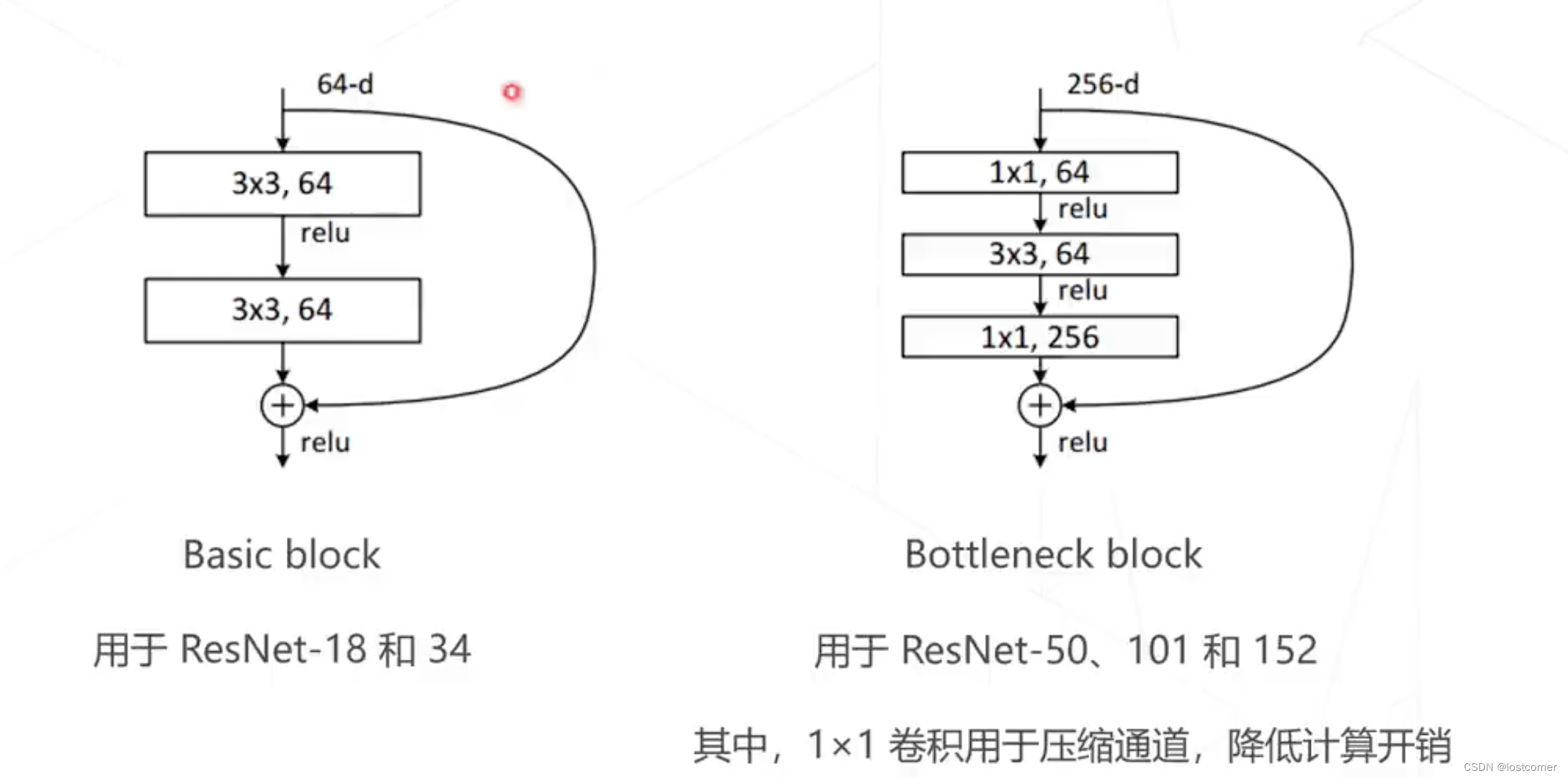
ResNet在VGG的基础上改进
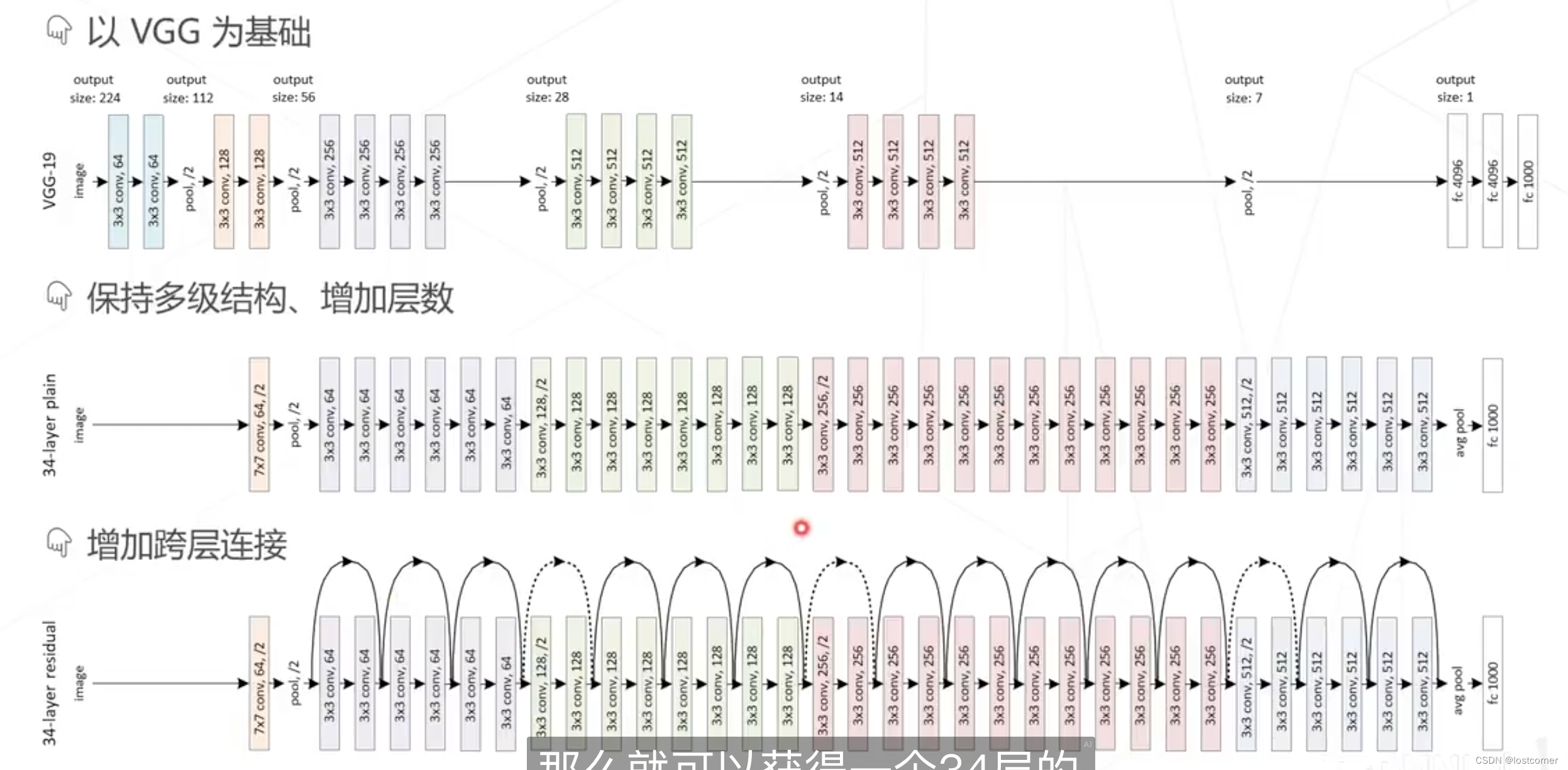
ResNet是深度学习领域中影响力最大、使用最广泛的模型之一。
Vision Transformer

这是ViT的逻辑图。
- 首先将图像分割成若干个固定大小的patch,所有块排列成一个词向量。先经过线性层映射,一张[H,W,C]维度的图像变为[L,C],再经过多层Encoder的计算产生相应的特征向量。
- patch之外加入额外的token,用于query其他patch的特征并给出最后的分类概率
- 注意力模块基于全局感受域。
注意力机制
注意力机制是为了对不同的特征进行一个有权重的选取,实现层次化特征。
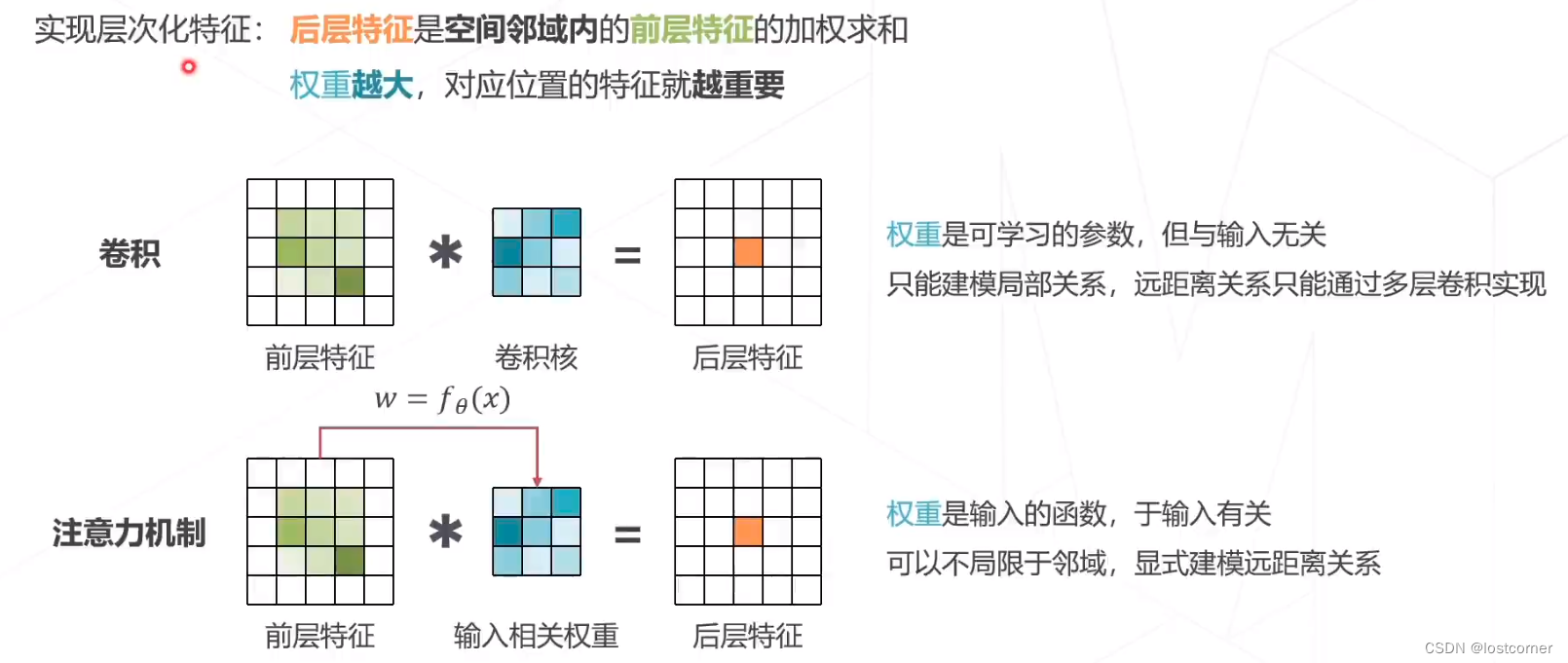
这是一个一维数据的注意力计算的逻辑图, 首先取一个输入,通过
W
Q
、
W
K
、
W
V
W_Q、W_K、W_V
WQ、WK、WV的计算得到
Q
K
V
QKV
QKV,将
Q
K
QK
QK进行一个计算得到一个
2
×
2
2\times2
2×2的权重,再把这个权重和
V
V
V计算得到结果。
因为是由自身的输入来产生
Q
K
V
QKV
QKV三个向量,所以叫做self-attention。

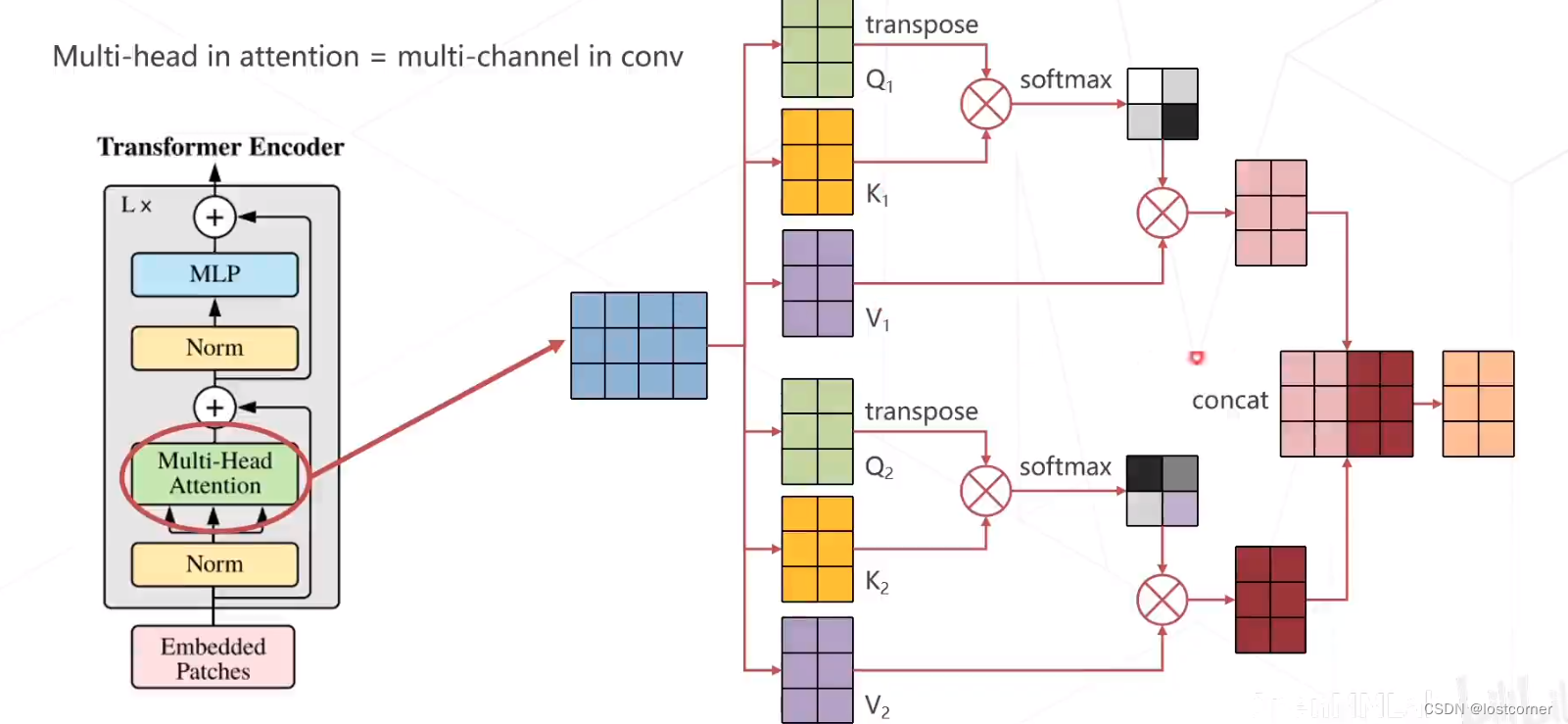
Multi-head Attention
多头注意力就是把两个特征图上得到的两组
Q
K
V
QKV
QKV进行拼接得到最后结果。
这样的好处是在计算过程中,不同的注意力能够对不同的特征进行分别提取,从而提升网络的性能。
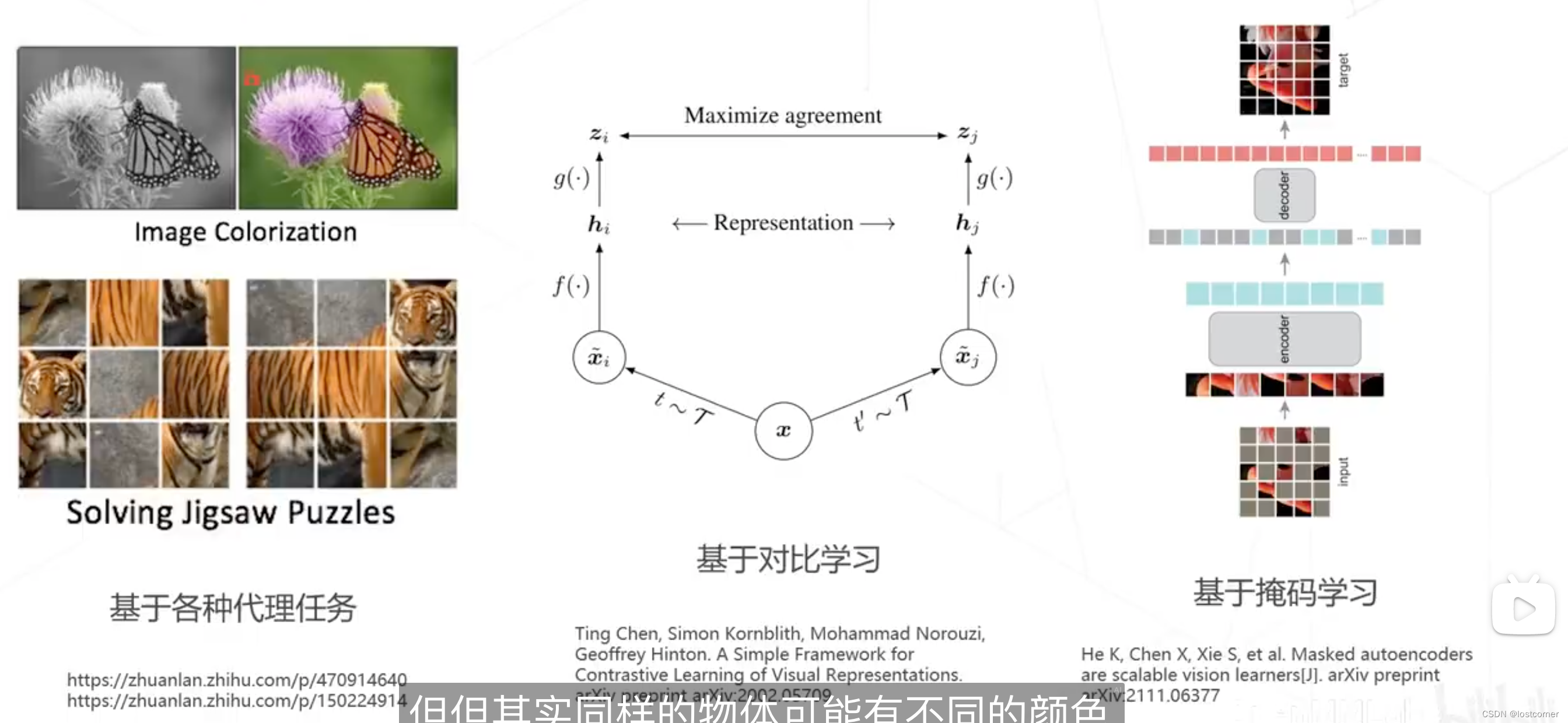
自监督学习
现在互联网上有大量的数据,但是有标注的数据是少之又少,所以为了利用这些数据,不依赖人工标注,让深度网络去学习到数据本身的特征表达,这是近年来的热点。以下是自监督学习的常见类型。
SimCLR
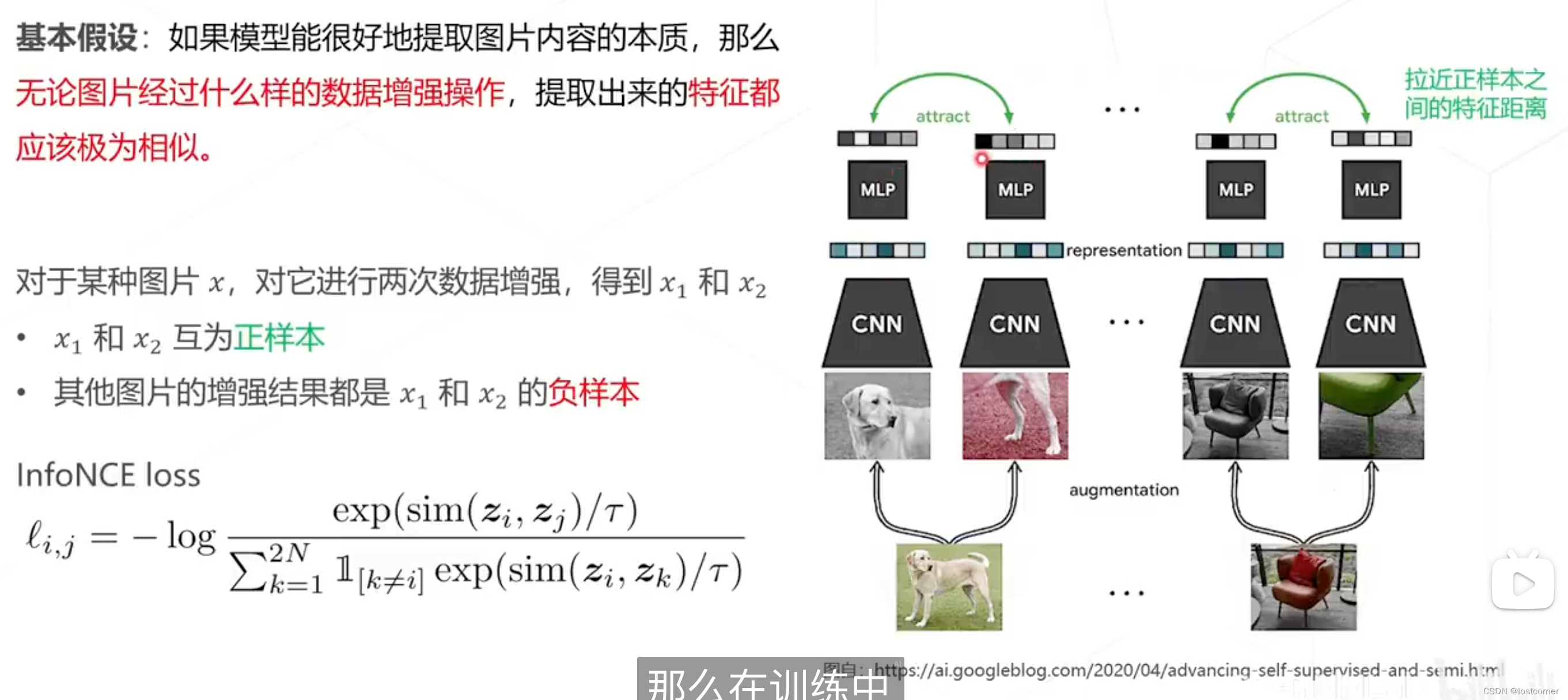

对比学习的思路就是就是推远副样本的距离,拉近正样本之间的特征距离。
MAE

MAE是一种掩码学习。
多模态算法
CLIP
经典算法CLIP是一个双流网络,由两个encoder分别来处理文本和图像数据
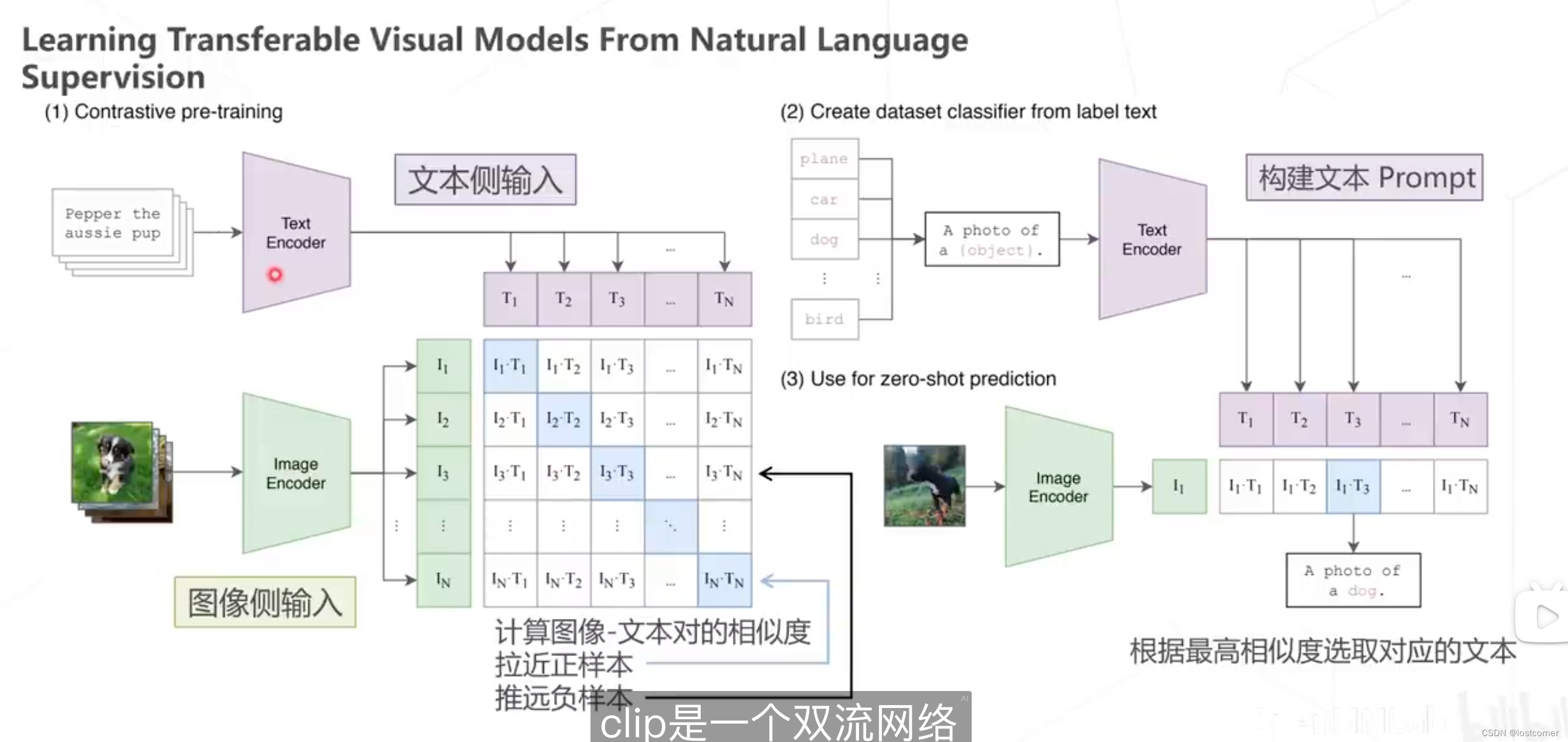
CLIP是一个优秀的zero-shot分类器,他能够迁移到大部分的数据集,能够得到非常好的效果,甚至能够超过ResNet。
BLIP

BLIP的Image Encoder就是一个ViT网络,对图像进行编码得到一个数据特征。同样,它有三个部分组成。

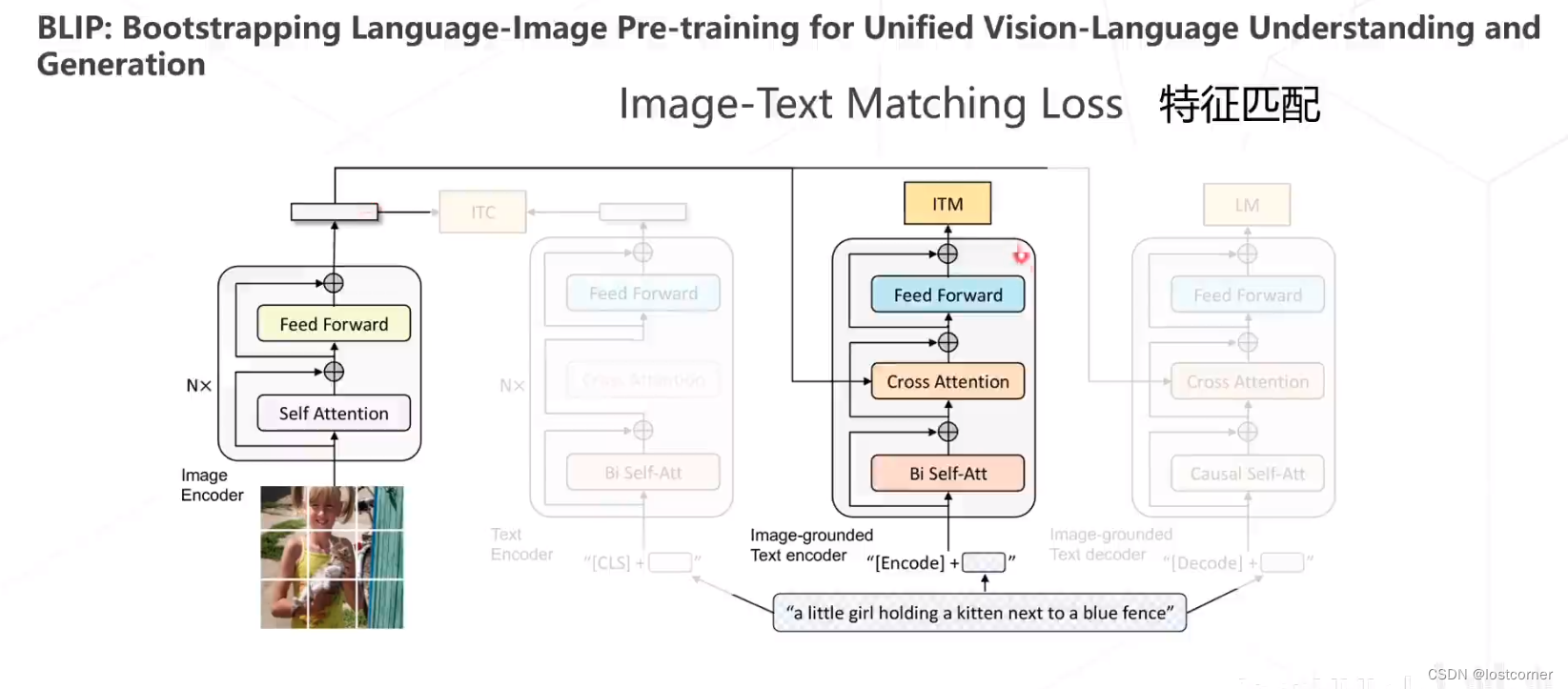

BLIP通过这三个loss的结合,构建了新的Vision Language Pre-training框架,能够实现各种下游任务。















 4908
4908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









