







 本文介绍了MTEB(MassiveTextEmbeddingBenchmark)项目,一个大规模文本嵌入评估基准,使用MTEBPytorch库进行安装和应用。通过SentenceTransformer模型执行任务评估,如Banking77Classification,并演示了如何在多GPU环境中并行处理。
本文介绍了MTEB(MassiveTextEmbeddingBenchmark)项目,一个大规模文本嵌入评估基准,使用MTEBPytorch库进行安装和应用。通过SentenceTransformer模型执行任务评估,如Banking77Classification,并演示了如何在多GPU环境中并行处理。
关于 MTEB
MTEB : Massive Text Embedding Benchmark
- github : https://github.com/embeddings-benchmark/mteb
- huggingface : https://huggingface.co/spaces/mteb/leaderboard
- paper : https://paperswithcode.com/paper/mteb-massive-text-embedding-benchmark
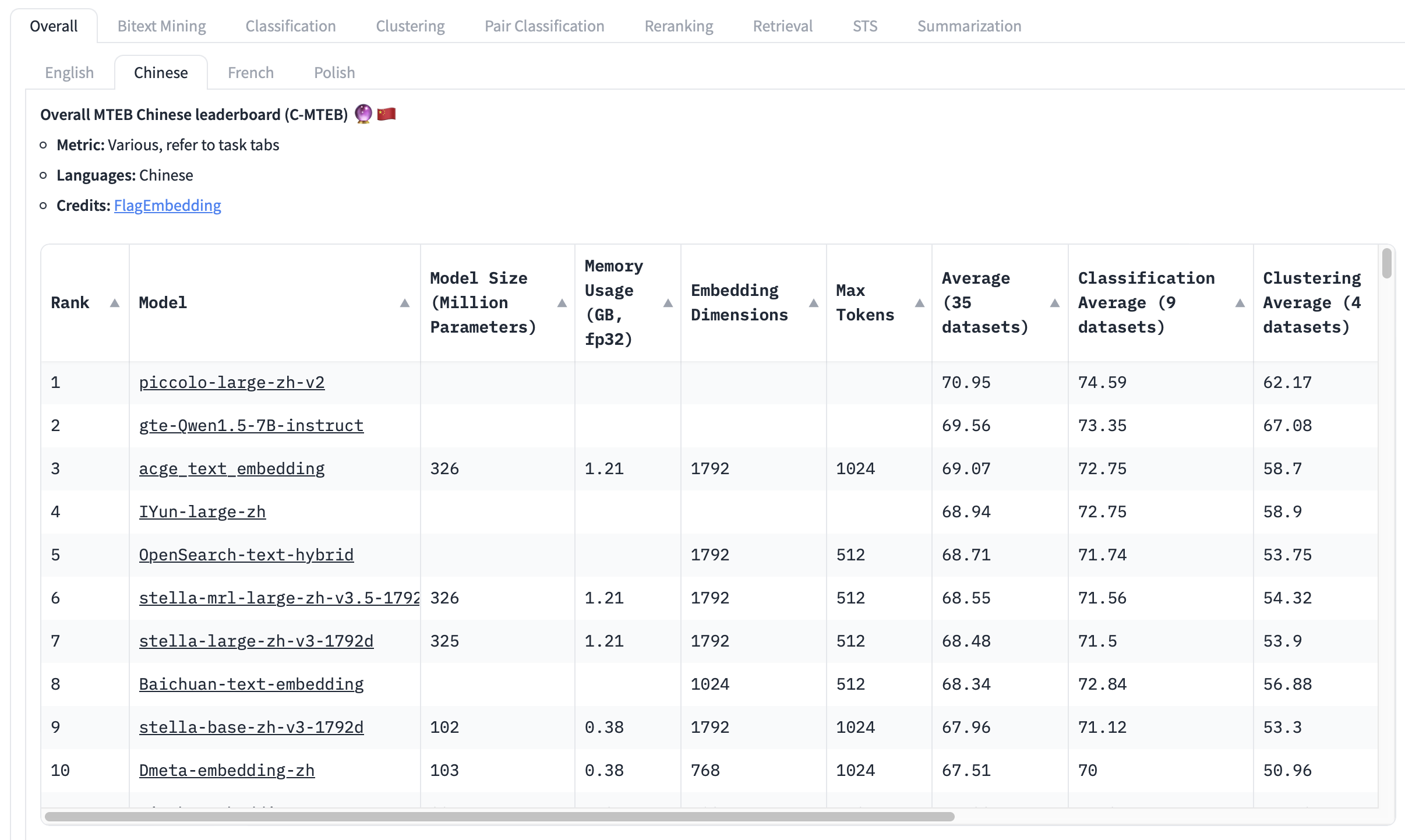
中文榜单(2024-05-03)
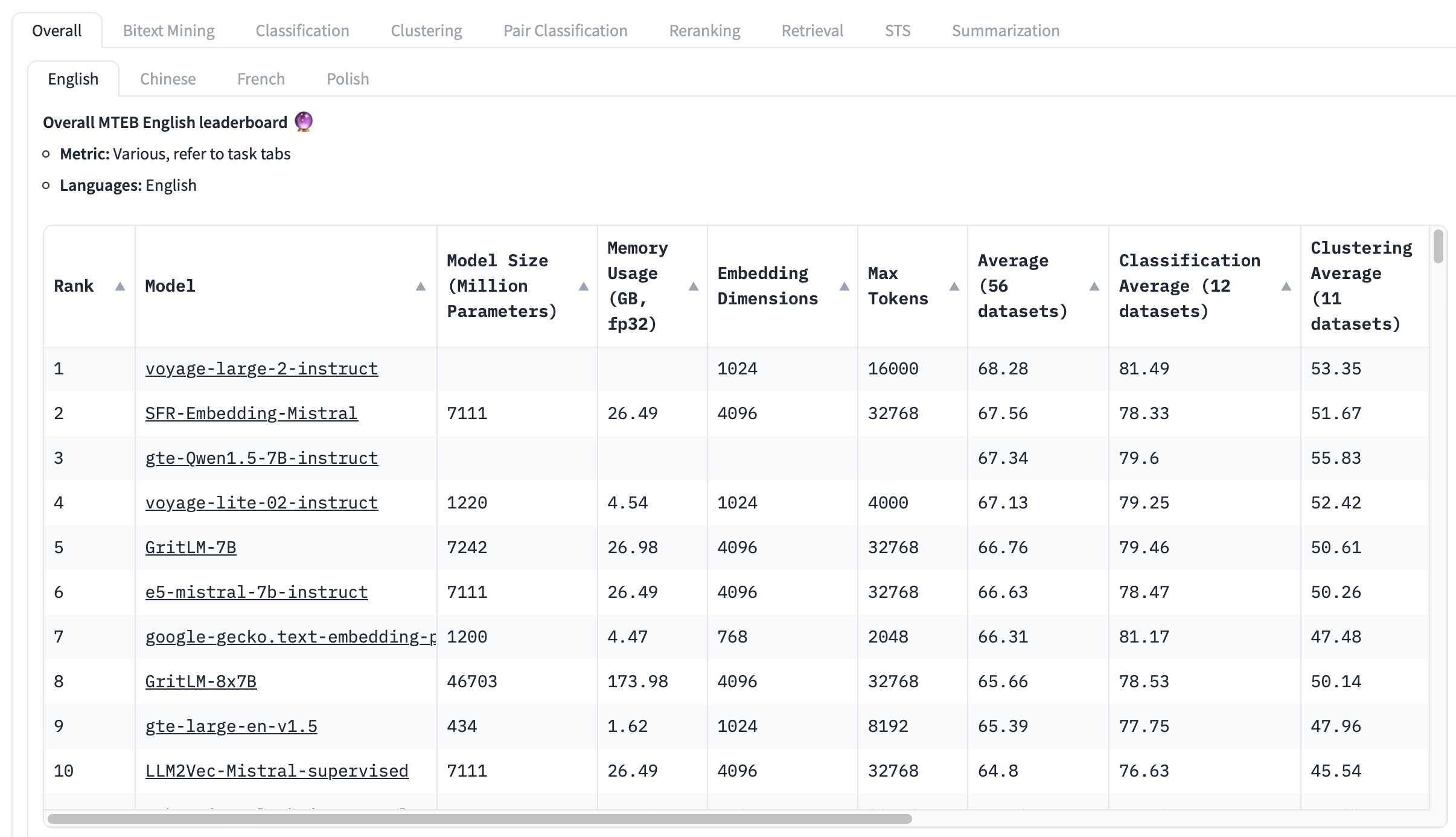
英文
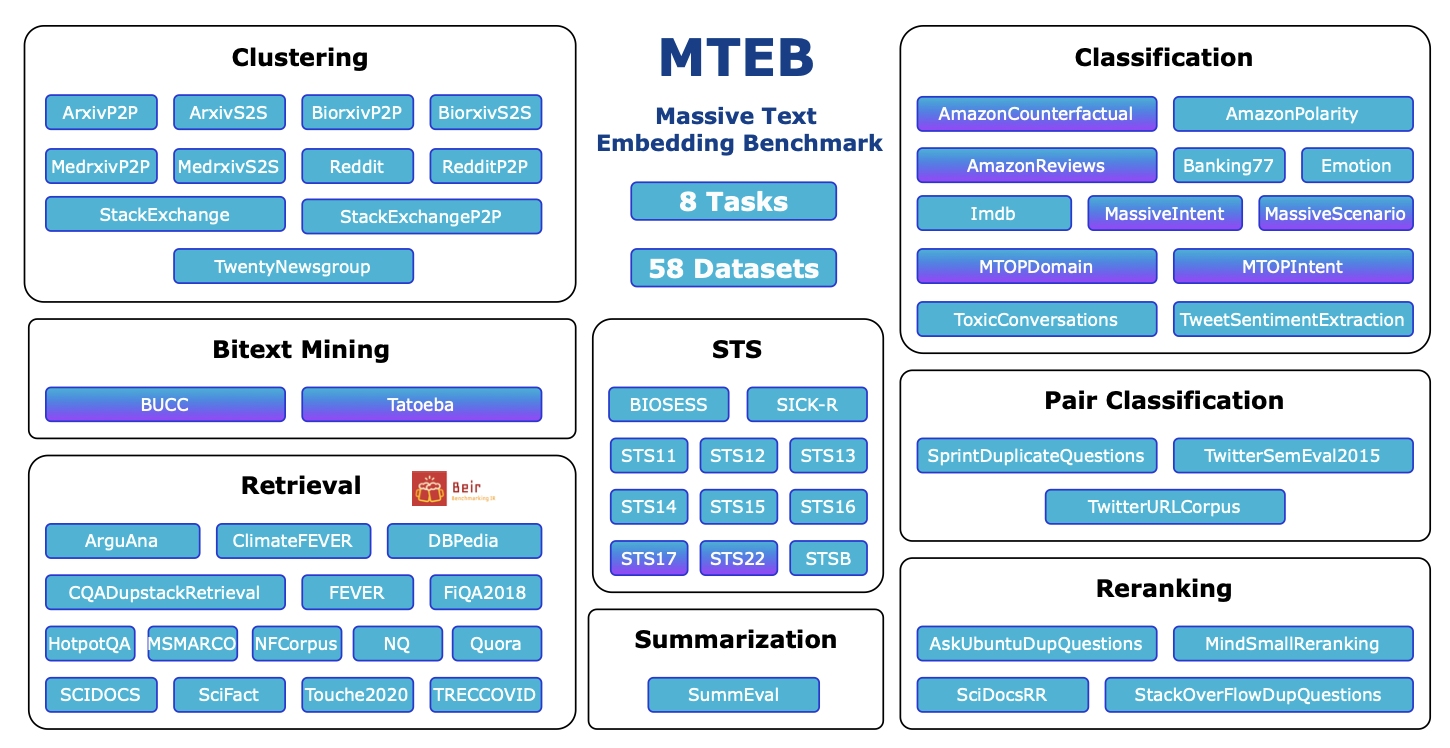
MTEB 任务和数据集概览
多模态标记为紫色。
使用 MTEB Pythont 库
Installation
pip install mteb
使用
- Using a python script (see scripts/run_mteb_english.py and mteb/mtebscripts for more):
from mteb import MTEB
from sentence_transformers import SentenceTransformer
# Define the sentence-transformers model name
model_name = "average_word_embeddings_komninos"
# or directly from huggingface:
# model_name = "sentence-transformers/all-MiniLM-L6-v2"
model = SentenceTransformer(model_name)
evaluation = MTEB(tasks=["Banking77Classification"])
results = evaluation.run(model, output_folder=f"results/{model_name}")
- 使用命令行
mteb --available_tasks
mteb -m sentence-transformers/all-MiniLM-L6-v2 \
-t Banking77Classification \
--verbosity 3
# if nothing is specified default to saving the results in the results/{model_name} folder
- Using multiple GPUs in parallel can be done by just having a custom encode function that distributes the inputs to multiple GPUs like e.g. here or here.
伊织 2024-05-03(五)



















 723
723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











