







本文翻译整理自:https://github.com/hiyouga/EasyR1
文章目录
一、关于 EasyR1
EasyR1 是基于原始 veRL 项目的清洁分支,旨在支持视觉语言模型。我们感谢所有作者提供了如此高性能的RL训练框架。
EasyR1 的高效性和可扩展性源于 HybirdEngine 的设计以及 vLLM 最新发布的SPMD模式。
相关链接资源
- github : https://github.com/hiyouga/EasyR1
- 官网:https://github.com/hiyouga/EasyR1
- 官方文档:https://verl.readthedocs.io/en/latest/start/multinode.html
- Paper : https://arxiv.org/abs/2409.19256
- Demo/在线试用:https://huggingface.co/datasets/hiyouga/geometry3k
- Hugging Face : https://huggingface.co/docs/trl/v0.16.1/en/grpo_trainer
- 微信群: https://github.com/hiyouga/EasyR1/raw/main/assets/wechat.jpg
关键功能特性
- 支持的模型
- Llama3/Qwen2/Qwen2.5 语言模型
- Qwen2/Qwen2.5-VL 视觉语言模型
- DeepSeek-R1 蒸馏模型
- 支持的算法
- GRPO
- Reinforce++
- ReMax
- RLOO
- 支持的数据集
- 任何符合特定格式的文本、视觉-文本数据集
- 支持的技巧
- 无填充训练
- 从检查点恢复
- Wandb & SwanLab & Mlflow & Tensorboard 跟踪
二、安装
软件要求
- Python 3.9+
- transformers>=4.51.0
- flash-attn>=2.4.3
- vllm>=0.8.3
我们提供了 Dockerfile 以便轻松构建环境。
推荐使用 EasyR1 中的预构建docker镜像。
docker pull hiyouga/verl:ngc-th2.6.0-cu126-vllm0.8.4-flashinfer0.2.2-cxx11abi0
硬件要求
- 预估值
| 方法 | 位数 | 1.5B | 3B | 7B | 32B |
|---|---|---|---|---|---|
| GRPO 全量微调 | AMP | 2*24GB | 4*40GB | 8*40GB | 16*80GB |
| GRPO 全量微调 | BF16 | 1*24GB | 1*40GB | 4*40GB | 8*80GB |
注:使用 worker.actor.fsdp.torch_dtype=bf16 和 worker.actor.optim.strategy=adamw_bf16 启用 bf16 训练。
我们正在努力减少RL训练中的VRAM占用,LoRA支持将在下次更新中集成。
三、教程:3步运行 Qwen2.5-VL GRPO 在 Geometry3K 数据集上
Geometry3K: https://huggingface.co/datasets/hiyouga/geometry3k
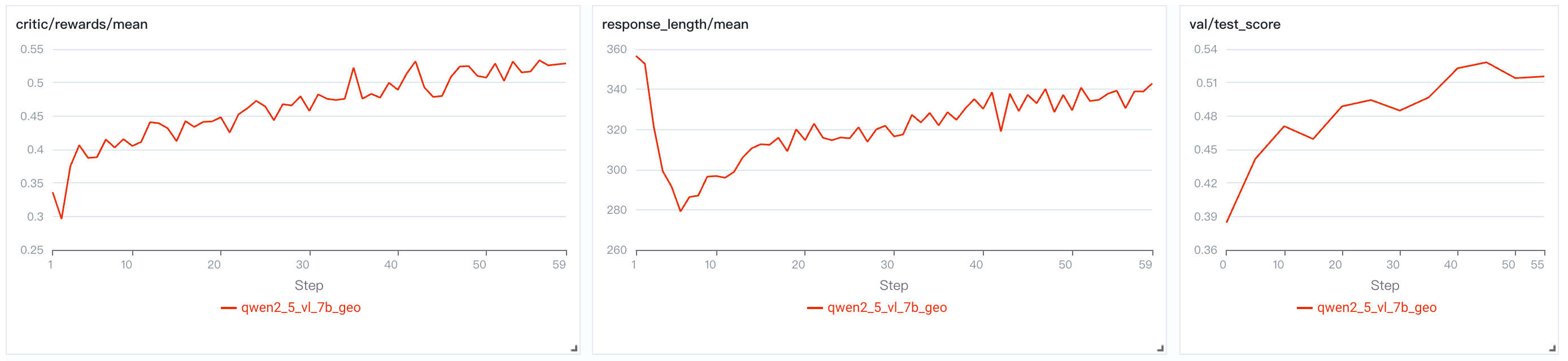
1、安装
git clone https://github.com/hiyouga/EasyR1.git
cd EasyR1
pip install -e .
2、GRPO 训练
bash examples/qwen2_5_vl_7b_geo3k_grpo.sh
3、合并 Hugging Face 格式的检查点
python3 scripts/model_merger.py --local_dir checkpoints/easy_r1/exp_name/global_step_1/actor
注:如果连接Hugging Face遇到问题,可以尝试 export HF_ENDPOINT=https://hf-mirror.com。
如果想使用 SwanLab 日志记录器,可以尝试 bash examples/qwen2_5_vl_7b_geo3k_swanlab.sh。
四、自定义数据集
请参考示例数据集准备您自己的数据集。
- 文本数据集: https://huggingface.co/datasets/hiyouga/math12k
- 图像-文本数据集: https://huggingface.co/datasets/hiyouga/geometry3k
- 多图像-文本数据集: https://huggingface.co/datasets/hiyouga/journeybench-multi-image-vqa
五、理解 EasyR1 中的 GRPO
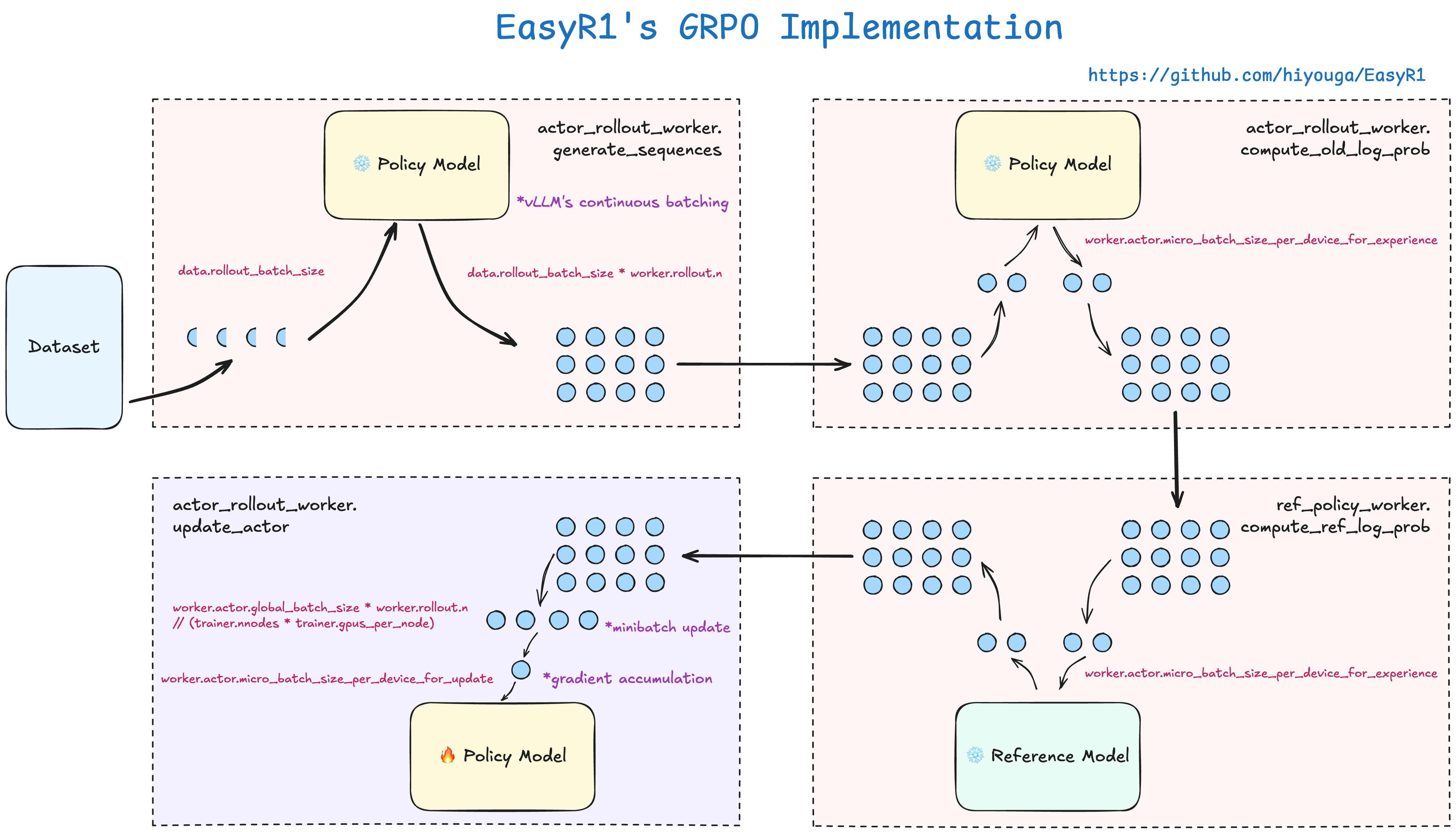
- 要了解 GRPO 算法,可以参考 Hugging Face的博客。
六、在多节点环境中运行 70B+ 模型
1、启动 Ray head 节点。
ray start --head --port=6379 --dashboard-host=0.0.0.0
2、启动 Ray worker 节点并连接到 head 节点。
ray start --address=<head_node_ip>:6379
3、检查 Ray 资源池。
ray status
4、仅在 Ray head 节点上运行训练脚本。
bash examples/qwen2_5_vl_7b_geo3k_grpo.sh
更多关于多节点训练和Ray调试器的细节,请参阅 veRL官方文档。
七、其他基线
我们还复现了 R1-V 项目的以下两个基线。
- CLEVR-70k-Counting: 在计数问题上训练 Qwen2.5-VL-3B-Instruct 模型。
- GeoQA-8k: 在GeoQA问题上训练 Qwen2.5-VL-3B-Instruct 模型。
八、性能基线
参见 baselines.md。
九、使用 EasyR1 的精彩项目
- MMR1: 推进多模态推理的前沿。 代码
- Vision-R1: 激励多模态大语言模型中的推理能力。 代码 arxiv
- Seg-Zero: 通过认知强化实现推理链引导的分割。 代码 arxiv
- MetaSpatial: 在VLMs中强化3D空间推理能力以支持元宇宙。 代码 arxiv
- Temporal-R1: 通过时间一致性奖励将时间推理能力融入LMMs。 代码
- NoisyRollout: 通过数据增强强化视觉推理。 代码 arxiv
- GUI-R1: 用于GUI代理的通用R1风格视觉语言动作模型。 代码 arxiv
十、TODO
- 支持 LoRA(高优先级)。
- 支持VLMs的ulysses并行(中优先级)。
- 支持更多VLM架构。
注:本项目不提供监督微调和推理的脚本。如果有此类需求,推荐使用 LLaMA-Factory。
已知问题
以下功能暂时禁用,我们计划在未来的更新中逐一修复。
- 视觉语言模型目前还不兼容ulysses并行。
十一、常见问题
ValueError: 图像特征和图像标记不匹配: tokens: 8192, features 9800
增加 data.max_prompt_length 或减少 data.max_pixels。
RuntimeError: CUDA Error: out of memory at /workspace/csrc/cumem_allocator.cpp:62
减少 worker.rollout.gpu_memory_utilization 并启用 worker.actor.offload.offload_params。
RuntimeError: 0 active drivers ([]). There should only be one.
从当前python环境中卸载 deepspeed。
伊织 xAI 2025-04-23(三)



















 183
183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}