









0. 简介
作为22年比较重磅的物体识别算法,作者觉得不得不说一说,虽然作者目前主要方向不是深度学习了,但是里面很多重要的操作还是值得回味的。这里就从想要大致了解Yolo v7同学的眼光来对v7的算法进行介绍。并按照原文《YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors》的顺序,来向读者介绍相较于之前的Yolo算法加了什么操作。与它的前辈一样,Yolo v7的代码是完全开源的,代码在Github上https://github.com/WongKinYiu/yolov7。
1. Yolo v7的性能与结构
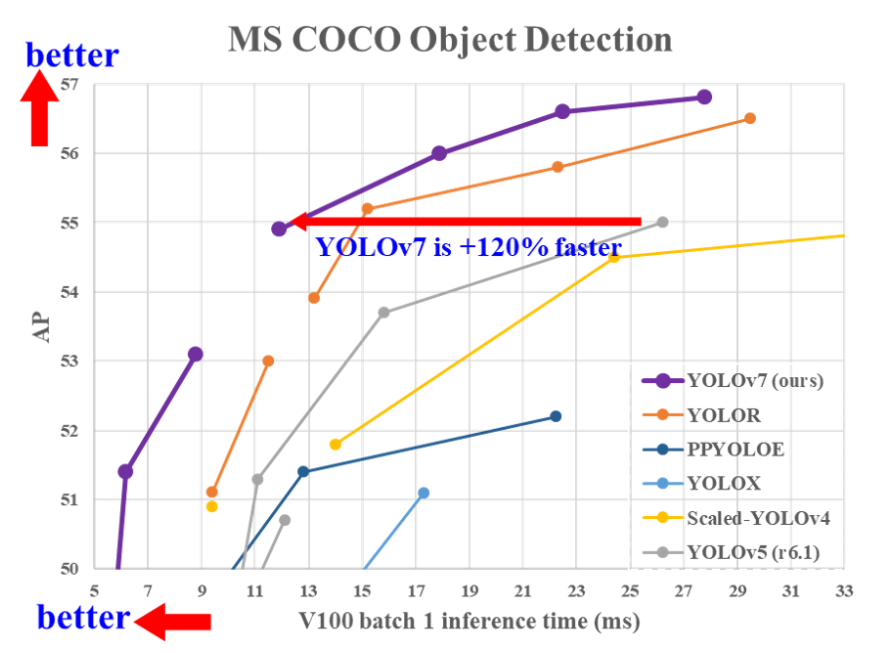
为了让我们对比,论文中,官方将YOLOv7相同体量下比YOLOv5精度更高,速度快120%(FPS),比 YOLOX 快180%(FPS),比 Dual-Swin-T 快1200%(FPS),比 ConvNext 快550%(FPS),比 SWIN-L快500%(FPS)。同时在精度为56.8% AP下模型仍可达到30 FPS以上的检测速率。这也是截止到目前最优目标识别算法了。
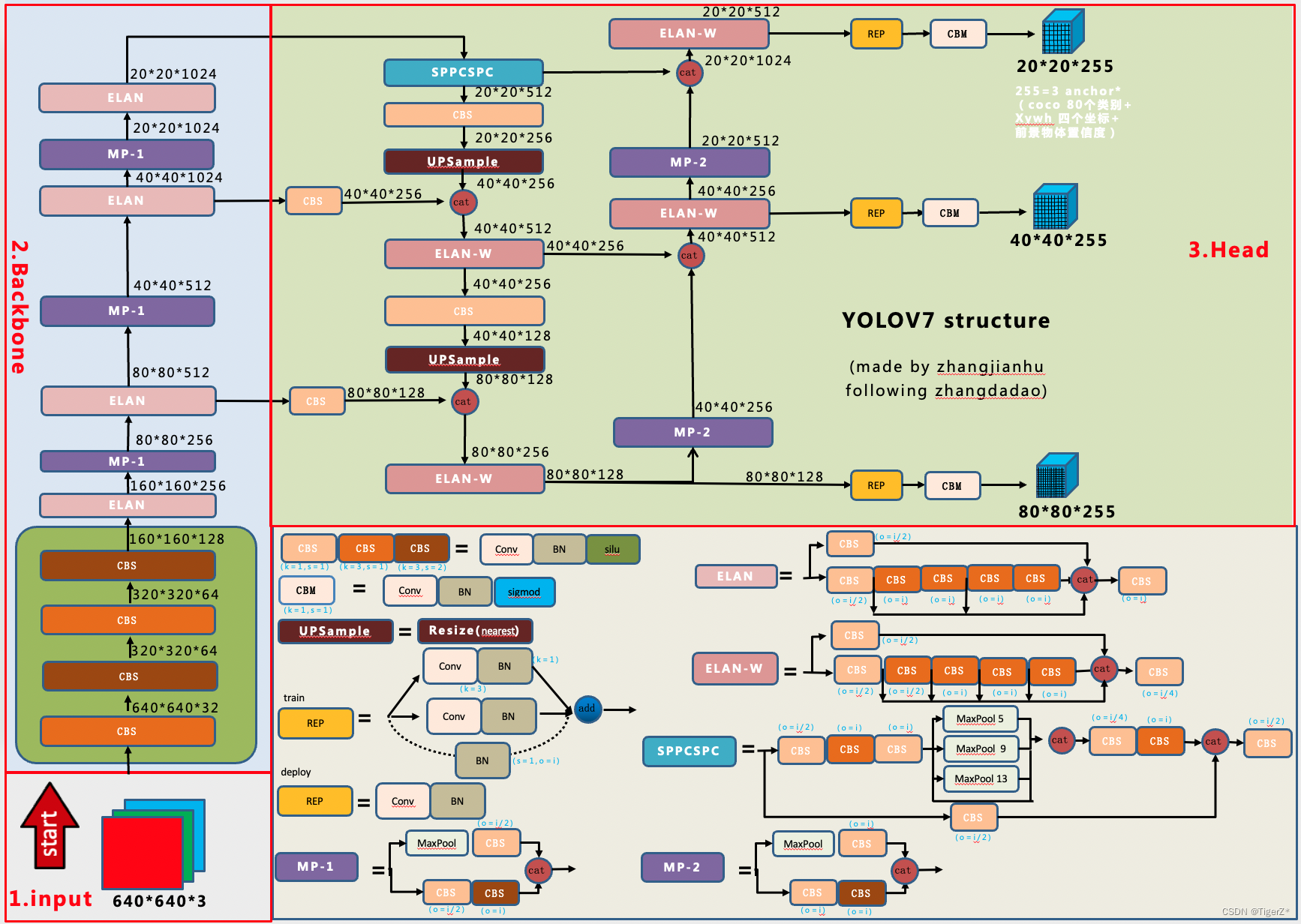
下面我们来看一下Yolo v7模型中整个流程图,其实比较简单的来看,其实Yolo v7将整个模型分成了三个大块。具体结构和Yolo v5挺类似的,主要就是对网络内部组件进行了更换,比如辅助训练头、标签分配思想等,但是基本上整体结构还是保持了Yolo的那一套处理。
2. Yolo v7 中新的模块
在Yolo v7中,我们可以看大,算法框架中多出了三种模块:E-ELAN模块、SPPSPC模块、REP模块。
2.1 Extended-ELAN模块
首先我们来看一下E-ELAN模块,该模块是通过控制最短最长的梯度路径,让更深的网络可以有效的学习和收敛的,作者提出的E-ELAN对基数(Cardinality)做了扩展(Expand)、乱序(Shuffle)、合并(Merge cardinality),能在不破坏原始梯度路径的情况下,提高网络的学习能力。
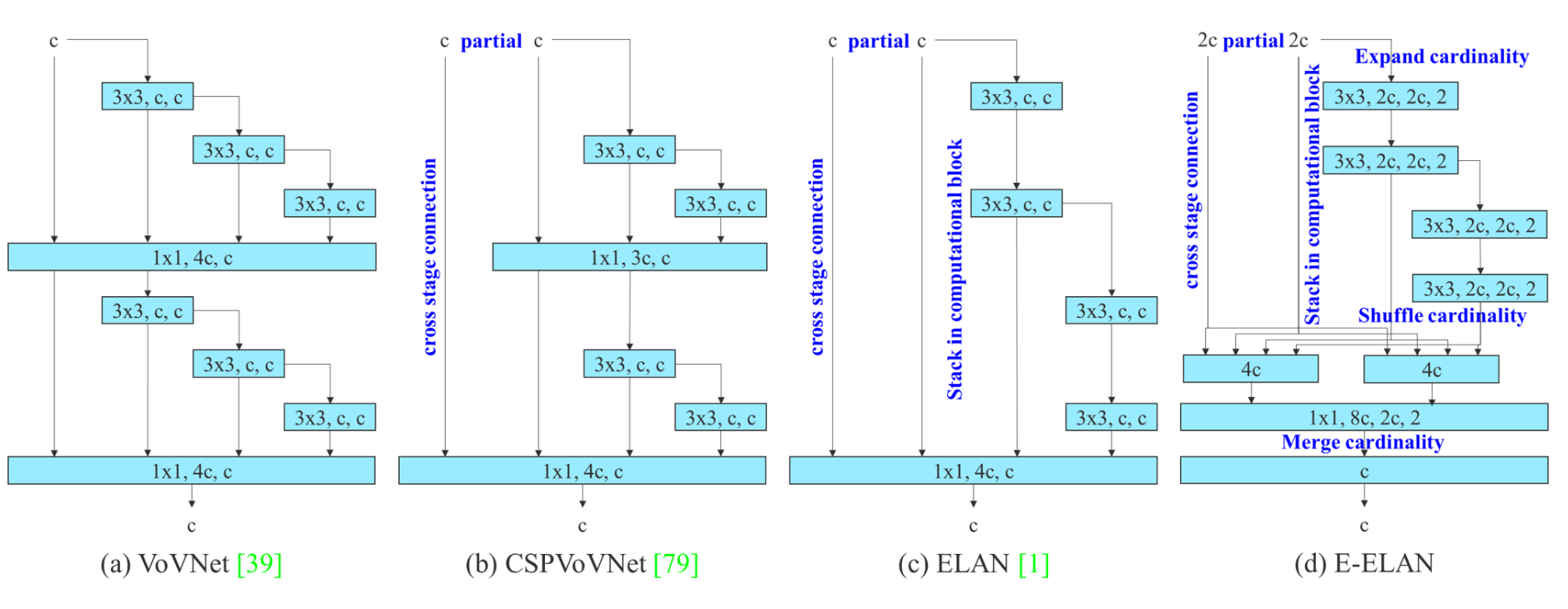
但是实际上作者并未实现E-ELAN,所以在这篇博文中,作者指出E-ELAN的改进,其等效网络就是两个ELAN(红框里)的Concat,作者的解释是:
For E-ELAN architecture, since our edge device do not support group convolution and shuffle operation, we are forced to implement it as an equivalence architecture.

对应部分在yolov7.yaml中
ELAN (backbone)
# ELAN1
[-1, 1, Conv, [64, 1, 1]],
[-2, 1, Conv, [64, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 11
简化结构如下,其中CBS是Conv+BN+LeakyReLu的结合。

ELAN-W (head)
# ELAN2
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 63

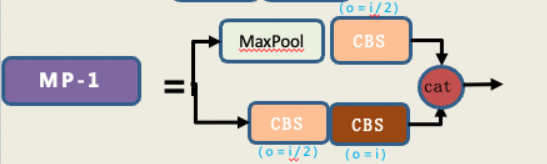
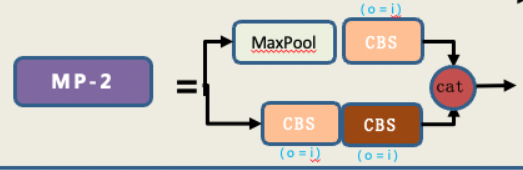
2.2 MP结构
我们可以看到这个结构存在两个头用于concat,之前下采样我们通常最开始使用maxpooling,之后大家又都选用stride = 2的3*3卷积,在Yolo v7中作者同时使用了max pooling 和 stride=2的conv。需要注意head中的MP前后通道数是不变的,而backbone处通道数减少一半。
MP-1 (backbone)
[-1, 1, Conv, [256, 1, 1]], # 11
# MPConv
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 16-P3/8
MP-2 (head)
[-1, 1, Conv, [128, 1, 1]], # 75
# MPConv Channel × 2
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3, 63], 1, Concat, [1]],
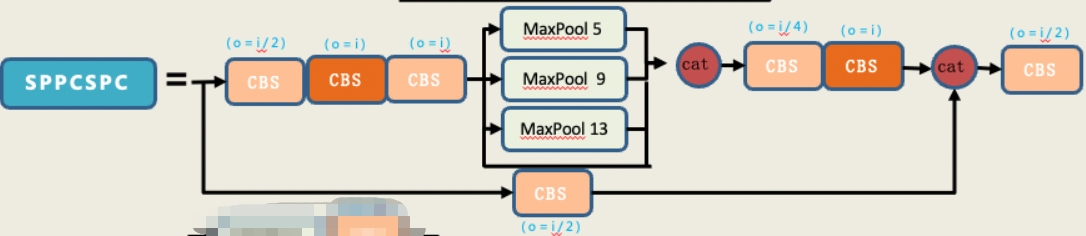
2.3 SPPCSPC模块
类似于yolov5中的SPPF,不同的是,使用了5×5、9×9、13×13最大池化。在在yolov7.yaml中,只使用了一次SPPSPC模块,在backbone与head对接的地方。可以看到,总的输入会被分成两段进入不同的分支,最中间的分支其实就是金字塔池化操作,上侧则为一个point conv,最后将所有分支输出的信息流进行concat。
# yolov7 head
head:
[[-1, 1, SPPCSPC, [512]], # 51
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[37, 1, Conv, [256, 1, 1]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
3. RepConv(重参数卷积)
模块重参化是近年来一个比较流行的研究课题。这种方法在训练过程中将一个整体模块分割为多个相同或不同的模块分支,但在推理过程中将多个分支模块集成到一个完全等价的模块中。模型重参化策略在推理阶段将多个模块合并为一个计算模块,可以看作是一种集成技术(model ensemble,其实笔者觉得更像是一种基于feature的distillation)。对于模型级重新参数化有两种常见的操作:
- 一种是用不同的训练数据训练多个相同的模型,然后对多个训练模型的权重进行平均。
- 一种是对不同迭代次数下模型权重进行加权平均。
这个重参数卷积(Planned re-parameterized convolution)也是一个非常重要的创新,RepConv在VGG中有比较优异的性能,但当它直接应用于ResNet、DenseNet或者其他架构时,精度会明显降低。这是因为RepConv中的直连(Identity connection)破坏了ResNet中的残差和DenseNet中的连接。

基于上述原因,作者使用没有identity连接的RepConv结构。图4显示了作者在PlainNet和ResNet中使用的“计划型重参化卷积”的一个示例。
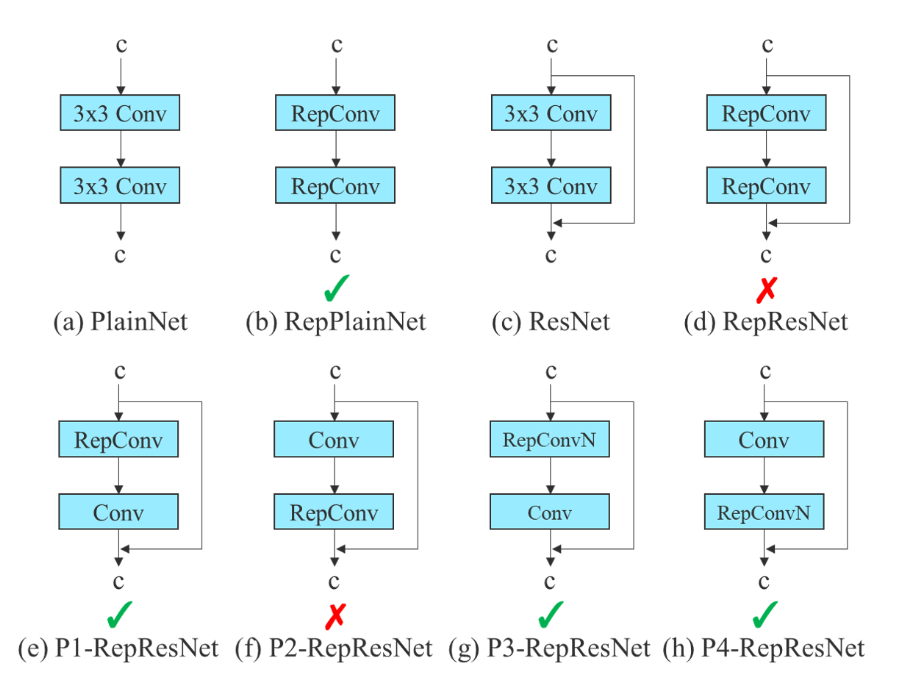
我们知道重参数化可以在保证模型性能的条件下加速网络,主要是对卷积+BN层以及不同卷积进行融合,合并为一个卷积模块。下面给出了卷积+BN融合的公式化过程,红色表示卷积参数(权重和偏置),蓝色是BN参数(
m
m
m是输入均值,
v
v
v是输入标准差,
γ
\gamma
γ和
β
\beta
β是两个可学习的参数),最终经过一系列化简,融合成了一个卷积:
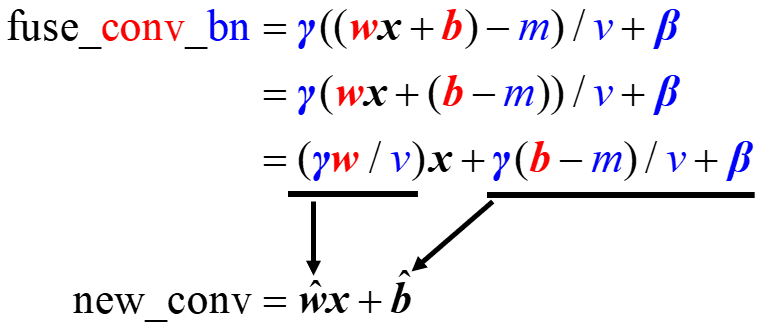
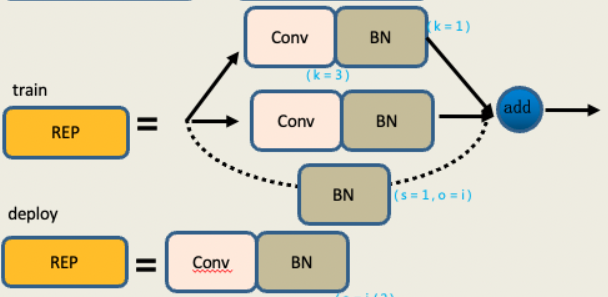
在YOLOv7中,REP在训练和部署的时候结构不同,在训练的时候由33的卷积添加11的卷积分支,同时如果输入和输出的channel以及
h
,
w
h,w
h,w的size一致时,再添加一个BN的分支,三个分支相加输出,在部署时,为了方便部署,会将分支的参数重参数化到主分支上,取3*3的主分支卷积输出。
[75, 1, RepConv, [256, 3, 1]],
[88, 1, RepConv, [512, 3, 1]],
[101, 1, RepConv, [1024, 3, 1]],
下面是对应的代码:


















 4795
4795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











