







0. 简介
随着Transformer爆火,也导致了许多以Transformer为主题框架的端到端网络的兴起,这也导致了传统自动驾驶模块化逐渐被取代,虽然已经发展得相当成熟,通常采用模块化串联的部署方式:其核心模块涵盖感知、定位、预测、决策和控制等,每个主要模块及其子模块都承担着特定的职责,且每个模块的输入通常来源于前一模块的输出。
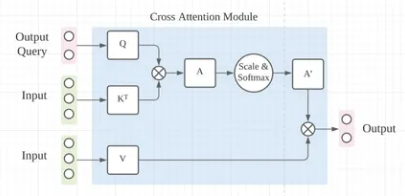
这类模块化设计的优势在于能够将复杂的自动驾驶任务分解为更小、更易于管理的子任务,同时便于问题的追踪和定位;然而,随着自动驾驶技术向数据驱动的方向发展,模块化设计的某些局限性也逐渐显现,例如信息传递过程中可能出现的损耗、计算延迟以及累积误差等问题。
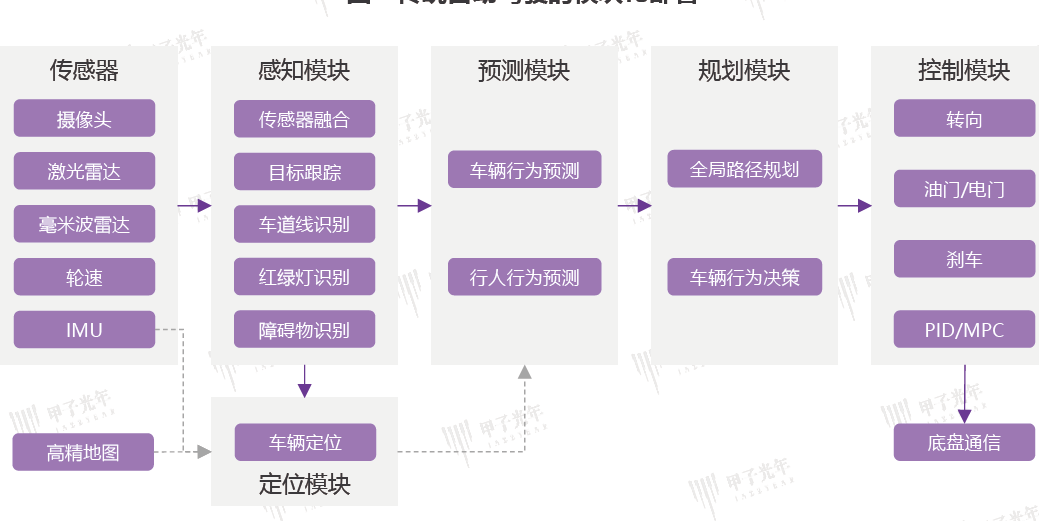
为此现在更多的工作开始瞄向“全局最优”。因为模块化自动驾驶系统面临信息丢失、计算效率低、累积误差以及维护成本等问题,这些问题难以回避,需要新的思路去解决。
端到端自动驾驶通过将传感器收集到的全面信息作为输入,在单一网络中直接生成车辆的控制指令或运动规划。这种设计使得整个系统针对最终目标进行优化,而非仅仅针对某个独立的子任务,从而实现自动驾驶性能的全局最优化。随着高质量数据的不断积累和模型的持续优化,端到端架构有望展现出比传统模块化架构更优越的自动驾驶性能。
目前,BEV+OCC+Transformer已经实现了感知模块的端到端架构,决策模块也在逐步从依赖手写规则向基于深度学习的模式转变,最终目标是实现模块化联合与单一模型的端到端自动驾驶
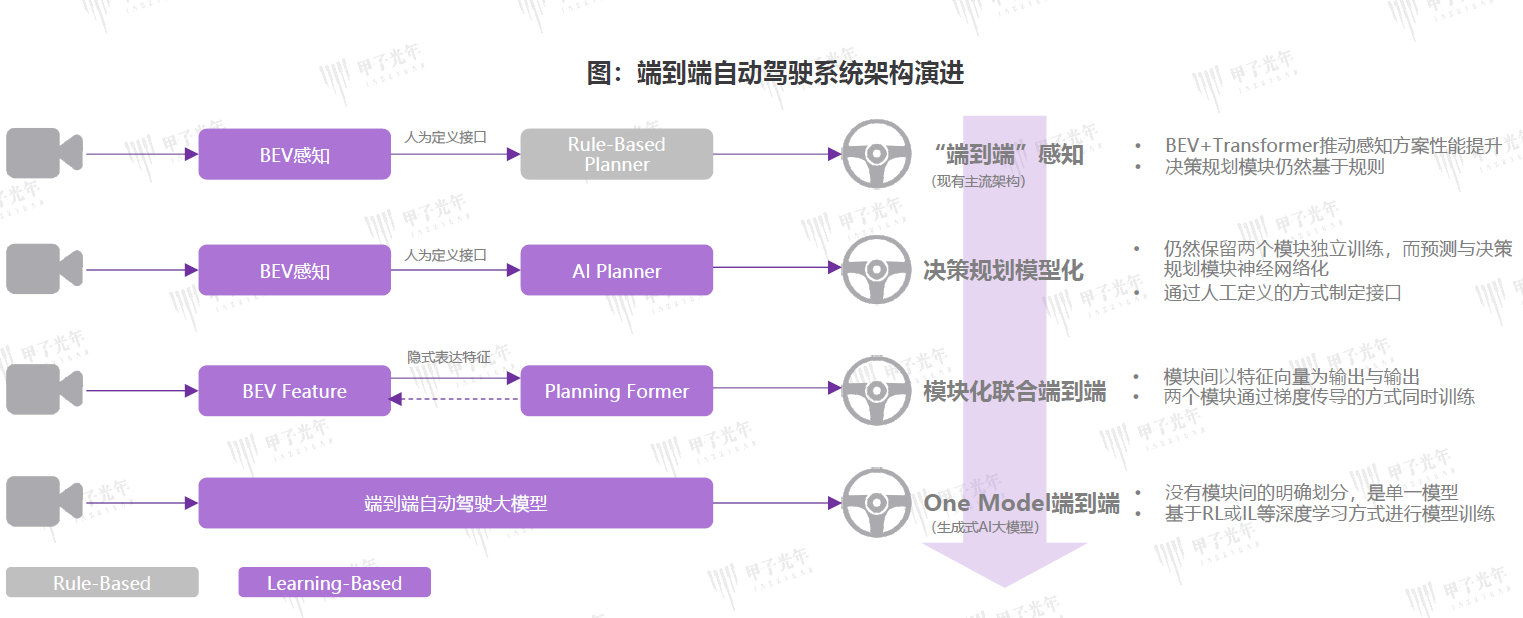
模仿学习(Imitation Learning)和强化学习(Reinforcement Learning)在端到端自动驾驶的训练过程中起着重要作用,因为它们分别从不同的角度解决了训练智能体的问题。以下是它们的基本原理和流程:
0.1 行为克隆(Behavior Cloning)
- 数据收集:从专家(如人类驾驶员)处收集大量驾驶数据,这些数据包括传感器输入(如摄像头图像、雷达数据)和相应的控制输出(如方向盘转角、加速和制动)。
- 数据预处理:对收集到的数据进行清洗和预处理,以确保数据质量。
- 模型训练:使用预处理后的数据训练一个神经网络模型,使其能够从传感器输入预测出相应的控制输出。
- 验证和测试:在不同的驾驶场景下验证和测试训练好的模型,确保其能够模仿专家的行为。
0.2 逆最优控制(Inverse Optimal Control)
- 数据收集:类似行为克隆,从专家处收集驾驶数据。
- 推断奖励函数:假设专家的行为是最优的,通过逆向推断专家的奖励函数。
- 模型训练:使用推断出的奖励函数训练神经网络模型,使其能够从传感器输入中推断出最优的控制输出。
0.3 强化学习(Reinforcement Learning)
强化学习通过试错和奖励机制来学习策略。其关键在于设计一个合理的奖励函数,使得智能体能够通过不断的交互和学习来优化其行为。
0.3.1 环境设置
- 环境仿真:创建一个逼真的驾驶模拟环境,使智能体能够在虚拟环境中进行训练和试错。
- 状态和动作空间定义:定义智能体的状态空间(如车的位置、速度等)和动作空间(如转向、加速、制动)。
0.3.2 奖励函数设计
- 奖励函数:设计一个奖励函数,以量化每个动作的好坏。奖励函数通常根据驾驶的安全性、效率、舒适度等因素来设计。
0.3.3 模型训练
- 初始策略:初始化智能体的策略,可以是随机的或从模仿学习得到的初始策略。
- 策略迭代:智能体在环境中进行试错,通过与环境的交互来收集经验。
- 价值函数估计:根据收集到的经验,估计状态的价值函数或动作的优势函数。
- 策略更新:根据价值函数或优势函数更新策略,使得智能体逐渐学会选择最优动作。
0.3.4 验证和测试
- 评估:在不同的驾驶场景和环境下评估训练好的模型,确保其能够在真实世界中表现良好。
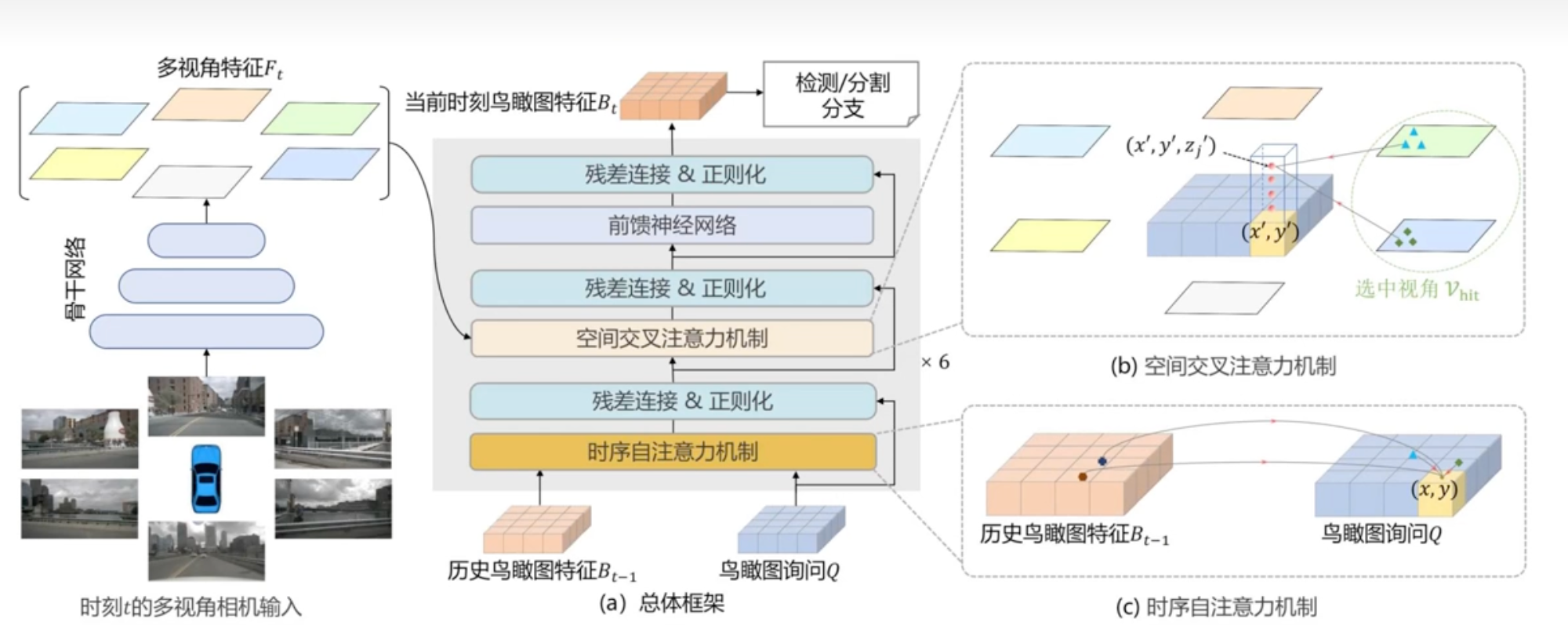
这些内容虽然我们后面都需要进行学习了解,但是一口不能吃成一个胖子,所以会先从BevFormer开始学起,BEVformer的输入数据格式大致为:
- 输入张量( b a t c h s i z e batch_size batchsize, q u e u e queue queue, c a m cam cam,C,H,W)
- q u e u e queue queue表示连续帧的个数,主要解决遮挡问题
- c a m cam cam表示图像数量 / p e r /per /per 帧
- C , H , W C,H,W C,H,W就是 c , h , w c,h,w c,h,w也就是图片通道数(3),高度,宽度
其他都好理解,可能queue和cam不好理解
比如你当前时刻是 t t t,那么 q u e u e queue queue我想设置成3,就意味着,除了当前时刻以外, t − 1 t-1 t−1和 t − 2 t-2 t−2时刻的信息我要一并拿来计算
c a m cam cam:可以简单理解成摄像头的数量,比如按我前几章的逻辑图画的 样子,那么 c a m < = 6 cam<=6 cam<=6
1. BEVformer Backbone以及设计思想
在BEV之前,大概三四年前吧,其实就出现了前后融合
- 后融合:或者叫结果融合,就是假如有6个摄像头,把6个摄像头的检测结果进行融合
- 前融合:或者叫数据融合,就是把6个摄像头拼成一个大图,然后对大图进行处理
看了我前后融合的解释,其实不难理解,前后融合都有各自的问题,目前看只有22年底出来的BEV,通过CNN,或者是Transformer(ViT)来提取特征,才能做到真正的特征级别的融合,也是代表未来的方向。
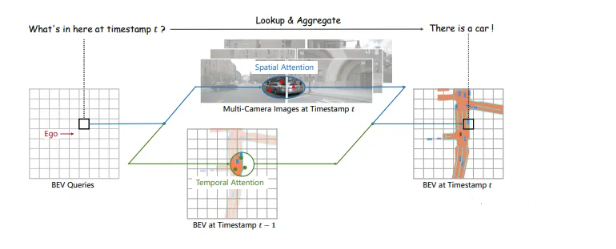
如图所示:BEVFormer主体部分有6层结构相同的BEVFormer encoder layers,每一层都是由以transformer为核心的modules(TSA+SCA),再加上FF、Add和Norm组成。BEVFormer encoder layer结构中有3个特别的设计:BEV Queries, Spatial Cross-attention(SCA)和Temporal Self-attention(TSA)。其中BEV Queries是栅格形可学习参数,承载着通过attention机制在multi-camera views中查询、聚合的features。SCA和TSA是以BEV Queries作为输入的注意力层,负责实施查询、聚合空间features(来自multi-camera images)和时间features(来自历史BEV)的过程。
这里我们可以将 BEV可以想象成一个Tensor。假设我画的下面这个图是200*200的矩阵
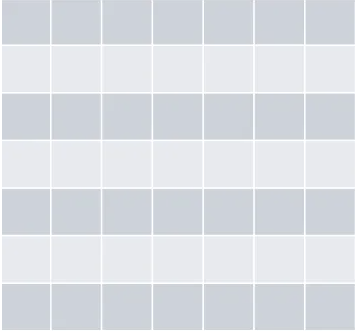
这个每一个对应的小方块(在现实世界一般是米为单位的,1米或0.5米完全取决于你要求的细致程度),每一个方块我们其实可以把它理解为一个向量。特征空间你可以给它想象成一个网络,特征空间的大小,也就是网格的间隔决定了你的精度,你可以弄
200
∗
200
200*200
200∗200,那就得到了4万个向量组成的在高维空间上融合的tensor。在特征空间里,我们可以以全局视角来进行预测,整个空间的长和宽(比如
200
∗
200
200*200
200∗200)都给出来了,只需要来计算每个方块的具体特征是啥就可以了。
如果在任务中把每个点的特征都做出来了,你在高维空间中做物体检测啥的,这就是已经现成了(传统比如Yolo,DETR,还得先构建特征空间和向量)。
按照图说,比如我要求橙色箭头上对应的这个点的特征,那如果我想求出这个点的特征,要和其他6个矩阵中的哪几个矩阵去做乘法呢(没错其实就可以简单理解成矩阵乘),如果我要全做,那这个框架等于没意义
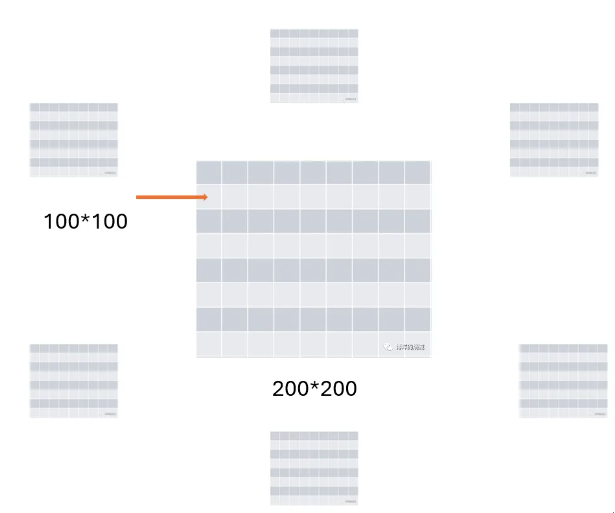
然后我们判断一下,这个点对应的实际上在物理世界里是前面和左前方摄像头的位置,跟其他额外的四个不发生关系
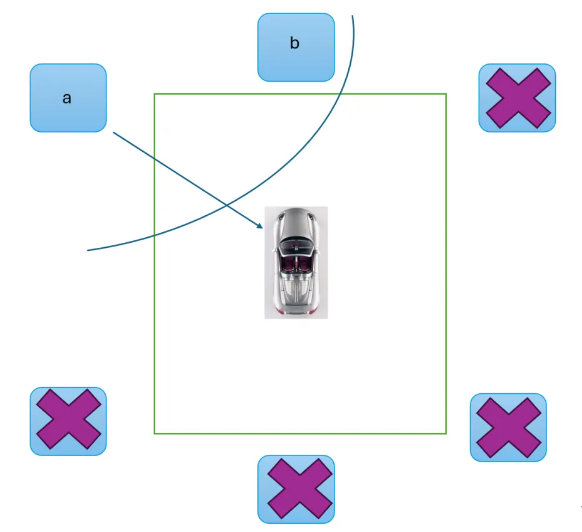
所以我们只要去和扇形框起来的这两个矩阵去做运算就可以了,这样一下子显存节省了百分之66,TFLOPs的消耗也节省了百分之66
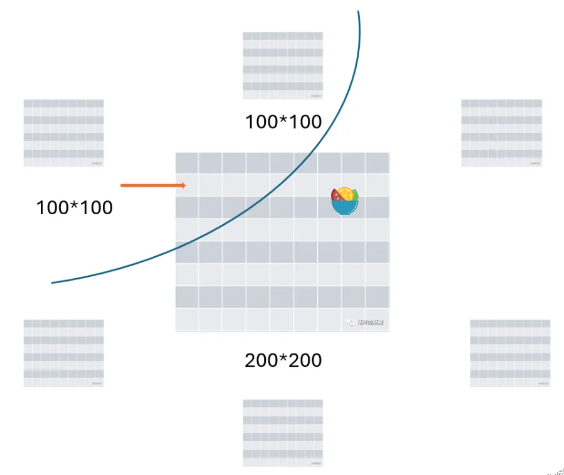
这个就是特征简化,BEVformer就直接帮你做了。在BEVformer里面有一个很重要的概念就是时间注意力模块,时间注意力模块的用途,就是做时间对齐的,因为不同帧里面的车和周围物体都会有偏移
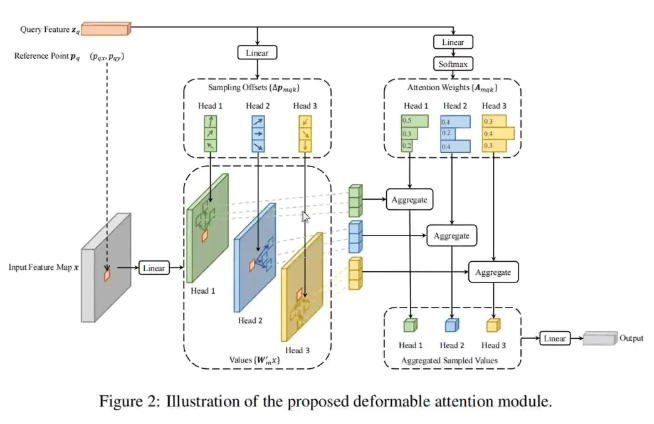
首先是原论文里的图,可以看到在做物体检测的时候实际上又外挂了两个Linear,就是全连接层。我们可以将上图每一个格子可以认为一个向量,那这个向量的特征咋算呢,它是跟这个矩阵中所有点都做self-attention吗,那就是N的平方的计算量了。如果说跟周边几个做?比如我就跟周边4个点做,那么算法是不是就从N方变成4N了,一下省了好多资源。


















 1505
1505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











